로그인 구현을 마치고 게시글 목록 생성 부분을 맡게 되어 정리해보려고 합니다.
📑Pagination이란?
목록을 생성하기에 앞서 우리는 이를 페이지로 구현할 것인지 아니면 무한 스크롤로 구현할 것인지 결정해야 했습니다.
이렇게 검색 결과를 가져올 때 데이터를 쪼개 번호를 매겨 일부만 가져오는 기법을 Pagination이라고 합니다. 만약에 Pagination을 적용하지 않는다면 DB에 저장된 모든 데이터를 한번에 뿌려야 합니다. DB에 저장된 모든 데이터를 가져오는데는 많은 시간이 소요됩니다.
Pagenation을 구현하는 방법에는 Offset방식과 Cursor방식이 있습니다.
- Offset 방식 : Offset과 Limit 예약어를 통하여 Select의 전체 결과 중 일부만 가져오는 방법
- Cursor 방식 : Cursor는 어떠한 레코드를 가리키는 포인터이고 이 Cursor가 가리키는 레코드부터 일정 개수만큼 가져오는 방식입니다. Seek Method, KeySet Pagination이라고도 합니다.
Offset 방식
클라이언트는 페이지 당 요청하는 자료 개수와 현재 페이지 번호를 파라미터로 요청합니다.
서버에서는 오프셋값을 구하고 이 값은 쿼리의 OFFSET 부분에 입력되는 값입니다.
| 현재 페이지 | 페이지 당 요청 개수 | 수식 | 오프셋 |
|---|---|---|---|
| 1 | 40 | (1-1)x40 | 0 |
| 2 | 40 | (2-1)x40 | 40 |
| 3 | 40 | (3-1)x40 | 80 |
| 4 | 40 | (4-1)x40 | 120 |
| 5 | 40 | (5-1)x40 | 160 |
SELECT * FROM PRODUCT LIMIT {페이지 당 자료의 개수} OFFSET{오프셋}
SELECT * FROM PRODUCT LIMIT 40 OFFSET 0; //1~40
SELECT * FROM PRODUCT LIMIT 40 OFFSET 40; // 41~80
SELECT * FROM PRODUCT LIMIT 40 OFFSET 80; // 81~ 120
SELECT * FROM PRODUCT LIMIT 40 OFFSET 120; // 121 ~ 160이 Offset 방식에는 성능 저하의 문제가 발생할 수 있습니다.
offset 값이 1억인 경우 1억개의 데이터를 모두 읽은 뒤에 다음 40개의 데이터를 조회하여 응답합니다. 따라서 뒤로 갈수록 읽어야 하는 데이터가 많아지고 점점 느려집니다.
또한 offset 방식은 데이터의 잦은 추가와 삭제가 있을 경우 데이터의 중복과 누락이 발생할 수 있습니다.
정리하면
일반적인 방식으로 쿼리가 복잡하지 않습니다.
다양한 정렬 방식을 쉽게 구현할 수 있습니다.
프론트 엔드에서 Pagination Bar를 구현할 수 있고 이런 장점은 Pagination을 간단하고 빠르게 구현할 수 있다는 장점이 있습니다.
하지만 페이지가 뒤로 갈수록 쿼리의 속도가 매우 느려집니다.
데이터의 잦은 추가와 삭제가 이뤄질 경우 누락과 중복이 발생할 수 있습니다.
Cursor 방식
SELECT * FROM PRODUCT LIMIT 40
SELECT * FROM PRODUCT WHERE ID > {기준값} LIMIT 40;
SELECT * FROM PRODUCT WHERE ID > 40 LIMIT 40;
SELECT * FROM PRODUCT WHERE ID> 80 LIMIT 40;
SELECT * FROM PRODUCT WHERE ID> 120 LIMIT 40;
SELECT * FROM PRODUCT WHERE ID > 160 LMIMT 40;CUROR 방식은 WHERE절에 들어가는 칼럼은 중복이 일어나지 않는 칼럼을 사용해야 합니다.
