
Dandi에서 날씨 API를 호출해 날씨 정보를 DB에 저장하는 Batch를 진행하고 있습니다.
이전에는 ItemWriter의 insert 쿼리에 대해, JDBC batchUpdate를 통해 Insert 쿼리 수를 줄이며 Write 성능을 개선했습니다.
하지만, 여전히 Batch 실행 시간은 아래와 같습니다.
| START_TIME | END_TIME
+----------------------------+----------------------------
| 2023-10-05 13:58:58.911000 | 2023-10-05 14:29:58.326000 31m
| 2023-10-06 01:28:53.780000 | 2023-10-06 02:13:21.228000 44m 28s
| 2023-10-06 05:40:21.567000 | 2023-10-06 06:09:59.018000 29m 38s
| 2023-10-06 06:50:45.222000 | 2023-10-06 07:27:18.385000 36m 33s
| 2023-10-06 17:10:00.528000 | 2023-10-06 17:47:04.443000 37m 4s
| 2023-10-09 07:13:21.478000 | 2023-10-09 07:56:43.949000 43m 22s
날씨 API의 응답 시간이 불규칙적이기 때문에 실행 시간에 API 응답 시간에 매우 의존적입니다.
Batch Job 시간이 오래 걸리는 이유 : ItemProcessor의 API Call
ItemProcessor에서 공공데이터 포털 API 요청을 통해 날씨 데이터를 받아옵니다. 정상적인 API 평균 응답 시간이 1.2인 API 호출을 한번의 Job 실행에 1628번이나 진행해야 합니다. 또한, 응답시간이 13s까지 걸리는 경우도 있습니다. 그렇기 때문에, 전체 Job 실행 시간 중 ItemProcessor의 실행 시간은 차지하는 비율이 상당히 높습니다. Read와 Write 성능은 최적화가 되어있기 때문에 거의 대부분이라고 보셔도 무방합니다.
따라서, ItemProcessor의 성능 개선은 필수입니다.
HTTP 지속적 연결
가장 먼저 떠오른 방식은 HTTP의 지속적 연결입니다.
문제
현재, API Call을 1628번 하고 모든 API Call에서 새로운 Connection을 맺고 있는 상황입니다. Job 실행중, 지속적으로 API Call을 하는데 매번 Connection을 맺는 것은 상당한 낭비입니다.
해결방안
따라서, 아래와 같이 Request Header에 아래와 같은 값을 통해 HTTP 지속적 연결을 맺으려해보았습니다.
Connection: Keep-Alive
Keep-Alive: timeout=5, max=1000
하지만, 응답 값에는 지속적 연결을 위한 응답 값이 존재하지 않았습니다.
GET {RequestURI}
Connection: Keep-Alive
Keep-Alive: timeout=5, max=1000
HTTP/1.1 200 OK (1087ms)
access-control-allow-origin: *
content-language: ko-KR
content-type: application/json;charset=UTF-8
date: Fri, 13 Oct 2023 11:49:32 GMT
server: NIA API Server
set-cookie: JSESSIONID=ZCzX9lyyeZrP9ZaQwdh6WQ5j5aUKYCNut4YgANlA59Rx6CVrnj5aUBQHaP1KCZAs.amV1c19kb21haW4vbmV3c2t5Mw==; Path=/1360000/VilageFcstInfoService_2.0; HttpOnly; Domain=apis.data.go.kr
transfer-encoding: chunked
{ResponseBody}
공공데이터 포털의 서버에는 지속적 연결을 위한 세팅이 되어 있지 않은 것으로 보입니다.
ItemProcessor 병렬 처리
문제
Spring Batch의 ItemProcessor 기본 설계에 따라, 현재 ItemProcessor는 1개의 스레드에서 단일 아이템을 순차적으로 처리하고 있습니다.
public interface ItemProcessor {
public Object processItem(Object item) throws Exception;
}
위에서 말씀드렸듯이, 정상적인 응답의 경우에 800 ~ 1200ms의 응답 시간을 가지는 API에 대해 1628번의 호출을 진행한다면, 대기시간만 800 * 1628ms ~ 1200 * 1628ms로 소요됩니다.
해결방안
따라서, ItemProcessor를 병렬로 처리해야겠다는 아이디어가 떠올랐습니다. ItemProcessor를 병렬 처리하는 간단한 방식은 아래와 같습니다.
