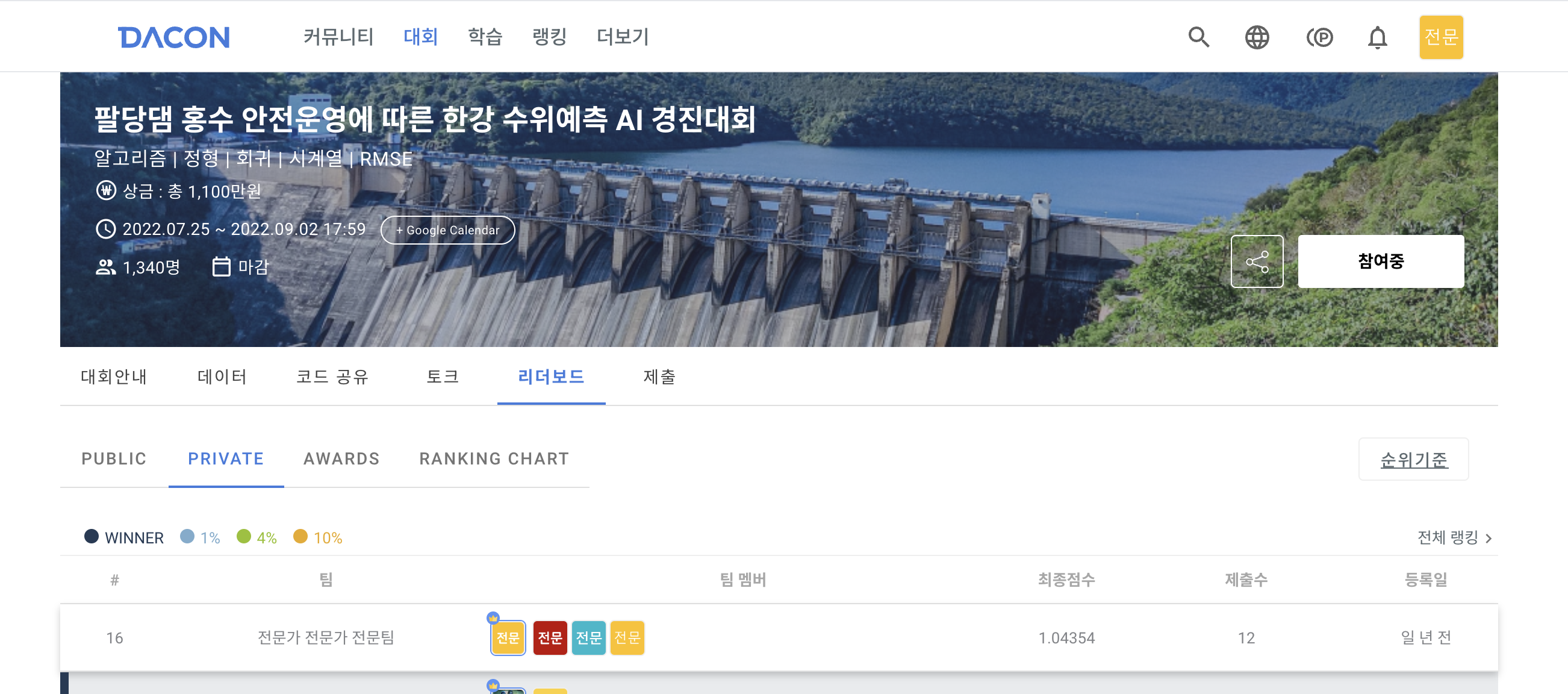
대회 소개
- 팔당댐 홍수 안전운영에 따른 한강 수위예측 AI 경진대회
- 청담대교, 잠수교, 한강대교, 행주대교 수위 예측하기
특이점
-
시계열 데이터 사용
-
22년 6월~7월 데이터를 사용하여 솔루션이 존재
-
Data Leakage가 존재할 수 밖에 없는 환경
-
외부 데이터 사용 제한 x

- private 스코어 기준 16등, 상위 5%
사용한 외부 데이터
0. 수위 데이터 및 조위 데이터
-
한강홍수통제소에서 제공하는 오픈 API 활용 → 수위 데이터
-
2022년 6~7월의 강화대교, 행주대교, 한강대교, 잠수교, 청담대교의 수위를 수집
- 예측하는 일시의 10분 전까지 훈련에 활용 -
2012년 ~ 2022년 7월 까지의 광진대교, 팔당대교, 김포시 전류리의 수위테이터 수집
- 예측하는 일시의 10분 전까지 훈련에 활용
- 코드를 참조하여 받아옴
1. 라이브러리 호출
import numpy as np
import pandas as pd
from glob import glob
from tqdm.notebook import tqdm
import requests
import calendar
import timesample_submission = pd.read_csv("./data/sample_submission.csv")2. 시계열 데이터 → unixtime
# datetime string to unixtime integer
def str_to_unixtime(str_time):
return int(pd.Timestamp(str_time).timestamp())시계열 데이터를 integer 형태의 데이터로 바꾸어준다
sample_submission["timestamp"] = sample_submission["ymdhm"].apply(str_to_unixtime)3. API 호출
SERVICE_KEY = "???"개인적으로 발급받은 api라서 가리도록 하겠다
url = f'http://api.hrfco.go.kr/{SERVICE_KEY}/waterlevel/info.json'
response = requests.get(url)
data = response.json()4. 데이터 확인
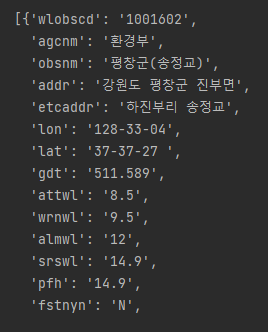
data['content']데이터를 찍어보면 다음과 같은 형태임을 알 수 있다.
