✨ DB(Database)란?
Oracle을 알기 전에 일단 DB 무엇인지부터 알아야겠죠?
데이터를 구조화하고, 저장하고 관리하며 필요할 때 검색할 수 있도록 사용하는 것을 데이터베이스라고 합니다.
우선 DB는 Database의 약자로서,
여러 개의 테이블, 뷰, 인덱스, 제약 조건 등을 포함하는 데이터베이스 객체의 집합입니다.
각 데이터베이스는 고유한 이름을 가지며, 인스턴스에 의해 관리됩니다.
정의는 이 정도이며, 예시를 들어 표현하자면 거대한 엑셀이라고 생각하시면 될 것 같습니다.
저는 회사에 아무것도 모르는 신입이 들어오면 DB를 엑셀, 서버를 컴퓨터라고 비유를 들어서 설명합니다...
이러한 데이터베이스에는 관계형데이터베이스(RDBMS)와 NoSQL데이터베이스로 분류됩니다.
제가 실제로 써보고 아는 것은 관계형뿐이라..
관계형 데이터베이스 중에서도 Oracle(오라클)에 대해서 집중적으로 알아볼 예정입니다.
✨ 관계형 데이터베이스란?
관계형 데이터베이스는 테이블과 열(Column)로 구성된 데이터를 처리합니다.
테이블은 튜플(Tuple)로 구성되며, 튜플은 레코드(Record), 행이라고도 불립니다.
테이블은 키(Key)를 사용하여 다른 테이블과 관계를 맺을 수 있습니다.
(키가 아닌 다른 값으로도 조인할 수 있지만, 관계를 표현할 떄는 주로 PK, FK를 씁니다.)
이러한 관계를 이용하여 데이터를 구성하는 방식을 정규화(Normalization)라고 합니다.
대표적인 관계형 데이터베이스 제품으로는 Oracle, MySQL, Microsoft SQL Server 등이 있습니다.
아래와 같은 관계형 데이터베이스가 있다고 가정을 해봅시다.
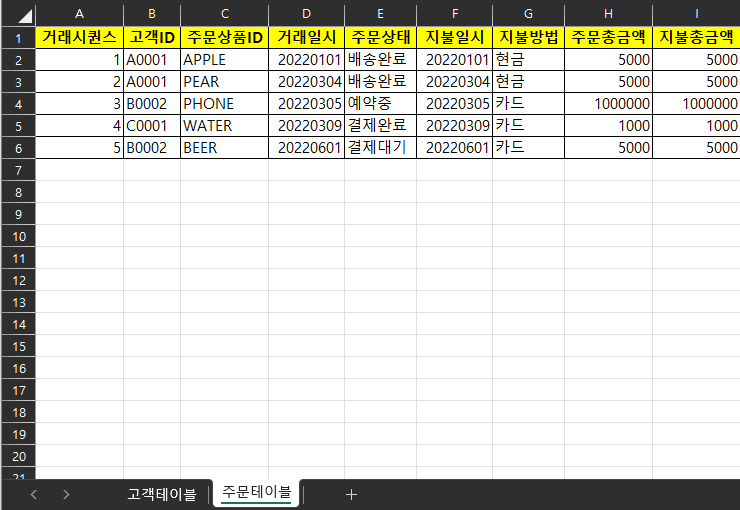
테이블 : 주문테이블, 고객테이블과 같은 시트의 개념
열(컬럼) : 거래시퀀스, 고객ID, 주문상품ID와 같은 데이터의 속성(데이터의 타입과 길이)을 나타내는 요소
키 : 키의 종류는 아래 2가지로 나뉘어집니다.
위 테이블에서는 거래시퀀스(거래일련번호)가 중복되면 안되겠죠? 이 값이 PK가 됩니다.
고객테이블에서는 같은 고객ID가 중복이 되면 안되기 때문에 고객ID가 PK입니다.
위에서 고객ID는 고객테이블의 PK이었죠? 그리고 주문테이블과 관계를 지어 조회하기 위해 FK를 사용합니다.
그리고 이렇게 관계를 지어 조회하는 것을 join이라고 표현합니다.
인덱스(index) : 값을 빨리 찾기 위한, 검색을 빨리 하기 위한 데이터구조. 하나 이상의 컬럼을 기준으로 생성되며,
위의 주문테이블과 같은 경우 거래시퀀스, 고객ID 와 같은 것을 지정합니다.
index를 효율적으로 생성하는 것이 중요한데요, 쓸데없는 index가 생길수록 성능이 떨어집니다.
예로, 지불일시와 주문총금액을 묶어서 찾는 경우가 드물테니 이 두가지를 index로 만들면
효율이 떨어지겠죠? 보통 검색 빈도가 높거나, 조건 검색에 자주 사용되는 컬럼을 사용합니다.
