
본 프로젝트 자료는 김영한님의 스프링 DB 1편 - 데이터 접근 핵심 원리을 참고 제작됐음을 알립니다.
트랜잭션에 대한 개념
트랜잭션은 직역하면 거래라는 뜻이다. 데이터베이스라는 개념에 거래가 왜 필요할까?
그 이유는 단순 데이터를 저장하기만 하면 간혹 오류가 발생할 수 있다. 예를 들어 A 가 B 에게 5000원을 입금하는 상황일 때, A 는 5000 감소, B 는 5000 증가를 해야하지만 오류가 발생해 A 의 5000이 감소하고 B 의 5000이 증가하지 못한다면 그 프로그램을 운영하는 업체 입장에서는 큰일이 발생하게 된다.
이를 해결하기 위해 나온게 트랜잭션인데,
트랜잭션은 위와 같은 상황에서 각각 따로 행동하는게 아니라 두 개의 행동을 하나의 행동으로 처리된다. 만약 1을 성공했는데 2을 성공하지 못한다면 그 행동은 실패로 처리되어 반환한다. 결과적으로는 사용하는 입장에서 오류 화면만 제공하고 결과값이 바뀌는게 없다는 소리다.
이처럼 모든 작업이 성공해서 결과값을 반영한다면 커밋( Commit )이라 하고, 작업 중에 문제가 생겨 실패로 처리해 거래 이전으로 돌리는 것을 롤백( Rollback )이라 한다.
트랜잭션 ACID
트랜잭션은 ACID 라는게 있다.
- 원자성(Atomicity): 모든 작업을 하나의 작업처럼, 모두 성공하거나 실패해야 한다.
- 일관성(Consistency): 데이터베이스에 정한 무결성 제약 조건을 항상 만족해야 한다.
- 격리성(Isolation): 트랜잭션들이 서로 영향을 미치지 못하게 격리를 한다. 예를 들어 동시에 같은 작업을 하지 못하게 한다는 등, 동시성과 같은 성능 이슈로 트랜잭션 격리 수준을 선택할 수 있다.
- 지속성(Durability): 트랜잭션을 성공적으로 끝낸다면 그 결과를 항상 기록해야 한다. 트랜잭션 처리 도중 시스템에 문제가 생기더라도 로그를 활용해 트랜잭션 내용을 성공적으로 복구해야 한다.
여기서 애매한 부분이 하나 있는데,
격리성(Isolation)
- READ UNCOMMITED(커밋되지 않은 읽기)
- READ COMMITTED(커밋된 읽기)
- REPEATABLE READ(반복 가능한 읽기)
- SERIALIZABLE(직렬화 가능)
트랜잭션 간의 격리성을 보장하려면 트랜잭션을 거의 순서대로 실행해야 한다.
이렇게 되면 동시 처리 성능이 매우 나빠져, 이 문제를 해결하기 위해 위에 격리 수준을 4단계로 나눴다.
데이터베이스 연결 구조와 DB 세션
데이터베이스 서버 연결 구조와 DB 세션에 대해 알아보자.
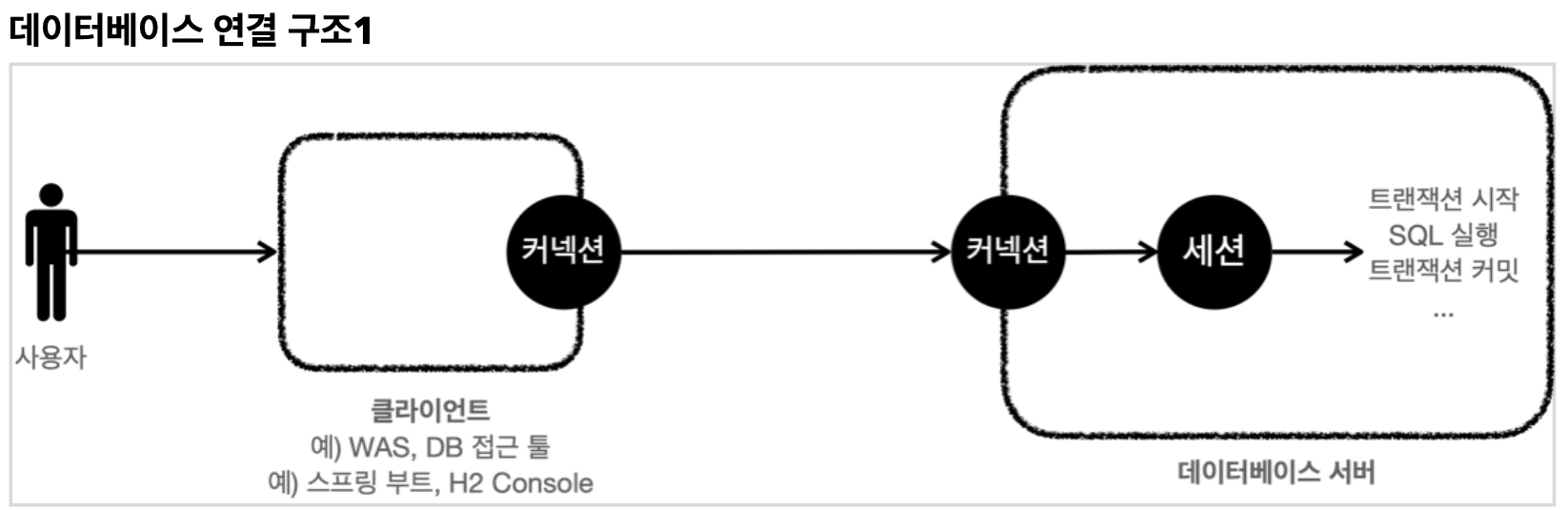
- 사용자가 서버에 접근할 때, 클라이언트는 데이터베이스 서버에 연결 요청하고 커넥션을 맺는다.
- 데이터베이스 서버는 커넥션을 맺게 될 때 내부에 세션을 생성하게 된다. 커넥션은 모든 요청을 이 세션을 통해 실행한다.
- 세션은 트랜잭션을 시작하고, 커밋 또는 롤백을 통해 트랜잭션을 종료한다.
- 사용자가 커넥션을 닫거나, 또는 DBA(DB 관리자)가 세션을 강제로 종료하면 세션은 종료된다.
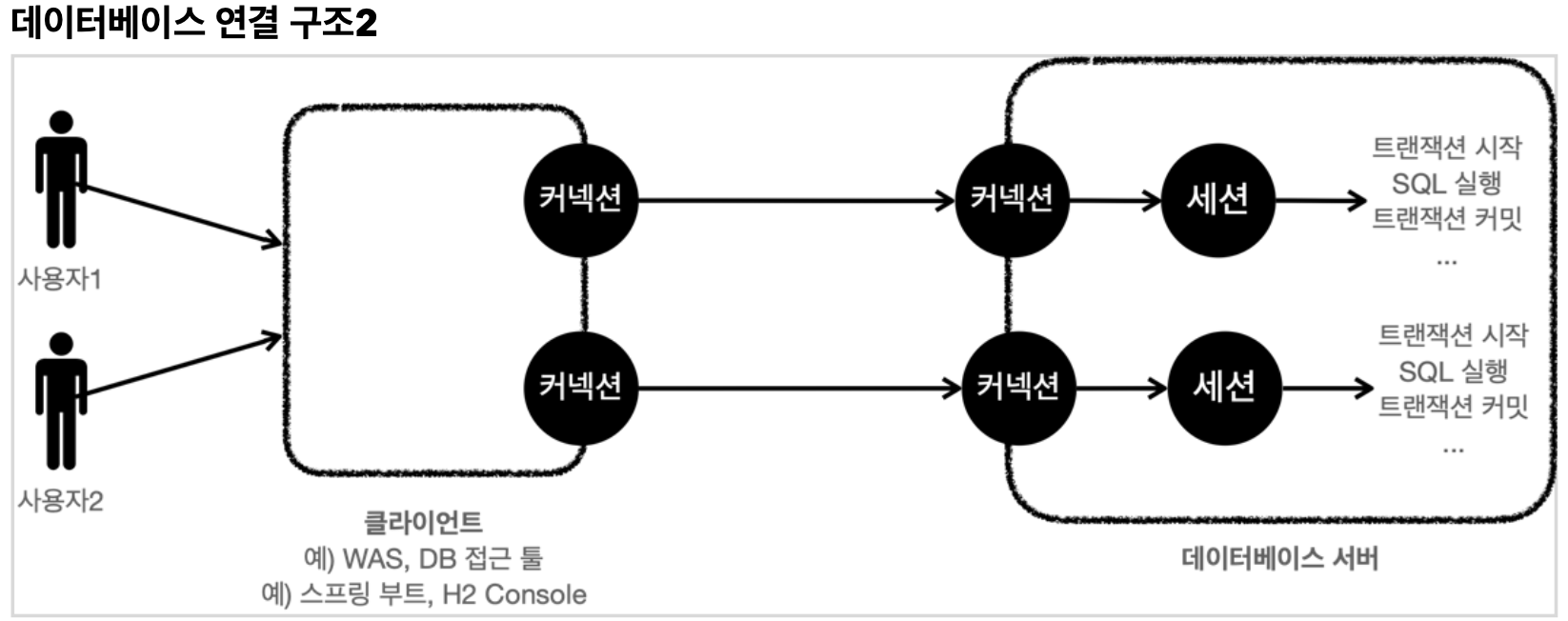
- 커넥션 풀을 활용해 커넥션을 10개를 만든다면, 세션도 10개 만들어진다.
트랜잭션 - DB 예제1 - 개념 이해
트랜잭션 사용법
- 데이터베이스에 결과를 반영하려면 커밋 명령어인 commit 을 호출, 결과를 반영하고 싶지 않다면 롤백 명령어인 rollback 을 호출.
- 커밋을 호출하기 전까지 데이터는 임시 저장된 형태로 남아있다. 이 임시 데이터는 본인이 생성한 세션에만 보이고 다른 세션한테는 보이지 않는다.
- 등록, 수정, 삭제 모두 같은 원리로 동작한다.
