이번에 42만명의 회원들에게 알림톡을 보내게 되면서 180명의 유저들에게 중복 메시지를 최소 100개 이상 보냈다.
또한 OPEN API의 TPS를 고려하지 않아 TPS 이상의 요청이 들어오면서 OPEN API 서버도 함께 뻗어버렸다.
이 문제를 어떻게 해결해 나갔는지를 정리해보려고 한다.
전체 호출 과정 및 용어 정리
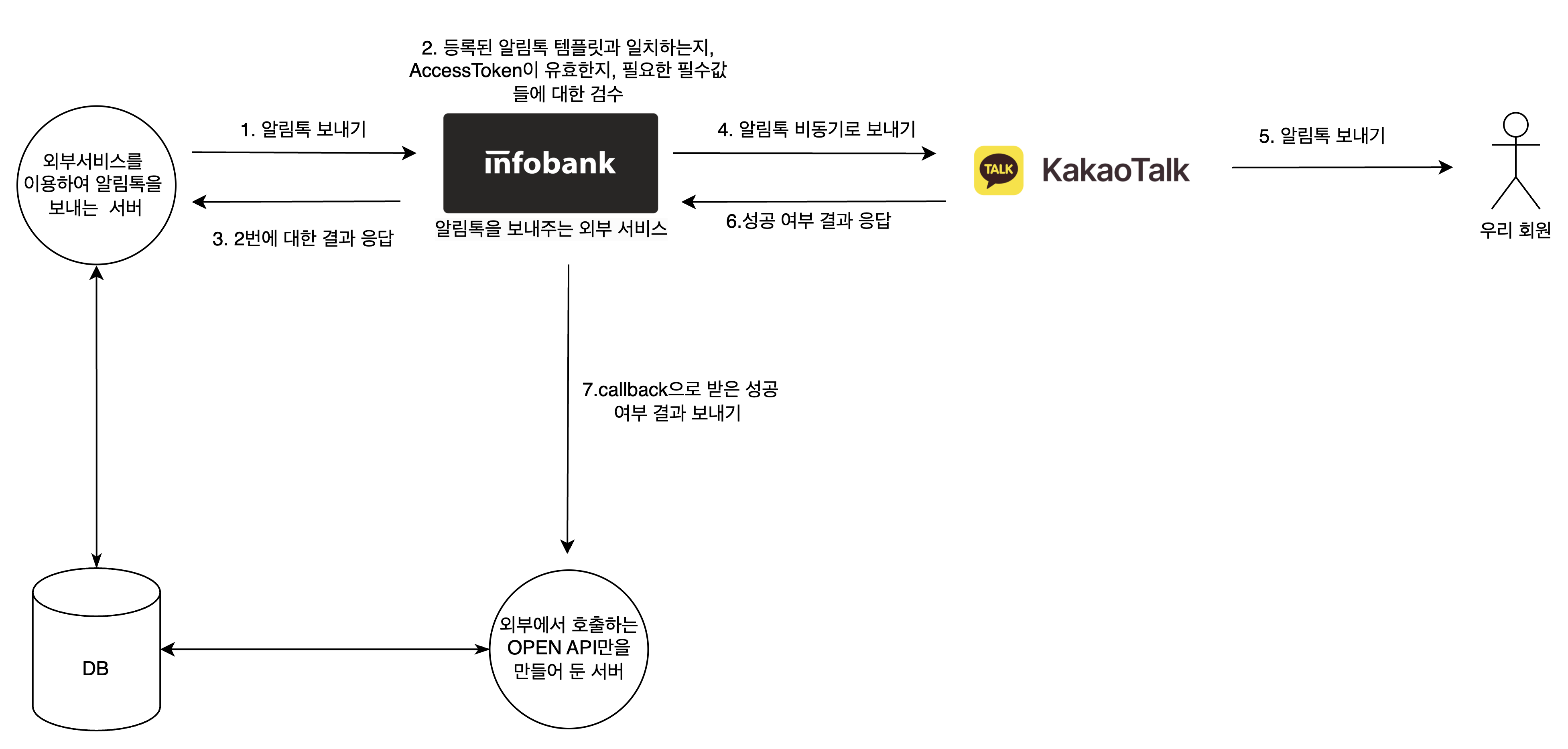
전체 호출 과정은 위와 같다.
7번 과정에서 보충 설명이 필요한데 인포뱅크에게 우리의 open api url을 미리 등록해줬기 때문에 가능한 과정이다.
알림톡이란
카카오톡을 통해 보내는 정보성 메시지이다.
해당 메시지는 "정보성" 메시지이기 때문에 광고성 문구를 넣을 수 없으며 따라서 미리 인포뱅크로부터 해당 메시지 내용을 보내도 되는지 검수를 받아야 한다. 검수를 넣고 승인을 받으면 해당 메시지에 대한 식별자인 템플릿 코드가 생기게 된다. 개발자는 승인된 템플릿 메시지에 대해서 토시 하나 틀리지 않고 회원들에게 알림톡을 보내야 한다. 만약에 실제로 승인 받은 메시지에 쉼표,문자를 추가하면 "전체 호출 과정" 그림의 2번 과정에서 실패가 발생한다.
