정의
그래프 내의 모든 정점들을 가장 적은 비용으로 연결할 때 사용된다.
그래프라는 것은 사이클이 적어도 하나 존재하기 때문에 모든 정점들을 가장 적은 비용으로 연결한다는 것은 사이클을 없앤 최소 신장 트리를 구하라는 말과 같다.
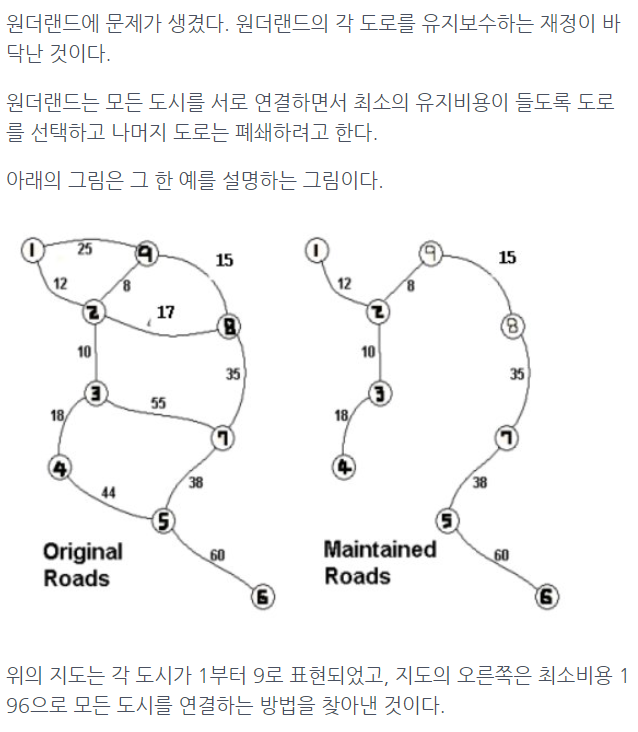
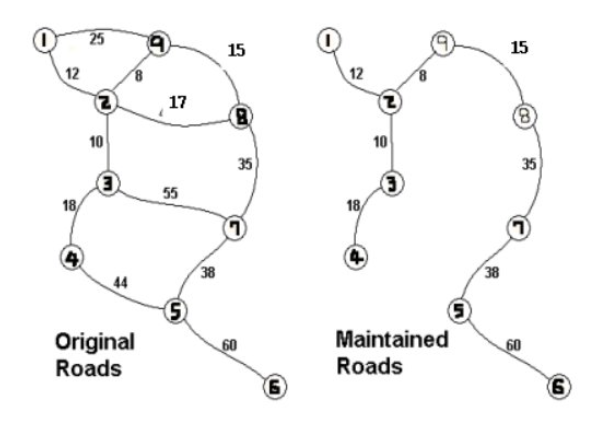
위 그림에서 왼쪽이 그래프이고 오른쪽인 최소 신장 트리이다.
접근
정리하면 크루스칼 알고리즘에는 그리디 알고리즘과 union&find 알고리즘이 쓰인다.
- 그리디 알고리즘은 미래를 생각하지 않고 각 단계에서 가장 최선의 선택을 하는 기법을 의미한다.
즉 이게 최적인지는 모르지만 이것이 최선이기 때문에 하는 것이다.
보통 회의실 배정, 씨름 선수 등 조건에 따라 정렬을 먼저 하고 그 정렬 순서에 따라 접근하는 기법이다.
이 크루스칼 알고리즘에서는 비용이 가장 적은 간선 순서대로 정렬한다.
- union&find는 여러 노드가 존재할 때 두 개의 노드를 선택해서 현재 두 노드가 서로 같은 그래프에 속하는지 판별하는 알고리즘이다. 보통 친구 관계 문제에서 사용된다. 친구 관계를 순서쌍으로 입력으로 주어진다면 문제로 어떤 두 친구를 제시하고 그 두친구가 서로 아는 사이인지 물어보는 것이다.
입력으로 주어지는 순서쌍으로 합집합을 만든다. 합집합을 만든다는 것은 서로 다른 집합이었던 둘의 집합을 하나로 만든다는 의미이고 그래프에서는 서로 같은 부모노드를 갖는다는 의미이다.
이 크루스칼 알고리즘에서는 사이클을 만들지 않도록 하는데 이용된다.
어떤 두개의 노드가 이미 연결되어져서 같은 부모 노드를 가지고 있는 것을 아닐가 확일 때 사용된다.
자바코드
import java.util.*;
import java.io.*;
public class Main{
static int[] result;
static ArrayList<Cost> list;
static int total_cost;
static class Cost{
int v1;
int v2;
int cost;
public Cost(int v1, int v2, int cost){
this.v1 =v1;
this.v2 = v2;
this.cost =cost;
}
}
static void make_Road(Cost c, int main_fee){
int c1 = find(c.v1);
int c2 = find(c.v2);
if(c1!=c2){
total_cost +=main_fee;
result[c2]=c1;
}
}
static int find(int vertex){
if(vertex == result[vertex]) return vertex;
else return result[vertex] = find(result[vertex]);
}
public static void main(String[] args) throws IOException{
BufferedReader br =new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
StringTokenizer st =new StringTokenizer(br.readLine()," ");
int V = Integer.parseInt(st.nextToken());
int E = Integer.parseInt(st.nextToken());
//트리 확인 같은 부모
result = new int[V+1];
for(int i=1;i<=V;i++){
result[i]=i;
}
//거리 넣기
list = new ArrayList<>();
for(int i=0;i<E;i++){
st=new StringTokenizer(br.readLine()," ");
int v1 = Integer.parseInt(st.nextToken());
int v2 = Integer.parseInt(st.nextToken());
int cost = Integer.parseInt(st.nextToken());
list.add(new Cost(v1,v2,cost));
}
// 규칙
Comparator<Cost> comp = new Comparator<Cost>(){
public int compare(Cost o1, Cost o2) {
return o1.cost-o2.cost;
}
};
Collections.sort(list,comp);
for(int i=0;i<list.size();i++){
make_Road(list.get(i),list.get(i).cost);
}
bw.write(Integer.toString(total_cost));
bw.flush();
bw.close();
br.close();
}
}
꾸준하게 Ready, Set, Go!