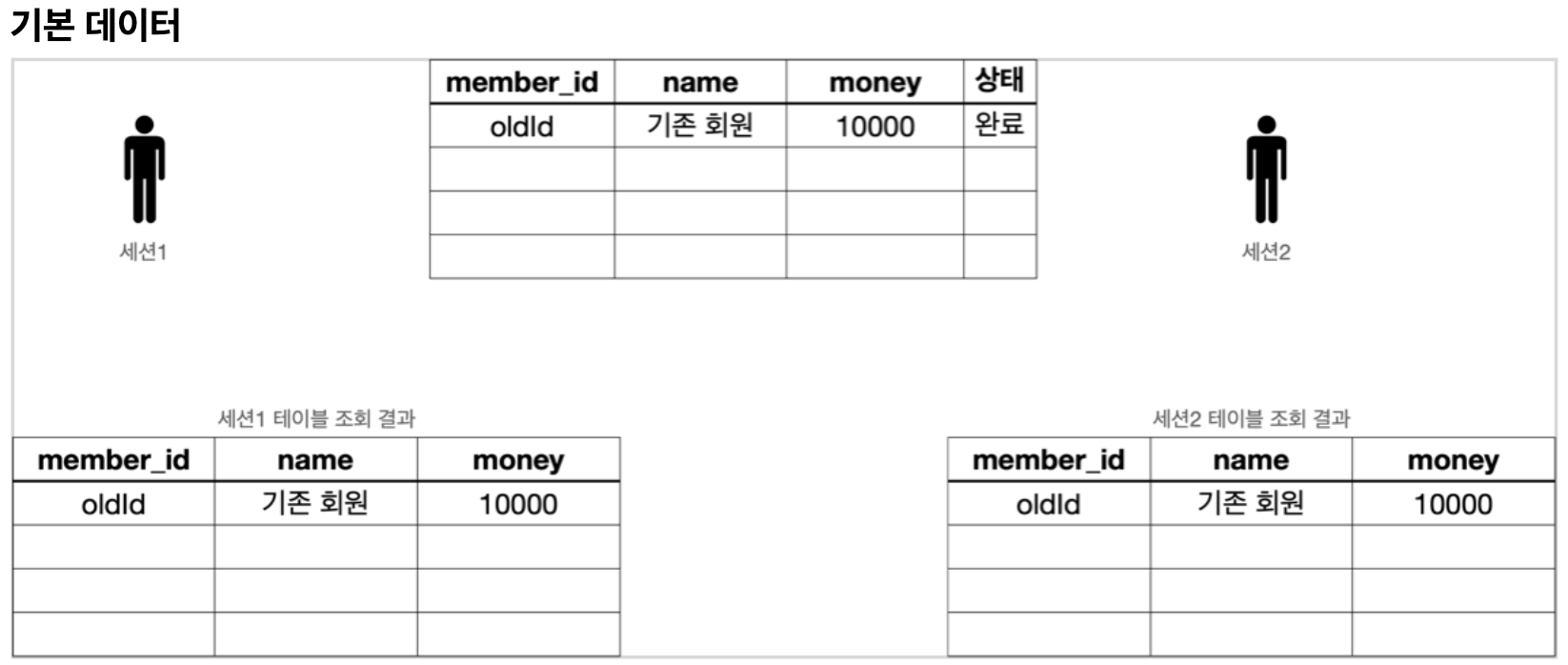
데이터를 넣으면 어떻게 될까?
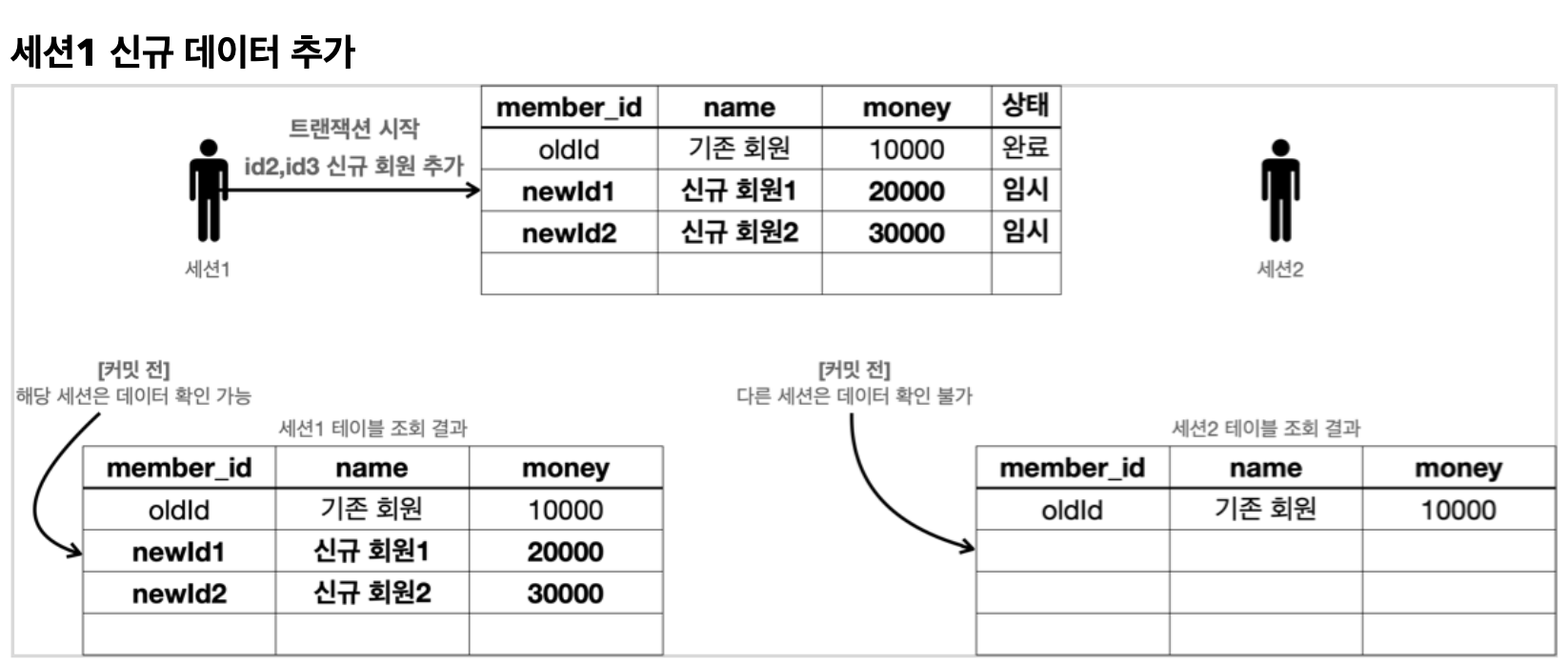
세션1 이 데이터를 커밋하지 않아 데이터들은 임시 데이터로 따로 보관하게 된다. 이 보관된 자료는 세션2 가 조회를 한다고 해서 조회가 가능한 데이터가 아니다. 커밋을 해야만 보인다.
커밋하지 않으면 임시 보관된 데이터들이 다른 사용자에게 조회가 됐을 때 어느 문제점이 생길까?
- 예를 들어서 커밋하지 않는 데이터가 보인다면, 세션2는 데이터를 조회했을 때 신규 회원1, 2가 보일 것이다. 따라서 신규 회원1, 신규 회원2가 있다고 가정하고 어떤 로직을 수행할 수 있다. 그런데 세션1이 롤백을 수행하면 신규 회원1, 신규 회원2의 데이터가 사라지게 된다. 따라서 데이터 정합성에 큰 문제가 발생한다.
- 세션2에서 세션1이 아직 커밋하지 않은 변경 데이터가 보이다면, 세션1이 롤백 했을 때 심각한 문제가 발생할 수 있다. 따라서 커밋 전의 데이터는 다른 세션에서 보이지 않는다.
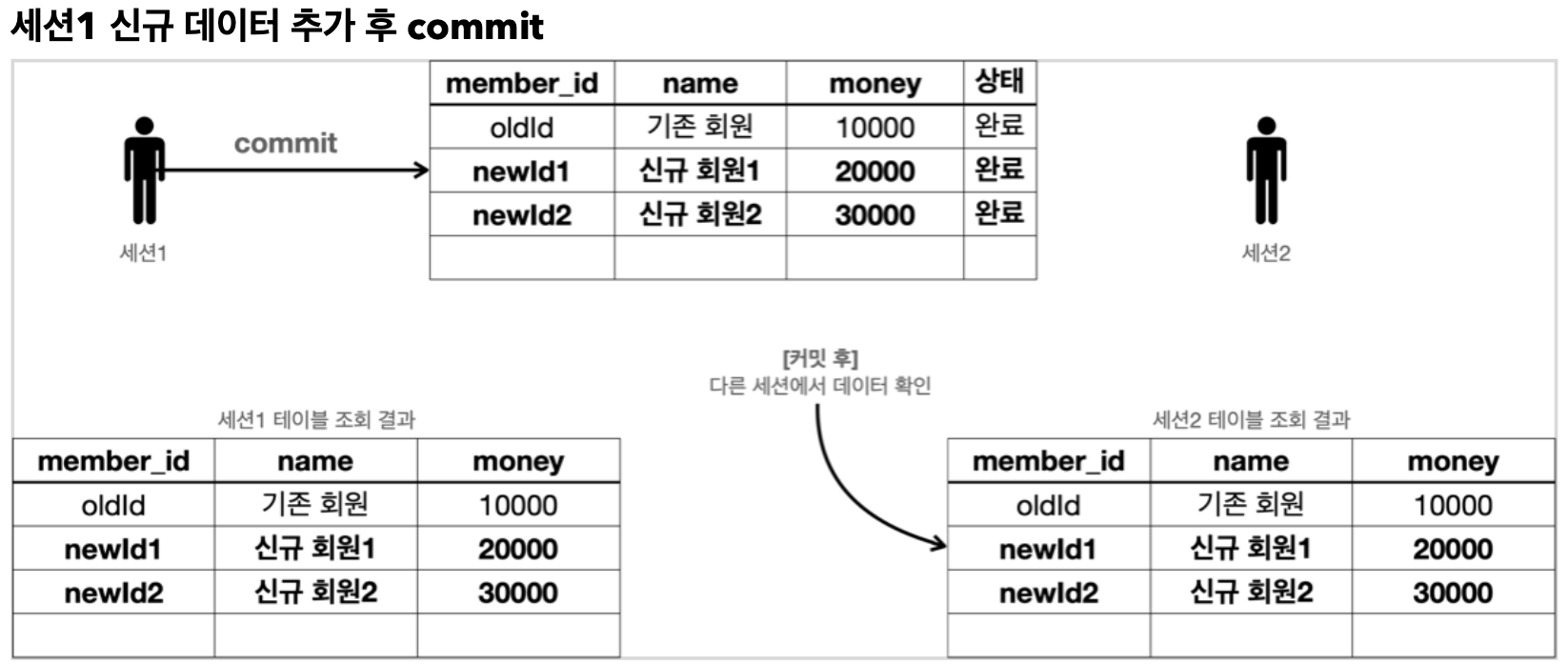
반면 커밋을 할 경우 데이터 보관이 임시에서 확정이 되는 것이기에 다른 세션에서 조회할 때 해당 데이터를 조회할 수 있다.