메시지 중복 발송 문제 해결하기
기존 구조 분석
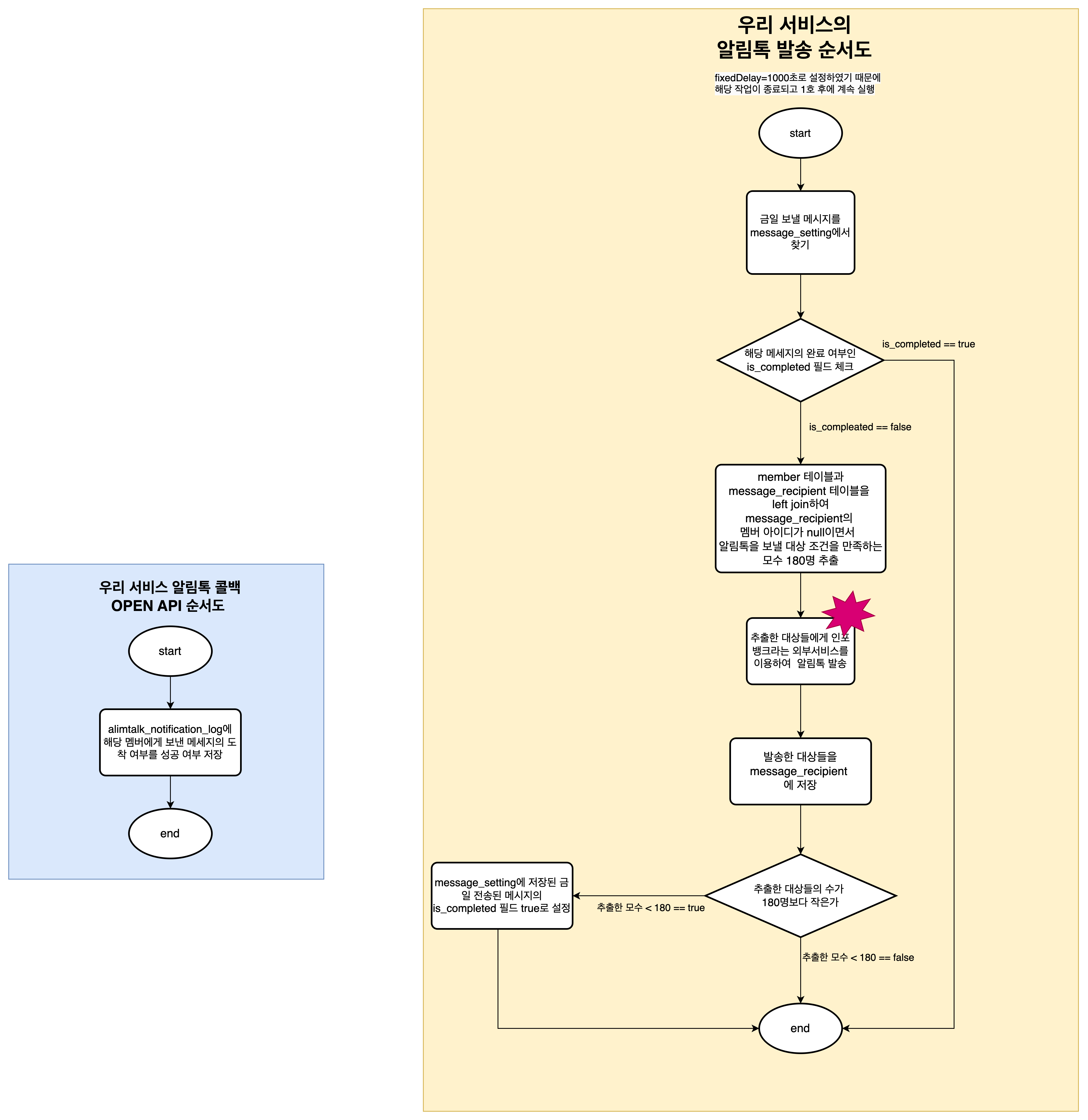
- 알림톡을 발송하는 순서도는 위와 같으며 위 과정은 모두 하나의 트랜잭션으로 운영되었다.
- 외부 서비스를 이용해 알림톡을 발송할 때는 CompletableFuture를 이용해 전용스레드풀을 만들었고 스레드의 개수는 기본 4개, 최대로 늘어날 수 있는 스레드의 개수도 4개, 대기열 큐의 사이즈를 100으로 설정하였다. 비동기로 호출하였기 때문에 해당 요청들의 완료를 기다리지 않고 넘어갔다.
- 외부 서비스의 TPS가 200이므로 이에 맞춰서 LIMIT 180 읽어와서 비동기로 보냈다.
