
public class Post {
private final Long id;
private final Member writer;
private final Temperatures temperatures;
private final String postImageUrl;
private final WeatherFeeling weatherFeeling;
private final LocalDate createdAt;
}현재 게시글(Post) 도메인은 위와 같은 필드값들을 가집니다.
Post의 데이터를 저장하는 Schema는 아래와 같습니다.
| post | CREATE TABLE `post` (
`post_id` bigint NOT NULL AUTO_INCREMENT,
`created_at` date DEFAULT NULL,
`feeling_index` bigint DEFAULT NULL,
`max_temperature` double DEFAULT NULL,
`member_id` bigint DEFAULT NULL,
`min_temperature` double DEFAULT NULL,
`post_image_url` varchar(255) DEFAULT NULL,
PRIMARY KEY (`post_id`)
) ENGINE=InnoDB AUTO_INCREMENT=100001 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci |하지만, 아래와 같이 내가 올린 게시글들을 조회하는 요청에서는 게시글의 id와 imageUrl 값만 응답해주면 됩니다.
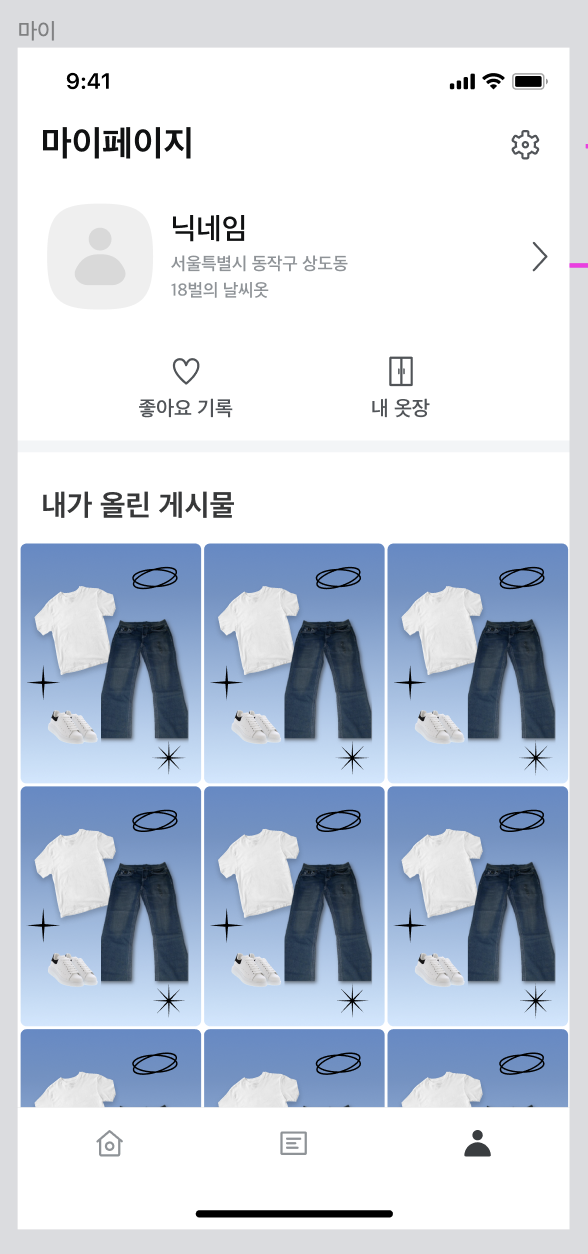
여기서 고민
위 요청을 처리하기 위해서 읽어와야하는 컬럼은 7개 중에 2개입니다. 그렇다면 2개의 컬럼만 읽어오면 되지 않을까요?
현재 저는 헥사고날 아키텍처를 사용해서 Post 도메인은 POJO이고 persistence 영역에 PostJpaEntity라는 객체가 JPA Entity로 사용되고 있습니다. 따라서, 데이터를 읽어올 때는 DB에서 데이터를 조회해서 PostJpaEntity로 만들고, PostJpaEntity를 Post로 변환하는 방식입니다.
또한, Post는 Member와 N:1 AdditionalFeelingIndex와 1:N의 관계를 맺고 있습니다. 따라서, 온전한 Post 도메인 객체를 생성하기 위해서는 3개의 테이블에 접근해야하는 상황입니다.
public class Post {
private final Long id;
private final Member writer;
private final Temperatures temperatures;
private final String postImageUrl;
private final WeatherFeeling weatherFeeling;
private final LocalDate createdAt;
}public class WeatherFeeling {
private final Long feelingIndex;
private final List<Long> additionalFeelingIndices;
}1. 필요한 2개의 컬럼만 조회하는 방식
1-1. 2개의 컬럼만을 조회해서 Post 도메인을 생성
따라서, DB에서 2개의 컬럼만 조회한다면 Post의 6개의 필드 중 4개는 null이 할당됩니다.
1-2. 2개의 컬럼을 조회하고 새롭게 정의한 DTO에 담고 이를 응답
Post에 null이 할당되는 것이 찜찜해서 고안해낸 방식입니다.
public class MyPostListElementDto {
private Long id;
private String imageUrl;
// ...
}위와 같은 DTO를 application에 정의해서 영속성 영역에서 2개의 컬럼을 읽어오도록 해서 이를 그대로 client로 반환하는 방식입니다. 위 방식을 채택한다면 2가지 고민을 해야했습니다.
첫번째로, 해당 DTO를 application의 어디에 위치시켜야할 것인가?
위 DTO는 persistence에서 데이터를 조회해오는 객체임에 application에게 요청을 한 controller에게 값을 내줘야 하는 객체이기도 합니다. 따라서, in port이면서 out port라는 생각이 들었습니다. 따라서, 이를 in port, out port도 아닌 키이름 지어야 함라는 이름의 패키지에 위치시켰습니다.