세션1 신규 데이터 추가 후 rollback
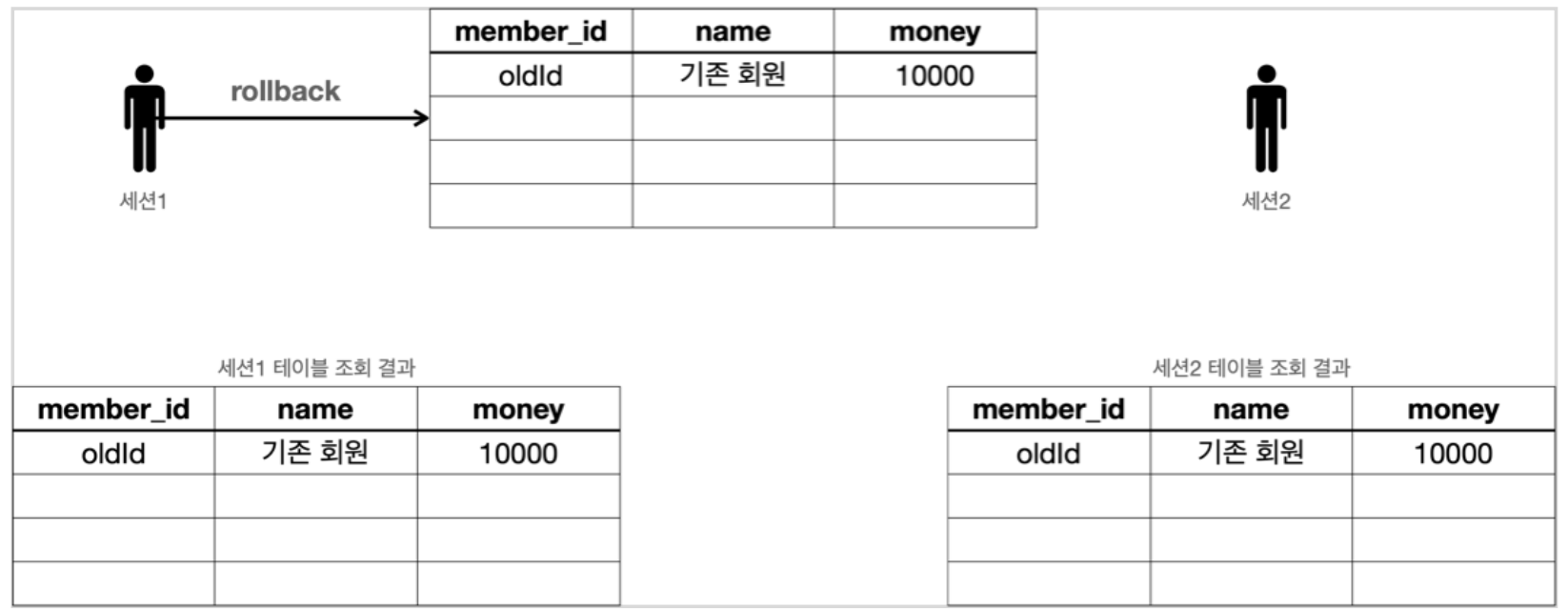
세션1 이 커밋 대신 롤백을 사용하면 본인이 등록한 모든 데이터가 처음 상태로 복구된다.
- 수정하거나 삭제한 데이터도 rollback 을 호출하면 모두 트랜잭션을 시작하기 직전의 상태로 복구된다.
트랜잭션 - DB 예제2 - 자동 커밋, 수동 커밋
자동 커밋, 수동 커밋에 대해 알아보자.
예제 테이블 생성

트랜잭션을 사용하려면 먼저 자동 커밋과 수동 커밋을 이해해야 한다.
우선 자동 커밋은 커밋이나 롤백을 직접 호출하지 않아도 되는 편리함이 있다. 하지만 쿼리를 실행할 때 마다 전부 자동으로 호출해주기에 우리가 원하는 트랜잭션 기능을 제대로 사용할 수 없다.
자동 커밋 설정
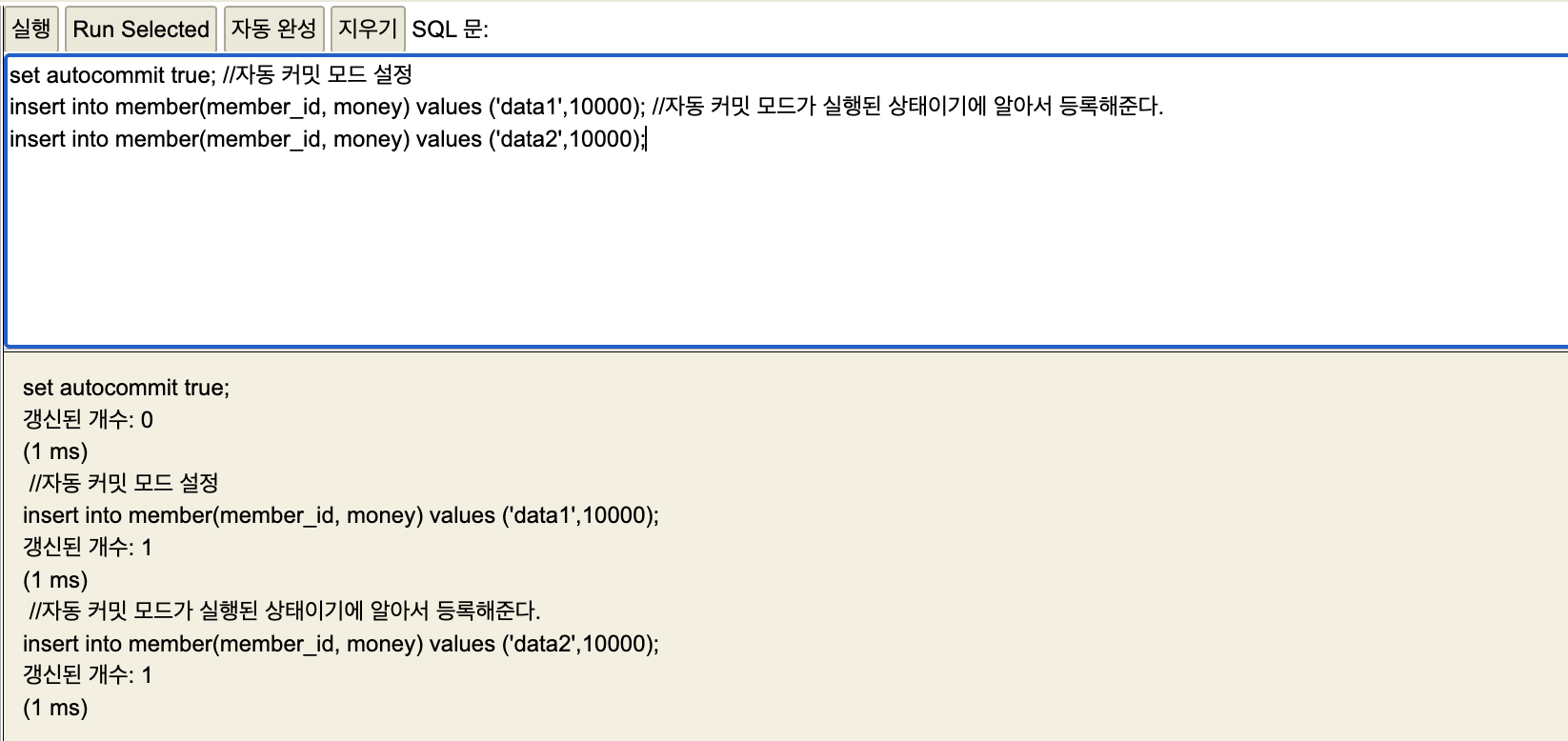
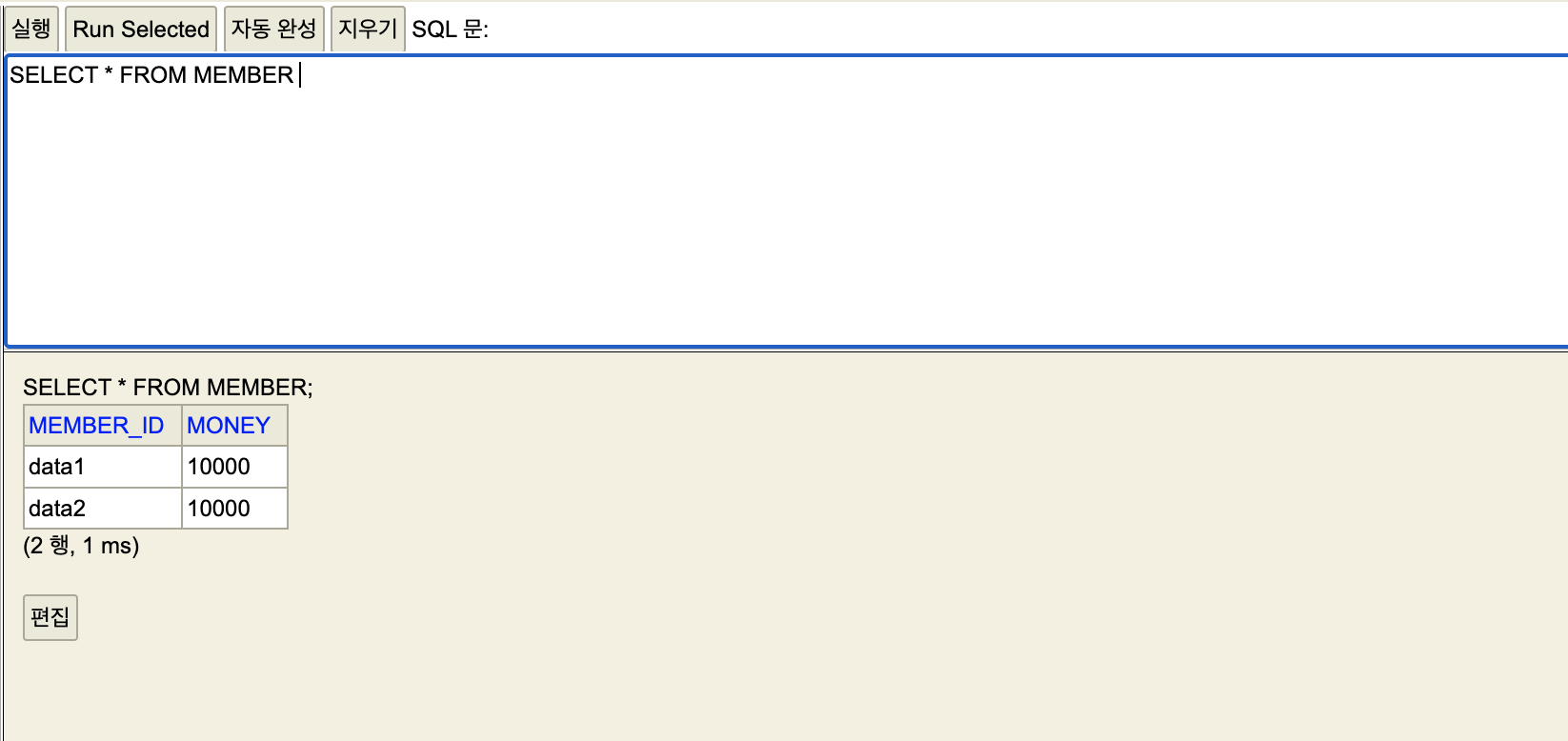
쿼리가 입력만으로도 테이블에 반영한걸 확인 할 수 있다.