- Multi-Threaded Step
- AsyncItemProcessor & AsyncItemWriter
- ExecutorService를 통해 직접 병렬 구현하기
3가지 방식중 어떤걸?
1과 2에 대한 설명은 간단하게 하겠습니다. 글에 있으니 참고하시면 좋을 것 같습니다.
1. Multi-Threaded Step
하나의 Step에서 여러 개의 청크를 N개의 스레드가 병렬로 처리하는 방식입니다.
(장점)
해당 방식은 TaskExecutor를 지정해주면 되는 간단한 방식입니다.
(단점)
하지만, Reader도 병렬로 처리되기 때문에, Batch의 핵심인 실패 지점부터의 재시도가 불가능합니다.
10개의 Chunk 중 9번 Chunk를 처리하다가 실패를 했을 때, 순차적으로 처리되는 것이 아니라 병렬적으로 처리되기 때문에 1~8번 Chunk가 성공했다는 보장이 없기 때문입니다.
공공데이터 포털은 500번대의 다양한 에러들을 간헐적으로 응답합니다. Retry 정책을 세워뒀지만, Batch가 실패했을 때, 긴 응답 시간, 높은 비용의 API Call을 처음부터 다시 호출하는 것 상당히 비효율적이라고 생각합니다.
또한, Reader와 Writer는 성능히 충분하기 때문에 굳이 비동기로 처리하지 않아도 됩니다.
2. AsyncItemProcessor & AsyncItemWriter
ItemProcessor에서, N개의 스레드가 비동기로 process를 처리하고 ItemWriter가 Future 타입을 받아서 Write하는 방식입니다. 결과적으로, Reader와 Writer가 아닌 ItemProcessor만 병렬로 처리되는 방식입니다.
일단, 위 방식을 사용하기 위해선 Spring-Batch-Integration 추가 의존성이 필요하다는 아쉬운 점이 있습니다.
하지만, Reader와 Writer의 성능이 우수해 병렬 처리가 필요하지 않은 저의 Job에 적절합니다.
또한, 위 방식은 Multi-Threaded Step과 달리 Reader는 병렬로 처리되지 않기 때문에 실패 지점에서부터의 재시도가 가능합니다.
3. ExecutorService를 통해 직접 병렬 구현하기
ExecutorService를 통해 직접 병렬을 구현하는 방법이 있습니다. ItemProcessor는 단건으로 처리됩니다. 따라서, ItemProcessor가 아닌 ItemWriter에서 API Call을 병렬로 처리해야합니다. 따라서 아래와 같은 형태가 되는데요.
private List<Weathers> requestWeatherApi(List<? extends WeatherLocation> weatherLocations, LocalDateTime baseDateTime,
int threadSize, ExecutorService executor, WeatherRequester weatherRequester) {
List<CompletableFuture<Weathers>> weathersFutures = new ArrayList<>();
List<Weathers> weathers = new ArrayList<>();
for (WeatherLocation weatherLocation : weatherLocations) {
CompletableFuture<Weathers> weatherFuture = CompletableFuture.supplyAsync(
() -> weatherRequester.getWeathers(baseDateTime, weatherLocation), executor);
weathersFutures.add(weatherFuture);
if (weathersFutures.size() == threadSize) {
weathersFutures.forEach(weathersFuture -> weathers.add(getFutureValue(weathersFuture)));
weathersFutures.clear();
}
}
return weathers;
}
private Weathers getFutureValue(Future<Weathers> weathersFuture) {
try {
return weathersFuture.get();
} catch (InterruptedException e) {
throw new WeatherRequestFatalException("(날씨 API Thread InterruptedException)" + e.getMessage());
} catch (ExecutionException e) {
throw handleExecutionException(e);
}
}
}
(장점)
AsyncItemProcessor & AsyncItemWriter과 달리 추가적인 의존성 없이 java.concurrent 만으로 병렬을 구현할 수 있습니다.
선택 : ExecutorService 를 통한 병렬 직접 구현
Multi-Threaded Step는 배치의 장점인 실패 지점부터의 재시도가 불가능하기 때문에, 채택하지 않았습니다.
AsyncItemProcessor & AsyncItemWriter를 통한 방식과 ExecutorService를 통한 직접 구현 방식은 실패 지점부터의 재시도가 가능합니다. 또한, 둘은 동일한 스레드에서 거의 동일한 성능 지표를 보였습니다.