물론, 분리하려면 in port 의 DTO 1개, out port의 DTO 1개로 분리할 수 있습니다. 하지만, 추후에 변경된다고 해도 요청 데이터의 변경에 따라 DB에서 조회하는 값이 함께 변경될 것이라고 생각해서 하나로 관리해도 충분하다는 생각을 했습니다. 또한, 추후에 json key 값의 변경에 따라 해당 객체의 필드명을 바꾸면 됩니다. 그리고 정말 만약에 json key 값과 db에서 조회하는 데이터 이름에 괴리가 생긴다면 그때 둘을 분리해도 충분하다고 생각했습니다.
두번째로, 서비스에서 Post에 대한 여러 조회 기능이 필요한 상황에 경우에 따른 Post 조회 메서드와 DTO가 계속해서 생성될 것이다.
해당 방식을 채택한다면, 앞으로의 구현에서 큰 리소스가 듭니다. Post 조회 조건에 따른 조회 메서드와 조회를 위한 DTO들이 계속해서 생겨날 것입니다. 이렇게 되면 클라이언트의 요청 사항에 Persistence(Repo) 영역까지 반영되는 문제가 발생할 수 있습니다. 기능 요구 사항에 따라 Persistence 영역이 변경된다고 생각할 수도 있습니다. 하지만, Post의 어떤 값을 view에 노출 시킬지에 따라 조회 메서드가 변한다고 생각합니다. 따라서, 기능 요구사항의 변경에 의해서가 아닌 View의 변경이 repo의 영역까지 들어오는 것이라고 생각합니다.
2. 그냥 post의 모든 컬럼을 다 조회하는 방식
Post 도메인 객체에 null이 할당되는 것도 싫고, 새로운 DTO를 관리하는 것도 싫다의 경우에 고려할 수 있는 방법입니다. 그냥 무지성으로 다 읽어오는 방식이죠.
Pagination 방식으로 여러 데이터를 조회하기 때문에 fetch join을 사용할 수 없고 결국 3개의 조회 쿼리를 실행해야합니다. 1번의 방식에 비해서 2번의 조회 쿼리가 더 발생해서 성능적으로는 1번에 비해 단점이 되는 방식입니다.
3. post 단일 테이블만 조회하는 방식
총 3개의 테이블에 select를 하는 것이 부담스럽다면, Post 테이블 만을 조회하는 것은 어떨까요? 이는 1번 방식들과 다를게 없습니다. Post에는 불완전한(null을 가진) 상태로 생성되는 것입니다.
결론
일단 null이 할당되는 1-1번 방식과 3번 방식은 제외했습니다.
그 후, 3개의 테이블에 접근해서 온전한 Post를 생성하는 2번 방식과
필요한 컬럼만 조회 전용 DTO에 조회하는 1-2번 방식 중에 고민했습니다.
결론은 온전한 Post 객체를 생성하는 2번 방식을 택했습니다.
아키텍처
클라이언트에서 필요한 데이터는 post_id와 post_image_url입니다.
1-2번 방식에 따라 위의 필요한 컬럼만 조회한다면 DB 조회 전용 DTO와 응답 DTO가 같은 형식이 될 것입니다. DB에서 조회하는 값과 응답하는 하는 값이 같기 때문이죠. 앞으로 클라이언트에 응답해야하는 데이터가 변경됨에 따라 DB 조회 DTO도 대부분 함께 변경될 것으로 예상합니다.
따라서, 조회 전용 DTO와 응답 DTO를 하나로 관리하는 것이 효율적이라고 생각합니다. 그렇다면, 이 DTO는 헥사고날 아키텍처에서 어디에 정의해야할까요? in port에 정의해야할까요? out port에 정의해야할까요? 어디에 정의해도 헥사고날 아키텍처의 in, out 개념을 지킬 수 없습니다. in이 아니고 out도 아닌 다른 port에 정의한다고 해도 in ↔ core ↔ out 의 헥사고날 컨셉은 지킬 수가 없습니다.
유지보수의 측면에서
필요한 컬럼만 조회 전용 DTO로 읽어오는 방식을 채택한다면, 추후에 새로운 조회 조건이 생긴다면 그에 따라 조회 메서드와 조회 전용 DTO가 계속해서 생겨야합니다. 이전의 조회 로직들을 재사용할 수 없기 때문에 재사용성이 너무 떨어진다고 생각했습니다. 또한,이는 View에 따른 Persistence(repo)의 변경이기 때문에 서버에게 더 위험합니다.
또한, 현재의 헥사고날 아키텍처로 구조화되어있습니다. 1개의 DB를 조회하기 위해서 out port, adapter, JpaRepository 의 메서드가 필요합니다. 그렇다면, 1개의 세부 조회 로직에 따라 3개의 메서드를 매번 선언해줘야합니다. 그에 따라 테스트 코드도 생길 것입니다.
하지만, 2번 방식을 채택한다면 Post와 관련된 조회 메서드를 계속해서 재사용할 수 있습니다.
성능
하지만, 온전한 Post를 조회하려면 3개의 테이블에 조회 쿼리를 실행해야 합니다. 성능적인 측면에서 1개의 테이블에 접근해서 필요한 컬럼만 조회하는 방식에 비해서 성능이 떨어집니다. 하지만, 성능의 경우에는 당장 큰 문제가 되지 않고, 추후에 성능이 문제가 된다면 캐싱을 통해서 성능을 개선할 수 있을거라 생각합니다.
만약, 캐싱을 적용해도 Hit Rate가 낮아서 성능이 좋지 않다면, 조회 전용 DTO를 구축하는게 좋을 수도 있다는 생각이 듭니다.
