한빛미디어 출판 "구글 BERT의 정석 " 책을 참고해서 작성하는 개인 공부 자료입니다.
혹시 내용에 저작권 등 문제가 있다면 알려주시면 감사하겠습니다.
! 내용에 신뢰도가 떨어지거나 상당부분 요약 되어 있을 가능성이 있음 !
! 제가 수식 보는 것을 싫어하기 때문에 꼭 필요하지 않다면 생략되있을 가능성이 높습니다 !
이제 Transformer에 대해 거의다 배웠다.
Encoder에 대해 다시 상기하자면 인코더는 문장의 각 단어( 토큰 )에 대한 표현 벡터를 얻기 위한 일련의 과정이었다는 것을 알 수 있다.
그럼 이 표현 벡터를 통해 어떻게 새로운 시퀀스를 얻어 내는 것일까?
디코더를 통해 그 과정에 대해 자세히 알아보겠다.
Decoder
디코더의 전체 프로세스는 다음과 같다.
- 디코더에 대한 입력 문장을 임베딩 행렬로 변환
- Positional Encoding 기법을 통해 문장의 위치 정보 추가
- Decoder( x N )
3-1. Masked Multi-Head Attention Layer에 통과시켜 어텐션 행렬 M 출력
3-2. 어텐션 행렬 M과 인코더 표현 R을 입력으로 하는 Multi-Head Attention Layaer에 통과시켜 새로운 어텐션 행렬 출력
3-3. Feed-Forward Network에 통과시켜 디코더 표현 출력
3-4. 디코더가 중첩된 개수 N만큼 반복
3-5. 최상위 디코더에서 최종 디코더 표현 출력
이를 유념하며 각 절차를 살펴보자.
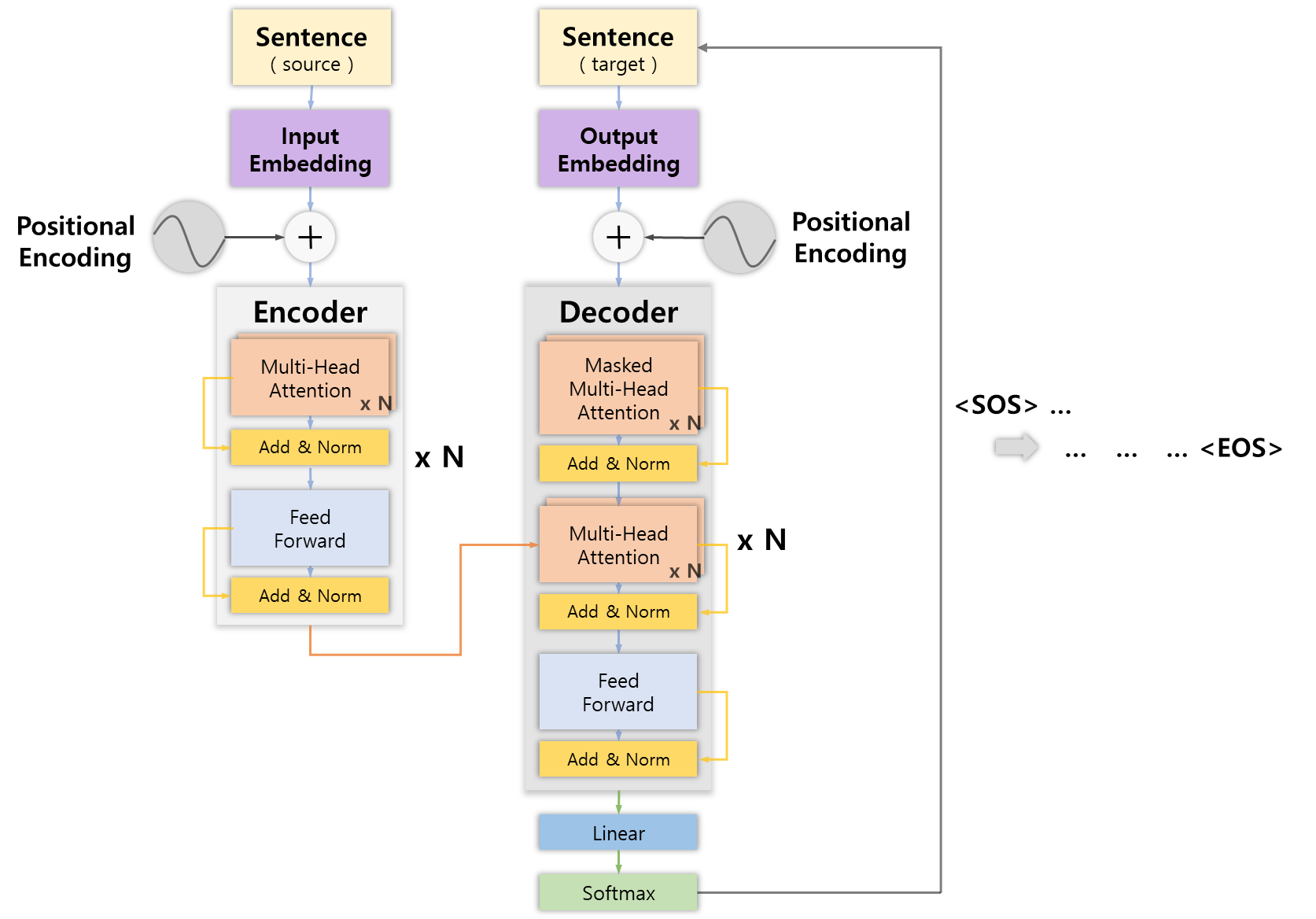
Output Embedding
인코더와 마찬가지로 디코더에도 문장을 입력하는데, 디코더에서는 최초에 문장의 시작을 뜻하는 <SOS>입력해 <EOS> 심볼을 반환할 때 까지 반복해서 디코딩과정을 반복한다.