- 또한 TPS를 넘기지 않기 위해서 해당 메서드 실행 완료 1초 뒤에 다시 실행되도록 설정하였다. (@scheduled에 fixedDelay =1000으로 설정)
원인 분석
-
중복 메시지가 발생된 원인은 CompletableFuture 설정의 대기열 큐가 터져 TaskRejectedException이 발생하였고 UncheckedException이기 때문에 알림톡이 발송된 사람을 저장하는 member_recipient 테이블이 롤백되었다. 해당 배치는 1초마다 다시 실행되었고 상위에 위치한 180명에게 똑같은 알림톡이 발송되는 상황이 반복되었다. 로그는 아래와 같다.
org.springframework.core.task.TaskRejectedException: Executor [java.util.concurrent.ThreadPoolExecutor@7098e80b[Running, pool size = 3, active threads = 3, queued tasks = 100, completed tasks = 5578]] did not accept task: java.util.concurrent.CompletableFuture$AsyncRun@2c8d08c7 at org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor.execute(ThreadPoolTaskExecutor.java:363) at java.base/java.util.concurrent.CompletableFuture.asyncRunStage(CompletableFuture.java:1750) at java.base/java.util.concurrent.CompletableFuture.runAsync(CompletableFuture.java:1965) at kr.co.bomapp.domain.rds.alimtalk.recipient.service.AlimTalkRecipientSendService.lambda$sendAlimTalkMessageSetting$4(AlimTalkRecipientSendService.java:134) at java.base/java.util.ArrayList.forEach(ArrayList.java:1541) Caused by: java.util.concurrent.RejectedExecutionException: Task java.util.concurrent.CompletableFuture$AsyncRun@2c8d08c7 rejected from java.util.concurrent.ThreadPoolExecutor@7098e80b[Running, pool size = 3, active threads = 3, queued tasks = 100, completed tasks = 5578] at java.base/java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2055) at java.base/java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:825) at java.base/java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1355) at org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor.execute(ThreadPoolTaskExecutor.java:360) -
대기열 큐 초과의 원인은 아래와 같다.
- LIMIT 180으로 모수들을 읽어왔기 때문에 180개의 발송 요청이 발생했을 것이며, 최대 스레드가 4개였기 때문에 최대 176개는 대기열 큐에서 대기하고 있는 순간이 존재한다. 따라서 설정한 대기열 큐 사이즈 100을 초과하였다.
-
마지막으로 가장 큰 원인은 대규모 발송에도 불구하고 테스트 없이 진행되었고 CompletableFuture의 설정을 제대로 확인하지 않았다는 점이다.
해결책
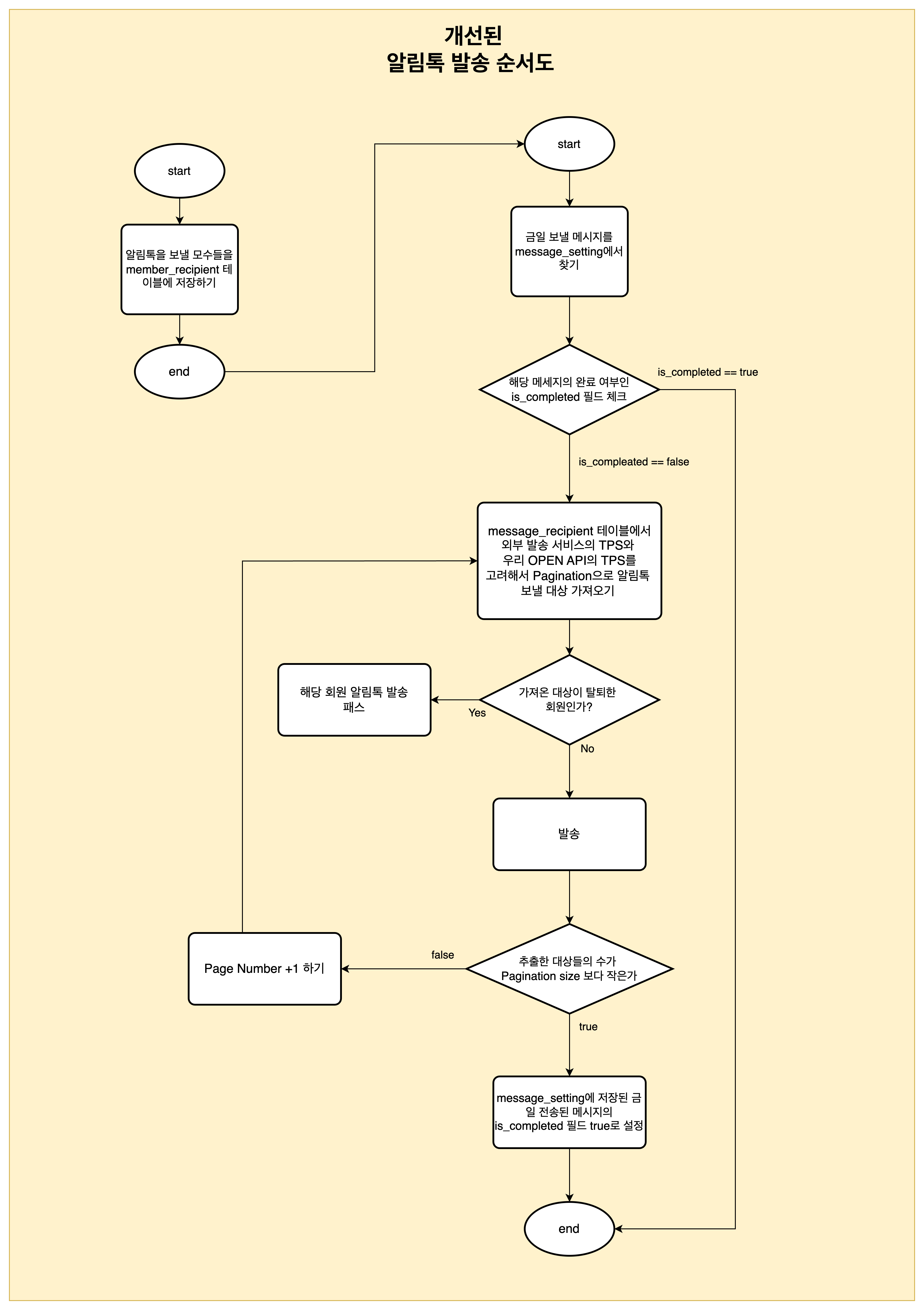
저장 방식 및 코드 흐름 변경
일단 먼저 member_recipient 테이블의 저장 방식을 바꿔 중복 메시지가 발생하지 않는 안정적인 방식으로 바꾸었다.