OFFSET 방식과 다르게 CURSOR 방식은 전체 데이터를 읽은 후 범위에 맞는 값만 남기고 나머지를 버리는 방식이 아닌 조건문에 맞는 값만 조회하게 되어
SNS와 같이 실시간으로 데이터가 추가되거나 삭제되는 서비스에 이용됩니다.
정리
SNS와 같이 복잡한 정렬이 필요없는 대용량 시스템에서는 CURSOR 방식이 필수적
온라인 마켓플레이스와 같은 서비스에서는 상품 검색이 자세할 수 있어 상품 개수가 줄기 때문에 OFFSET 방식이 어울립니다.
그렇다면 제가 구현하려는 무한스크롤 방식은 어떤 Pagination 방식에 어울릴까 생각하게 되었습니다.
일단 저의 프로젝트의 경우 사용자로부터 게시글 삭제와 추가가 빈번하게 일어나 무한스크롤로 구성하는 것이 더 적합하다고 생각했기 때문에 무한스크롤로 결정하게 되었습니다.
위 이유에 따라 cursor 기반의 무한스크롤 방식을 사용하기로 결정하였습니다.
실제 어떻게 구현해야 하는지 살펴보겠습니다.
Spring Data JPA를 통해 어떻게 Pagination을 구현할까?
다음은 순수한 JPA로 만든 쿼리문입니다.
List<Item> items =
entityManager.createQuery("select i from Item i", Item.class)
.setFirstResult(0)
.setMaxResults(10)
.getResultList();setFirstResult를 통해서 결과를 조회해 올 시작점을 지정합니다.-> OFFSET
그리고 setMaxResults를 통해서 조회해 올 최대 데이터 수를 지정합니다. -> LIMIT
하지만 위 방식으로 Pagination을 구현한다고 했을 때 매번 조회해올 시작점과 최대 데이터 수를 지정해야하는 번거로움이 존재합니다.
따라서 Spring Data JPA는 이런 Pagination도 추상화하여 제공합니다.
페이지 크기와 순서만 전달하면 DB에서 해당 페이지에 해당하는 데이터만 가져올 수 있습니다.
Pageable과 PageRequest
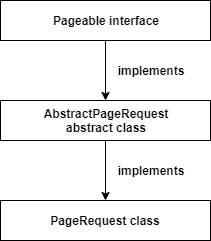
Spring Data에서 제공하는 페이지네이션 정보를 담기 위한 인터페이스 구현체
페이지 번호와 단일 페이지 개수를 담을 수 있습니다.
이를 Spring Data JPA 레포지토리의 파라미터로 전달하여 반환되는 엔티티의 컬렉션에 대해 페이징을 할 수 있습니다.
- PageRequest 생성
첫번째 파라미터는 페이지 순서, 두번째 파라미터는 단일 페이지 크기PageRequest page = PageRequest.of(0, 10);
페이지 순서는 0부터 시작 - Pageable의 ofSize()
Pageable 인터페이스는 ofSize()라는 스태틱 메서드를 제공.Pageable.ofSize(10);
이 메소드를 통해소 PageRequest를 생성할 수 있습니다.
단, 페이지 번호는 0으로 고정되고 페이지 사이즈만 설정
조회 결과 정렬
Sort 클래스 혹은 Sort 내부 enum클래스인 Direction 사용하여 정렬
PageRequest.of(0, 10, Sort.by("price").descending());
PageRequest.of(0, 10, Sort.by(Direction.DESC, "price"));
PageRequest.of(0, 10, Sort.by(Order.desc("price")));
PageRequest.of(0, 10, Direction.DESC, "price");Slice와 Page
Spring Data JPA 레포지토리에 Pageable을 전달하면 반환 타입으로 Slice 혹은 페이지를 받을 수 있습니다.
두 인터페이스 모두 Pagination을 통한 조회 결과를 저장하는 역할을 합니다.
Slice
전체 페이지 개수 = 전체 데이터 개수 / 단일 페이지 크기
이를 계산하기 위해서는 전체 데이터 개수를 알아야합니다.