이 때 디코더에 입력 문장으로 들어가 임베딩 벡터로 변환된 모든 입력 값을 Output Embedding이라고 한다.
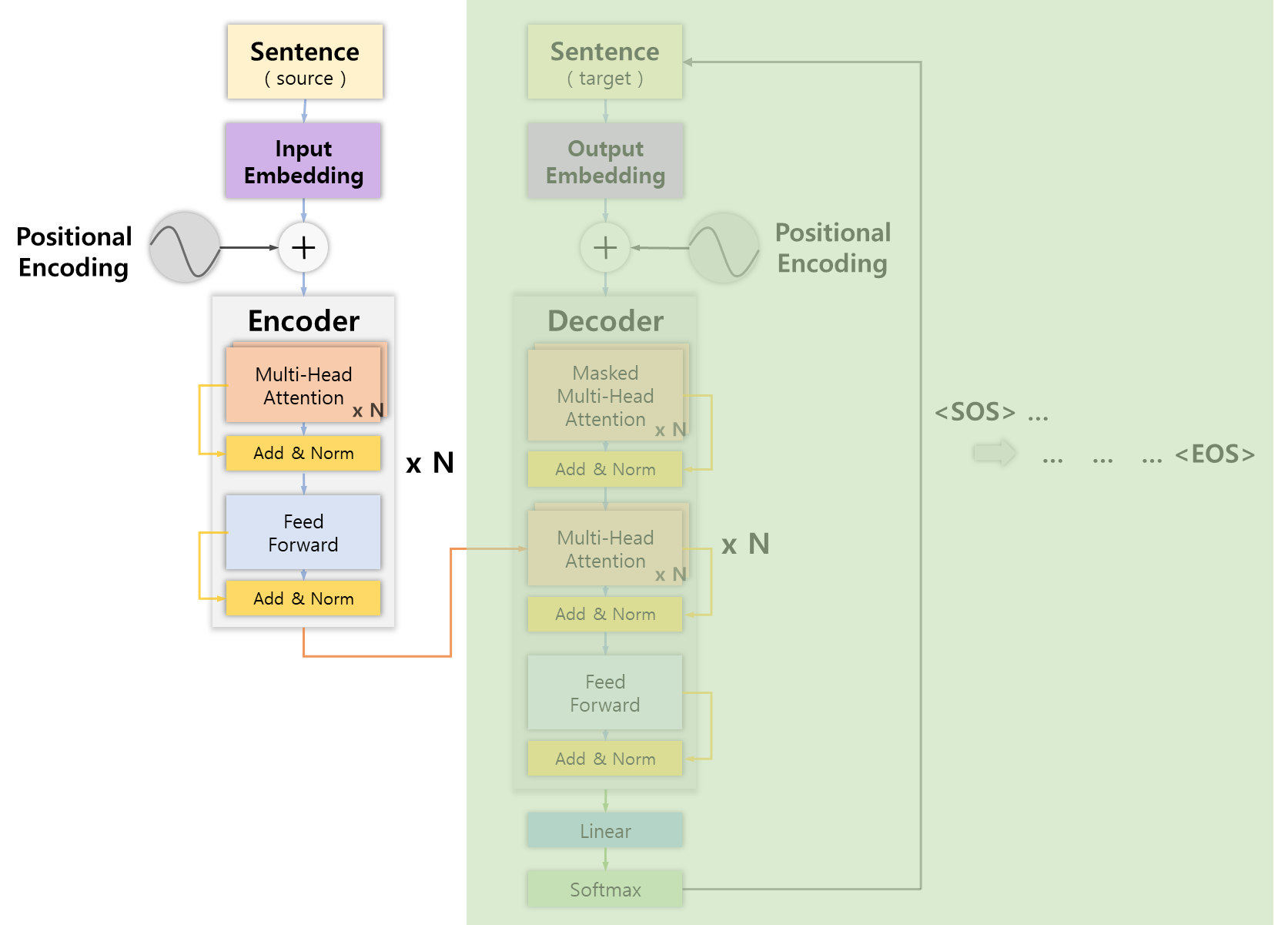
Positional Encoding
인코더와 마찬가지로 모델이 단어의 순서 정보를 이해할 수 있도록 위치 인코딩을 진행한다.
