스터데이라는 학원 지도 및 아이 스케줄 관리 플랫폼을 만들면서 성능테스트를 어떻게 진행했는지를 적어보려고 합니다.
🤔어떤 부분을 개선하려고 하나
스터데이라는 학원 지도 및 아이 스케줄 관리 플랫폼을 만들면서 학원 목록 무한스크롤 부분에 대한 성능을 개선해보기로 했습니다.
이유는 저희 서비스의 핵심 기능인 중심 위치 기반으로 전체 데이터 30만 개 중에서 최대 400개의 데이터를 10개씩 반환하는데 3초가 걸렸습니다. 구글 리서치 자료에 따르면 모바일 웹 사이트의 로딩시간이 3초 이상일 때 32%의 사용자 이탈률이 발생합니다.
🔖목표는 어떻게 산정했나
경쟁사 중에서 공부선배가 학원 지도를 제공하였기 때문에 이 사이트를 기준으로 목표치를 산정하려고 했으나 저희와 다른 방식의 학원 지도를 제공하기 때문에 저희가 벤치마킹한 Daum 지도를 바탕으로 목표치를 산정하였습니다.
그래서 저희의 목표는 Daum 지도의 응답 시간보다는 20% 개선하는 것을 목표로 두었습니다. 그러기 위해서 Performance Insight라는 개발자 도구(f12)를 이용해서 Daum 지도를 분석해보았습니다.
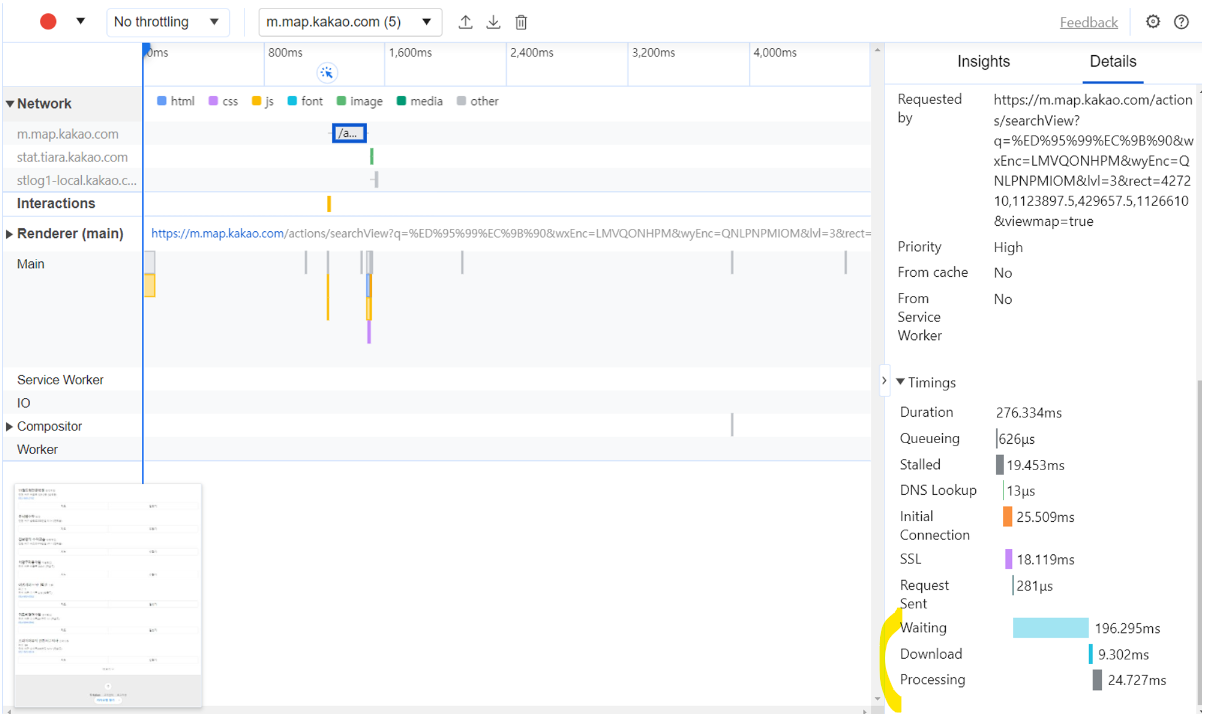
제가 형광펜으로 표시한 부분을 중심으로 살펴보았습니다.
- Waiting(= WAS 및 DB 처리 시간) : 196ms
- DB : 137ms
- WAS : 59ms
- DB와 WAS를 7 : 3의 비율로 나눴습니다. 아무래도 DB는 네트워크 비용이 발생하고 하나의 데이터를 찾고 조회하는데 연산하는 작업이 발생하기 때문입니다.
- Download(= WAS에서 브라우저로 응답을 보내는데 걸리는 시간) : 9.302ms
위 분석을 바탕으로 20%의 성능을 개선해보고자 하였습니다. 하지만 저희는 10개씩 학원 데이터가 등장하지만 Daum 지도는 15개씩 등장하여 이 부분을 반영하여 계산해보았습니다.
(196+59) / 15 x 10 x 0.8 = 109ms
그래서 저희 목표는 요청당 109ms가 나오는 것입니다.
그러나 다음의 서버 환경과 저희의 서버 환경은 큰 차이가 있을 것입니다. 다음은 많은 유저들이 이용하는 사이트이기 때문에 더 좋은 서버 사양을 가지고 있을 것이기 때문입니다.
요청이 몰리는 순간 몇명의 유저가 들어오나
하지만 유저가 한 두명 있을 때가 아니라 실제로 요청이 몰리는 순간에도 109ms가 유지되어져야 한다는 것입니다.
경쟁사를 분석하여 실제로 몇명의 유저가 몰리는지 계산해보아야 합니다.
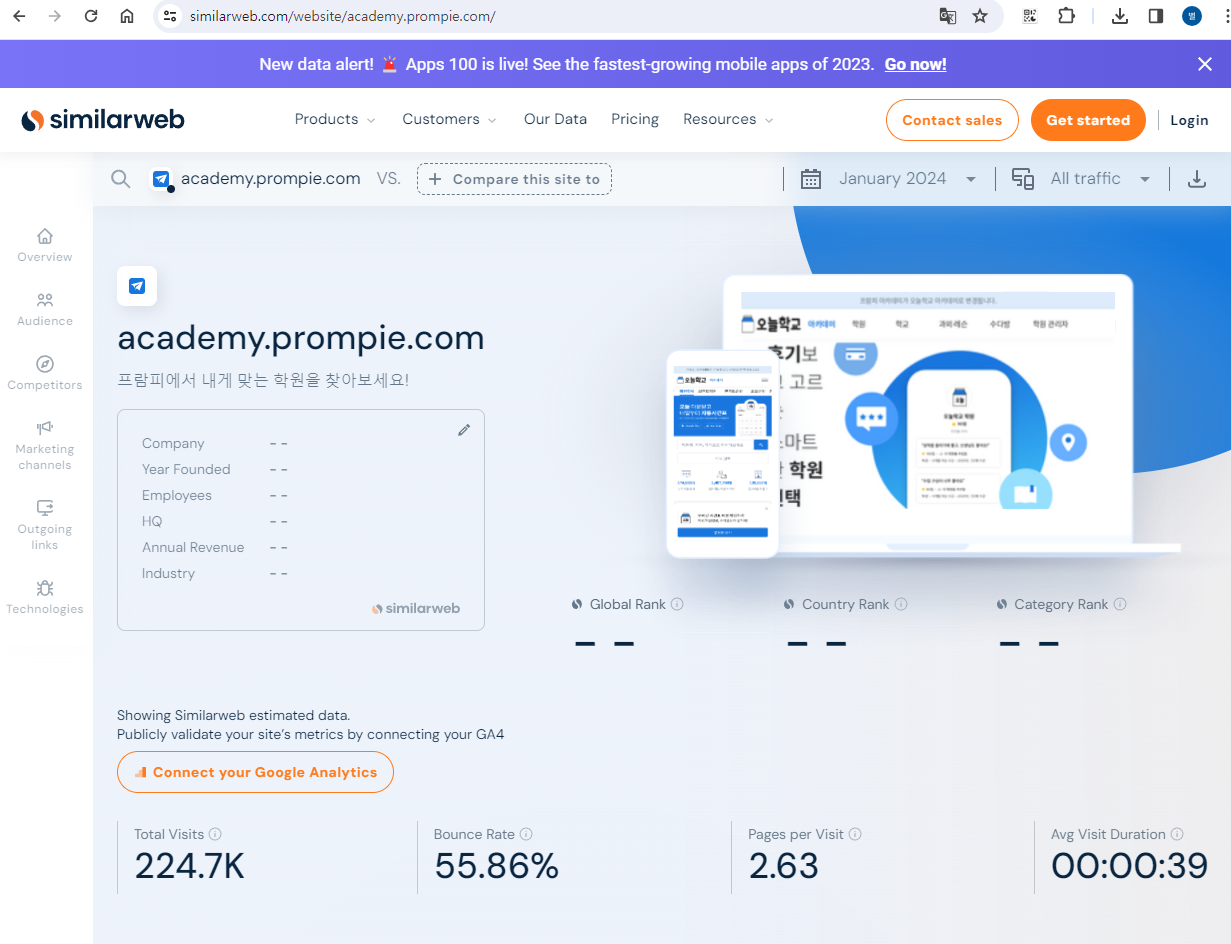
저희의 경쟁사는 "오늘학교 아카데미"라는 곳입니다.