[AS-IS]
- 기존 시스템에서는 알림톡을 보낸 회원을 member_recipient 테이블에 저장하고 있었다.
- 알림톡 발송 대상은 member 테이블과 member_recipient 테이블을 LEFT JOIN하여, member_recipient에 저장되지 않은 회원 180명을 선별해 발송했다.
- member_recipient에 기록되지 않은 경우 알림톡을 보내지 않았다고 판단하여, 중복 메시지가 발생할 가능성이 남아있었다. 특히, Scheduler의 fixedDelay와 함께 사용되었기 때문에 중복 발송 위험이 더욱 높았다.
- 트랜잭션이 하나로 묶여 있어 문제가 발생했을 때 저장 로직까지 롤백되었다.
[TO-BE]
알림톡 발송 방식은 보다 안전하게 개선되었다.
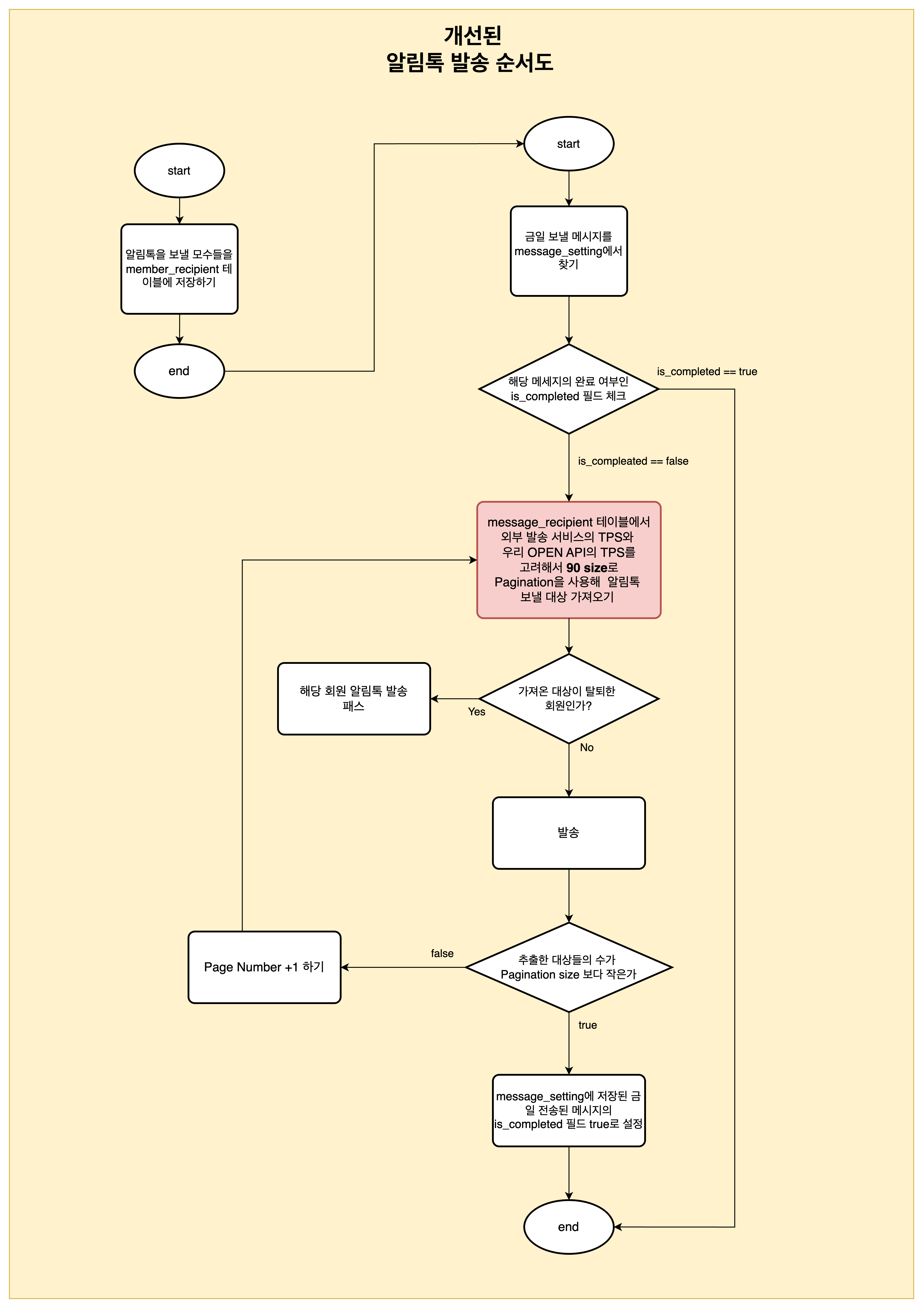
- 알림톡 발송 대상자를 먼저 member_recipient 테이블에 저장한다.