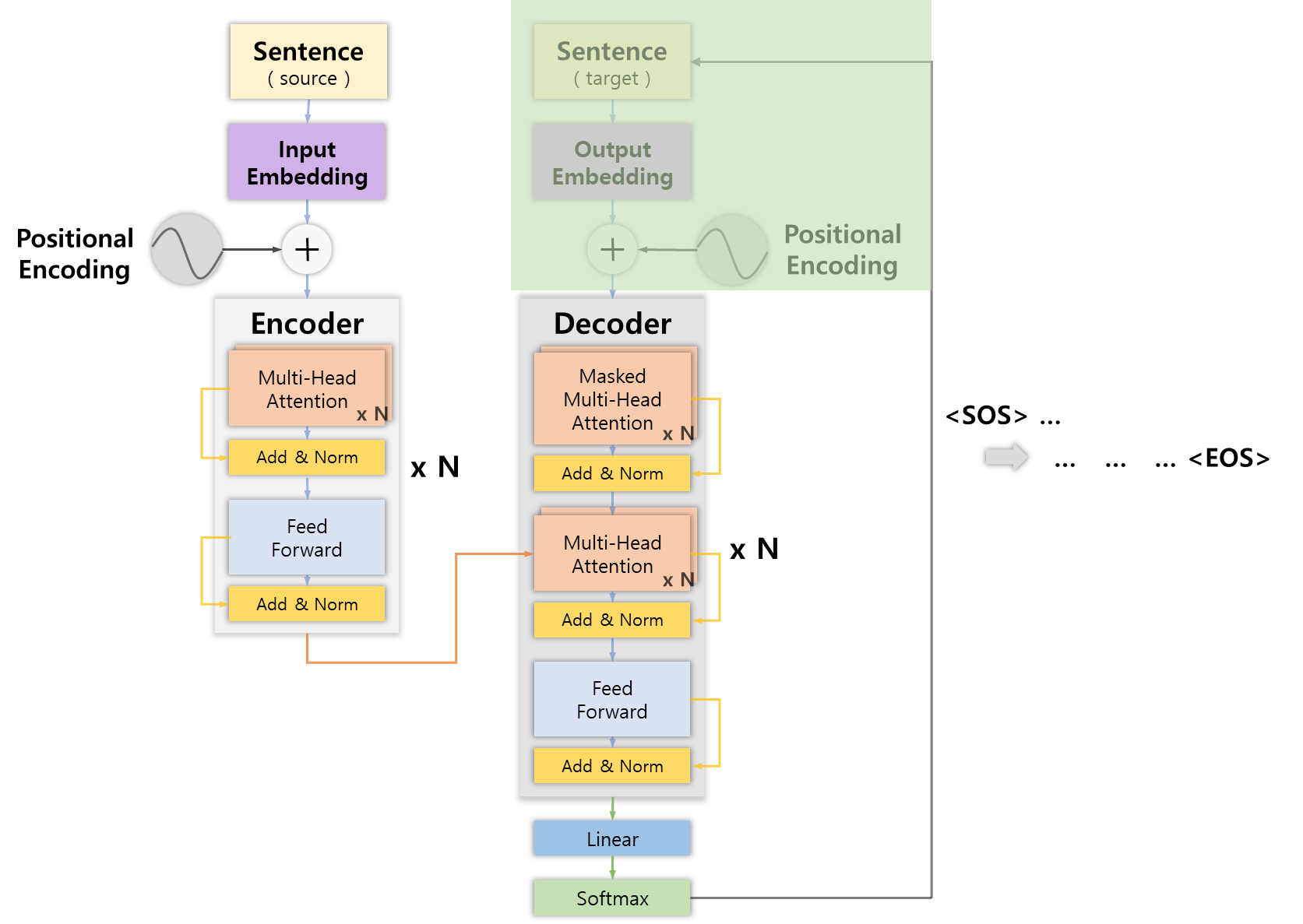
Masked Multi-head Attention
기본적으로 인코더와 같은 Multi-head Attention 서브 레이어를 사용하는데, 디코더에서는 앞서 말했듯이 <SOS>심볼 하나만 가지는 벡터로 시작해 <EOS>심볼로 끝나는 문장을 생성해야 한다.
[
<SOS>]
->[<SOS>,Je]
->[<SOS>,Je,vais]
->[<SOS>,Je,vais,bien]
->[<SOS>,Je,vais,bien,<EOS>]
이와 같이 디코더는 문장을 생성할 때 이전 단계에서 생성한 단어만 입력문장으로 넣기 때문에 모델이 아직 예측하지 않은 모든 단어를 마스킹해 학습을 진행하게 된다.
그렇기 때문에 학습 시의 스코어 행렬은 다음과 같이 구성하게 된다.
<SOS>,MASK,MASK,MASK
<SOS>,Je,MASK,MASK
<SOS>,Je,vais,MASK
<SOS>,Je,vais,bien
이를 행렬로 구현한 예시이다.

예시에는 실제로 의미 없는 값을 보기 쉽게 표현하려고 음의 무한대 값을 이용했지만 실제로 구현할 때는 작은 값()으로 지정해 계산을 수행한다.
나머지는 멀티 헤드 어텐션과 작동방식이 같은데, 이와 같은 단어 마스킹 작업으로 셀프 어텐션에서 입력되는 단어에만 집중해 단어를 정확하게 생성하는 효과를 가져온다.
Add & Norm
마찬가지로 잔차 연결 및 정규화 과정을 거친다.