저는 시밀러웹을 이용해서 경쟁사의 DAU를 얻었습니다.
- 한달 평균 방문자 수(최근 세달 기준) : 145,000명
- 아침, 저녁, 점심, 출근, 퇴근마다 4번씩 요청
- 직장인 평군 스마트폰 사용시간 5시간 (맞벌이 부모들을 위한 플랫폼이므로 고려)
(145000 x 5 x 4) / (5x60x60) = 166번
피크시간에는 4번씩 요청한다고 가정하면 644번
Vuser = 644 * 0.109 = 70명
Vuser는 70명이 나왔습니다.
이를 바탕으로 저는 atillery를 이용해서 부하테스트를 진행해보기로 하였습니다.
💣Artillery를 이용한 부하테스트

Artillery를 nGrinder, k6와 같은 스트레스 테스트 도구입니다. 이 중에서 제가 Artillery를 사용한 이유는 러닝 커브가 낮다는 데 있었습니다. yml을 통해 쉽게 시나리오를 작성할 수 있습니다. 실제로 인프런에 있는 foo님의 강의를 3시간 이내에 듣고 바로 적용할 수 있었습니다. 사용법은 부록 부분에 첨부해두겠습니다.
제가 작성한 시나리오는 아래와 같습니다.
테스트는 대략 1시간 동안 진행하도록 설계하였습니다.
실제로 부하가 몰리는 시간에 30분 정도 접속해있다고 가정하였습니다.
config:
target: 'https://studay'
phases:
- duration: 300
arrivalRate: 1
rampTo : 50
name: Ramp 1 to 50
- duration: 300
arrivalRate: 50
name: maintain 50
- duration: 600
arrivalRate: 50
rampTo: 70
name: Ramp 50 to 70
- duration: 1200
arrivalRate: 70
name: maintain 70
- duration: 600
arrivalRate: 70
rampTo: 0
name: Ramp 70 to 0
payload:
- path: "access-token.csv"
fields:
- "token"
- path: "complex-scroll.csv"
fields:
- "lat"
- "lng"
- "pageNumber"
scenarios:
- flow:
- get:
url: "/academies/complexes-scroll?lat={{ lat }}&lng={{ lng }}&pageNumber={{ pageNumber }}"
headers:
authorization: "Bearer {{ token }}"결과는 어떻게 나왔을까요?
하나씩 살펴보도록 하겠습니다.
📍 현재 서버 사양
백엔드 서버 : t2.small(cpu :1, 메모리 : 2GiB)
RDS 서버

📍 성능 개선 전
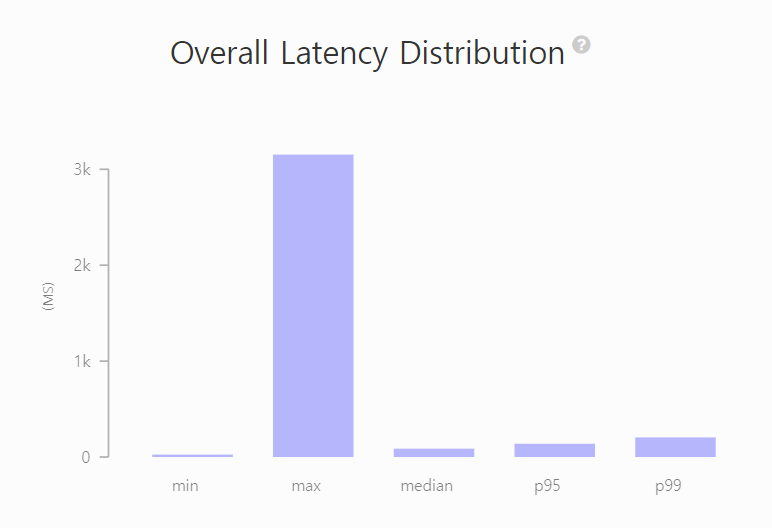
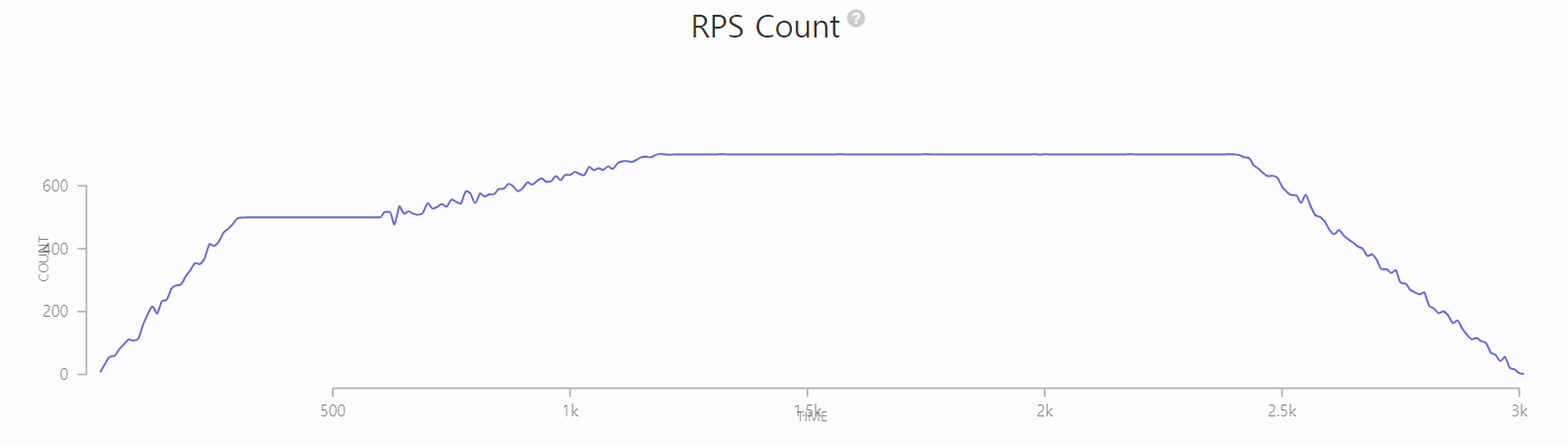
Artillery의 report를 통해 보면 최대 3초가 나오는 것을 확인할 수 있습니다.
또한 어느 순간에 처리하는 RPS의 수가 늘어나지 않고 일정한 순간이 발생하고 있습니다.
이에 따라 저는 어디에서 병목이 발생하는지 확인해보려 합니다.
🔗 모니터링 서버 확인하기
WAS 모니터링 서버를 확인해보겠습니다.
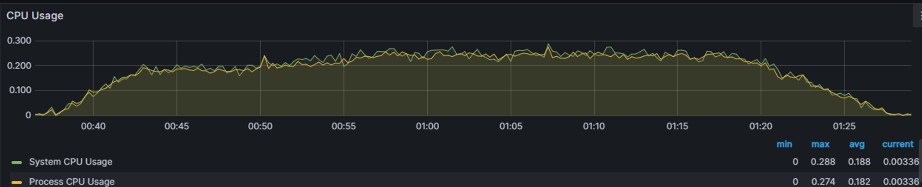
CPU 사용량이 60%이내로 양호해보였습니다.