둘 중, ExecutorService로 직접 구현하는 방식은 외부 의존성 없이 구현할 수 있기 때문에 직접 구현 방식을 택했습니다.
성능 개선 지표 및 스레드 개수
성능 개선 지표와 병렬 처리 할 적절한 스레드 개수도 함께 알아보겠습니다.
변인 통제
@Bean
@StepScope
public ItemProcessor<WeatherLocation, Weathers> weatherItemProcessor() {
return weatherLocation -> weatherRequester.getWeathers(dateTimeJobParameter.getLocalDateTime(), weatherLocation);
}
public class MockWeatherRequester implements WeatherRequester {
private final List<Weather> weathers;
// ...
@Override
public Weathers getWeathers(LocalDateTime baseDateTime, WeatherLocation location) throws WeatherRequestException {
try {
Thread.sleep(1500);
} catch (InterruptedException e) {}
return new Weathers(location.getId(), weathers);
}
}
기상청 날씨 API는 응답 시간이 불규칙적입니다. 따라서, 동일한 조건에서의 테스트를 위해 AsyncItemProcessor의 delegate인 실질적 API를 호출하는 ItemProcessor는 1.5s를 대기하고 모킹된 날씨 정보를 반환하도록 했습니다.
성능 개선 지표
기존의 단일 Thread - 약 40m 51s
| START_TIME | END_TIME
+----------------------------+---------------------------
| 2023-10-13 17:10:00.576000 | 2023-10-13 17:50:51.416000 40m 51s
| 2023-10-13 20:10:00.431000 | 2023-10-13 20:50:51.235000 40m 51s
| 2023-10-13 23:10:00.503000 | 2023-10-13 23:50:51.361000 40m 51s
Thread 개수 2개 - 약 20m 35s
| START_TIME | END_TIME
+----------------------------+---------------------------
| 2023-10-14 01:05:05.626000 | 2023-10-14 01:25:39.653000 20m 34s
| 2023-10-14 01:26:22.542000 | 2023-10-14 01:47:00.431000 20m 38s
| 2023-10-14 02:10:00.543000 | 2023-10-14 02:30:33.069000 20m 33s
Thread 개수 3개 - 약 13m 50s
| START_TIME | END_TIME
+----------------------------+---------------------------
| 2023-10-13 09:19:45.228000 | 2023-10-13 09:33:36.667000 13m 51s
| 2023-10-13 09:34:24.444000 | 2023-10-13 09:48:17.527000 13m 53s
| 2023-10-13 10:27:46.669000 | 2023-10-13 10:41:39.253000 13m 53s
Thread 개수 4개 - 약 10m 26s
| START_TIME | END_TIME
+----------------------------+---------------------------
| 2023-10-13 10:46:24.366000 | 2023-10-13 10:56:47.202000 10m 23s
| 2023-10-13 10:57:11.973000 | 2023-10-13 11:07:35.418000 10m 24s
| 2023-10-13 11:08:00.370000 | 2023-10-13 11:18:30.265000 10m 30s
스레드 N개에 따른 실행 시간은 약 단일 스레드 소요 시간 / N 입니다.
스레드 개수
위에서 보셨듯이, 스레드 개수가 늘어감에 따라 성능은 계속 개선됩니다.
그렇다면 스레드를 무작정 늘리면 되는 걸까요? 그렇지 않습니다. 몇가지 고려해볼 사항이 있습니다.
1. 서비스적으로 얼마나 빨라야하나?
먼저, 서비스적으로 최신 날씨 갱신이 얼마나 빨라야하는지를 고려해보아야 합니다. 사용자에게 특정 시간이내로 갱신된 날씨를 제공하는 것이 중요하다면 스레드 개수를 늘리면서 빠르게 갱신하는 것이 유의미할 것입니다.
그렇지 않다면, 스레드 개수를 늘리는 것은 낭비일 것입니다.
2. 제한적인 컴퓨팅 자원
1번과 비슷한 내용이라 생각합니다. 컴퓨팅 자원을 무제한으로 Scale-Up하는 것은 불가능합니다.