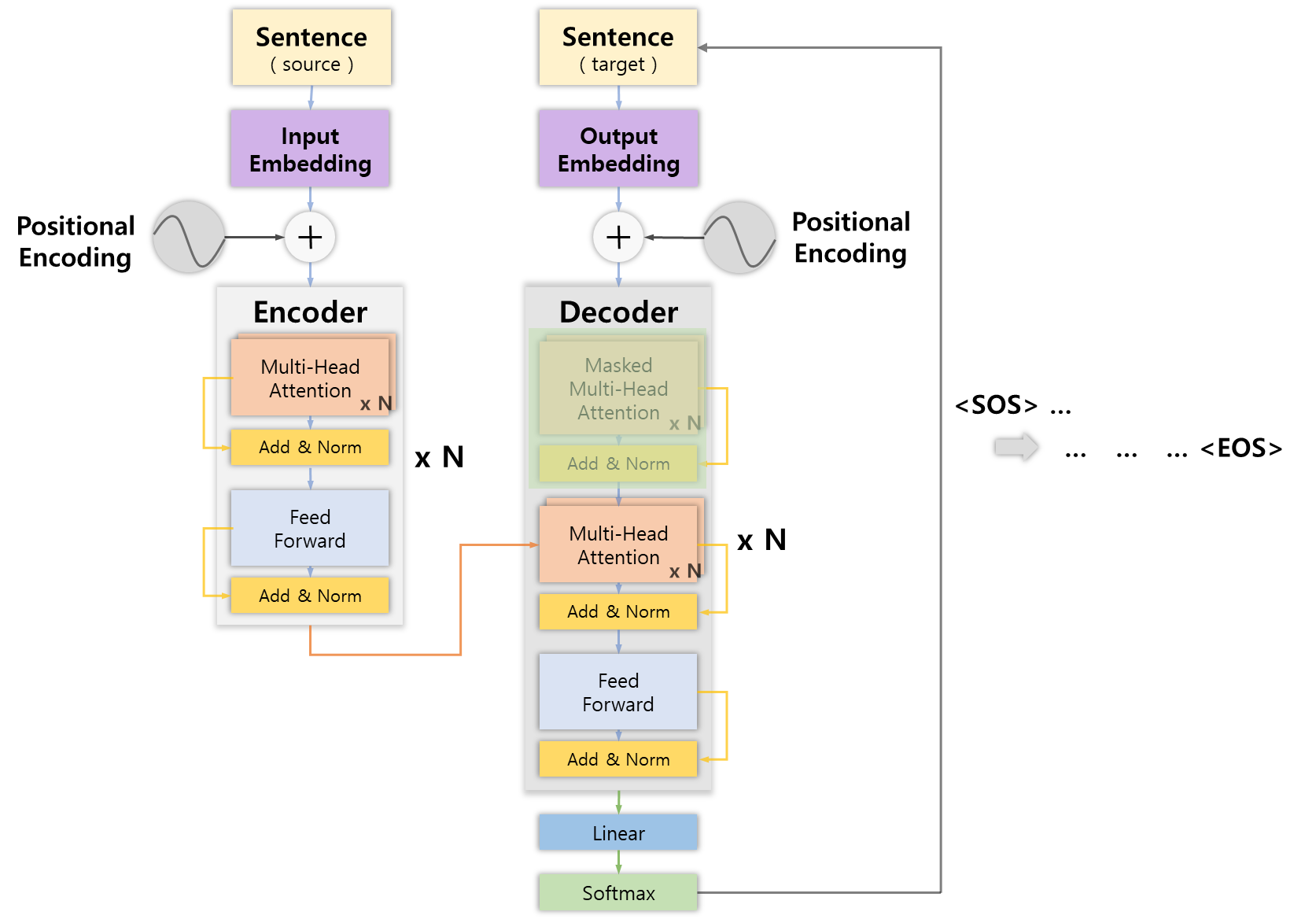
Multi-head Attention
다음으로 앞서 정리했던 멀티 헤드 어텐션 메커니즘이 적용되는데, 이때 디코더의 멀티 헤드 어텐션은 입력 데이터 2개를 받는다.
하나는 이전 서브레이어의 출력값( )이고 다른 하나는 인코더의 표현값( )을 사용하는데, 여기서 인코더의 결과와 디코더의 결과 사이에 상호작용이 일어난다.
때문에 이 서브레이어를 인코더-디코더 어텐션 레이어라고 부른다.
멀티 헤드 어텐션 레이어에서는 처음에 Q, K, V 행렬을 생성한다.
앞에서 행렬에 가중치 행렬을 곱해서 세 가지 행렬을 만들 수 있다는 것을 배웠는데 디코더에서는 입력 값이 2개이기 때문에 다음 절차를 따른다
- 어텐션 행렬( 이전 레이어의 결과 ) 에 가중치 행렬 를 곱해 쿼리행렬 를 생성한다.
- 인코더 표현값 에 가중치 행렬 , 를 각각 곱해 , 를 생성한다.
일반적으로 쿼리 행렬은 타겟 문장의 표현을 포함하므로 타겟 문장에 대한 값인 의 값을 참조하고, 키와 밸류 행렬은 입력 문장의 표현을 가져서 의 값을 참조하기 때문이다.
이와 같은 구성으로 인해 가질 수 있는 장점은 셀프 어텐션의 계산 과정에서 알 수 있는데, 다음과 같이 가정하고 계산 과정을 진행해보자.
인코더의 입력 문장 = 'I am Good'
디코더의 입력 문장 =<SOS>'Je vais bien'
일단 처음에 와 를 통해 스코어 행렬을 구하는 과정을 통해 두 입력 문장의 유사도를 구하게 되는데, 여기서 인코더의 각 토큰( 단어 )과 디코더의 토큰이 얼마나 유사한지 알 수 있게 된다.
이후 와의 연산을 통해 최종적으로 인코더의 입력 문장 "I am Good"과 디코더의 입력 문장 "<SOS> Je vais bien" 대한 어텐션 행렬을 얻게 되는 것이다.
인코더의 멀티 헤드 어텐션에서 설명했듯이, 이런 과정을 거쳐 디코더에서의 어떤 문장이 입력되었을 때( Query ) 다음 단어가 무엇이 나올지를 예측( Key )하게 되는것이다.
