
속닥속닥 팀 프로젝트는 400개 이상의 테스트 케이스들이 존재합니다. 따라서, 로컬에서 테스트들을 실행할 때 시간이 오래 걸렸습니다.(자세한 시간은 아래에서 알아보겠습니다). 또한, CI를 Github Action을 통해 진행하고 있는데, CI의 Test Stage에서도 오랜 시간이 시간이 소요되었습니다.
따라서, 팀원인 이스트와 함께 테스트 성능을 개선해보았습니다.
1. Context Caching
https://velog.io/@byeongju/인수테스트-격리-방식 포스팅에 나와있듯이, 프로젝트 초반에 DB 초기화를 위해 사용했던 DirtiesContext를 제거하면서 Context를 Caching 할 수 있도록 했습니다. 하지만, 테스트 클래스마다 사용하는 Bean들이 달라서 Context Caching을 잘 활용하고 있지 못하는 상황이었습니다.

위와 같이 location, contextCustomizers와 같은 context cache key에 따라, Context를 재사용할지 새로운 Context를 load할지가 결정됩니다. Context를 새로 Load하는 것은 무거운 작업입니다.
한 종류의 테스트에서 하나의 Context만 Load 되도록 설정
따라서, 한 종류의 테스트마다 하나의 Context만 Load하여 캐싱-재사용하는 전략이 필요했습니다.
현재 저희 팀의 테스트 종류는 아래와 같습니다.
- 서비스 계층 테스트(@SpringBootTest)
- 컨트롤러 계층 테스트(@WebMvcTest)
- Repository 계층 테스트(@DataJpaTest)
- 인수테스트(@SpringBootTest)
Test의 종류에 따라 필요한 Bean들만 다를 뿐이지 Context Caching의 개념과 방법은 동일하기 때문에,
서비스 계층 테스트를 예시로 보겠습니다.
Service Layer Test
아래와 같이 @SpringBootTest 어노테이션이 존재하는 ServiceTest를 Service 계층의 테스트들이 상속하도록 해서 동일한 Context를 사용하도록 의도했습니다.
하지만, EmailServiceTest에서는 다른 서비스 레이어 테스트에서 필요로 하지 않는 @MockBean이 필요하기 때문에 **새로운 Context가 로드**되고 있었습니다. 이와 같은 서비스 레이어 테스트들이 존재했습니다. 그에 따른 비용(시간)도 소모되었습니다.
class EmailServiceTest extends ServiceTest {
// ...
@MockBean
private EmailSender emailSender;
@MockBean
private AuthCodeGenerator authCodeGenerator;
// ...
}따라서, ServiceTest에 모든 서비스 레이어 테스트들에서 필요한 Bean들을 등록했습니다. @MockBean과 @SpyBean 과 같은 Bean들을 ServiceTest에 모조리 선언했습니다.
코드 레벨에서 조금 더 설명을 하자면, 위의 EmailServiceTest에서만 필요하던 AuthCodeGenerator, EmailSender MockBean을 모든 서비스 레이어 테스트가 상속하는 ServiceTest에 선언하였습니다. 따라서, 모든 서비스 레이어 테스트가 해당 빈이 등록된 Context를 재사용하도록 했습니다.
@SpringBootTest
public class ServiceTest {
// ...
@MockBean
protected AuthCodeGenerator authCodeGenerator;
@MockBean
protected EmailSender emailSender;
// ...
}그 결과, 첫번째 서비스 계층 테스트가 실행될 때, 서비스 레이어 계층 테스트에 필요한 모든 Bean들이 다 등록된 Context가 로드됩니다. 따라서, 서비스 계층 테스트를 추가적인 Context 로드 없이, 하나의 Context로 실행할 수 있었습니다.
위와 같은 방식으로 테스트 종류마다 하나의 Context만 Load되도록 할 수 있습니다.
결과적으로 Controller, Service, Repository, 인수테스트 총 4개의 Context로 모든 테스트를 실행할 수 있습니다.
성능
Context Caching을 완벽하게 적용하기 전에 모든 테스트에 소요된 시간입니다.
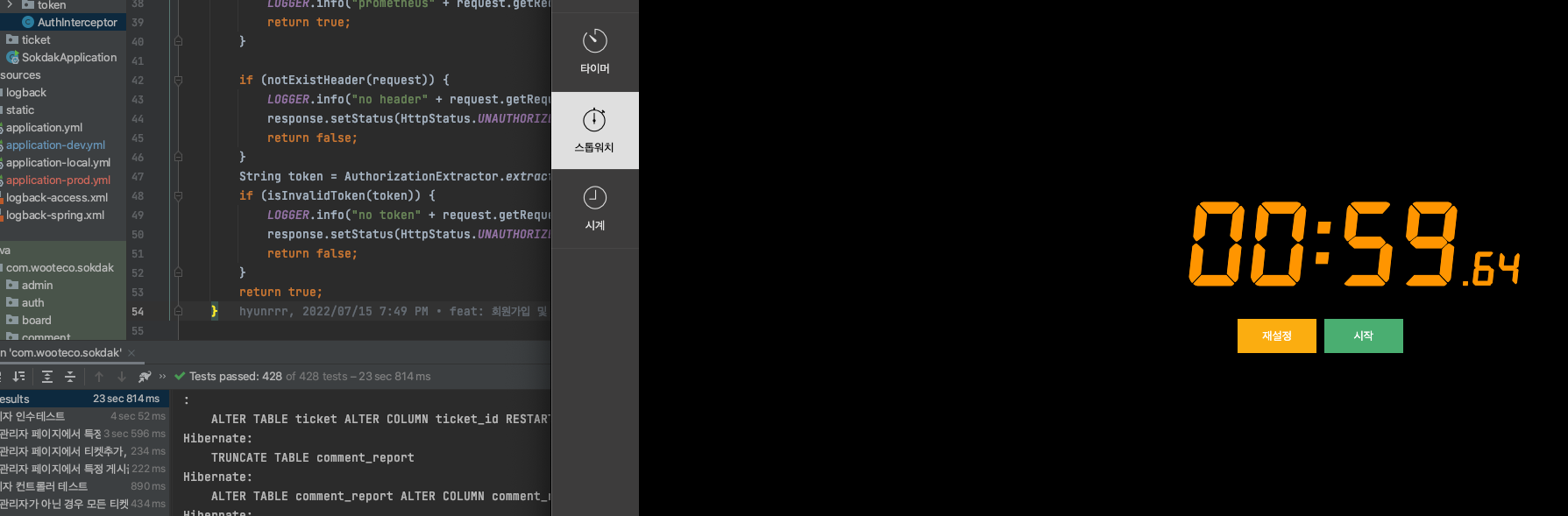
Context Caching을 완벽하게 적용한 후 모든 테스트에 소요된 시간입니다.