- 이후, member_recipient에서 외부 서비스 및 콜백을 받을 OPEN API 서버의 TPS를 고려하여 Pagination Size를 설정하고, 저장된 대상자들을 읽어와 알림톡을 발송한다.
- TPS를 고려하는 이유는, 외부 서비스에 보내는 TPS와 동일한 수준의 TPS로 OPEN API에 콜백 요청을 보내지기 때문이다.
- 발송 시점에 탈퇴한 회원 여부를 다시 확인하여, 유효하지 않은 대상에게 메시지가 발송되지 않도록 했다.
- Pagination 기반 처리로 전환한 이후, @Scheduled의 cron을 사용하여 발송 시작 일시를 명시적으로 설정하고, 1초마다 재실행되는 fixedDelay=1000 설정을 제거했다. 그러나 지금 생각해보면 하드 코딩된 스케줄은 다른 사람에 의해서 고쳐질 위험이 있고 일정이 바뀔경우 재배포해야하는 번거로움이 존재하는 거 같다. ( 해당 내용은 알림톡 구조 개선기 2에서 바뀔 예정이다)
CompletableFuture 설정 변경
외부 서비스의 TPS 제한 및 Open API의 TPS 제한, 그리고 스레드풀의 기본/최대 개수를 고려하여 비동기 작업 처리에 사용되는 대기열 큐의 크기를 200으로 설정하였다.
발송 작업은 페이징 단위(Pagination Size)로 분할해 비동기로 병렬 처리되며, 각 작업이 모두 완료될 때까지 다음 단계로 진행되지 않도록 하기 위해 다음과 같이 CompletableFuture를 사용하였다:
CompletableFuture.allOf(currentBatchTasks.toArray(new CompletableFuture[0])).join();이를 통해 외부 API의 TPS를 초과하지 않도록 제어하면서도 안정적인 대량 발송 처리를 구현할 수 있었다.
한편, 해당 작업은 I/O Bound 성격이기 때문에 기존에 설정되어 있던 전용 스레드풀의 크기(4개)로는 4개 작업이 모두 완료될 때까지 다음 작업이 대기해야 했다.
이를 개선하기 위해 스레드풀의 최대 스레드 수를 100개로 증가시켰고, 실행 중 CPU 사용률은 최대 38.7% 수준으로 관찰되었다.
CPU 리소스를 고려하면 더 많은 스레드를 설정할 여유가 있었지만, 결국 Open API의 TPS 제한을 초과하지 않기 위해 스레드 수를 100개로 유지하였다.
중복 메시지 테스트
알림톡 발송에는 비용이 발생하기 때문에, 실제 발송 대신 외부 서비스와 동일한 요청/응답 구조를 갖는 Mock Controller를 만들어 테스트를 진행했다.
Mock Controller에서 1초마다 TPS를 측정하여 로그로 출력하고, TPS를 초과하는 순간 예외를 발생시키도록 했다.
중복 메시지 여부 확인 방식
- 회원 ID를 key, 알림톡 수신 횟수를 value로 갖는 Map을 사용해 메시지를 추적했다.
- 모든 발송 작업이 완료된 후, value가 1인 경우만 출력되도록 설정하여 중복 메시지 여부를 확인했다. 테스트 완료 후, 운영 환경(prod)에서는 해당 로그가 출력되지 않도록 코드에서 제거했다.
OPEN API의 TPS를 측정하여 안정적으로 서비스 운영하기
원인 분석
7번 과정은 1번 과정(알림톡을 인포뱅크에 전송하는 과정)의 TPS에 따라 비슷한 수준으로 발생하는 요청이다.
그리고 7번 과정에서는 log성 테이블에 업테이트가 발생한다.