하지만 DB Connection이 10이 되는 순간이 있었습니다. 참고로 저희의 서버는 DBCP의 수는 Default은 10이었습니다.
🔗 DB 모니터링 서버 확인하기
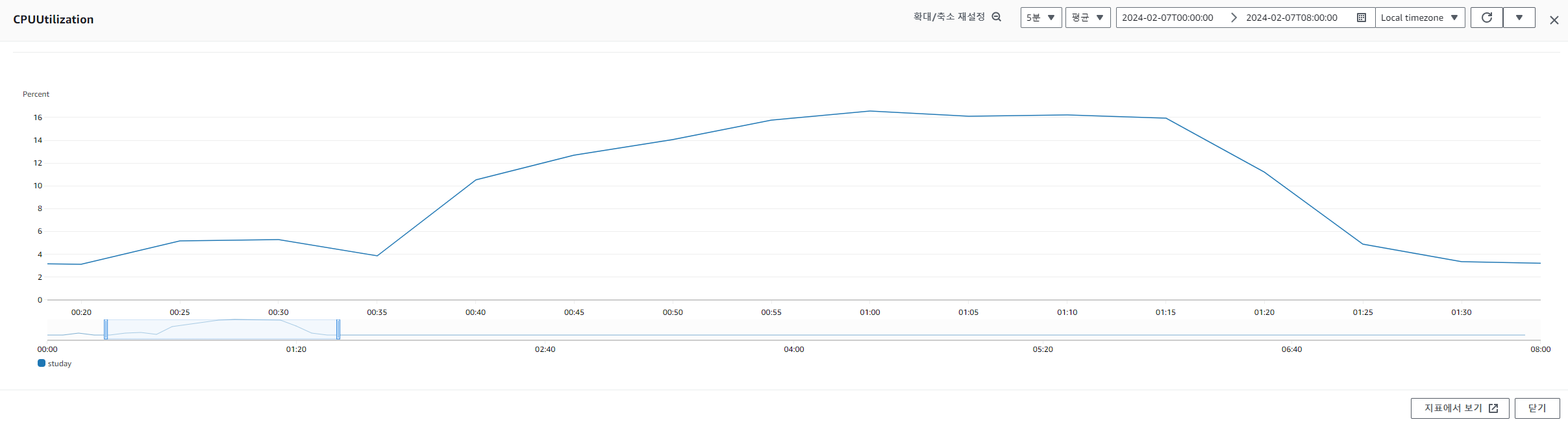
DB의 CPU 사용량도 60%이내였습니다.
이에 따라 저는 DB connection 개수가 부족하거나 Thread의 개수가 부족해서 발생하는 문제가 아닐까 생각해보게 되었습니다.
CPU 사용량이 60%이내였기 때문에 CPU를 제대로 활용하지 못해 발생한다고 생각했습니다.
📍 DBCP의 수를 늘려보자
그래서 저는 첫 번째로 DBCP의 개수 기본인 10개에서 20개로 늘려보고자 하였습니다.
spring:
datasource:
hikari:
minimum-idle: 20
maximum-pool-size: 20
idle-timeout: 30000
pool-name: DevLogHikariCP
max-lifetime: 200000
connection-timeout: 30000위와 같이 설정하였는데 각각의 지표가 무엇을 의미하는지 정리해 보았습니다.
- minimum-idle : DBCP에서 유지하는 최소한의 idle connection 수입니다.
- maximum-pool-size : DBCP에서 가질 수 있는 최대 Connectin 수입니다. idle + active = maximum-pool-size입니다.
- max-lifetime : DBCP에서 커넥션 최대 수명으로 설정값을 넘기면 idle일 경우 DBCP에서 바로 제거하고 actvie인 경우에는 Pool에 반환된 후 제거됩니다. 단위는 ms, 기본값은 30분, 최소값은 30초, 0으로 설정하면 무제한입니다. DB의 wait_timeout보다 몇 초 짧게 설정해야 합니다. 그 이유는 만약에 max-lifetime이 50s이고 DB의 wait_time이 똑같이 50s이라면 요청이 들어와 BackEnd에 있는 Connection이 active로 바뀌었지만 wait_time이 똑같이 50이라 DB의 도달하지 못하고 close 됩니다.
- connection-timeout : DBCP에서 connection을 받기 위한 대기 시간, API 요청이 들어오고 connection을 할당받기 위해 기다리는 시간입니다. 만약에 Connection을 할당받지 못한다면 SQLException을 뱉어냅니다. 이 지표를 통해서 확인할 수 있는 것은 장기간 트랜잭션을 물고 있는 슬로우 쿼리, OSIV 등이 없는지 확인할 수 있고, DBCP의 connection 수가 부족한 것은 아닌지 생각해볼 수 있습니다.
각각 지표가 무엇인지 살펴보았고 왜 제가 저렇게 설정했는지 이유를 설명해보려고 합니다.
- minimum-idle과 maximum-pool-size를 같게 설정한 이유는 DBCP의 Pool size를 항상 고정하기 위함입니다. 예를들어 minimum-idle이 4이고 maximum-pool-size 10이라면 idle한 coonection이 줄어들 때마다 하나씩 새로 생기겠죠? DBCP를 만든 이유는 TCP 연결이 발생하여 connection을 만드는데 비용이 많이 들어 이 비용을 줄이고자 미리 만들어 둔 것입니다. 따라서 새로 생기는 것은 cpu의 리소를 많이 잡아먹게 됩니다. 그래서 이 수를 고정시키기 위해서는 둘의 설정값을 같게 만들어야 합니다. 그 이유는 maximum-pool-size가 minimum-idle보다 우선순위가 높기 때문입니다. 즉 둘 다 10이라면 하나의 connection이 active가 되어 idle한 connection이 9가 되어도 maximum-pool-size이 10이기 때문에 connection을 새로 생성할 수 없습니다.
- minimum-idle과 maximum-pool-size를 20으로 설정한 이유는 기본이 10이었기 때문에 이를 늘려 20으로 설정하였습니다.
- max-lifetime을 대략 3분으로 설정했는데 그 이유는 트래픽이 몰리는 상황에서는 3분으로 짧게 설정하여도 connection이 종료될 일이 없다고 생각했고 종료된다면 너무 많은 수의 connection을 설정했다고 판단할 수 있을거라 생각했습니다.
- connection-timeout은 default인 30000ms인 30초로 설정했는데 더 짧게 설정해서 DBCP나 슬로워쿼리에 대해서 고려해 볼 수 있었을 거 같습니다. 이 부분은 두 번째 시도에 넣어보겠습니다.