수동 커밋 설정
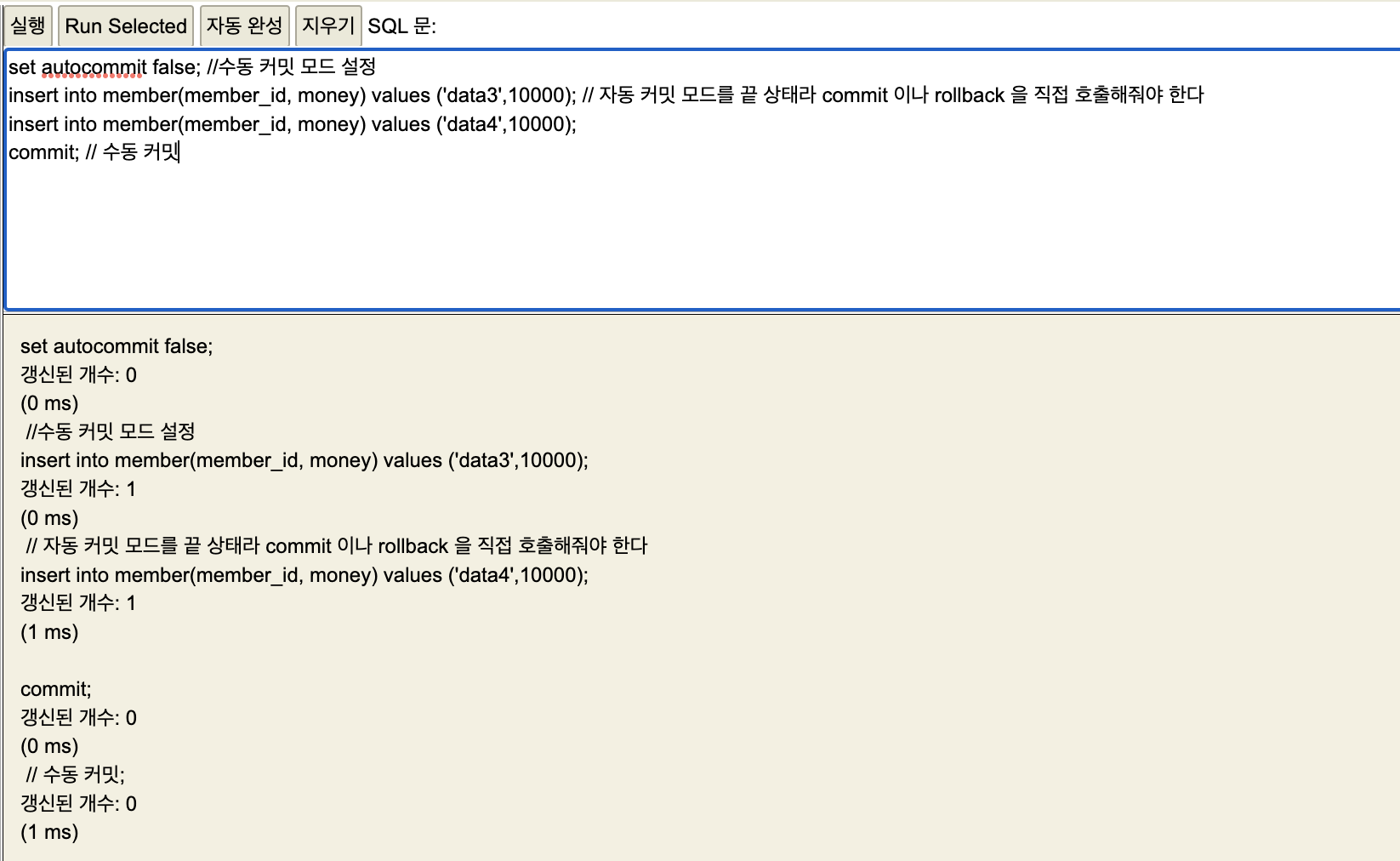
수동같은 경우 다음과 같이 commit; 이나 rollback; 을 직접 입력해야지만 쿼리가 반영된다. 만약 쿼리를 반영할 때 이 둘을 생략했다면 오류가 발생해 데이터가 반영하지 않는다.
트랜잭션 - DB 예제3 - 트랜잭션 실습
지금까지 배운 내용들을 예습을 통해 확인해보자.
2개의 경우를 확인하기 위해 2개의 H2 데이터베이스를 켜두자.
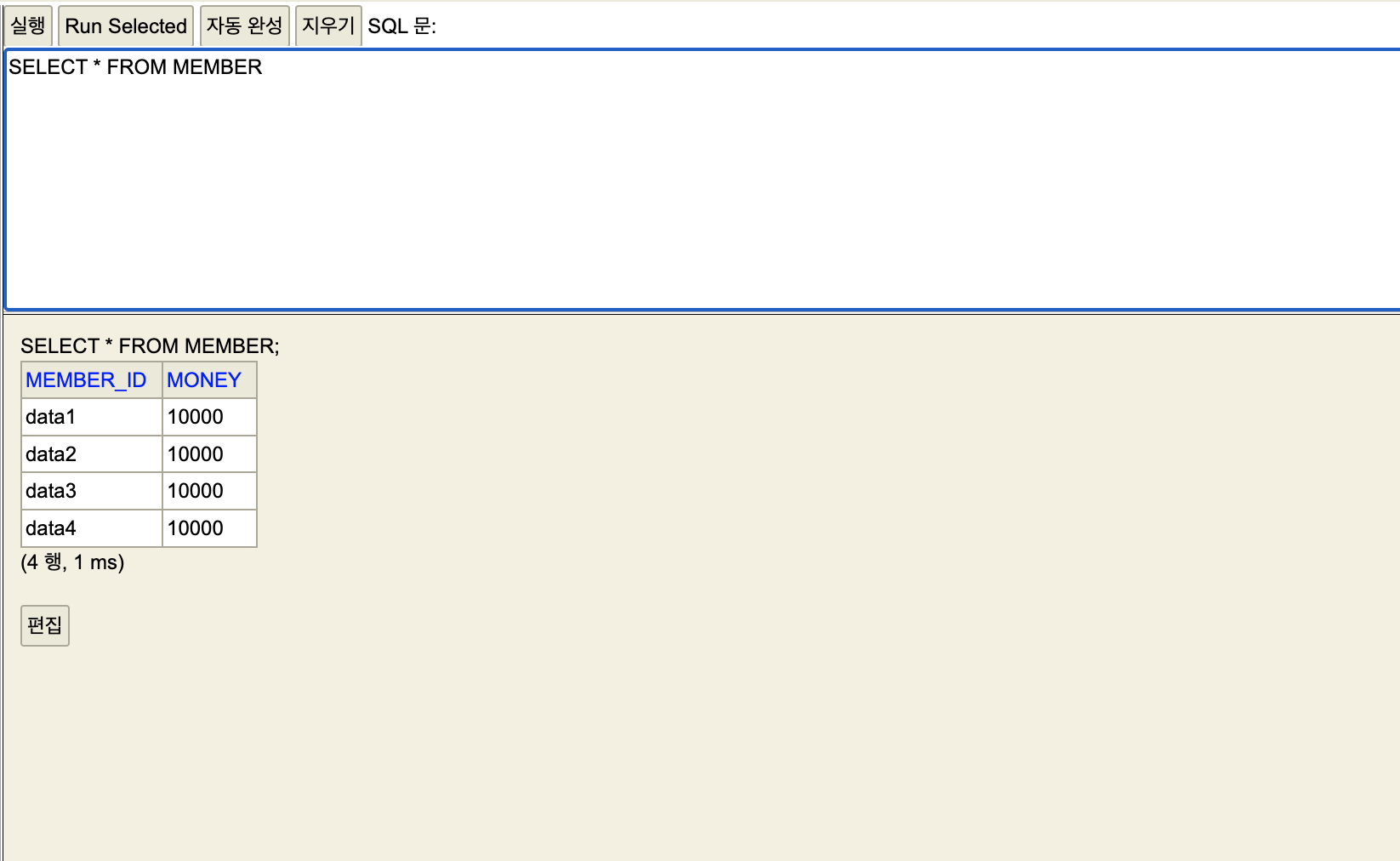
기본 데이터
- 세션1, 세션2 같은 테이블을 공유하고 있다.
- 자동 커밋 모드를 사용했기 때문에 별도로 커밋을 호출하지 않아도 된다.
이제 데이터를 추가하는데 자동 커밋을 풀고 커밋을 하지 않은 상태를 확인해보자.