엄청 비약적으로 테스트 코드의 시간이 단축되지 않았지만, 그래도 꽤 유의미한 결과라고 생각합니다.
2. 인수테스트 불필요한 로그인 API 호출 제거
속닥속닥 서비스는 기본적으로 로그인이 필요한 서비스입니다. 따라서, 인수테스트에서 대부분의 Get 요청을 제외하고는 모두 로그인 과정이 필요했습니다.
따라서, 아래와 같은 Fixture를 통해 모든 로그인이 필요한 인수테스트에서 로그인 요청을 하여 토큰을 새로 발급받았습니다.
public class MemberFixture {
//...
public static String getToken(String username) {
LoginRequest loginRequest = new LoginRequest(username, TEST_PASSWORD);
return httpPost(loginRequest, "/login").header(AUTHORIZATION);
}
//...
}문제점
인수테스트 마다, 로그인을 계속해야할까? 어차피 똑같은 값이 계속 나올텐데 불필요하다는 생각이 들었습니다.
먼저, 아래 처럼 로그인 요청이 이뤄지는 곳에 count를 해서 로그인 요청이 몇 번 발생하는지 확인 해보았습니다.
public class MemberFixture {
//...
private static int tokenCount = 0;
public static String getToken(String username) {
System.out.println("=====Token Call: " + ++tokenCount + " ========") ;
LoginRequest loginRequest = new LoginRequest(username, TEST_PASSWORD);
return httpPost(loginRequest, "/login").header(AUTHORIZATION);
}
//...
}확인해본 결과, 전체 로그인 요청이 180번 발생했습니다.

