
배열이란?
- 메모리 상에 원소를 연속하게 배치한 자료구조

배열의 성질
- O(1)에 k번째 원소를 확인/변경 가능
- 메모리 상에 원소를 연속하게 배치한 자료구조이므로, k번 인덱스값만 이용하면 해당 원소값 확인 가능
- 위의 사진을 토대로, k=5 일때 원소값은 1이다. 그리고 arr[k] = 5라는 값을 한번에 알 수 있으니 O(1)
- 추가적으로 소모되는 메모리의 양(=overhead)가 거의 없음
- 자바에서는 배열의 크기를 지정하여 생성하고, 생성한 이후에는 배열 크기 증/감 불가
- 필요한 만큼만 사용하기에 낭비되는 메모리 양이 적음
- Cache hit rate가 높음
- 참조하려는 데이터가 캐시에 존재 - hit
- 참조하려는 데이터가 캐시에 존재X - miss = hit / (hit + miss) = hit된 횟수 / 전체 참조 횟수 = Cache hit rate
- 캐시가 적중일 때 캐시 메모리 데이터를 CPU레지스터에 복사하기 떄문에 자주 사용되는 메모리들은 배열의 앞쪽으로 이동 . → hit 확률 높아짐
- 메모리 상에 연속한 구간을 잡아야해서 할당에 제약이 걸림
배열의 기능과 구현
배열은 수정, 삭제, 추가 정도의 기능이 있다.
-
수정 : O(1), 원하는 인덱스의 값을 다른 값으로 넣어주면 된다 .
-
삭제 : O(1), 마지막 원소 제거시 배열의 길이를 줄이면 됨
-
추가 : 추가는 두 가지 방향이 있다. 배열 중간의 임의의 위치에 원소를 추가하거나, 맨 뒤에 추가하거나.
-
맨 뒤에 추가 : 맨 뒤에 추가는 배열의 맨 뒤에 넣기만 하면 돼서 O(1) → 배열이 가득차지 않았을 때 가정
-
임의의 위치에 원소 추가 : 여기가 중요. O(N)이 된다. 왜냐 사이즈를 늘리고, 해당 인덱스에 원하는 데이터를 넣고, 그 뒤에 인덱스부터 뒤로 다 밀어야하기 때문.
- 추가하는 위치가 배열 길이에 가까울 수록 시간 down, 길 수록 up
- 평균 O(2/N) → O(N)
- 임의의 위치 제거또한 마찬가지
정리하자면
1. 임의의 위치에 있는 원소를 확인/변경 = O(1)
2. 원소를 끝에 추가 = O(1)
3. 마지막 원소를 제거 = O(1)
4. 임의의 위치에 원소를 추가 / 임의 위치의 원소 제거 = O(N)
해당 내용 실습
class Array {
static int idx = 3;
static int num = 6;
static int[] arr = new int[10];
public static void main(String[] args) {
for (int i = 0; i < arr.length - 1; i++) {
arr[i] = i;
}
check(); // 초기화 상태
//0 1 2 3 4 5 6 7 8 0
insert();
check(); // 임의의 위치 추가 상태
//0 1 2 6 3 4 5 6 7 8
delete();
check(); // 임의의 위치 삭제 상태
//0 1 2 3 4 5 6 7 8 0
}
static void check() {
for (int x : arr) {
System.out.print(x + " ");
}
System.out.println();
}
static void insert() {
for (int i = arr.length - 1; i >= idx; i--) {
int tmp = arr[i - 1];
arr[i] = tmp;
}
arr[idx] = num;
}
static void delete() {
for (int i = idx; i < arr.length - 1; i++) {
int tmp = arr[i + 1];
arr[i] = tmp;
}
arr[arr.length - 1] = 0;
}
}해당 코드를 설명하면 이렇다.
내가 추가/삭제 하고싶은 위치인 인덱스 idx, 사용할 데이터 num , 초기배열인 arr 이 존재한다.
여기서 처음 check 메소드를 실행하면 초기화된 배열을 보여준다.
그 다음 insert 메소드를 실행시키는데, 원하는 인덱스에 데이터를 넣는 방식이다.
해당 로직을 보면 배열의 맨 끝-1에서 idx까지 내려가면서 맨 끝 인덱스 이전 값을 맨 끝 인덱스로 넣어가며 idx 까지 내려가는 방식이다. 그렇게 idx 까지 내려가면 해당 인덱스에 데이터가 빈 채로 있다. 이때 넣고싶은 데이터 num 을 삽입한다.
delete 메소드도 마찬가지이다. insert 와는 반대로 idx 부터 시작해서 arr.length-1 , 맨 끝 인덱스 이전까지 가는데, idx값을 idx+1에 넣는 방식으로 맨 끝 인덱스 -1 까지 간다.
이렇게하면
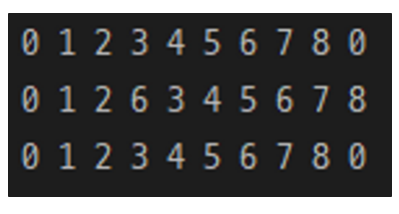
- 체크
- insert
- delete
현재는 배열의 크기가 작은 상태이지만, 배열의 크기가 엄청 크다면 작은 인덱스에 추가/삭제를 하게될 경우 시간을 크게 늘어날 것이다.
데이터 N개에서 평균적으로 2/N개는 이동해야하니 단일 연산에서는 사용하기에 괜찮지만, 다중 연산에서는 시간이 많이 걸리는 것이 사실이다.
p.s) 아래는 시간적 복잡도의 빠른 순서다.
오른쪽으로 갈 수록 오래걸린다고 이해!
💡 *O(1) < O(logN) < O(N) < O(N*logN) < O(N^2) < O(2^N) < O(N!)*
배열을 활용할 수 있는 문제