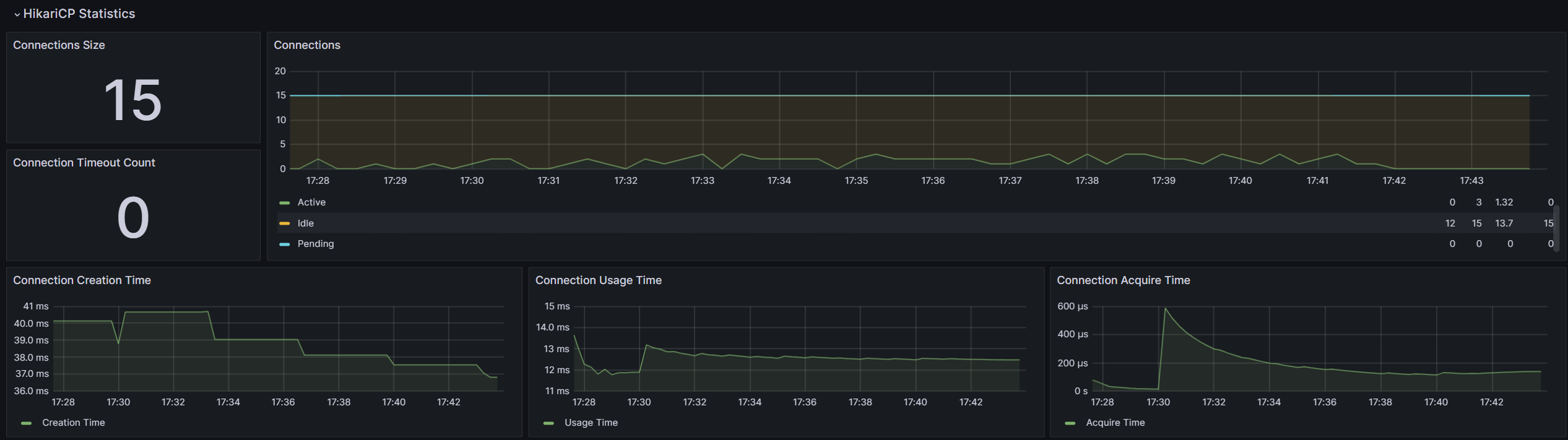
✅ 결과
-
artillery 결과
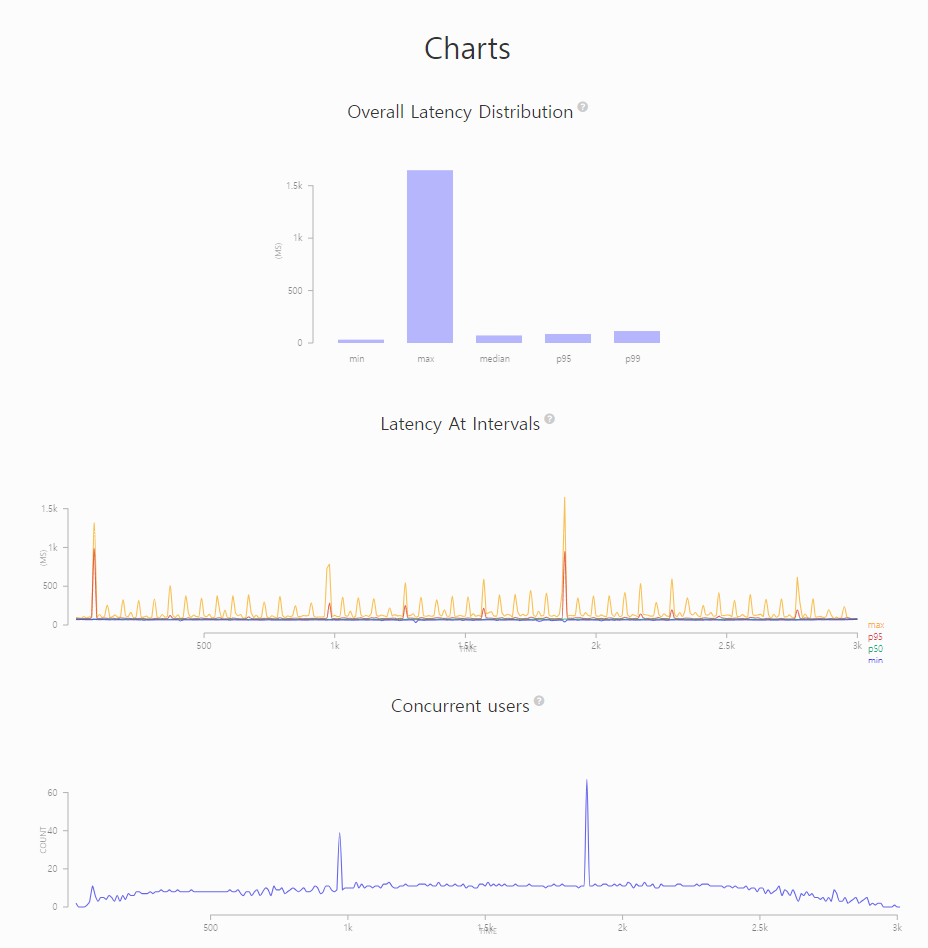
-
서버 모니터링 Grafana
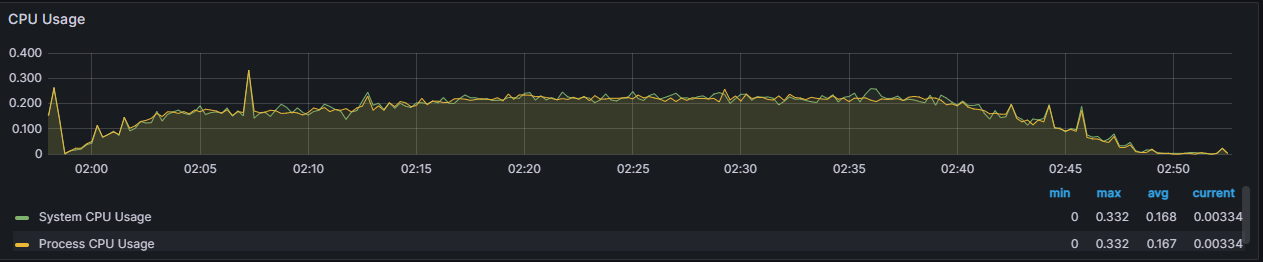
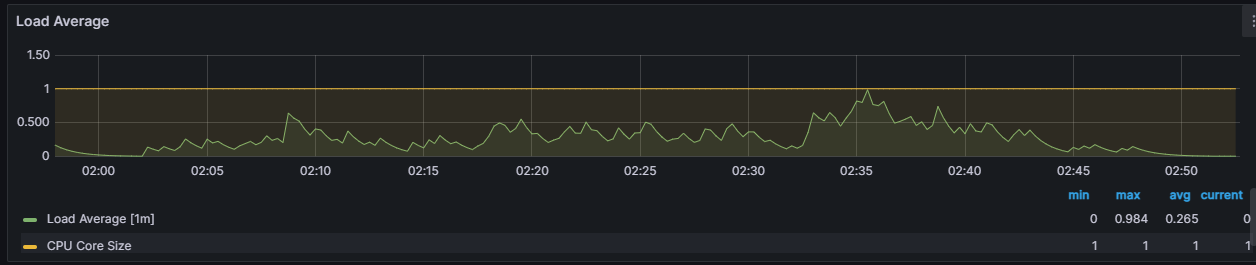

-
RDS 모니터링
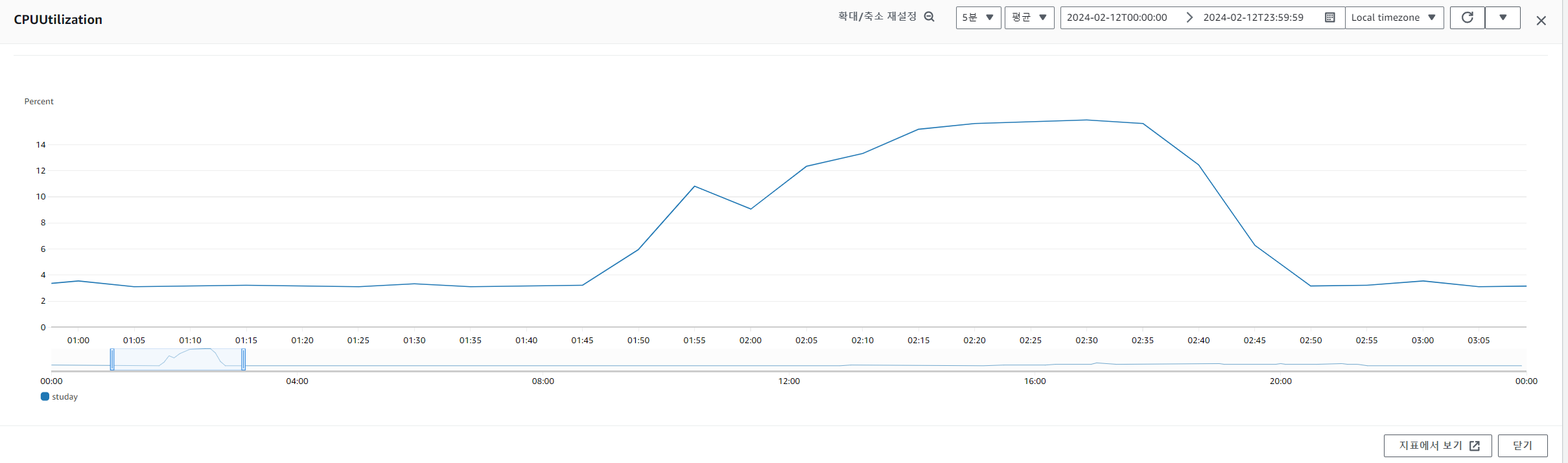
최대 3초에서 반절인 1.5초로 낮아졌지만 20개 중에서 평균 1.43개를 너무 많이 늘린 것은 아닐까라는 의문이 들었습니다. 또한 성능을 높이기 위해서 이렇게 connection의 수를 높이기만 한다면 결국 connection도 자원이기 때문에 어느 순간에는 성능이 나빠질지도 모릅니다. 좋은 해결책은 아닌 거 같았습니다.
