1. 모델링
- 모든 모델은 LGBM 모델을 사용
- 하이퍼 파라미터 및 데이터 전처리를 계속 바꾸어가며 여러번 실험하였다
- 하이퍼 파라미터는 optuna를 통하여 탐색 (optuna는 다음 편에서 계속)
- optuna의 목적 함수는 validation set의 RMSE점수 활용!- test 데이터 활용하지 않음 (Leakage 아님!)
models = []
scores = []
for i, col in enumerate(target_columns):
X_train, X_valid, y_train, y_valid = train_test_split(shifted_X_train, shifted_y_train[:, i], test_size=0.2, random_state=42)
# kfold
from sklearn.model_selection import TimeSeriesSplit
from sklearn.model_selection import KFold
from xgboost import XGBRegressor
#n_fold = 5
#kf = KFold(n_splits=n_fold, shuffle=True, random_state=42)
#for i, col in tqdm(enumerate(target_columns)):
# fold_scores = []
# drop_X_train = shifted_X_train.copy()
# drop_X_test = shifted_X_test.copy()
# drop_X_train = drop_X_train[feature_importance.loc[lambda x: x[col] > 500]["feature"].values]
# drop_X_test = drop_X_test[feature_importance.loc[lambda x: x[col] > 500]["feature"].values]
# for train_idx, valid_idx in tqdm(kf.split(drop_X_train, shifted_y_train[:, i])):
# X_train, X_valid, y_train, y_valid = train_test_split(shifted_X_train, shifted_y_train[:, i], test_size=0.2, random_state=42)
# X_train = drop_X_train.iloc[train_idx, :]
# X_valid = drop_X_train.iloc[valid_idx, :]
# y_train = shifted_y_train[train_idx, i]
# y_valid = shifted_y_train[valid_idx, i]
params = {"objective": "regression",
"metric": "rmse",
"n_jobs": -1,
"random_state": 42,
'n_estimators': 4000, 'num_leaves': 167, 'min_child_samples': 18, 'learning_rate': 0.011205969159912312, 'bagging_fraction': 0.9268973395667537, 'feature_fraction': 0.8029296666198301, 'bagging_freq': 3, 'feature_fraction_seed': 7, 'bagging_seed': 2, 'drop_seed': 6, 'data_random_seed': 7, 'boosting_type': 'gbdt', 'early_stopping_rounds': 38
}
# lgb_model = LGBMRegressor(random_state=42, n_jobs=-1, n_estimators=5000)
# lgb_model.fit(X_train, y_train, verbose=500, eval_set=[(X_valid, y_valid)], eval_metric="rmse",
# early_stopping_rounds=20)
lgb_model = LGBMRegressor(**params)
lgb_model.fit(X_train,y_train, verbose=500, eval_set=[(X_valid, y_valid)], eval_metric="rmse",)
# models.append(lgb_model)
# test_pred = lgb_model.predict(drop_X_test)
test_pred = lgb_model.predict(shifted_X_test)
rmse_score = rmse(solution[col].values, test_pred)
#fold_scores.append(rmse_score)
#print("{} : {}".format(col, np.mean(np.array(fold_scores))))
print("{} : {}".format(col, rmse_score))
#scores.append(np.mean(np.array(fold_scores)))
print("mean : {}".format(np.mean(np.array(scores))))- 이 코드에서 하이퍼 파라미터와 데이터를 바꾸어가며 계속 실험했다.
- Kfold의 흔적은 모두 주석처리 하였다.