마지막으로 개의 헤드에 대해 어텐션 행렬을 구한 후 이를 연결하고, 가중치 행렬 를 곱하면 최종 어텐션 행렬을 구할 수 있다.
Add & Norm
마찬가지로 잔차 연결 및 정규화 과정을 거친다.
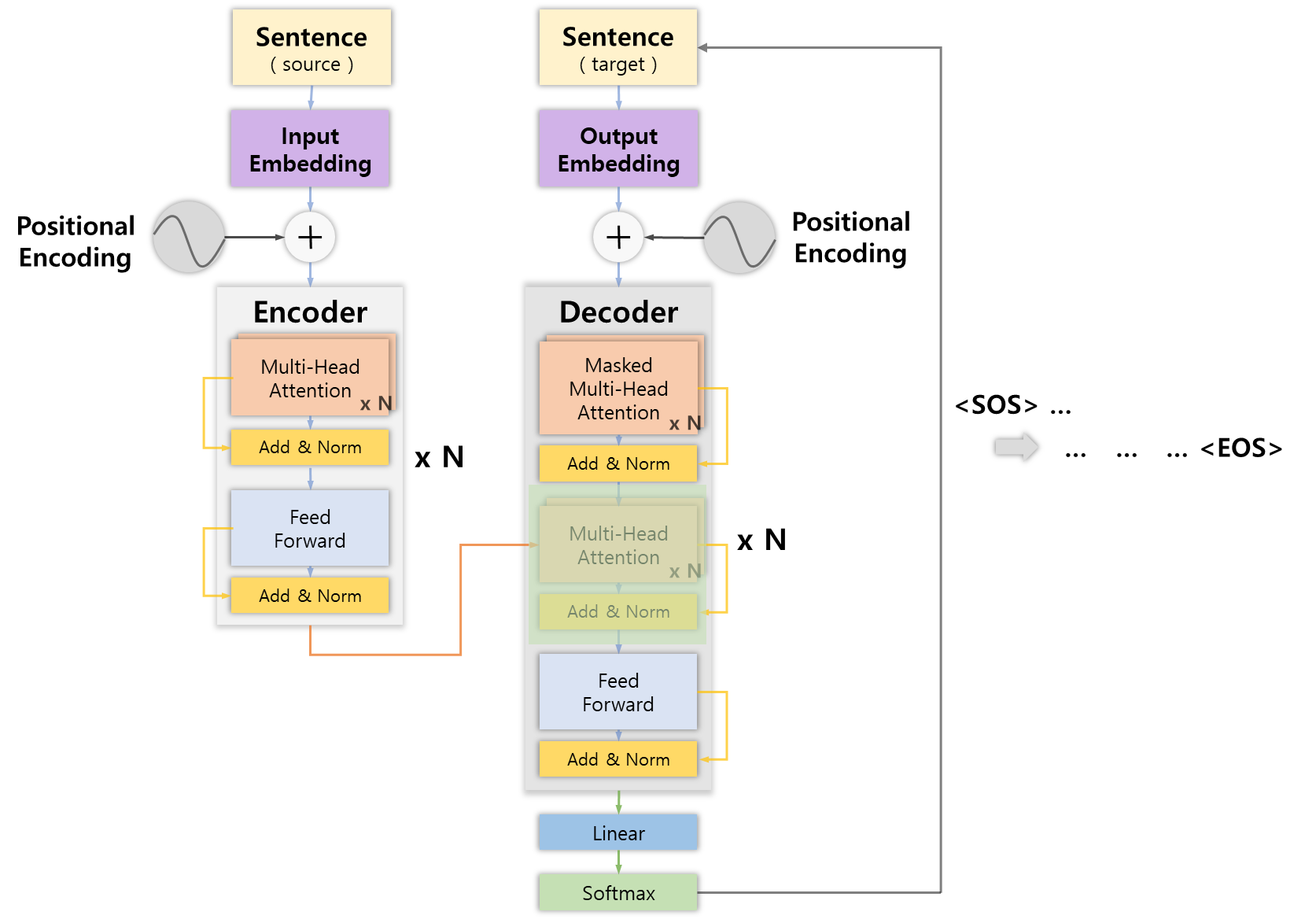
Feed-forward Network
Add & Norm
디코더에서의 마지막 서브레이어는 인코더와 동일하게 Feed-forward Network를 통과한 후 잔차 연결 및 정규화 과정을 거쳐 최종 값을 출력한다.