📍 Hikari Connection Timeout 설정으로 슬로우 쿼리인지 확인해보기
이번에는 20개였을 때 max active connection이 1.43이었으므로 dbcp의 conntection의 수는 15개로 줄이고 connection timeout을 1000ms인 1초로 두어 슬로우 쿼리인지 확인해보겠습니다.
spring:
datasource:
hikari:
minimum-idle: 15
maximum-pool-size: 15
idle-timeout: 30000
pool-name: DevLogHikariCP
max-lifetime: 200000
connection-timeout: 1000✅ 결과
결과가 아주 재미있게 나왔습니다.
- 서버 Grafana
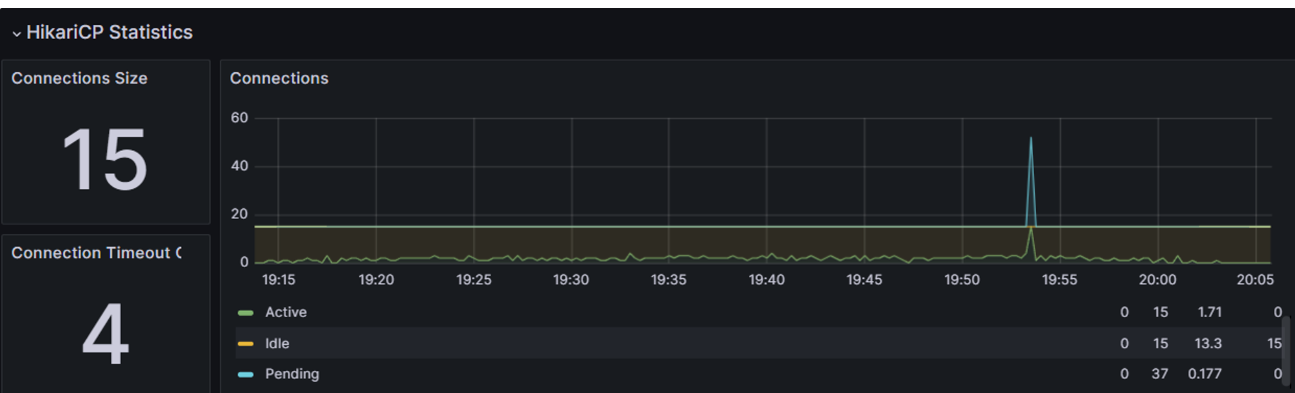
- 서버 로그
Feb 15 19:45:01 ip-10-0-15-135 java[386]: Caused by: org.hibernate.exception.JDBCConnectionException: Unable to acquire JDBC Connection [DevLogHikariCP - Connection is not available, request timed out after 1000ms.] [n/a]
Feb 15 19:45:01 ip-10-0-15-135 java[386]: at org.hibernate.exception.internal.SQLExceptionTypeDelegate.convert(SQLExceptionTypeDelegate.java:49) ~[hibernate-core-6.2.13.Final.jar!/:6.2.13.Final]
Feb 15 19:45:01 ip-10-0-15-135 java[386]: at org.hibernate.exception.internal.StandardSQLExceptionConverter.convert(StandardSQLExceptionConverter.java:56) ~[hibernate-core-6.2.13.Final.jar!/:6.2.13.Final]
Feb 15 19:45:01 ip-10-0-15-135 java[386]: at org.hibernate.engine.jdbc.spi.SqlExceptionHelper.convert(SqlExceptionHelper.java:108) ~[hibernate-core-6.2.13.Final.jar!/:6.2.13.Final]
Feb 15 19:45:01 ip-10-0-15-135 java[386]: at org.hibernate.engine.jdbc.spi.SqlExceptionHelper.convert(SqlExceptionHelper.java:94) ~[hibernate-core-6.2.13.Final.jar!/:6.2.13.Final]결국 4번 SQLException이 발생했습니다.
위 Grafana를 보면 갑자기 뾰족한 봉우리가 보일 겁니다. 해석해보면 총 15개의 connection이 active한 상태에서 대기하는 요청이 1초 이내에 connection을 얻지 못했고 이 횟수가 4번이 발생했다는 의미입니다.
결국은 쿼리가 너무 느려서 1초 이내에 connection을 다시 반납하지 못해 4번의 SQLException이 발생하였던 것이죠
따라서 저는 쿼리를 개선해보기로 하였습니다.
이는 세 번째 시도에서 살펴보도록 하겠습니다.
📍 요청 당 2번 나가는 쿼리 횟수 1번으로 개선하기
일단 제가 먼저 생각했던 것은 쿼리가 몇 번 나가는지 였습니다.
현재 complexes-scroll?lat=37.493182&lng=127.056705&pageNumber=0은 총 2번의 쿼리가 나갑니다.
- 중심 위, 경도에 해당하는 반경 2KM 이내의 학원 목록 중 해당 페이지에 해당하는 학원 10개 반환
➡️ academies table 및 categorie 등의 관련 join 쿼리 - 중심 위, 경도가 어떤 지역 이름에 위치하는지 시도, 시군구, 읍면동 반환
➡️ regions table 조회 쿼리
{
"academiesByLocationResponse": [
{
"academyId": 31531,
"academyName": "토브피아노교습소",
"address": "서울특별시 강남구 개포로 516, 201-4호 (개포동, 개포주공아파트)",
"contact": " ",
"categories": [
"예체능"
],
"latitude": 37.4886321,
"longitude": 127.0704418,
"shuttleAvailable": "NEED_INQUIRE",
"isLiked": false
}
],
"sido": "서울시",
"sigungu": "강남구",
"upmyeondong": "대치동",
"hasNext": true
}저는 regions table 조회를 다른 api로 분리하여 호출하기로 하였습니다. 왜냐하면 실제로 학원 목록 조회에서는 시도, 시군구, 읍면동 데이터가 필요하지 않았습니다. 하지만 같이 준 이유는 아래와 같이 해당 필터를 누르면 해당 중심 위치에 해당하는 지역이름이 필요했기 때문입니다. 지금 살펴보니 자원도 다르고 로직 자체도 분리될 필요성이 뚜렷하게 보입니다.
즉 complexes-scroll?lat=37.493182&lng=127.056705&pageNumber=0 요청이 오면
academies table 및 categorie 등의 관련 join 쿼리만 실행하도록, 1번의 쿼리만 나가도록 바꿨습니다.