2. submission
#kfold를 했을 때 사용되는 submission
for i, col in enumerate(target_columns):
temp = []
for j, model in enumerate(models[i*5:i*5+5]):
if j == 0:
temp = np.array(model.predict(shifted_X_test))
else:
temp = np.append(temp, model.predict(shifted_X_test))
print(rmse(temp.reshape(5, -1).mean(axis=0), solution[col].values))
sample_submission[col] = temp.reshape(5, -1).mean(axis=0)#kfold를 하지 않았을 때 사용되는 submission
for i, col in enumerate(target_columns):
sample_submission[col] = models[i].predict(shifted_X_test)submission = sample_submission.drop(["timestamp"], axis=1)
submission.to_csv("???", index=False)3. ensemble 모델 소개
모델 0
- timestamp 행을 제외한 행들은 170분 전까지 활용
- timestamp는 10분 전까지의 데이터만 활용
- 김포시 전류리의 수위 데이터 제거
- 조위 데이터 제거
- 하이퍼 파라미터:{'n_estimators': 5000, 'num_leaves': 111, 'min_child_samples': 5, 'learning_rate': 0.01607068962363006, 'bagging_fraction': 0.9537414866849975, 'feature_fraction': 0.8391788379788974, 'bagging_freq': 2, 'feature_fraction_seed': 5, 'bagging_seed': 4, 'drop_seed': 6, 'data_random_seed': 6, 'boosting_type': 'gbdt', 'early_stopping_rounds': 45}
<모델1>
- 모델0과 다르게 timestamp 역시 170분 전까지의 데이터를 활용
- 김포시 전류리의 수위 데이터 제거
- 조위 데이터 제거
- 하이퍼 파라미터: {'n_estimators': 5000, 'num_leaves': 170, 'min_child_samples': 12, 'learning_rate': 0.020066250910486232, 'bagging_fraction': 0.9075081291774554, 'feature_fraction': 0.8008354016930453, 'bagging_freq': 6, 'feature_fraction_seed': 2, 'bagging_seed': 4, 'drop_seed': 2, 'data_random_seed': 5, 'boosting_type': 'gbdt', 'early_stopping_rounds': 40}
<모델2>
- 김포시 전류리 수위 데이터 활용
- 조위 데이터를 제거
- 하이퍼 파라미터: {'n_estimators': 4000, 'num_leaves': 167, 'min_child_samples': 18, 'learning_rate': 0.011205969159912312, 'bagging_fraction': 0.9268973395667537, 'feature_fraction': 0.8029296666198301, 'bagging_freq': 3, 'feature_fraction_seed': 7, 'bagging_seed': 2, 'drop_seed': 6, 'data_random_seed': 7, 'boosting_type': 'gbdt', 'early_stopping_rounds': 38}
<모델3>
-
모델2 +
- 24시간 기준으로 만든 시간 데이터를 활용 - n_splits를 5로하여 kfold해줌 - 각 다리마다 5개의 모델이 생성 - 각 다리의 모델 결과값의 평균을 최종 모델3의 결과값으로 도출
<모델4>
-
<모델 3> +
24시간 기준으로 만든 시간 데이터를 제거
<모델5>
-
<모델 4> +
조위 데이터를 170분 전까지 활용
4. ensemble 실행
[Weighted mean averaging]
- 모델 0~4의 각 결과값에 각각 가중치를 두어 평균을 내는 방식
submission0 = pd.read_csv('lgb_optuna_0.csv') #모델 0 = lgb_optuna_0
submission1 = pd.read_csv('lgb_optuna_1.csv') #모델 1 = lgb_optuna_1
submission2 = pd.read_csv('lgb_optuna_2.csv') #모델 2 = lgb_optuna_2
submission3 = pd.read_csv('lgb_cv.csv') #모델 3 = lgb_cv
submission4 = pd.read_csv('lgb_cv_important1000.csv') #모델 4 = lgb_cv_important1000모델 0~4의 결과값을 csv 파일로 만들어서 submission 0~4 으로 받아온다
def datetime_index(df):
df["timestamp"] = df["ymdhm"].apply(str_to_unixtime)
df.index = pd.to_datetime(df["timestamp"], unit="s")
df = df.drop(["ymdhm", "timestamp"], axis=1)
return dfsubmission0 = datetime_index(submission0)
submission1 = datetime_index(submission1)
submission2 = datetime_index(submission2)
submission3 = datetime_index(submission3)
submission4 = datetime_index(submission4)편리하게 가공하여 평균치를 내주기 위해 datetime으로 index를 바꾸어준다
# calculate weighted mean by each columns
def weighted_mean(df, weigths):
return np.average(df, axis=1, weights=weigths)numpy에서 weights를 설정해두면 알아서 average를 해준다
(친절한 numpy)
for i, (col_name, weigths) in enumerate(zip(submission0.columns, [[2, 3, 2, 3, 0], [2, 0, 0, 8, 0], [2, 1, 2, 5, 0], [2, 0, 0, 0, 8]])):
sample_submission[col_name] = weighted_mean(pd.DataFrame([submission0[col_name], submission1[col_name], submission2[col_name], submission3[col_name], submission4[col_name]]).T, weigths=weigths)이렇게 weighted mean ensemble 해준다.