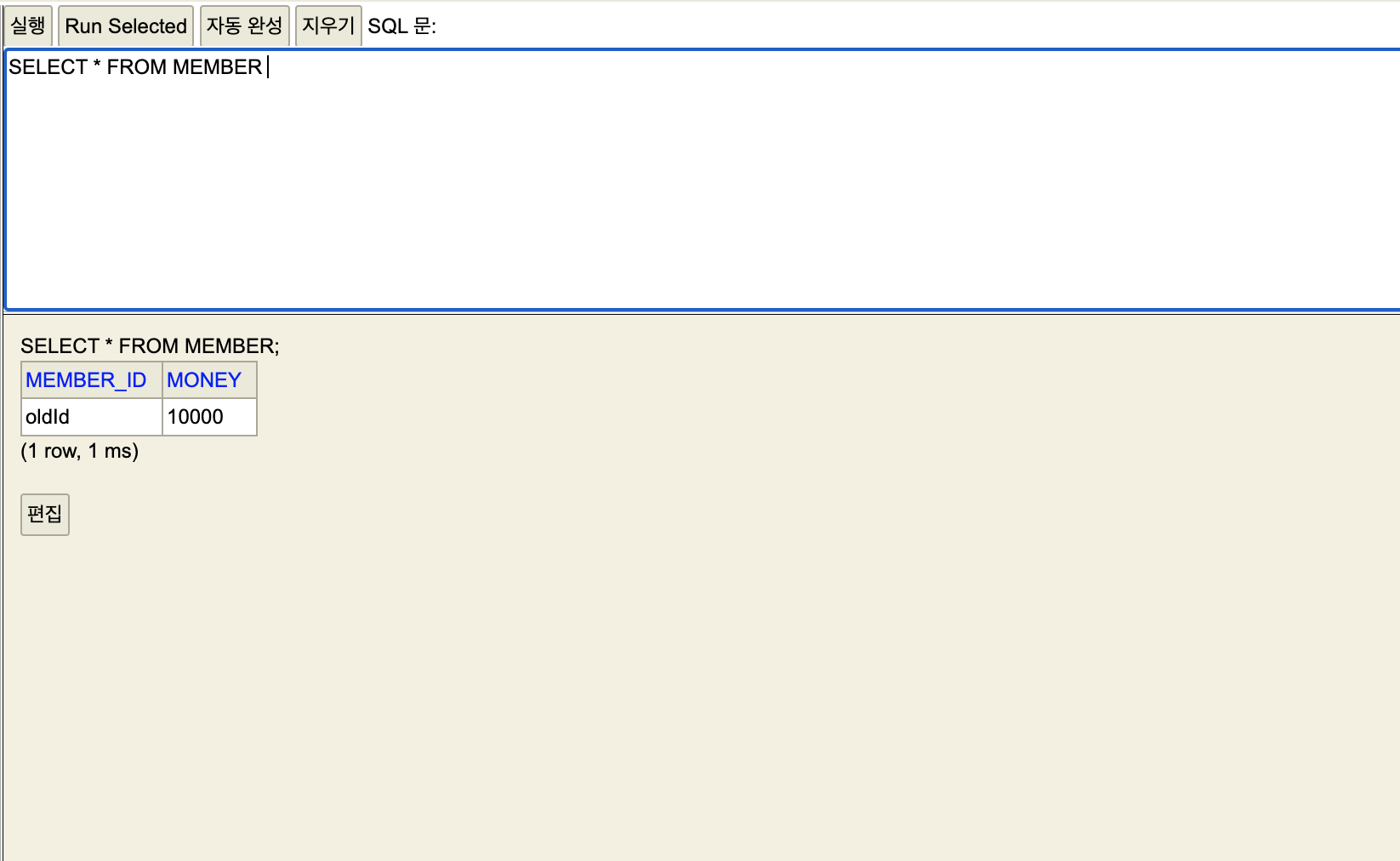
데이터 추가 - 커밋 전
세션1

자동 커밋을 false 로 바꾸고 commit 을 입력하지 않았다.
이러면 세션1 에만 보이는 임시저장 상태다.
세션2
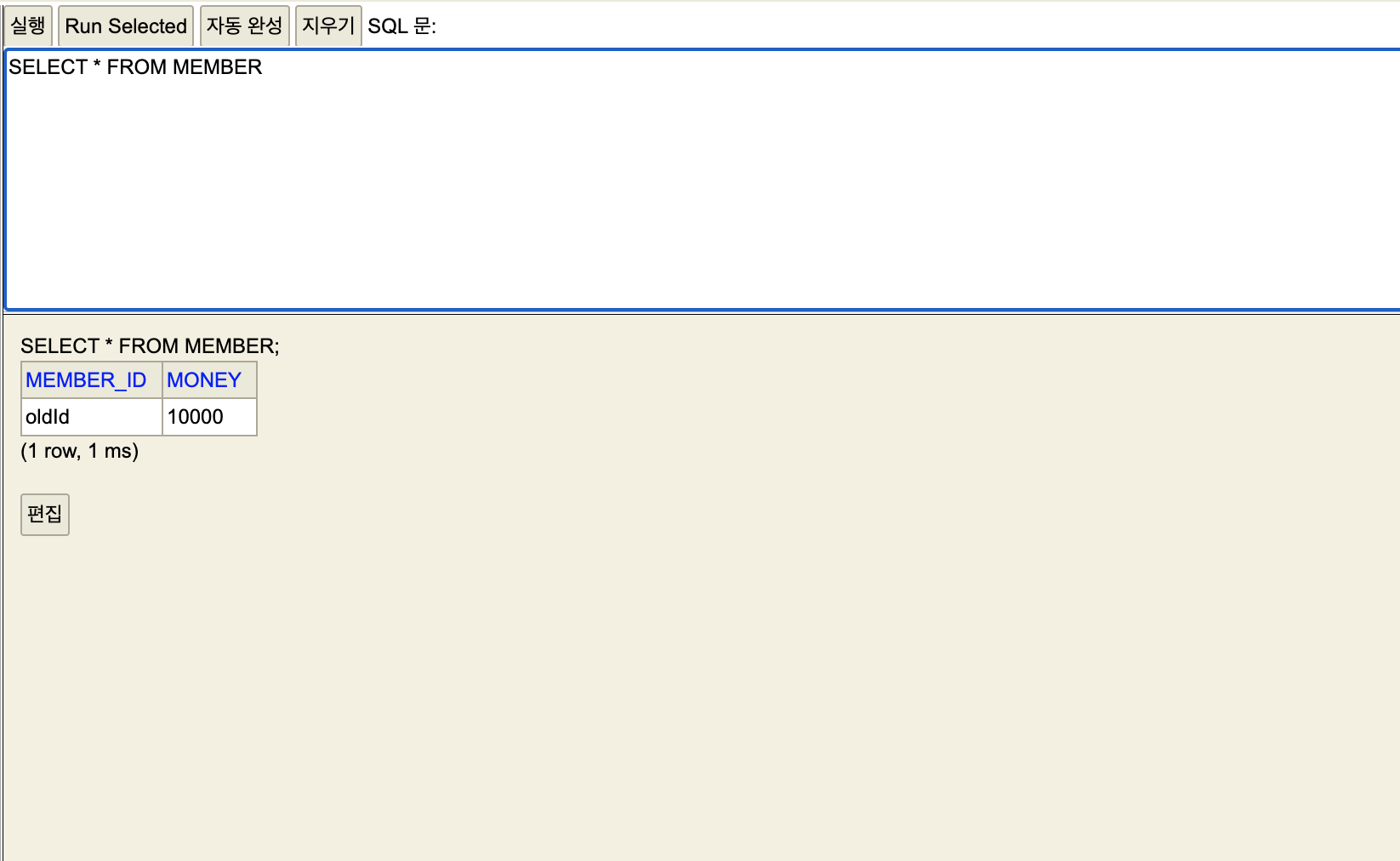
세션2 에서 보이지 않는 것을 확인 할 수 있다.
반대로 커밋을 입력해주면 어떻게 될까?
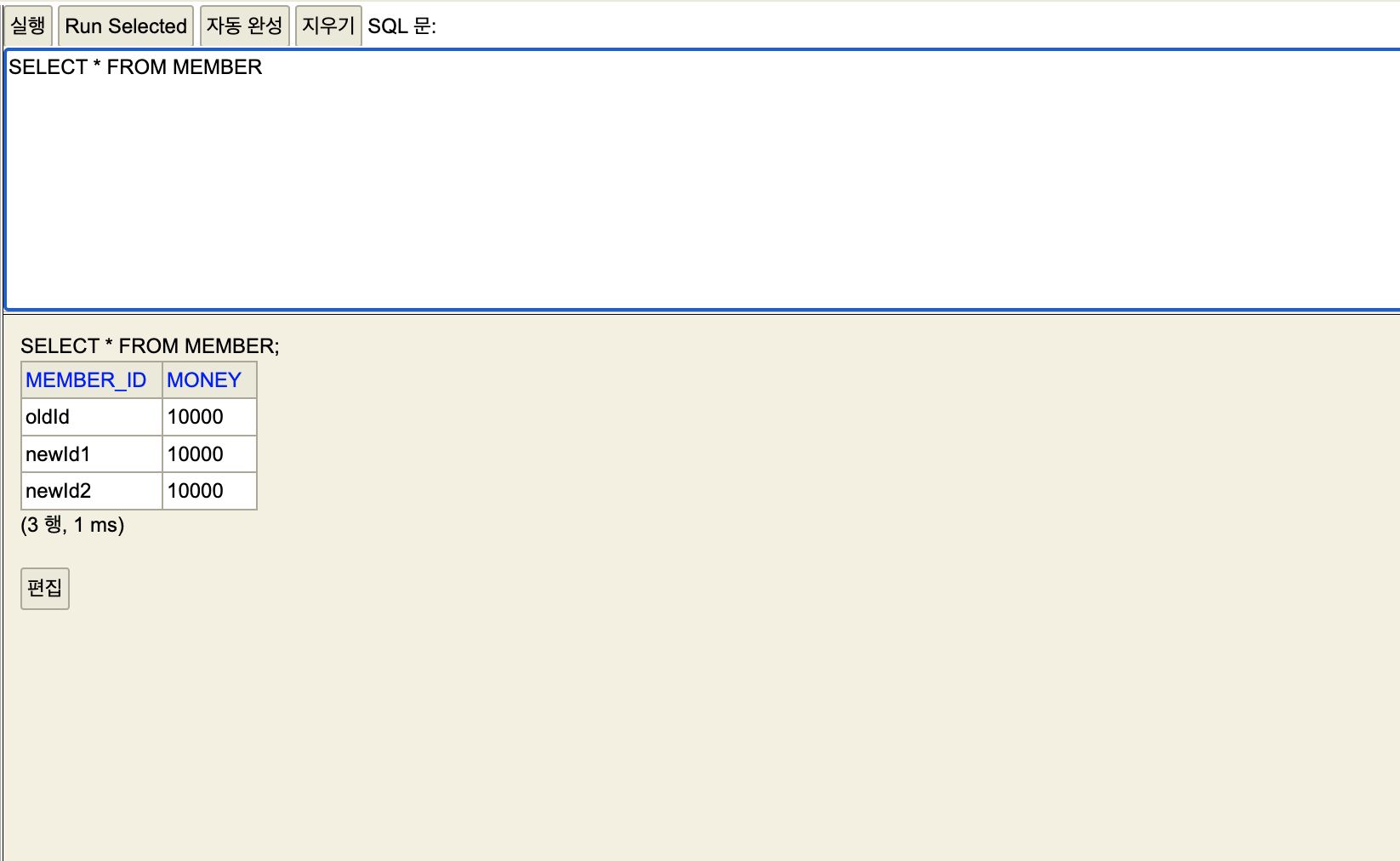
commit 입력