✅ 결과
- artillery
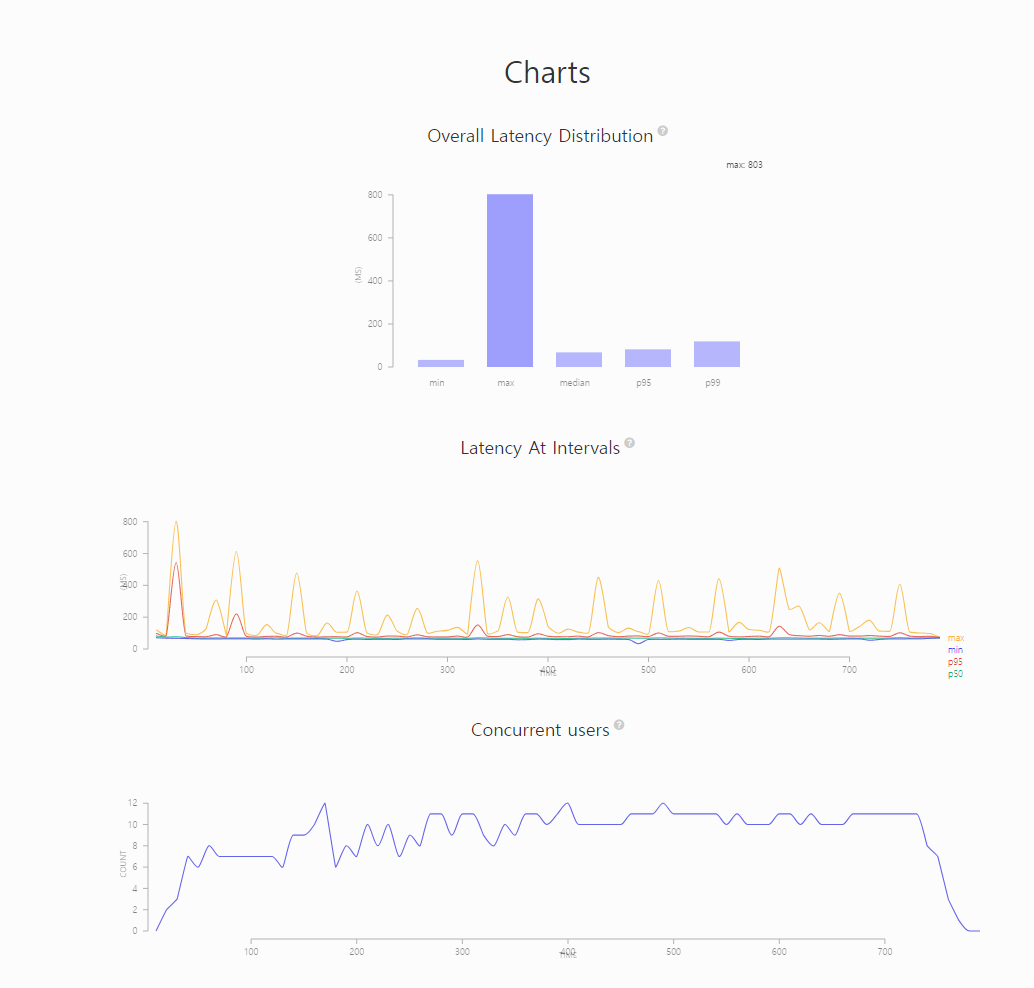
결과를 보면 최대 레이턴시가 803ms로 15000ms에서 1/2로 개선되었음을 확인할 수 있습니다."aggregate": { "timestamp": "2024-02-16T06:12:40.559Z", "scenariosCreated": 45712, "scenariosCompleted": 45712, "requestsCompleted": 45712, "latency": { "min": 33, "max": 803, "median": 68, "p95": 82, "p99": 119 }, "rps": { "count": 45712, "mean": 58.47 }, "scenarioDuration": { "min": 136.7, "max": 886.7, "median": 155, "p95": 179.3, "p99": 216.8 }, "scenarioCounts": { "0": 45712 }, "errors": {}, "codes": { "200": 45712 },
하지만 여전히 109ms는 달성하지 못했습니다. - Grafana

CPU도 60% 이내의 사용으로 양호해보입니다.
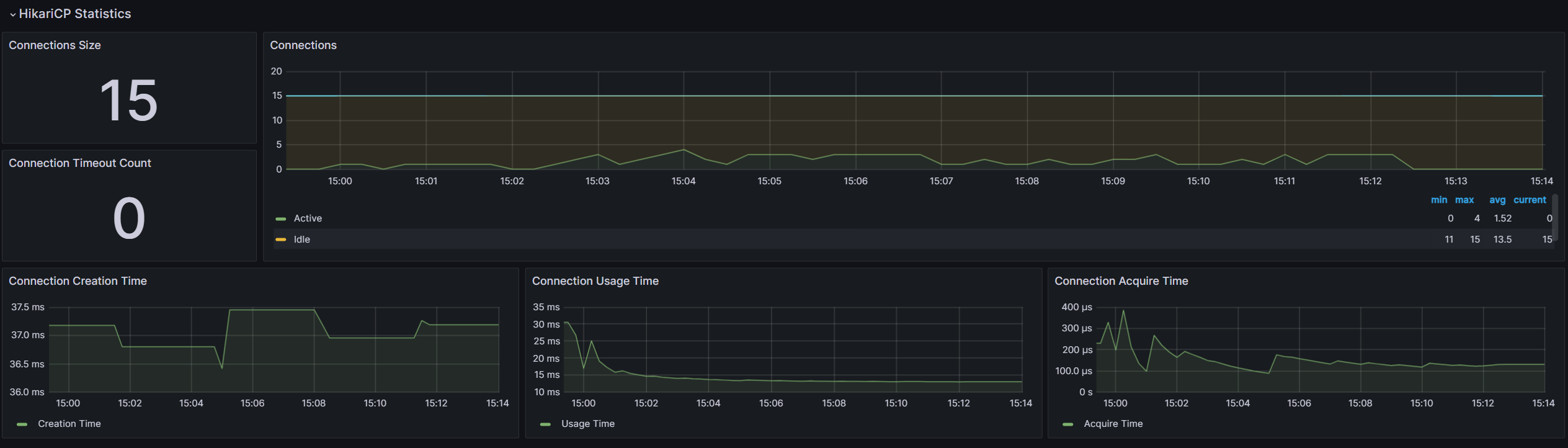
connection timeout이 발생하지 않았습니다. 제 예상대로 regions 테이블을 조회하면서 쿼리가 2번 나가 발생했던 병목으로 확인되었습니다. - RDS 서버
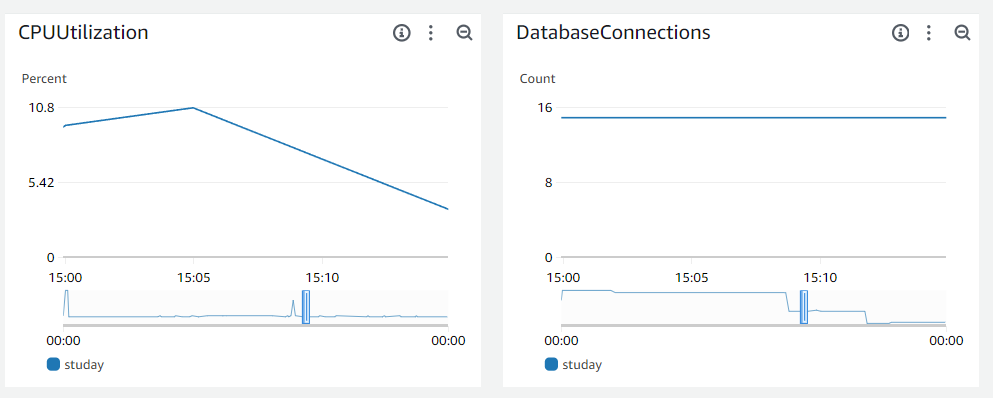
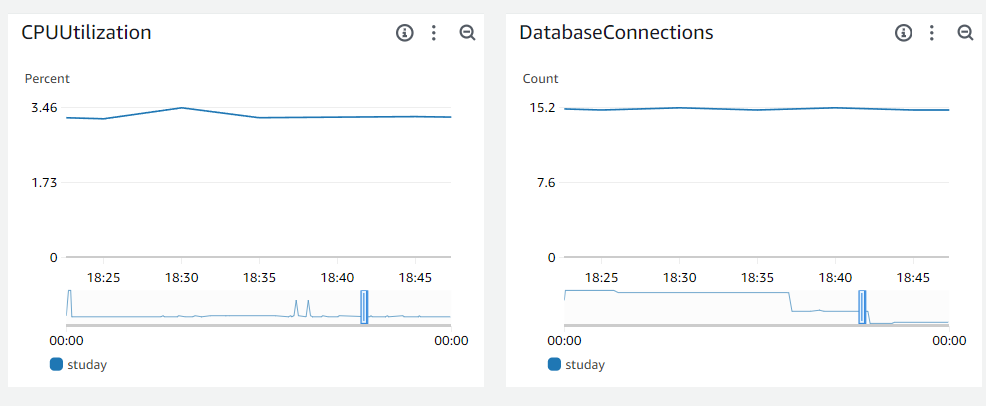
RDS CPU도 60%로 양호해보입니다.
📍 오프셋에서 커서 기반으로 변경하여 슬로우 쿼리 개선하기
학원 목록을 조회하는 쿼리에서 오프셋 방식에서 커서 기반으로 변경해 보았습니다.
explain을 통해서 실행 계획을 보면 둘 다 동일한 실행계획을 가져옵니다.