만약 Batch 작업과 API 응답이 동일 서버에서 이뤄진다면, Batch에서 많은 리소스를 사용하는 만큼 API 응답은 느려질 수 있습니다. 또한, DB도 분리된 Batch 서버와 API 서버가 동일한 DB를 바라본다면 마찬가지입니다.
모니터링 지표 등을 토대로 컴퓨팅 자원 사용률을 확인하면서 적절한 값을 지정해야합니다.
3. 서버(공공데이터 포털)의 TPS 및 에러 응답
클라이언트에서 성능을 높이기 위해서 많은 스레드로 서버에 요청을 한다고 해도 서버가 처리 가능해야 합니다. API 호출을 가진 Batch의 실행 시간은 날씨 API 서버에 종속적이라는 것입니다.
무작정 스레드의 개수를 늘릴 수는 없습니다. 응답 속도가 늦다는 것은 서버에 부하가 많이 왔다는 것이고 부하를 잘 받는 서버에 많은 수의 스레드로 요청을 보내면 에러를 응답할 확률이 올라갑니다. 따라서, 제한적인 Retry 수를 가진 Batch Job은 실패할 것입니다. 그렇다고 Retry 한도를 무작정 늘릴 수도 없습니다. 서버에 문제가 생겼다면 Retry를 계속 하는 것이 무의미하기 때문입니다.
클라이언트에서 성능을 높이기 위해서 많은 스레드로 서버에 요청을 한다고 해도 서버가 처리 가능해야 합니다. 만약, 서버에 너무 많은 트래픽을 준다면 서버에 장애가 발생할 것이고 (장애 복구 대기 + Batch 재시도 처리)로 인해 최신 날씨로 갱신하는데 더 오랜 시간이 걸릴 것입니다. 또한, 제가 사용하는 공공데이터 포털의 날씨 단기예보 API 초당 최대 트랜잭션은 30TPS라고 문서에 명시되있습니다.
너무 많은 스레드로 서버에 요청을 한다면 아래처럼 서버는 에러를 응답합니다. 더 많아진다면 서버가 다운되어서 다른 API 사용자들에게 피해를 줄 수도 있습니다.
2023-10-13 23:10:44.296 [scopedTarget.weatherProcessorTaskExecutor-2] INFO dandi.dandi.weather.adapter.out.kma.KmaFeignDecoder - 공공 데이터 포털 에러 XML 응답
<OpenAPI_ServiceResponse>
<cmmMsgHeader>
<errMsg>SERVICE ERROR</errMsg>
<returnAuthMsg>HTTP ROUTING ERROR</returnAuthMsg>
<returnReasonCode>04</returnReasonCode>
</cmmMsgHeader>
</OpenAPI_ServiceResponse>
2023-10-13 23:10:44.943 [scopedTarget.weatherProcessorTaskExecutor-4] INFO dandi.dandi.weather.adapter.out.kma.KmaFeignDecoder - 공공 데이터 포털 에러 XML 응답
<OpenAPI_ServiceResponse>
<cmmMsgHeader>
<errMsg>SERVICE ERROR</errMsg>
<returnAuthMsg>HTTP ROUTING ERROR</returnAuthMsg>
<returnReasonCode>04</returnReasonCode>
</cmmMsgHeader>
</OpenAPI_ServiceResponse>
2023-10-13 23:10:49.826 [scopedTarget.weatherProcessorTaskExecutor-5] INFO dandi.dandi.weather.adapter.out.kma.KmaFeignDecoder - 공공 데이터 포털 에러 XML 응답
<OpenAPI_ServiceResponse>
<cmmMsgHeader>
<errMsg>SERVICE ERROR</errMsg>
<returnAuthMsg>HTTP ROUTING ERROR</returnAuthMsg>
<returnReasonCode>04</returnReasonCode>
</cmmMsgHeader>
</OpenAPI_ServiceResponse>
4. 그래서 스레드 몇개로 할거야?
결론부터 말하자면 3개입니다.
4-1. 서비스 및 성능 측면
날씨라는 도메인을 다루면서 알았던 정보인데, 해당 도메인을 다루면서 알았던 정보인데, 날씨 정보가 시간에 따라 꽤 자주 바뀌는 것으로 확인했습니다. 따라서, 서비스적으로 10분 ~ 20분의 시간안에 날씨 데이터를 갱신하는 것이 목표였습니다. 그렇기에, 일단 스레드의 개수가 3개 혹은 4개 정도가 적당해보입니다.