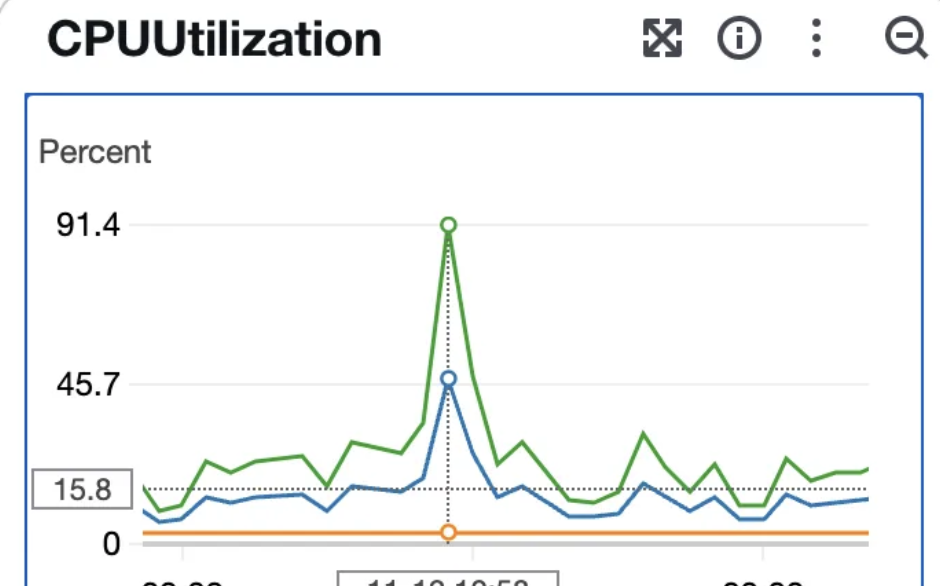
1번 호출에서 1번의 업데이트가 발생한다. 이에 따라 RDS 과부하가 발생했고 CPU 사용량이 90퍼센트를 넘게 되었다.
왜 업데이트 하나만으로 CPU 사용량이 급증했을까? 아래와 같다고 생각한다.
1. InnoDB는 UPDATE마다 undo/redo 로그 생성
- 기존 값을 undo log에 저장 (복구/rollback을 위해)
- 새 값을 페이지에 기록
- redo log에도 변경 기록
→ 트랜잭션당 최소 두 번 이상 CPU + 메모리 작업
- 버퍼 풀에서 Dirty Page 발생
- 페이지 단위로 메모리에 올라와 있는 데이터를 수정하면 → dirty page
- dirty page가 많아지면 백그라운드에서 flush
- flush가 많아지면 → CPU 사용량 급증 (로그 → 디스크 반영)
해결 과정
따라서, TPS를 조절하며 RDS의 CPU를 안정적으로 유지될 수 있는 적절한 TPS를 찾아갔다.
RDS CPU와 Server CPU 확인하기
커넥션 점유 여부 분석
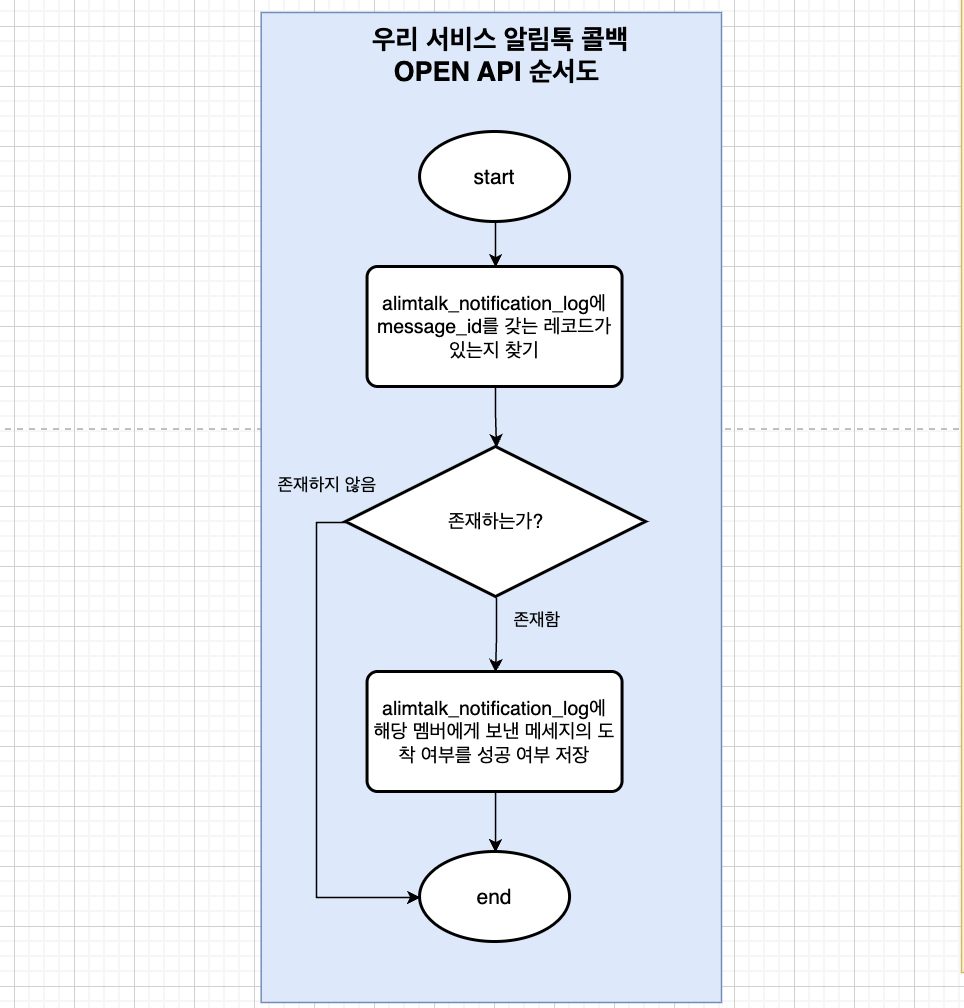
알림톡 전송 로직에서 message_id를 통해 alimtalk_notification_log 테이블에서 해당 로그를 찾는(find) 과정과, 해당 멤버에게 보낸 메시지의 성공 여부 칼럼을 갱신(update)하는 과정은 트랜잭션이 분리되어 있다.