이전에 오프셋을 사용했던 이유는 학원 데이터가 추가될 경우가 적어 간편한 오프셋을 선택하게 되었습니다. 또한 범위에 해당하는 최대 400개의 데이터로 데이터의 양이 적다고 생각했습니다. 하지만 오프셋의 경우 앞에서부터 전부 읽고 그 중에서 해당하는 범위를 잘라내기 때문에 부하가 몰릴수록 비효율적일 거라는 생각을 하게 되었습니다.
그래서 커서 기반으로 수정해서 부하테스트를 진행해 보았습니다.
- 오프셋 (뱐경 전)
SELECT a.id AS academyId, a.academy_name AS academyName, a.phone_number AS phoneNumber, a.full_address AS fullAddress, a.latitude AS latitude, a.longitude AS longitude, a.shuttle AS shuttleAvailable, (CASE WHEN l.academy_id IS NOT NULL THEN true ELSE false END) AS isLiked, ac.category_id AS categoryId FROM academies AS a INNER JOIN academy_categories AS ac ON a.id = ac.academy_id left JOIN likes AS l ON a.id = l.academy_id where MBRContains(ST_LINESTRINGFROMTEXT('LINESTRING(37.457634 127.154890, 37.432197 127.122852)',4326), a.point) ORDER BY a.id ASC LIMIT 10 offset 40; - 커서 기반 (변경 후)
SELECT a.id AS academyId, a.academy_name AS academyName, a.phone_number AS phoneNumber, a.full_address AS fullAddress, a.latitude AS latitude, a.longitude AS longitude, a.shuttle AS shuttleAvailable, (CASE WHEN l.academy_id IS NOT NULL THEN true ELSE false END) AS isLiked, ac.category_id AS categoryId FROM academies AS a INNER JOIN academy_categories AS ac ON a.id = ac.academy_id LEFT JOIN likes AS l ON a.id = l.academy_id AND l.member_id = 1 WHERE MBRContains(ST_LINESTRINGFROMTEXT('LINESTRING(37.510598 127.109216, 37.485161 127.077155)',4326), a.point) AND a.id >28994 ORDER BY a.id ASC LIMIT 10;
✅ 결과
- artillery
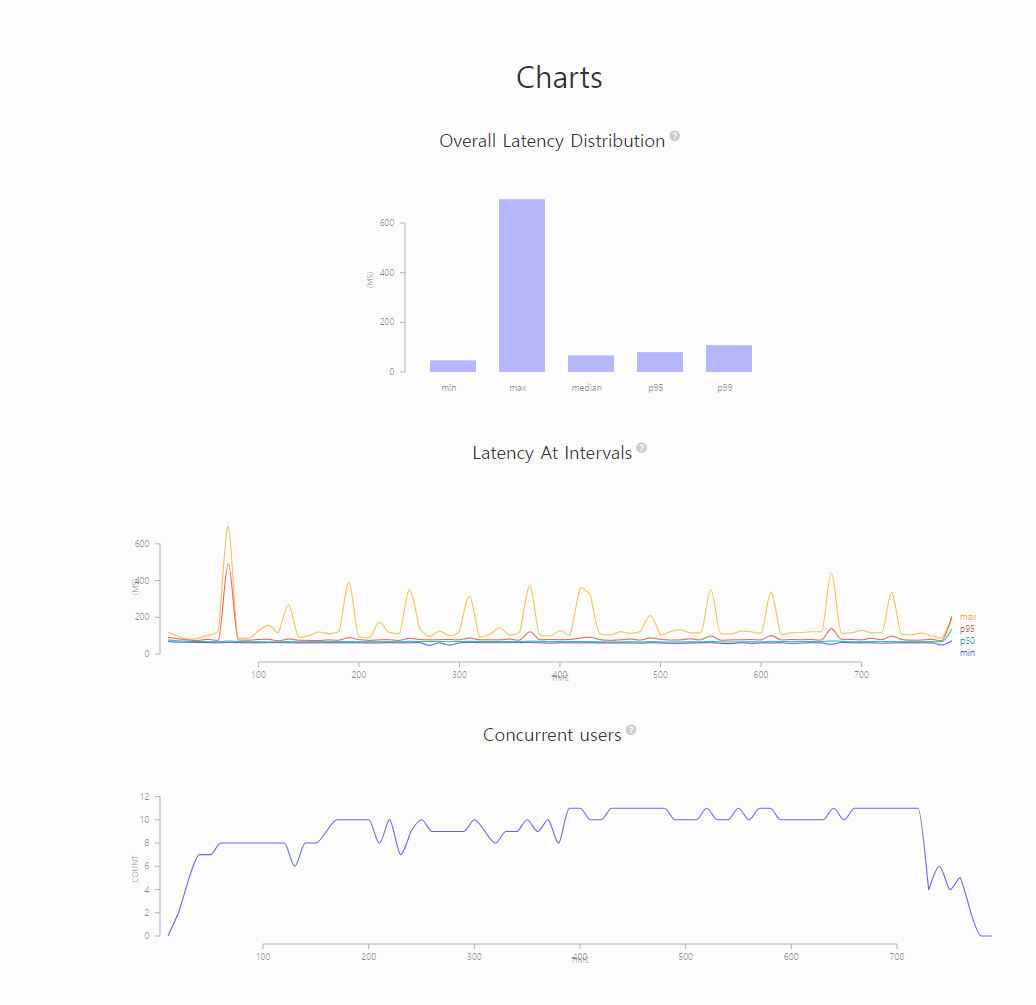
결과를 보면 오프셋 방식보다 최대 레이턴시가 696ms로 100ms 가까이 줄어들었습니다. 또한 p99가 108ms로 원하던 109ms보다 낮게 나왔습니다."aggregate": { "timestamp": "2024-02-17T08:42:03.022Z", "scenariosCreated": 45839, "scenariosCompleted": 45839, "requestsCompleted": 45839, "latency": { "min": 47, "max": 696, "median": 67, "p95": 80, "p99": 108 }, "rps": { "count": 45839, "mean": 58.67 }, "scenarioDuration": { "min": 138.5, "max": 777.7, "median": 152.7, "p95": 176.9, "p99": 206.1 }, "scenarioCounts": { "0": 45839 }, "errors": {}, "codes": { "200": 45839 },
하지만 아직도 최대가 높아서 캐시를 이용해서 네트워크 비용을 줄이는 방식을 생각해보았습니다. 이를 위해서는 쿼리에서 좋아요 여부를 분리해보려고 합니다.
좋아요와의 join이 있어서 다른 회원이 같은 위치에 요청을 보내면 캐시의 효율이 떨어지기 때문입니다. - Grafana
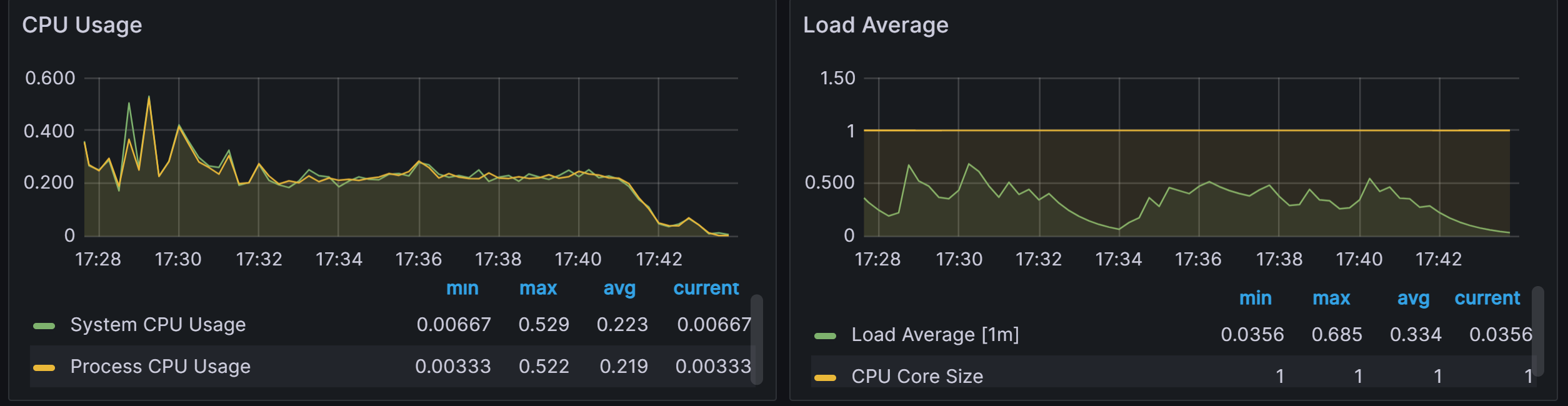
둘 다 양호해보입니다.