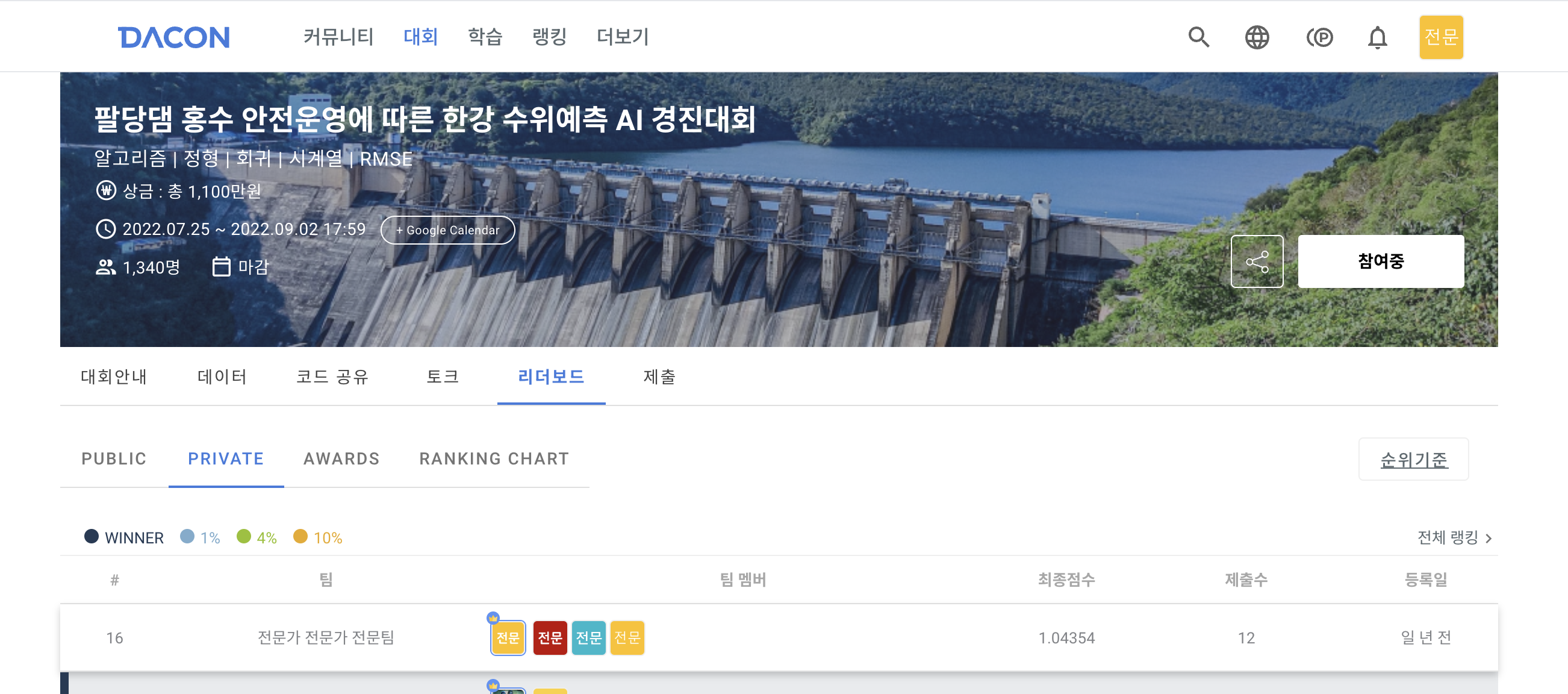
파란색으로 채워진 칸은 점수가 가장 잘 나온 모델의 점수이다.
이를 합쳐 죄종 제출할 submission 파일을 만들었다.