따라서, 해당 과정이 장시간 커넥션을 점유하지는 않았다.
트레이드 오프의 발견
하지만 테스트를 진행하던 중 예상치 못한 문제를 발견했다.
나는 코드를 작성할 때, 정합성이 반드시 보장될 필요가 없다면 트랜잭션을 짧게 유지하려고 한다.
이는 트랜잭션이 길어질 경우, 커넥션이 장시간 점유되고, 언두 로그(Undo Log) 메모리에 오랜 시간 머물러 RDBMS 성능에 부정적인 영향을 미치기 때문이다.
그러나 이 과정에서 트레이드 오프(Trade-off)가 발생한다는 점은 간과했다.
해당 작업은 CPU를 소모하는 복잡한 연산이 아닌 단순한 네트워크 I/O 작업임에도 불구하고, CPU 성능이 기대보다 낮았다.
이에 대해 오랜 시간 고민한 결과, 트랜잭션을 생성하고 종료하는 과정 자체가 CPU 자원을 소모한다는 사실을 깨달았다.
트랜잭션을 하나로 묶고 부하 테스트를 다시 진행한 결과, CPU 최대 부하 상황에서 약 10%의 성능 개선이 이루어졌다.
트랜잭션을 하나로 묶을지에 대한 고민
해당 작업은 정합성을 보장할 필요가 없는 작업이지만, 트랜잭션을 하나로 묶는 것이 적절한지 고민했다.
그 이유는 코드를 읽는 다른 개발자가 요구사항을 오해하여, 정합성이 중요한 작업으로 잘못 해석할 가능성이 있기 때문이다.
하지만 아래와 같은 이유로 트랜잭션을 하나로 묶는 것이 합리적이라고 판단했다.
- 해당 요청은 알림톡을 대량으로 발송하는 과정에서 빈번하게 발생한다.
- 커넥션이 장시간 유지되지 않는다.
- alimtalk_notification_log 테이블에서 message_id를 조회하는 작업은 대량 발송 중 단 한 번만 발생한다. 해당 레코드는 하나만 존재하는 것이 보장되며, 인덱스가 설정되어 있어 조회 성능에 문제가 없다.
최종 결정
트랜잭션을 하나로 묶고, 해당 기능의 트랜잭션이 필요한 이유를 명확하게 주석으로 추가하기로 했다. 이를 통해, CPU 성능을 최적화하고, 코드를 읽는 개발자가 오해하지 않도록 예방할 수 있다.
적절한 TPS 찾기
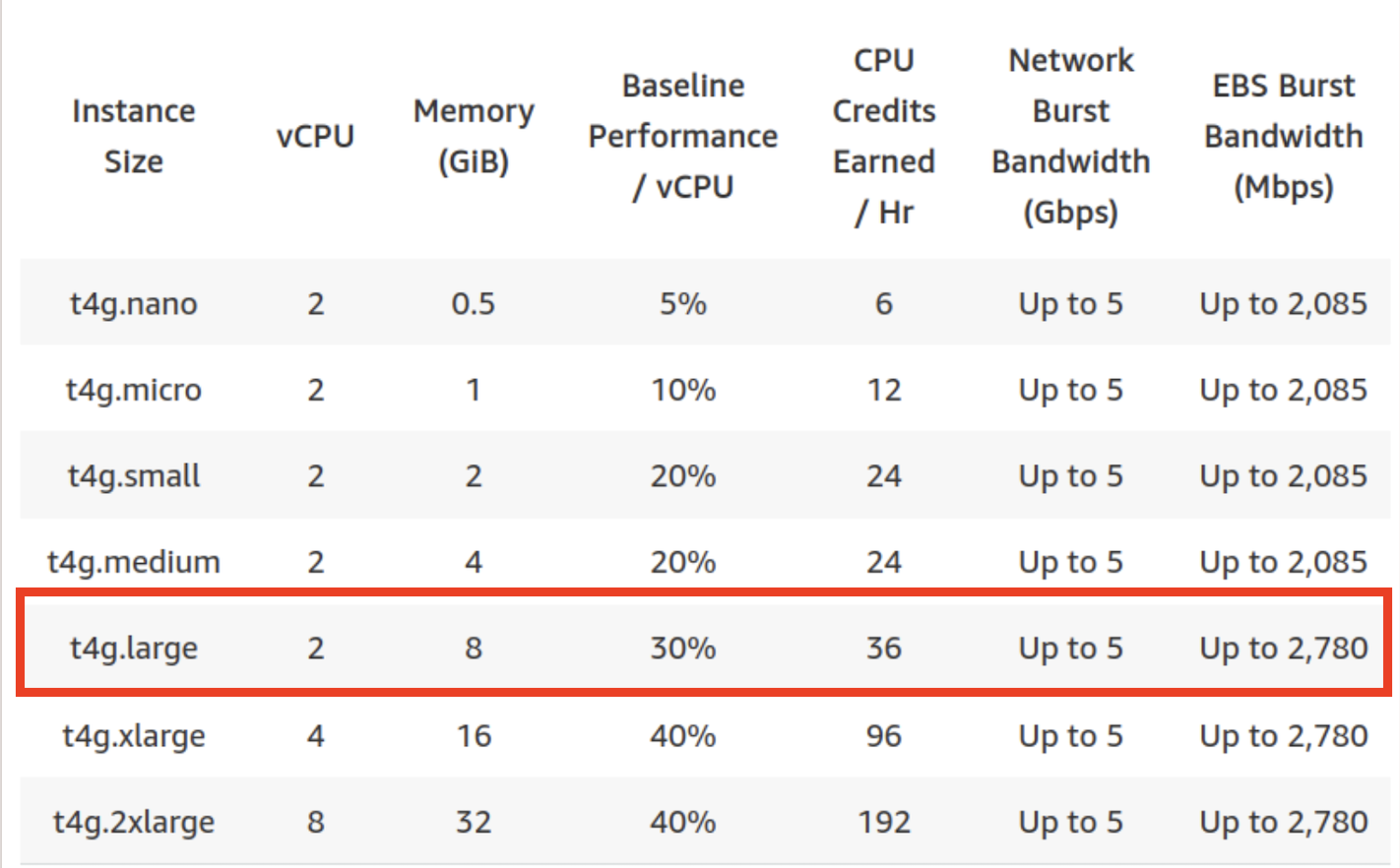
Artillery라는 도구를 사용하여 테스트를 진행하였다. dev 환경에서 진행했으며 해당 dev의 서버 사양은 t4g.large이다. dev 환경에서 진행한 이유는 prod 혹은 stg에서 진행하면 실제 서비스에 영향이 가기 때문이었다.
Artillery라는 도구를 사용해 시나리로를 작성했고 해당 시나리오는 인포뱅크에서 요구하는 TPS 200을 시작으로 OPEN API 서버가 터지지 않은 적절한 TPS를 찾아갔다.
시나리오 예시는 아래와 같다.
config:
target: "https://dev-openapi.co.kr" # 요청을 보낼 대상 URL