- RDS 서버
📍 join 쿼리 분리하여 잘 변하지 않은 데이터를 가진 쿼리만 2차 캐시 이용해보기
위 말과 같이 like join 쿼리를 분리하기로 하였습니다.
데이터 베이스에서 잘 변하지 않는 데이터를 2차 캐시에 적용하는게 올바른 선택이라고 생각했습니다.
그래서 라이크 쿼리는 사용자마다 좋아요 여부가 다르다고 판단하였습니다.
근데 그 과정에서 서버와 RDS의 사양이 더 축소되는 상황으로 바뀌게 되었습니다 😢
똑같은 환경에서 성능 테스트가 진행되지 않는 점을 유념하시고 글을 읽어주시기 바랍니다.
- 라이크 쿼리 분리 전
SELECT a.id AS academyId, a.academy_name AS academyName, a.phone_number AS phoneNumber, a.full_address AS fullAddress, a.latitude AS latitude, a.longitude AS longitude, a.shuttle AS shuttleAvailable, (CASE WHEN l.academy_id IS NOT NULL THEN true ELSE false END) AS isLiked, ac.category_id AS categoryId FROM academies AS a INNER JOIN academy_categories AS ac ON a.id = ac.academy_id LEFT JOIN likes AS l ON a.id = l.academy_id AND l.member_id = 1 WHERE MBRContains(ST_LINESTRINGFROMTEXT('LINESTRING(37.510598 127.109216, 37.485161 127.077155)',4326), a.point) AND a.id >28994 ORDER BY a.id ASC LIMIT 10; - 라이크 쿼리 분리 후
SELECT a.id AS academyId, a.academy_name AS academyName, a.phone_number AS phoneNumber, a.full_address AS fullAddress, a.latitude AS latitude, a.longitude AS longitude, a.shuttle AS shuttleAvailable, ac.category_id AS categoryId FROM academies AS a INNER JOIN academy_categories AS ac ON a.id = ac.academy_id WHERE MBRContains(ST_LINESTRINGFROMTEXT('LINESTRING(37.510598 127.109216, 37.485161 127.077155)',4326), a.point) AND a.id >28994 ORDER BY a.id ASC LIMIT 10;
바뀐 서버 사양
t2.mico, db.t2.miro로 변경되었습니다.
✅ 결과
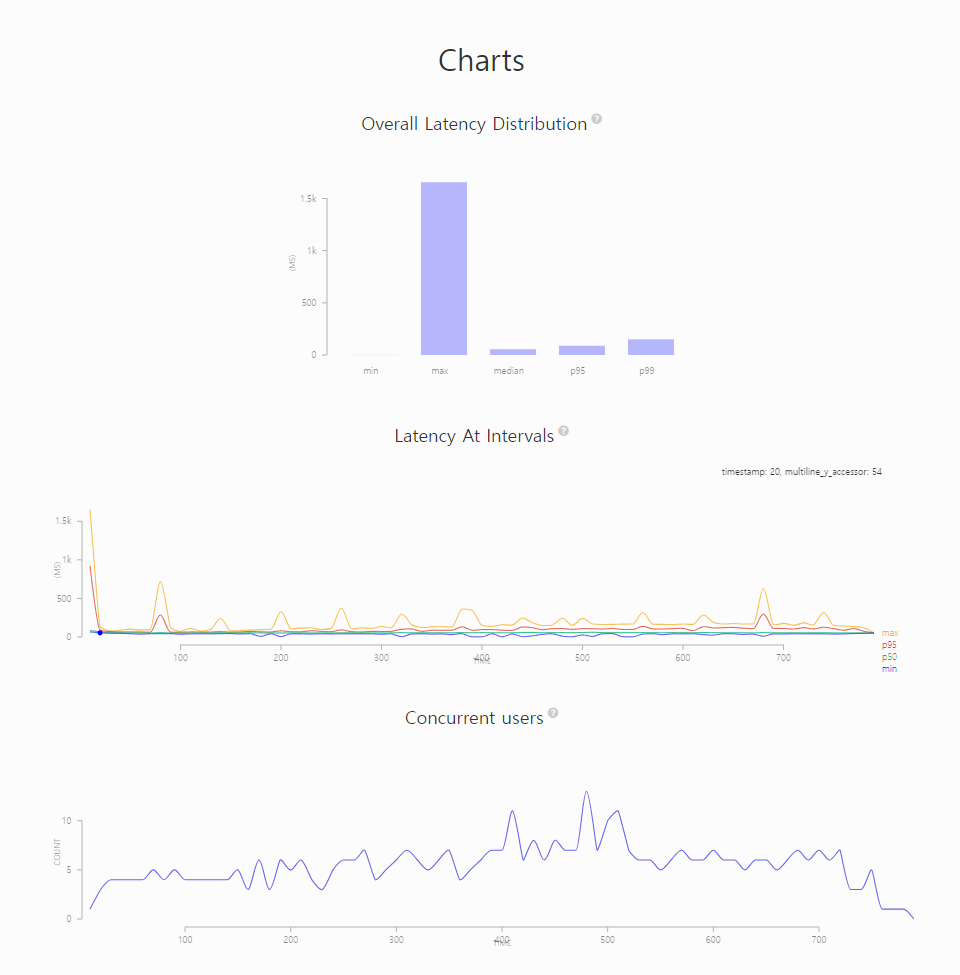
오히려 성능이 나빠졌습니다.
아무래도 2배 많은 네트워크 비용이 발생하기 때문이지 않을까 생각합니다.
또한 최대인 1,656ms가 제 생각에는 처음 warm-up이 제대로 되지 않아서 발생하지는 않았을까 생각했습니다.
그래서 그 부분에 대해서 max로 잡는 것이 올바른 것일까도 생각해봐야할 거 같습니다.
p99가 150ms여서 아무래도 좋은 선택은 아니었던 거 같습니다.
{
"aggregate": {
"timestamp": "2024-02-23T10:26:52.020Z",
"scenariosCreated": 45727,
"scenariosCompleted": 45727,
"requestsCompleted": 45727,
"latency": {
"min": 2,
"max": 1656,
"median": 55,
"p95": 89,
"p99": 150
},🔖 결론
그래서 결국 저는 제가 목표로 하는 70 vuser의 109ms가 나오는 상황을 만드는데는 실패했습니다.
하지만 앞서 말씀드린 내용과 같이 다음 지도의 서버 사양과 저희 스터데이의 서버 사양은 큰 차이가 있을 것입니다. 그래서 목표치 산정에서 너무 이상적으로 수치를 계산한 부분도 있을 것이라 생각합니다. 이렇게 서버 사양이 다른 환경에서 어떻게 목표치를 산정해야 하는지도 생각해야할 부분으로 남아 있습니다.
🔗 부록
Artillery 이용하는 방법
- 공식문서 : https://www.artillery.io/docs
- 간단하게 이용하는 방법입니다.
터미널에 아래와 같이 입력해주세요.- 시나리오 작성하기
config: target: '테스트하고자 하는 도메인 주소를 이 따옴표 안에 넣어주세요' phases: - duration: 60 arrivalRate: 1 rampTo : 50 name: 테스트 이름, 1부터 50까지 점점 부하를 늘려가는데 그 시간은 1분동안 입니다. - duration: 60 arrivalRate: 50 name: 테스트 이름, 50을 1분간 유지합니다. - path: "access-token.csv" fields: - "token" - path: "complex-scroll.csv" fields: - "lat" - "lng" - "pageNumber" scenarios: - flow: - get: url: "/academies/complexes-scroll?lat={{ lat }}&lng={{ lng }}&pageNumber={{ pageNumber }}" headers: authorization: "Bearer {{ token }}"- 시나리오 작동하기
artillery run --output report_fourth.json test-config.yaml - json 결과물을 html으로 바꾸기
artillery report report_fourth.json --output report_fourh.html