세션1
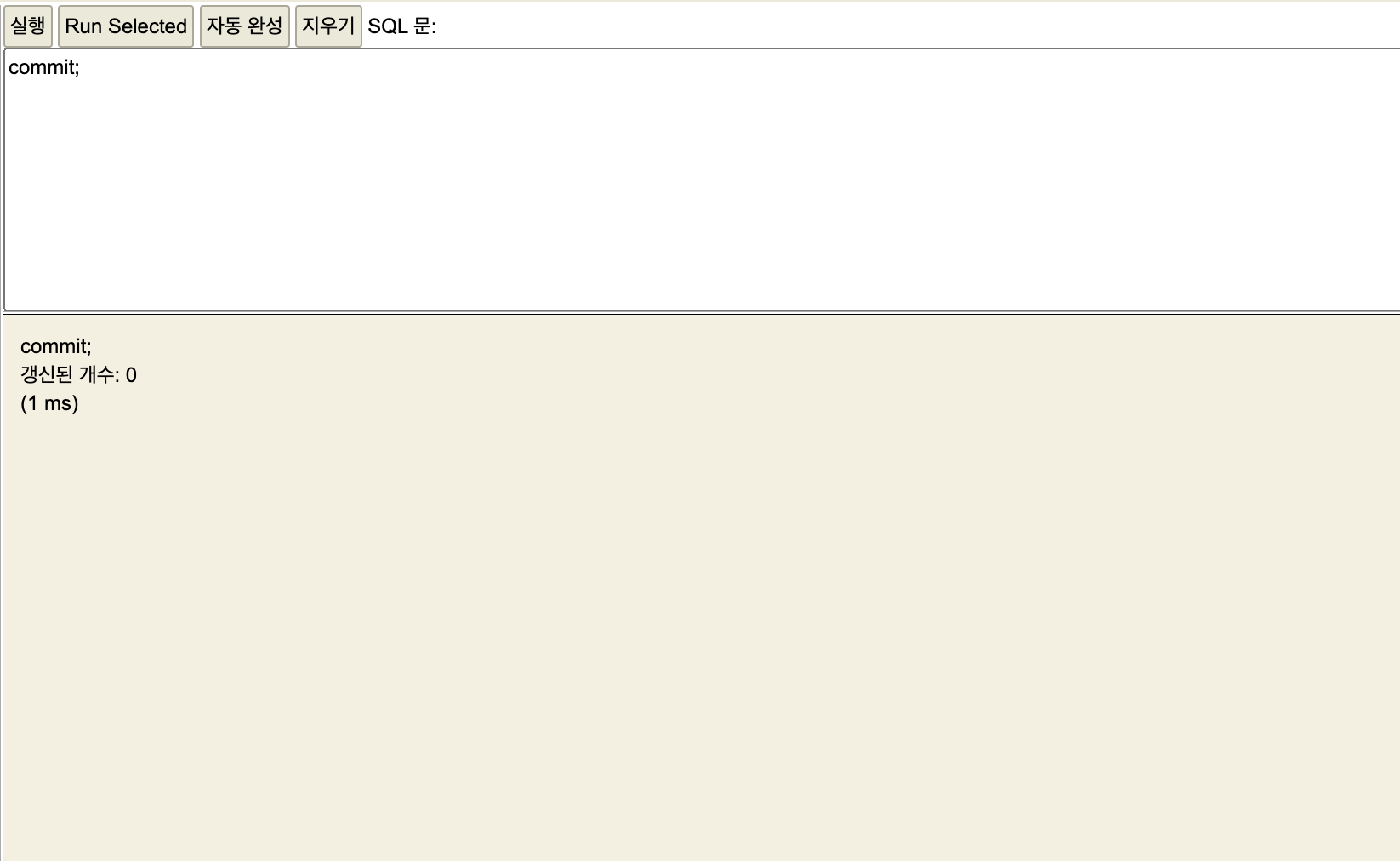
커밋을 입력.
세션2
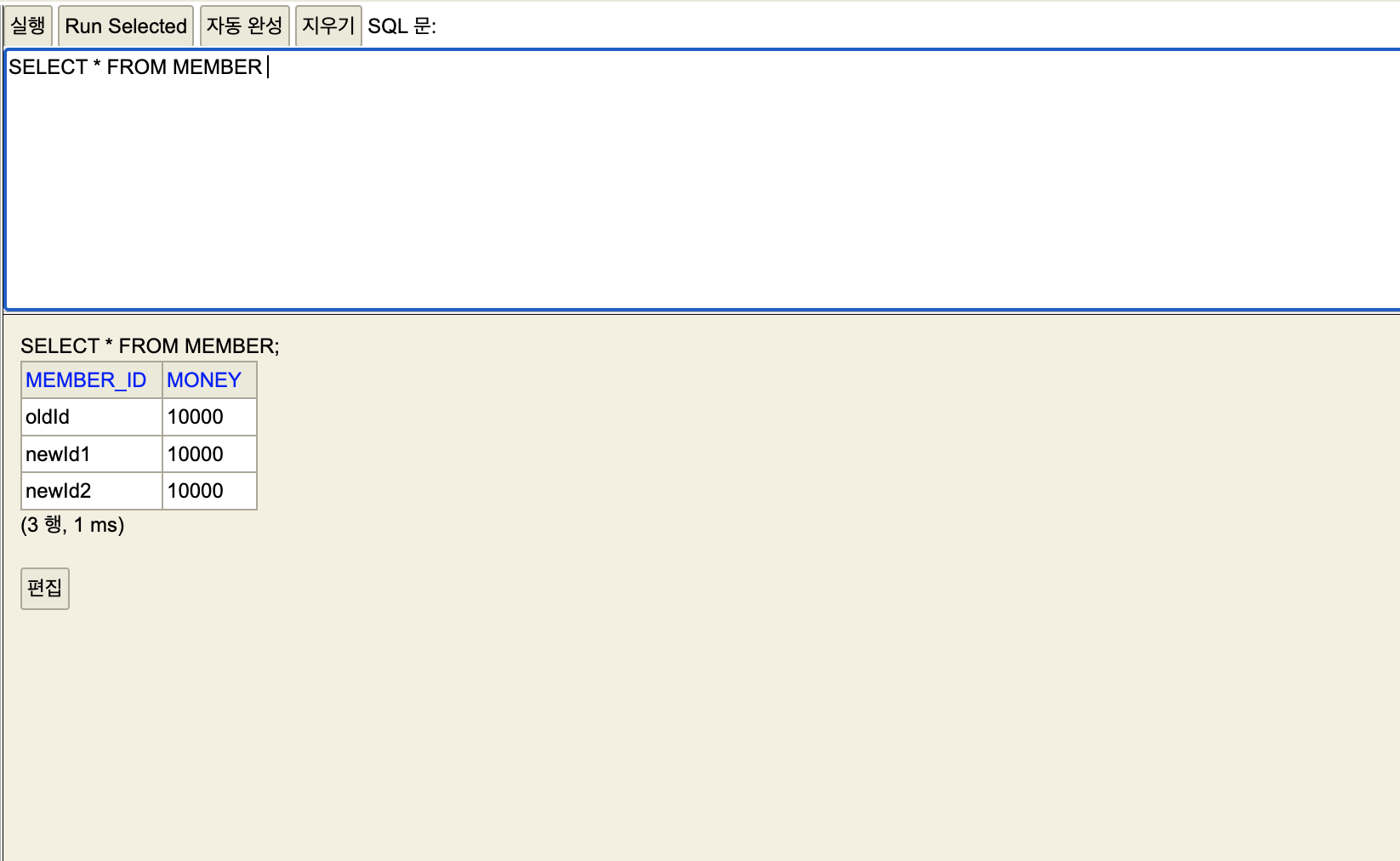
세션1 에서만 임시데이터가 정식으로 등록되어 확인할 수 있는 모습이다.
이번에는 롤백에 대해 알아보자.
rollback 입력
롤백을 테스트하기 위해 기존 데이터를 전부 초기화 시켜준다.
세션1,2 전부 해당된다.
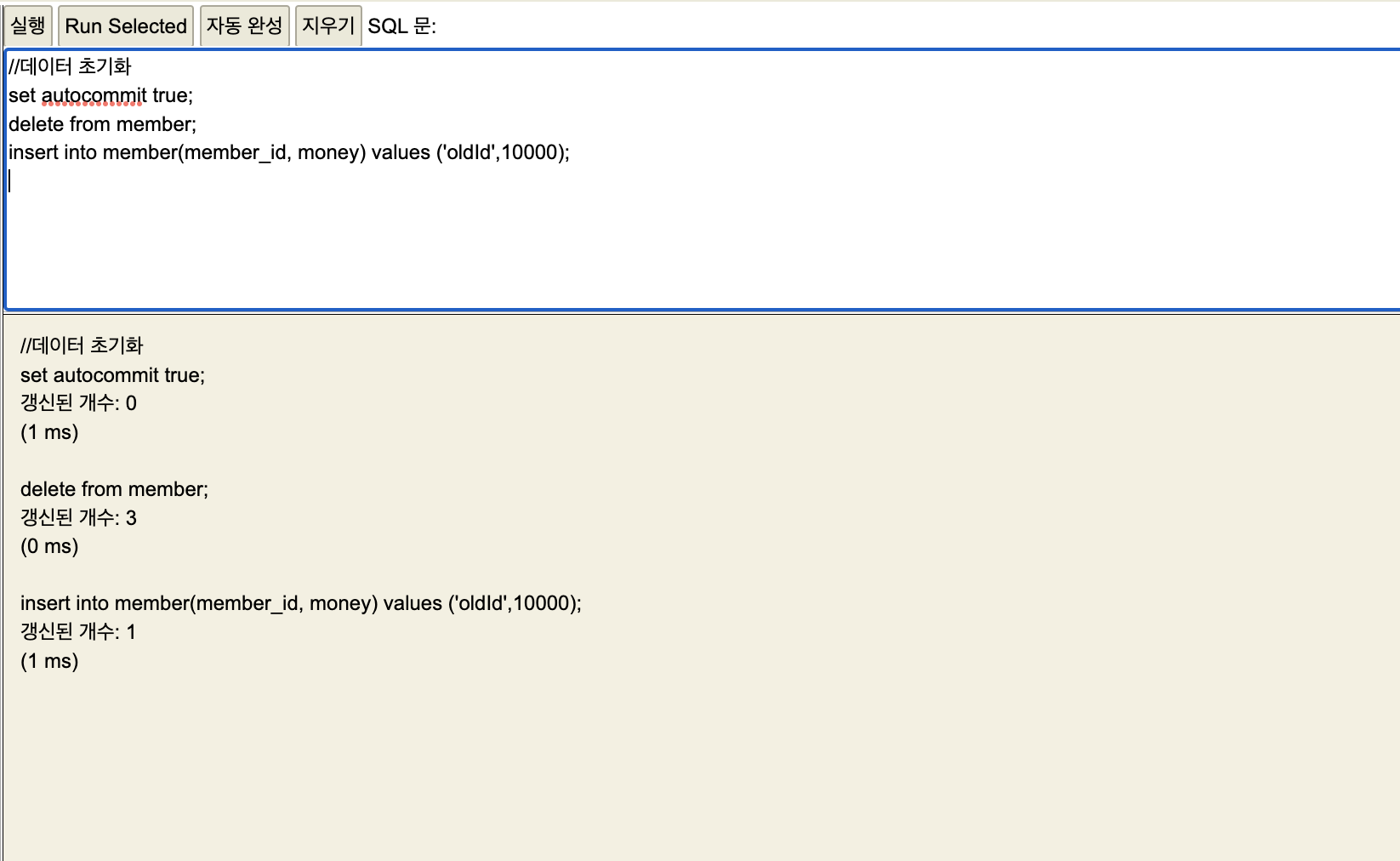
데이터 초기화.