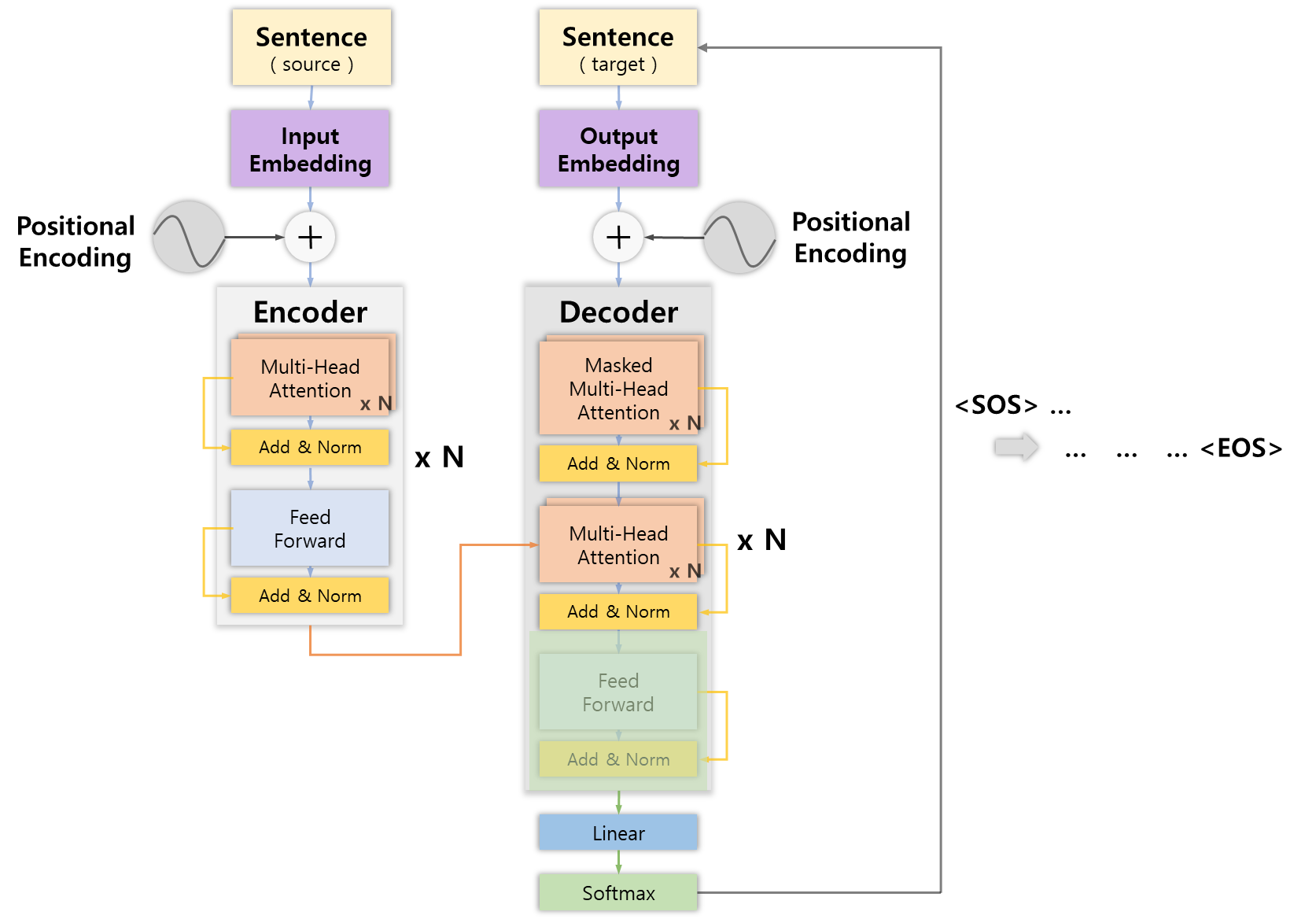
자 여기까지 디코더를 알아보았고 이제 이 디코더의 출력값으로 다음으로 어떤 단어가 나올지 예측할 차례다.
Linear & Softmax
단어 예측을 하기 위해서는 선형 레이어와 소프트맥스 레이어를 사용하는데 간단하게 이야기해보자면 다음과 같다.
Linear Layer
선형 레이어는 이전층의 노드와 현재 층의 노드가 전부 연결되어 있는 FC Layer의 구조를 갖고 있는 선형 결합 층이다.
선형 레이어는 이전에 디코더에서 나온 출력값을 통해 단어 사전( 이하 vocab )의 크기 만큼의 벡터인 logits 벡터로 투영시키는데, 모델이 training 데이터에서 총 10,000개의 영어 단어를 학습했다고 하면 logits 벡터의 크기가 10,000이 되는 것이다.
Softmax Layer
또한 선형레이어에서 나온 출력 값을 소프트맥스 레이어에 통과시키는 과정을 통해 이전 레이어에서 얻은 점수들을 확률로 변환시켜 가장 높은 확률 값을 가지는 노드에 해당하는 단어가 해당 스텝의 최종 결과물( 예측 단어 )로서 출력되게 된다.
이와 같은 과정을 <SOS> 시퀀스에서 <EOS> 시퀀스를 반환할때까지 반복하며 최종 출력물로 예시와 같이 시퀀스를 입력해 새로운 시퀀스를 출력하는 모델이 바로 Transformer이다.