또한, 부하가 많지 않은 서버 상태의 API 응답 시간이 평균 800 ~ 1200ms입니다. 따라서, 1500ms에 13m 50s면 느린 응답들을 고려했을 때, 적절하다고 생각합니다.
실제 날씨 API를 통해 Batch 작업을 수행했을 때의 평균 소요 시간은 약 12 ~ 18분으로, 3개의 스레드만으로 목표 성능 개선치에 도달했습니다.
4-2. 컴퓨팅 자원 측면
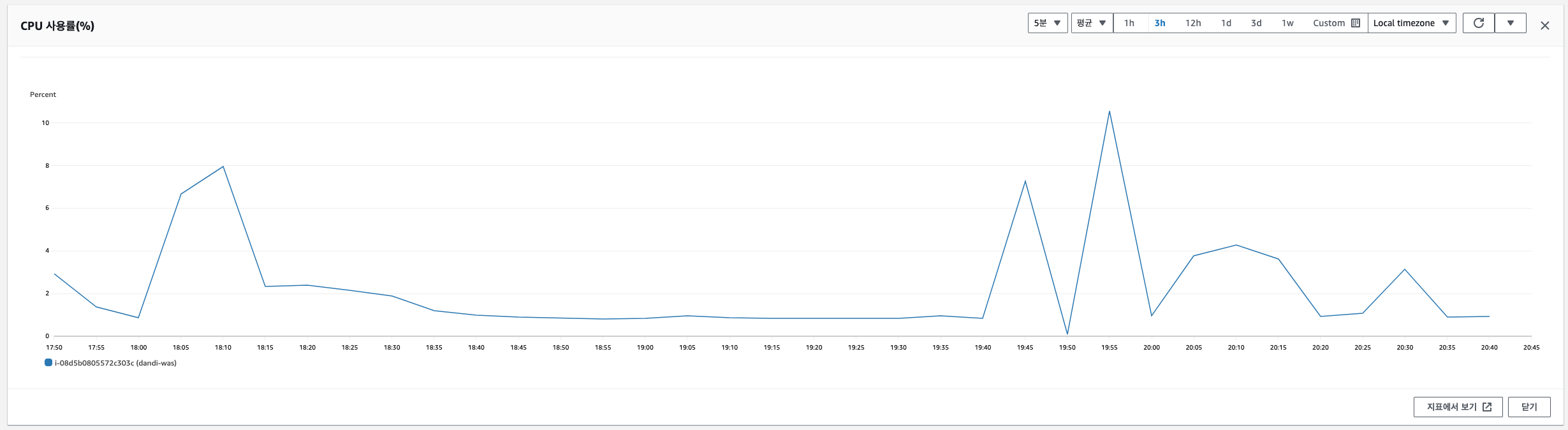
3개의 스레드로 Batch를 진행하면 CPU 사용률은 최대 약 10% 증가합니다. 현재, 해당 프로젝트는 운영중이지 않은 토이 프로젝트로, 최대 10%의 수치는 괜찮다고 생각합니다.
한편으론, API 요청에 따른 컴퓨팅 자원 사용률, DB Connection Pool등을 함께 고려하여 스레드 개수를 선택하지 못한 것이 아쉽습니다. 만약, 운영중이라고 가정한다면 Batch 서버를 따로 분리하거나, API 서버와 동일한 서버에서 Batch를 동작시킨다면 서비스 API에 영향을 미치지 않는 스레드 개수를 정해야할 것입니다.
4-3. 서버의 TPS 및 응답 속도 측면
날씨 API 문서에 처리가능 TPS는 30으로 명시되어있습니다. 실제로 10개 이상의 스레드로 Job을 실행해보니, 에러가 많이 응답되어 해당 Job이 실패했습니다. 물론, 서버의 상태에 따라 달라질 수 있겠지만, 스레드 3개로는 안정적으로 Job을 수행하는 겻을 확인했습니다.
4-4. 스레드 개수 결론
3개의 스레드로 아래와 같은 결론에 도달했기에 스레드의 개수는 3개로 결정했습니다.
- 원하는 성능 개선 목표에 도달
- 컴퓨팅 자원도 적당히 사용
- 여러번의 에러 응답에 의한 Job의 실패가 거의 발생하지 않음