✨ Oracle이란?
데이터베이스는 "데이터베이스 관리 시스템(DBMS)"를 통해 관리가 됩니다.
대표적인 DBMS 중의 하나인 제품이 Oracle Database가 있으며,
이 Oracle Database에서 사용되는 언어가 Oracle입니다.
위에서 설명한 "관계형 데이터베이스" 언어 중 하나로서 많은 기업에서 실질적으로 사용하는 언어입니다.
✨ Oracle의 요소?
인스턴스 (Instance):
데이터베이스가 실행될 때 메모리 상에 로드되는 프로세스 집합입니다.
인스턴스는 데이터베이스의 구성, 메모리 할당, 성능 모니터링 등을 관리합니다.
데이터베이스 (Database):위에서 설명한 요소입니다!
테이블 (Table):
행과 열로 이루어진 데이터의 집합입니다.
테이블은 데이터베이스의 핵심 구성 요소 중 하나이며, 데이터를 저장하고 조회하는 데 사용됩니다.
뷰 (View):
테이블에서 선택된 열이나 행으로 이루어진 가상 테이블입니다.
뷰는 데이터를 단순화하거나 특정 사용자의 데이터 접근 권한을 제한하는 데 사용됩니다.
흔히 쿼리의 조회 결과라고 생각하시면 됩니다.
인덱스 (Index): 이것도 위에서 설명한 내용입니다!
SQL (Structured Query Language):
Oracle 데이터베이스에서 데이터를 관리하기 위해 사용되는 언어입니다.
SQL을 사용하여 데이터베이스 객체를 생성, 조회, 수정, 삭제할 수 있습니다.
SQL 자체는 DB관리 언어이며, oracle은 SQL 중 하나입니다.
PL/SQL (Procedural Language/Structured Query Language):
Oracle 데이터베이스에서 저장 프로시저, 함수 등을 생성할 때 사용되는 프로그래밍 언어입니다.
chat GPT 형님의 말씀을 참고로 설명을 이어갈게요.
(이건 아직 써본 적이 없어요...ㅠ)
DECLARE
x number := 10;
BEGIN
IF x > 5 THEN
dbms_output.put_line('x is greater than 5');
ELSE
dbms_output.put_line('x is less than or equal to 5');
END IF;
END;이 예시는 변수 x를 정의하고, IF 문을 사용하여 x가 5보다 큰지를 검사합니다. 결과에 따라 메시지가 출력됩니다.
DECLARE
customer_name customers.name%TYPE;
customer_address customers.address%TYPE;
BEGIN
SELECT name, address INTO customer_name, customer_address FROM customers WHERE id = 100;
dbms_output.put_line('Customer name: ' || customer_name);
dbms_output.put_line('Customer address: ' || customer_address);
END;이 예시에서는 변수 customer_name과 customer_address를 정의하고, SELECT 문을 사용하여 데이터베이스에서 id가 100인 고객의 이름과 주소를 조회합니다. 조회 결과는 변수에 할당되고, 결과를 출력합니다.
이와 같이 조건/변수/반복문을 수행할 수 있다고 합니다..:)
✨ Oracle의 데이터 단위?
블록(Block) :
데이터베이스에서 가장 작은 논리적 저장 단위입니다.
모든 데이터는 블록 단위로 저장되며, 블록의 크기는 데이터베이스에서 설정 가능합니다.
블록은 여러 개의 레코드(행)으로 이루어져 있으며, 각 블록은 고유한 번호를 가지고 있습니다.
익스텐트(Extent) :
세그먼트를 구성하는 데이터 블록의 집합을 의미합니다.
데이터베이스는 익스텐트를 여러 개로 나누어 세그먼트를 구성하며, 익스텐트의 크기는 미리 정해져 있습니다.
세그먼트(Segment) :
테이블, 인덱스, 클러스터 등과 같은 데이터베이스 객체의 저장 공간을 의미합니다.
세그먼트는 하나 이상의 익스텐트로 구성되어 있으며, 데이터베이스의 논리적 저장 구조 중에서 가장 큰 단위입니다.
I/O(In/Out) :
보통 개발자들 사이에서 "얘기할 때 I/O가 많이 일어난다." 이런 얘기를 합니다.
오라클에서의 I/O는 디스크의 I/O를 의미합니다.
쿼리의 속도/성능을 따질 때 얘기를 하며, 디스크와의 입출력 작업을 의미합니다.
그렇기 때문에 이 I/O를 줄이는 것이 쿼리 성능에 직접적인 영향을 준다고 보시면 될 것 같습니다.

깔끔 정리 감사합니다