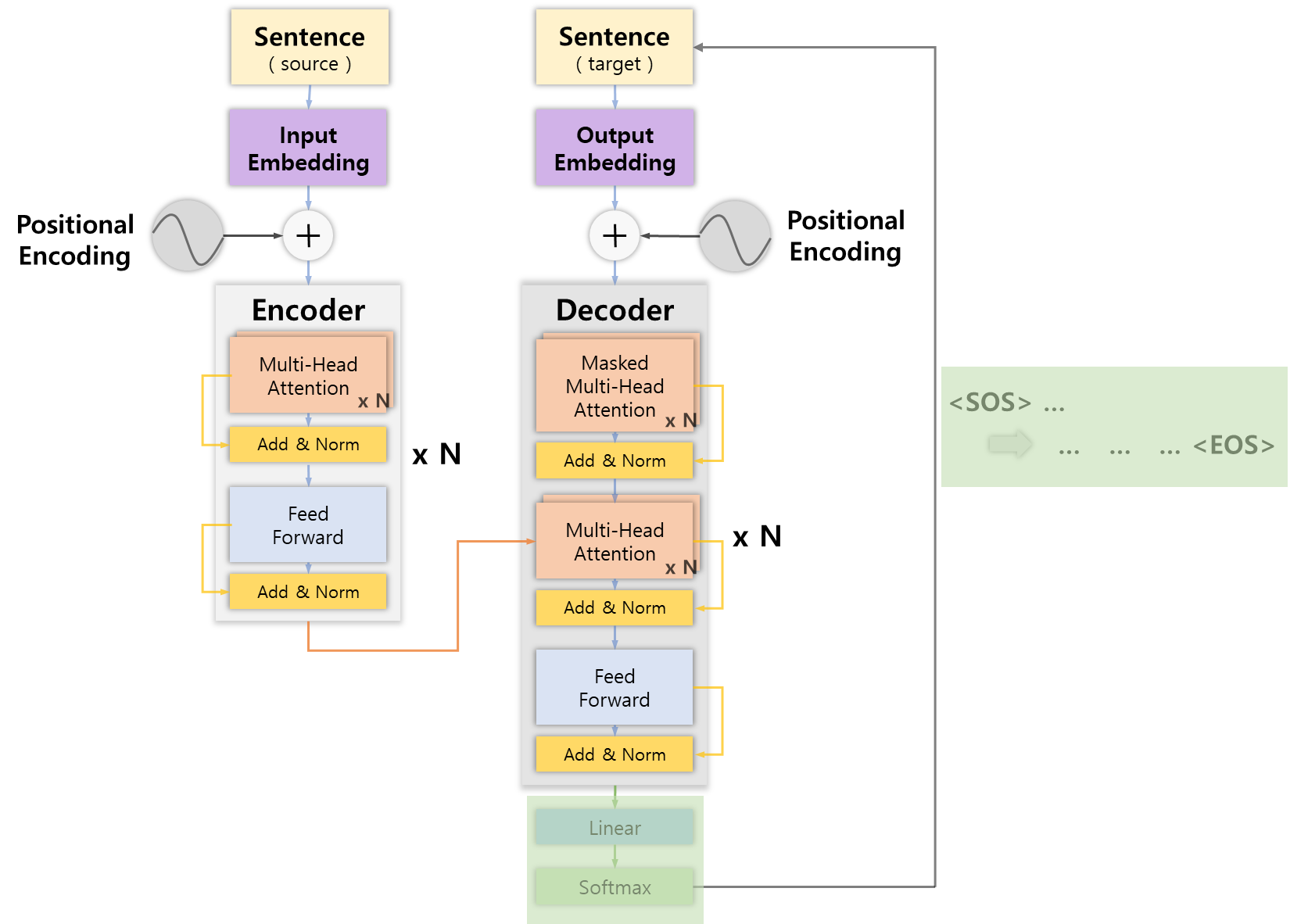
Component Integration
마지막으로 디코더의 구성요소를 정리해보면 다음과 같다.
- 디코더에 대한 입력 문장을 임베딩 행렬로 변환
- Positional Encoding 기법을 통해 문장의 위치 정보 추가
- Decoder( x N )
3-1. Masked Multi-Head Attention Layer에 통과시켜 어텐션 행렬 M 출력
3-2. 어텐션 행렬 M과 인코더 표현 R을 입력으로 하는 Multi-Head Attention Layaer에 통과시켜 새로운 어텐션 행렬 출력
3-3. Feed-Forward Network에 통과시켜 디코더 표현 출력
3-4. 디코더가 중첩된 개수 N만큼 반복
3-5. 최상위 디코더에서 최종 디코더 표현 출력 - 단어 예측
4-1. Linear Layer에 통과시켜 로짓 벡터 출력
4-2. Softmax Layer에 통과시켜 로짓 벡터를 확률값으로 변환
4-3. 디코더에서 가장 높은 확률값을 갖는 인덱스의 단어 출력
4-4. 디코더에 대한 입력 문장에 해당 단어를 Concaternate - <EOS> 심볼을 반환할 때까지 디코더에 문장 입력 및 단어 예측( 1번부터 )을 반복
Summary
자 이렇게해서 Transformer에 대한 전반적인 지식을 알아 보았다.
다시 한 번 사진과 요약을 통해 머리속을 정리해보자.