for con in data['content']:
if '서울' in con['obsnm']:
print(con['obsnm'], con['wlobscd'])
if '팔당' in con['obsnm']:
print(con['obsnm'], con['wlobscd'])
if '김포' in con['obsnm']:
print(con['obsnm'], con['wlobscd'])
if '소양' in con['obsnm']:
print(con['obsnm'], con['wlobscd'])
if '충주' in con['obsnm']:
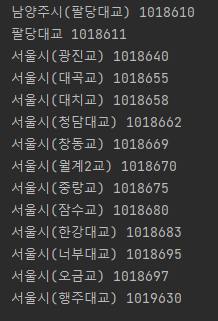
print(con['obsnm'], con['wlobscd'])조금 더 자세하게 찍어보면 다음과 같은 다리들의 정보가 있음을 알 수 있다 ( 사진보다 더 많다)
5. 특정 다리의 수위 데이터 요청
5-1. 광진교, 팔당대교, 전류리의 2012~2022년 7월까지의 수위 데이터 요청
bridge = {
"서울시(광진교)": 1018640,
"남양주시(팔당대교)": 1018610,
"김포시(전류리)": 1019675,
}# bridge 변수에 저장한 다리의 수위 자료 요청
for name, code in bridge.items():
for year in tqdm(range(2012, 2023)):
ms, me = (5, 11) if year != 2022 else (5, 8)
for month in range(ms, me):
weekday, end = calendar.monthrange(year, month)
sdate = f"{year}{month:02}010000"
edate = f"{year}{month:02}{end:02}2350"
url = f"http://api.hrfco.go.kr/{SERVICE_KEY}/waterlevel/list/10M/{code}/{sdate}/{edate}.json"
response = requests.get(url)
df = pd.DataFrame(response.json()['content'])
df.to_csv(f"./level/{year}{month:02}_{name}.csv")
time.sleep(1)
5-2. 청담대교, 잠수교, 한강대교, 행주대교의 2022년 7월까지의 수위 데이터 요청
answer_bridge = {
"서울시(청담대교)" : 1018662,
"서울시(잠수교)" : 1018680,
"서울시(한강대교)" : 1018683,
"서울시(행주대교)" : 1019630,
}# bridge 변수에 저장한 다리의 수위 자료 요청
for name, code in answer_bridge.items():
year = 2022
ms, me = (5, 11) if year != 2022 else (6, 8)
for month in range(ms, me):
weekday, end = calendar.monthrange(year, month)
sdate = f"{year}{month:02}010000"
edate = f"{year}{month:02}{end:02}2350"
url = f"http://api.hrfco.go.kr/{SERVICE_KEY}/waterlevel/list/10M/{code}/{sdate}/{edate}.json"
response = requests.get(url)
df = pd.DataFrame(response.json()['content'])
df.to_csv(f"./level/{year}{month:02}_{name}.csv")
time.sleep(1)6. 데이터 합치기
# datetime string to unixtime integer
def str_to_unixtime(str_time):
str_time = str(str_time)
temp_time = "{}-{}-{} {}:{}".format(str_time[:4], str_time[4:6], str_time[6:8], str_time[8:10], str_time[10:12])
return int(pd.Timestamp(temp_time).timestamp())
def make_one_file(filepaths, bridge_code):
files = []
for filepath in filepaths:
files.append(pd.read_csv(filepath))
df = files[0]
for file in files[1:]:
df = df.append(file)
df["time"] = df["ymdhm"].apply(str_to_unixtime)
df.rename(columns={"wl" : "wl_{}".format(bridge_code)}, inplace=True)
df.rename(columns={"fw" : "fw_{}".format(bridge_code)}, inplace=True)
return df[[ "time", "wl_{}".format(bridge_code), "fw_{}".format(bridge_code)]]-
wl : water level 로 수위 데이터이다.