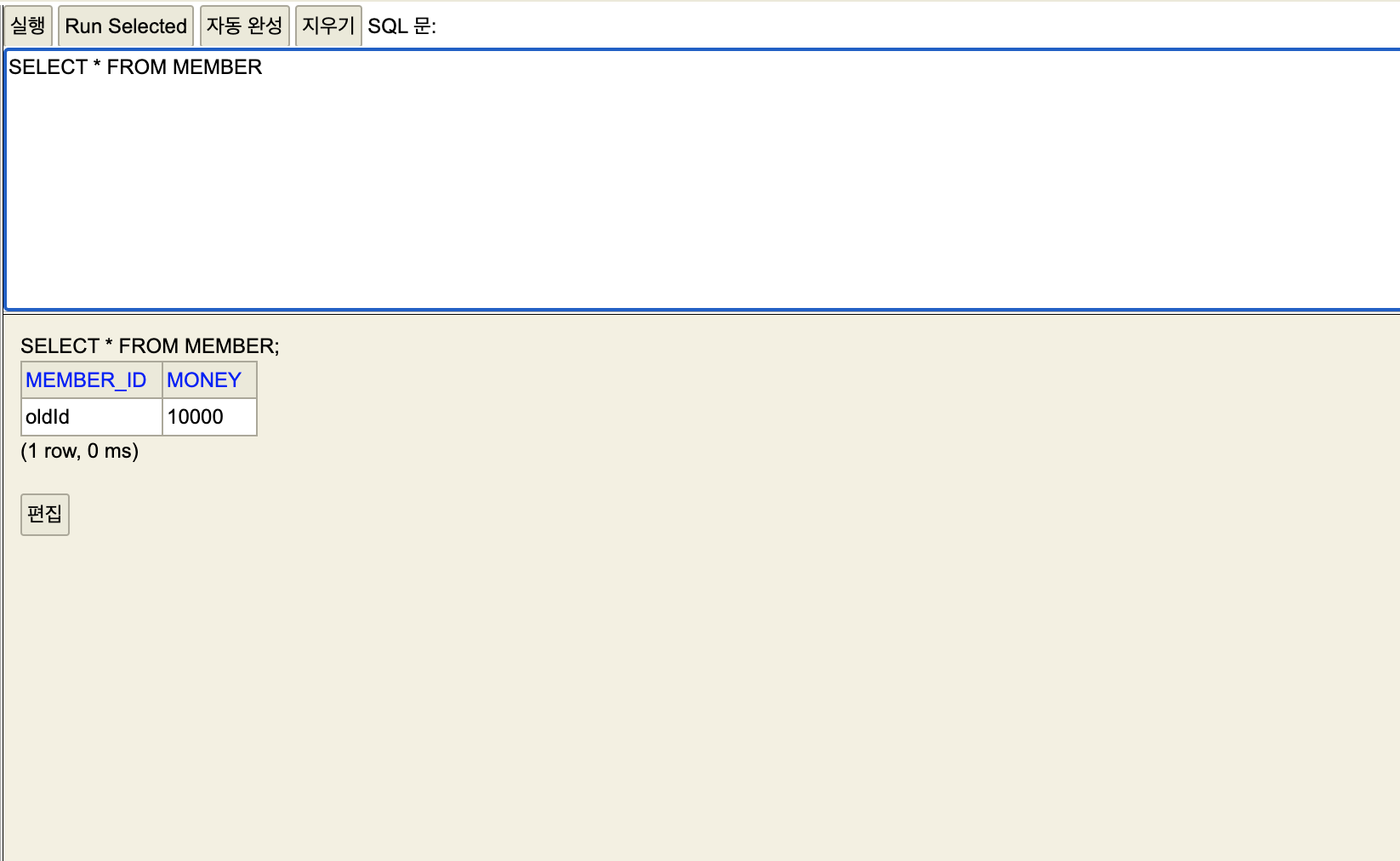
세션1,2 멤버 테이블을 다시 생성해서 등록.
세션1
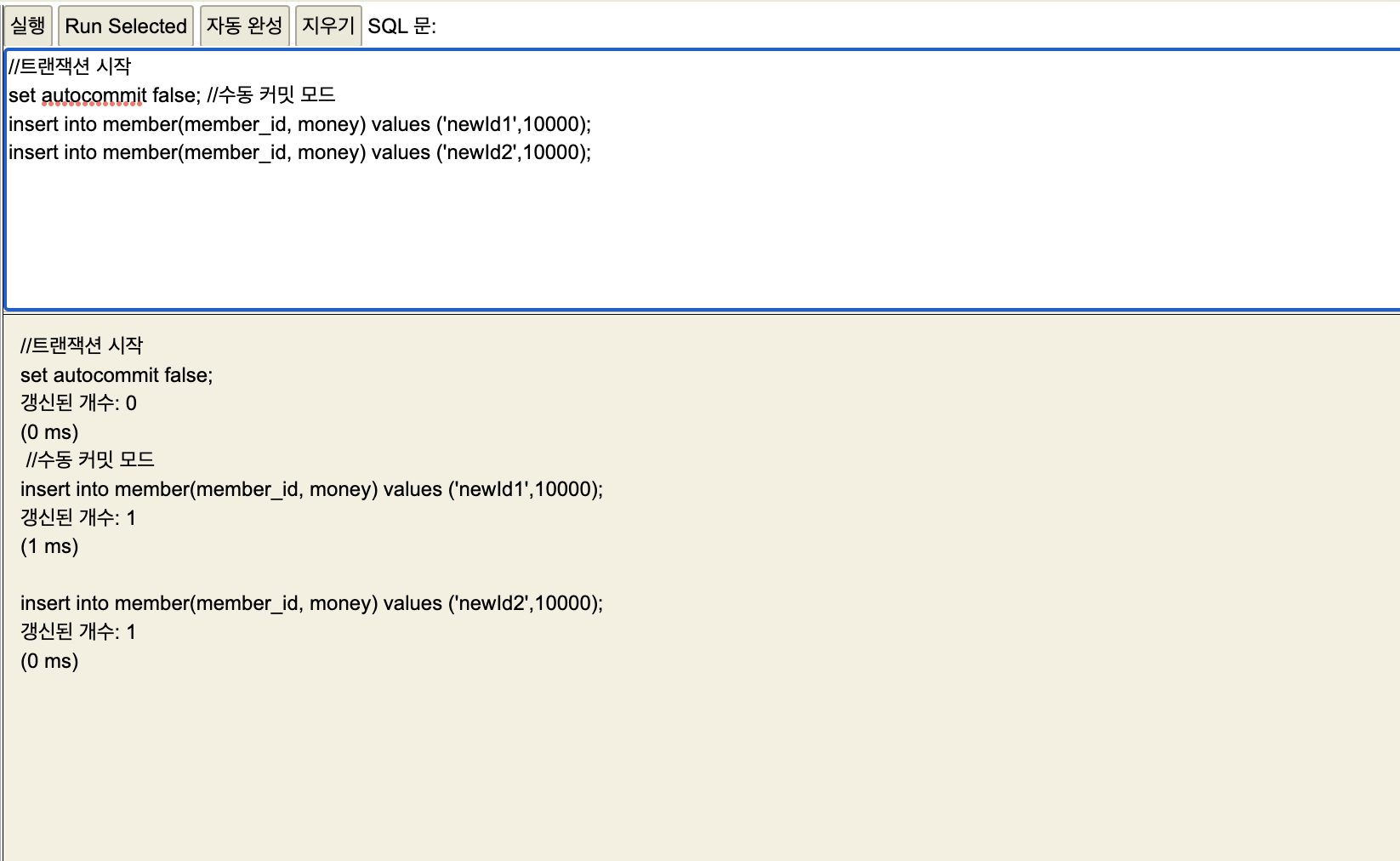
아까처럼 세션1에 쿼리 등록.