processor : "./messageId.js"
phases:
- duration: 50 # 테스트 지속 시간 (초)
arrivalRate: 1
rampTo : 100
name : Ramp 1 to 100
- duration : 150
arrivalRate : 100
rampTo : 180
name : Ramp 100 to 180
- duration : 100
arrivalRate : 180
name : maintain 180
- duration : 100
arrivalRate : 180
rampTo : 0
name : Ramp 180 to 0
scenarios:
- name: "Example Scenario"
flow:
- function: "generateMessageId" # messageId 생성
- post:
url: "/dev_only/reception-result" # API 엔드포인트
headers:
authorization: "Bearer accessToken"
json: # 요청 바디 (JSON 형식)
messageId : "{{ messageId }}"
resultCode : "SUC"
errorText: ""
reportTime: "2024-11-25 11:12:12"
brandtalkType : "F"
ref : ""결과
DEV 환경에서 테스트 진행 결과, TPS 80에서 CPU 53%를 사용하였다.
그 외의 TPS에서는 CPU 사용률이 저조하거나 혹은 80%를 이상을 사용하거나 실패 응답이 포함되어 있었기에 TPS 90에 맞게 1번 요청을 진행하기로 결정했다. 따라서 아래와 같은 순서도가 완성되었다. 하지만 DEV 환경은 PROD 환경보다 서버 사양이 많이 낮기 때문에 측정한 TPS에서는 완전히 안정적으로 운영될 것이라고 확신했다.
적용 후 및 느낀점
중복 알림톡 문제를 해결하기 위해 서비스를 재정비한 후, 정확히 일주일 뒤 40만 명을 대상으로 알림톡을 다시 발송했다.
그 결과, 중복 메시지 없이 알림톡이 정상적으로 발송되었다.
이번 경험을 통해 나는 다음과 같은 중요한 교훈을 얻었다.
- 외부 서비스 호출을 트랜잭션 안에 포함시키지 않고, 트랜잭션을 분리하여 짧게 유지해야 한다.
- OPEN API를 구축할 때 고려해야 할 사항과 비동기 처리를 위한 정책 수립의 중요성을 인식했다.
- 사용하는 기술에 대해 정확하게 이해하고 넘어가는 것의 필요성을 절감했다.
- 사전에 철저하게 테스트를 진행하는 것이 문제 예방에 필수적임을 깨달았다.
이 과정은 단순한 문제 해결을 넘어, 시스템 설계와 운영에 대한 깊은 인사이트를 제공하는 값진 경험이 되었다.