이는 count 쿼리를 실행하여 계산합니다.
하지만 Slice는 count쿼리를 실행할 필요가 없습니다.
따라서 이를 실행하는데 드는 비용을 절역할 수 있습니다.
현재 제가 구현하고자 하는 무한스크롤 방식은 전체 페이지 개수가 필요없기 때문에 Slice를 적용하는 것이 적절해보입니다.
public interface ItemRepository extends JpaRepository<Item, Long> {
Slice<Item> findSliceByPrice(int price, Pageable pageable);
}for (int i = 1; i <= 40; i++) {
itemRepository.save(new Item("상품" + i, 5000));
}
Slice<Item> itemSlice = itemRepository.findSliceByPrice(5000, PageRequest.of(0, 5));
for (Item item : itemSlice.getContent()) {
System.out.println(item.getName());
}
//결과
//상품1
//상품2
//상품3
//상품4
//상품5Slice 내부 코드
public interface Slice<T> extends Streamable<T> {
int getNumber(); // 현재 Slice 번호를 반환
int getSize(); // 현재 Slice 크기를 반환
int getNumberOfElements(); // 현재 Slice가 가지고 있는 엔티티의 개수 반환
List<T> getContent(); // 엔티티 목록을 List로 반환
boolean hasContent(); // 엔티티 목록을 가지고 있는지 여부를 반환
Sort getSort(); // Slice의 Sort 객체를 반환
boolean isFirst(); // 현재 Slice가 첫번째인지 여부를 반환
boolean isLast(); // 현재 Slice가 첫번째인지 여부를 반환
boolean hasNext(); // 다음 Slice의 존재 유무를 반환
boolean hasPrevious(); // 이전 Slice의 존재 유무를 반환
default Pageable getPageable() {
return PageRequest.of(getNumber(), getSize(), getSort());
} // (디폴트 메소드) 현재 Slice에 대한 Pageable을 생성해서 반환
Pageable nextPageable(); // 다음 Pageable을 반환
Pageable previousPageable(); // 이전 Pageable을 반환
<U> Slice<U> map(Function<? super T, ? extends U> converter);
// Slice 내의 엔티티를 다른 객체로 매핑
default Pageable nextOrLastPageable() {
return hasNext() ? nextPageable() : getPageable();
} // (디폴트 메소드) 다음 Slice가 있다면 다음 Pageable을, 현재 Slice가 마지막이면 현재 Pageable을 반환
default Pageable previousOrFirstPageable() {
return hasPrevious() ? previousPageable() : getPageable();
} // (디폴트 메소드) 이전 Slice가 있다면 이전 Pageable을, 현재 Slice가 첫번째면 현재 Pageable을 반환
}여기서 드는 의문
Slice는 어떻게 다음 Slice 존재 유무를 판단하는가?
isFirst(),isLast(), hasNext(), hasPrevious()의 작동 원리?
이는 Slice가 설정된 페이지 사이즈보다 +1한 값으로 쿼리를 실행하고
그 쿼리를 통해 +1한 사이즈의 데이터가 존재한다면 다음 데이터가 존재하는 것으로 판단합니다.
Page
Page는 Slice와 다르게 count 쿼리르 실행합니다.
전체 데이터 개수와 전체 페이지 개수를 계산할 수 있습니다.
public interface ItemRepository extends JpaRepository<Item, Long> {
// ...
Page<Item> findPageByPrice(int price, Pageable pageable);
}for (int i = 1; i <= 40; i++) {
itemRepository.save(new Item("상품" + i, 5000));
}
Page<Item> itemPage = itemRepository.findPageByPrice(5000, PageRequest.of(0, 5));
for (Item item : itemPage.getContent()) {
System.out.println(item.getName());
}
//결과
//상품1
//상품2
//상품3
//상품4
//상품5REFERENCE
https://betterdev.tistory.com/17
https://hudi.blog/spring-data-jpa-pagination/