-
fw: flowing water로 유량 데이터이다.
'위에서 받아온 한 달 기준으로 잘려있는 데이터들을 files라는 한 파일에 전부 몰아서 넣어준다'
는 내용의 함수
gimpo = make_one_file(glob("./level/*_김포시(전류리).csv"), "1019675")
seoul = make_one_file(glob("./level/*_서울시(광진교).csv"), "1018640")
namyang = make_one_file(glob("./level/*_남양주시(팔당대교).csv"), "1018610")gimpo = gimpo.drop(["fw_1019675"], axis=1)
gimpo = gimpo.sort_values(by="time")
seoul = seoul.sort_values(by="time")
namyang = namyang.sort_values(by="time")김포시 전류리의 경우 fw의 결측값이 너무 많아 drop 해주었다.
final_external = pd.concat([gimpo, seoul.drop(["time"], axis=1), namyang.drop(["time"], axis=1)], axis=1)학습에 사용될 광진대교, 팔댕대교, 전류리의 데이터를 concat하여 하나의 final_external로 만들어주었다.
7. 데이터 저장
def convert_float(x):
if x == "":
return np.nan
else:
try:
return float(x)
except:
return np.nanfinal_external = final_external.applymap(convert_float)final_external.to_csv("gimpo_seoul_namyang.csv", index=False)final_external 파일을 float 형태로 바꿔준다음 csv파일로 저장한다.
8. 정답 데이터(솔루션) 저장
answer_file = []
for ind, bridge_name in enumerate(["잠수교", "청담대교", "한강대교", "행주대교"]):
filepaths = glob("./level/*_서울시({}).csv".format(bridge_name))
files = []
for filepath in filepaths:
temp = pd.read_csv(filepath)
files.append(temp)
answer_df = files[0]
for file in files[1:]:
answer_df = answer_df.append(file)
bridge_code = answer_df.wlobscd.iloc[0]
answer_df["time"] = answer_df["ymdhm"].apply(str_to_unixtime)
answer_df.rename(columns={"wl": "wl_{}".format(bridge_code)}, inplace=True)
answer_df.rename(columns={"fw": "fw_{}".format(bridge_code)}, inplace=True)
answer_df = answer_df[["time", "wl_{}".format(bridge_code)]]
if ind == 0:
answer_file = answer_df
else:
answer_file = pd.merge(answer_file, answer_df, on="time")
answer_file.head()광진대교, 팔당대교, 전류리와 같은 방법으로 정답 데이터들 또한 끌어와서 합쳐준다.
(정답 데이터의 경우 수위 데이터만 있으면 되기 때문에 wl 데이터만 있어도 된다.)
answer_file을 위와 같이 찍어보면
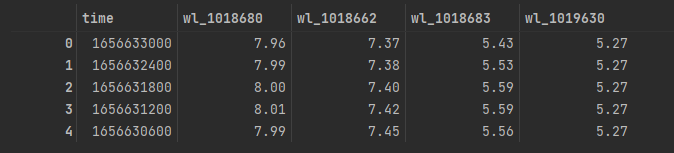
위와 같은 결과를 얻을 수 있다.
answer_file.index = pd.to_datetime(answer_file.timestamp, unit="s")
answer_file.sort_index(inplace=True)
answer_file = answer_file.iloc[:len(sample_submission), :]7월 18일 까지의 데이터만 필요하기 때문에
sample_submission의 길이만큼 잘라준다.
datetime으로 index를 바꾸어 찍어보면
다음과 같이 잘 잘렸음을 알 수 있다.
answer_file.isnull().any()기특하게도 정답 데이터니까 결측치가 없는 것을 확인할 수 있다.
answer_file.to_csv("./solution.csv", index=False)마지막으로 answer_file을 csv 파일로 만들어주면
학습에 필요한 외부 데이터들을 모두 사용 가능한 csv 파일로 예쁘게 가공하는 작업이 끝난다.