세션2
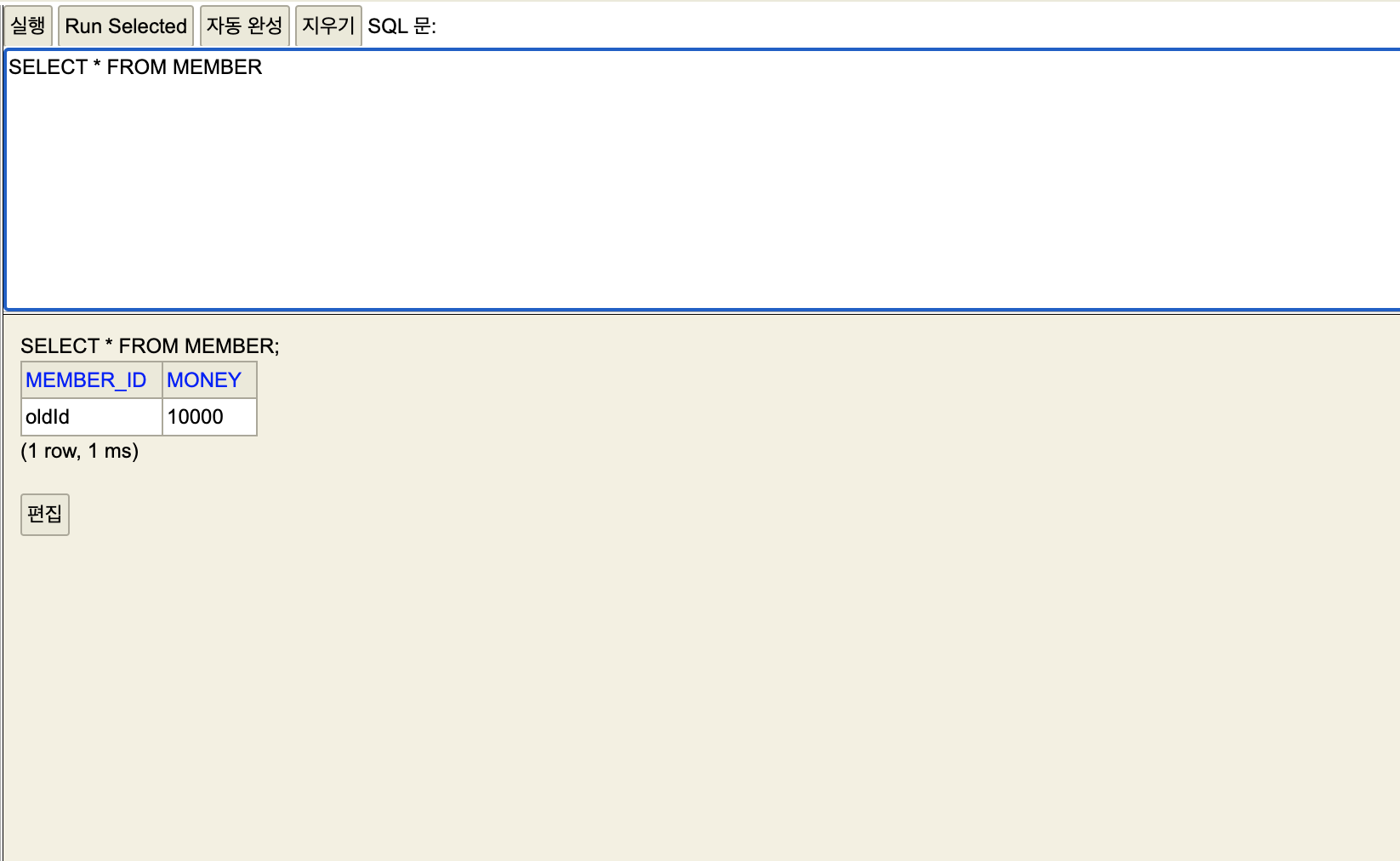
임시 등록이라 안보인다.
세션1
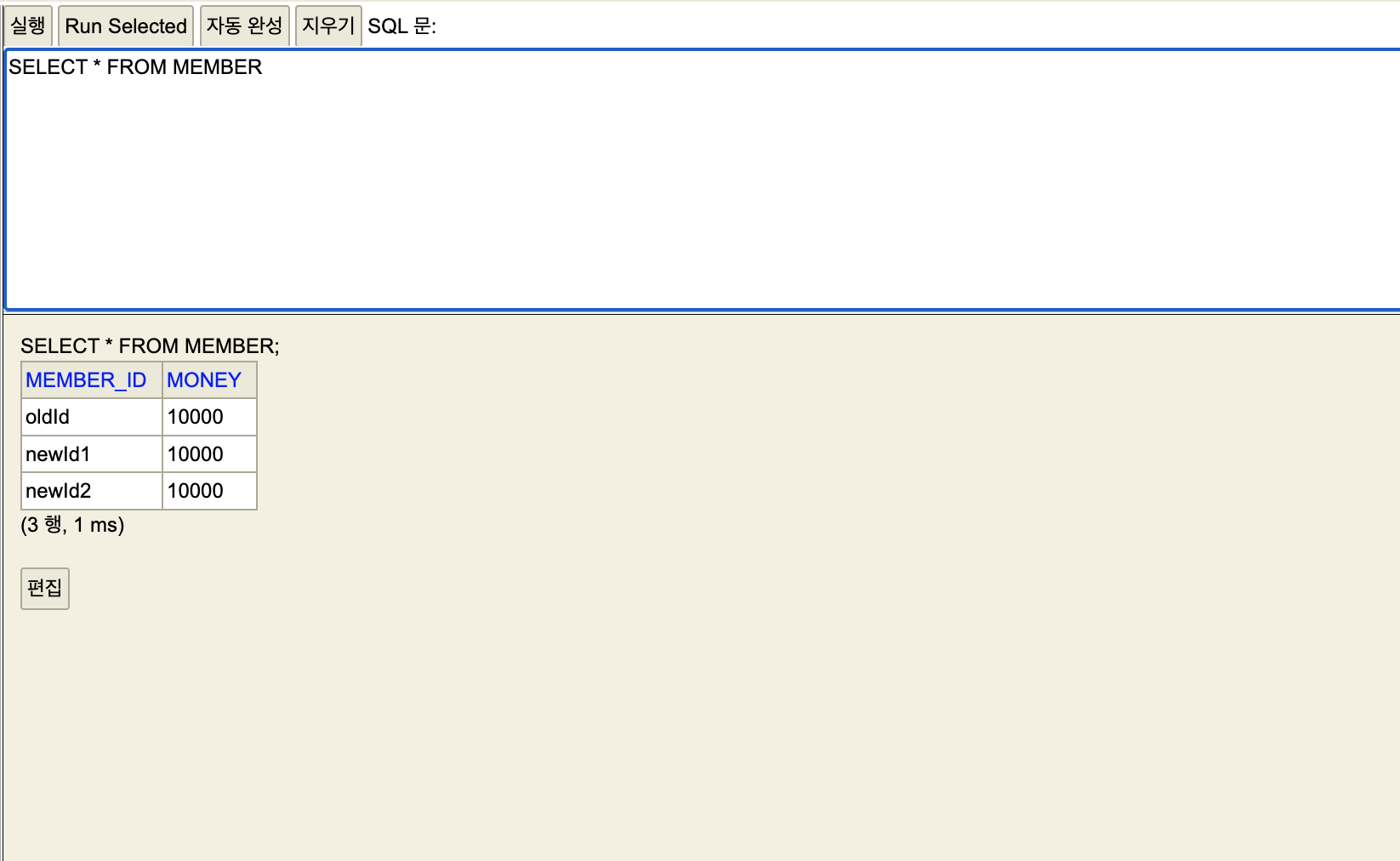
이제 롤백을 사용해볼려고 한다.
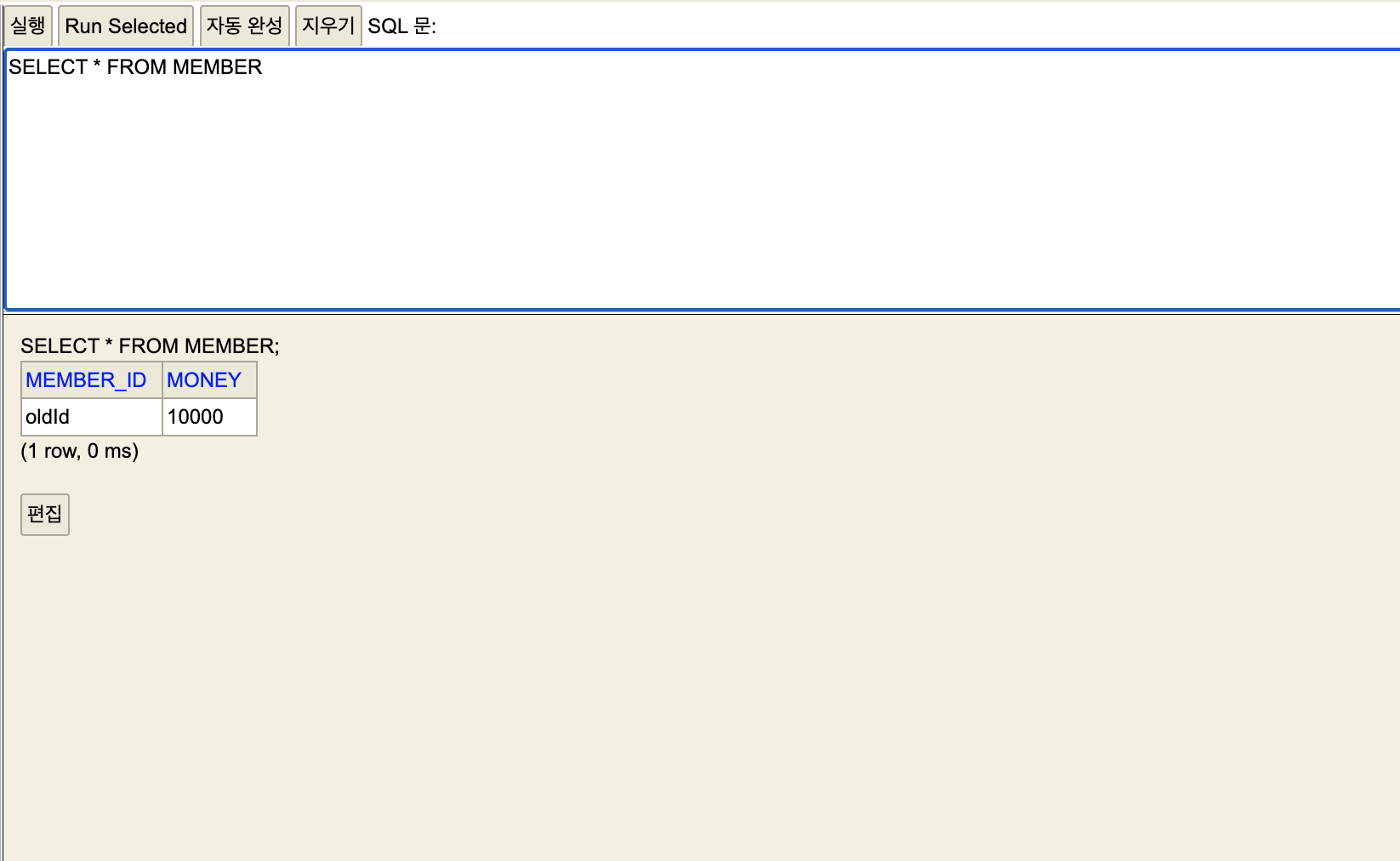
세션1,2 가 롤백으로 데이터가 DB에 반영되지 않은 것을 확인할 수 있다.