- 인코더에 영어 문장 입력
- 입력 받은 문장에 대한 학습된 표현 도출 및 디코더에 전달
- 디코더에서 프랑스어로 번역된 문장 생성
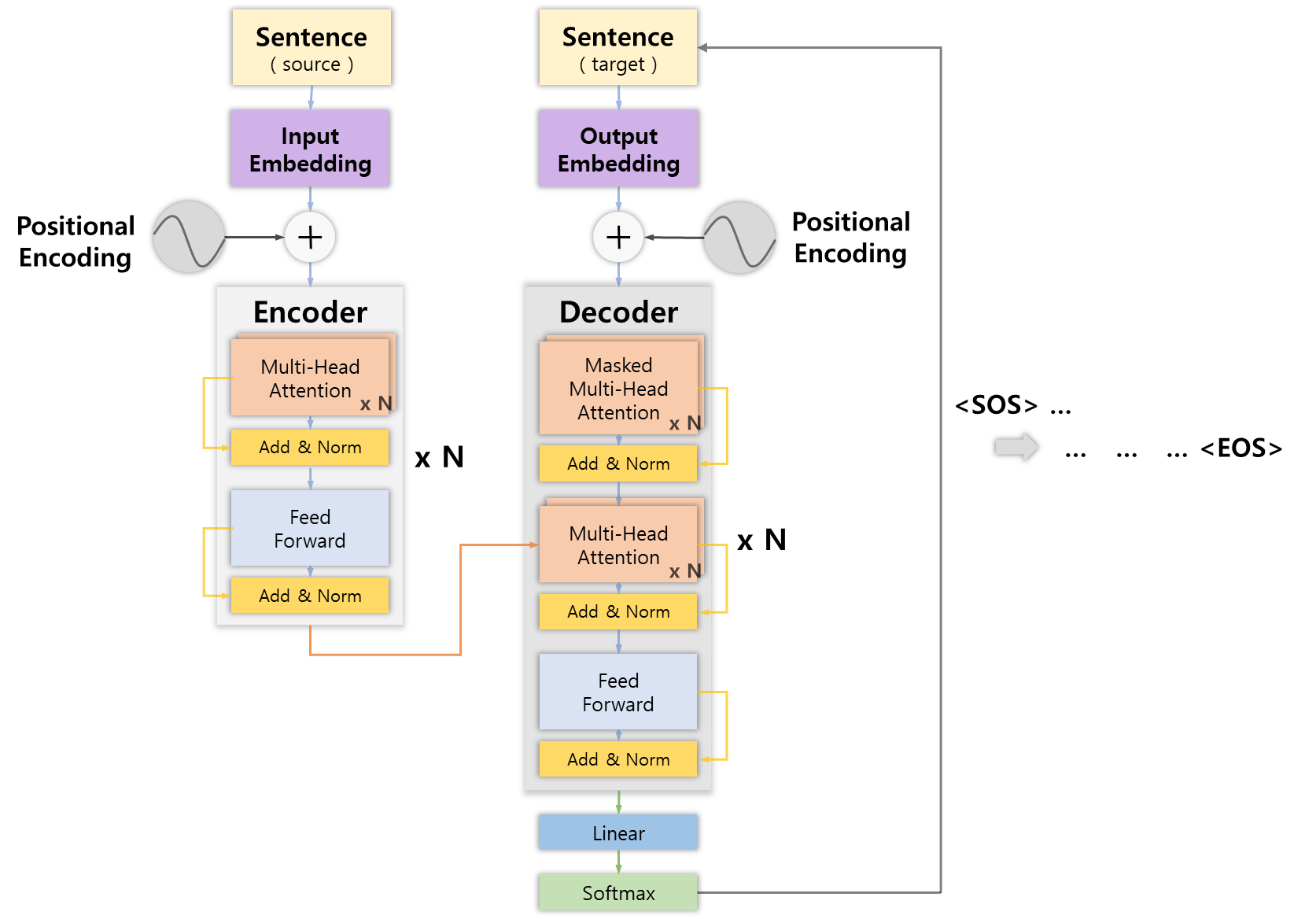
즉, Transformer 모델의 목적은 입력 시퀀스의 표현에 대한 목표 시퀀스를 얻기 위함인데, 시작하기에 앞서 전체 프로세스에 대해 정리해보면 다음과 같다.
-
인코더에 대한 입력 문장을 임베딩 행렬로 변환
-
Positional Encoding 기법을 통해 문장의 위치 정보 추가
-
Encoder( x N )
3-1. Multi-Head Attention Layer에 통과시켜 어텐션 행렬 출력
3-2. Feed Forward Network에 통과시켜 인코더 표현 출력
3-4. 인코더가 중첩된 개수 N 만큼 반복( 이전 출력값을 입력값으로 사용 )
3-5. 최상위 인코더에서 최종 인코더 표현 R 출력 -
최초 입력 문장을 <SOS> 심볼로 초기화 후 디코더에 입력
-
디코더에 대한 입력 문장을 임베딩 행렬로 변환
-
Positional Encoding 기법을 통해 문장의 위치 정보 추가
-
Decoder( x N )
7-1. Masked Multi-Head Attention Layer에 통과시켜 어텐션 행렬 M 출력
7-2. 어텐션 행렬 M과 인코더 표현 R을 입력으로 하는 Multi-Head Attention Layaer에 통과시켜 새로운 어텐션 행렬 출력
7-3. Feed-Forward Network에 통과시켜 디코더 표현 출력
7-4. 디코더가 중첩된 개수 N만큼 반복
7-5. 최상위 디코더에서 최종 디코더 표현 출력 -
단어 예측
8-1. Linear Layer에 통과시켜 로짓 벡터 출력
8-2. Softmax Layer에 통과시켜 로짓 벡터를 확률값으로 변환
8-3. 디코더에서 가장 높은 확률값을 갖는 인덱스의 단어 출력
8-4. 디코더에 대한 입력 문장에 해당 단어를 Concaternate -
<EOS> 심볼을 반환할 때까지 디코더에 문장 입력 및 단어 예측( 5번부터 )을 반복
처음에는 막막했지만 이제는 Transformer에 대해 이해할 수 있게 되었다.
그럼 드디어 목적지인 BERT에 대해서 진행할 수 있게 된 것이다.
다소 힘든 과정이었지만 조금 더 힘내서 다음 포스팅에는 BERT에 대해서 알아보겠다.
누군가 보는 사람이 있다면 이 글을 통해 Transformer 공부에 도움이 되었으면 좋겠습니다.
글솜씨가 없어 이해하기 어려운 부분도 있을 수 있겠지만 잘 보셨으면 좋겠습니다!