테스트를 위해 사용되는 Member의 수는 6명라서 6번의 토큰 발급만 이뤄지면 됩니다.
하지만, 현재 180번의 로그인 요청이 발생하고 있었습니다.
토큰 캐싱하기
public class TokenFixture {
private static final Map<String, String> TOKENS = new ConcurrentHashMap<>();
//...
public static String getToken(String username) {
return TOKENS.computeIfAbsent(username, ignored -> {
LoginRequest loginRequest = new LoginRequest(username, "Abcd123!@");
return httpPost(loginRequest, "/login").header(AUTHORIZATION);
});
}
}따라서 위와 같이 Token을 캐싱하는 전략을 세웠습니다. 이전의 인수테스트에서 발급 받은 Token이 존재한다면 이를 재사용하고, 존재하지 않을 때만 로그인 API 요청을 하도록 하였습니다.

다시 확인 해본 결과, Token을 위한 180번의 로그인 API 호출이 6번으로 줄어든 것을 확인할 수 있었습니다.
174번의 불필요한 API 호출을 제거했습니다.
성능
API 호출을 감소시킨 성능의 경우에 Context들이 Load되는 시간을 측정할 필요가 없다고 판단이 들어, 테스트가 끝나고 intellij에서 제공하는 Test 소요 시간을 측정했습니다.
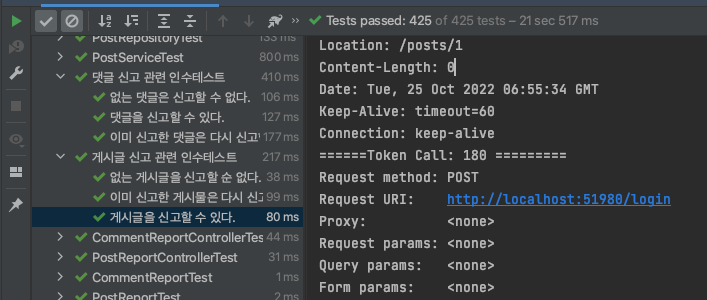
Token 캐싱 이전
21 sec 517 ms
Token 캐싱 이후
19 sec 391 ms
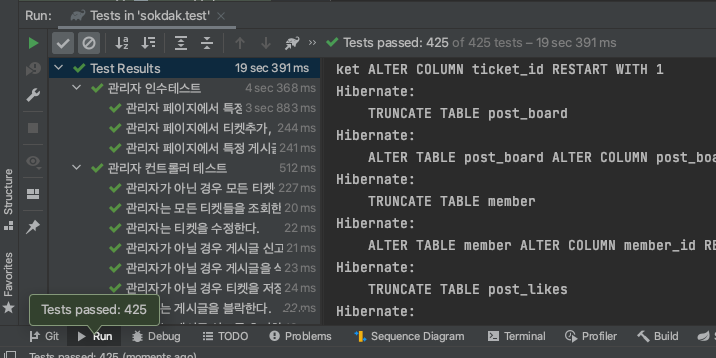
사실, intellij test 소요 시간은 조금은 왔다갔다하는 지표입니다. 하지만 불필요한 174번의 API Call을 제거했으므로, 확실히 성능적인 개선은 존재했습니다.
아직 개선점이 더 많기 때문에 테스트 리팩토링을 더 진행해봐야 할 것 같습니다.
끗

감사합니다!