학습 요약
Spring 숙련 강의
Spring 입문 6주차
오늘도 어김없이 밀린 TIL 써보겠습니다.
Layered Architecture
- 애플리케이션을 세 가지 주요 계층으로 나누어 구조화하는 방법으로 각 계층은 특정한 책임을 갖고 있음
- 계층 간에는 명확한 역할 분담이 이루어져 코드의 재사용성, 유지보수성, 확장성을 높이는 데 도움을 줌
Layered Architecture 구조
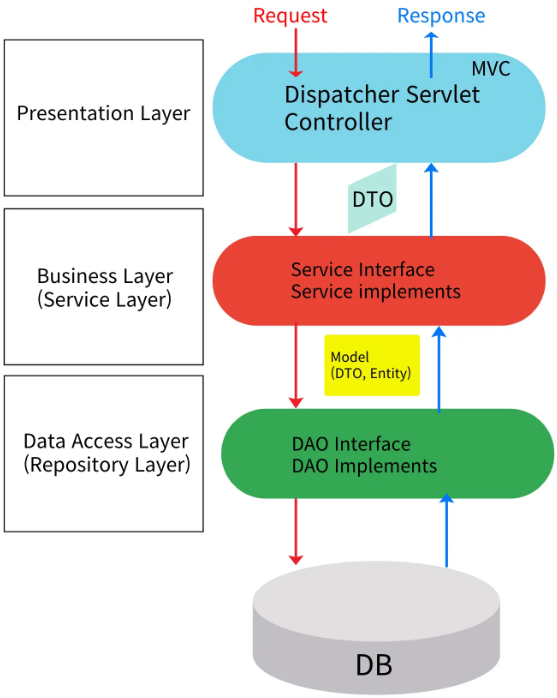
- Presentation Layer
- 사용자의 요청을 받고 응답하는 역할을 수행
- 화면을 응답하거나 데이터를 응답하는 API를 정의
- Business Layer(Service Layer)
- 비지니스 로직을 수행
- 요청을 해석하여 Repository Layer에 전달
- 일반적으로 하나의 비즈니스 로직은 하나의 트랜잭션으로 동작
- Data Access Layer(Repository Layer)
- 데이터베이스와 연동되어 실제 데이터를 관리
용어 설명
- DTO(Data Transfer Object)
- 계층간 데이터 전달을 위해 사용되는 객체
- Model
- Entity
- 추후 숙련주차에 배울 JPA와 관련이 있음
- JPA에서는 Entity라는 형태로 데이터를 반환
- Entity
- DAO(Data Access Object)
- 데이터 접근을 위해 사용되는 객체
Layered Architecture 적용
- Controller
- 클라이언트의 요청을 받는 역할을 수행
- 요청에 대한 처리를 Service Layer에 전달
- Service에서 처리 완료된 결과를 클라이언트에 응답
- 사용하는 Annotation :
@Controller, @RestController
- Service
- 사용자의 요청 사항을 처리
- DB와 상호작용이 필요한 경우, Repository Layer에게 요청
- 사용하는 Annotation:
@Service
- Repository
- DB와 상호작용을 수행
- Connection 연결, 해제
- CRUD 작업 처리
- 사용하는 Annotation:
@Repository
- DB와 상호작용을 수행
- DTO(Data Transfer Object)
- 계층간 데이터 전달을 위해 사용
- 요청 데이터를 처리하는 객체는 일반적으로
RequestDto - 응답 데이터를 처리하는 객체는 일반적으로
ResponseDto
Database 1강
- 여러 사람이 공유하고 사용할 목적으로 한 곳에서 관리되는 데이터의 조직화된 집합으로, 데이터를 소프트웨어에서 효율적으로 관리하기 위한 저장소
- 데이터베이스 관리 시스템(DBMS)에 의해 제어
DBMS(Database Management System)
- Database를 관리하고 운영하는 시스템
- 데이터를 정의, 저장, 검색, 수정, 삭제하는 등의 작업을 효율적으로 수행할 수 있게 해줌
- 다수의 사용자들이 동시에 데이터에 접근하고, 데이터를 안전하게 관리할 수 있도록 다양한 기능을 제공
- SQL이라는 언어로 DBMS에 데이터 관리를 요청하면 DBMS가 요청을 처리
DBMS의 주요 기능
-
데이터 정의
- 데이터베이스 구조를 정의할 수 있는 기능을 제공
-
데이터 관리
- 데이터를 물리적으로 저장하고, 관리하는 역할을 수행
- 데이터를 저장하기 위한 최적화된 구조와 파일 시스템을 관리
- 사용자가 데이터를 다룰 수 있도록 쿼리 언어(SQL)을 제공
-
데이터 보안
- 사용자 권한 관리, 암호화, 감사 로그 등을 통해 데이터를 보호
-
트랜잭션 관리
- DBMS는 여러 사용자가 동시에 데이터에 접근할 때, 데이터의 일관성을 유지하기 위한 트랜잭션 관리 기능을 제공
- ACID 속성 보장
- Atomicity: 트랜잭션의 모든 작업이 성공적으로 완료되거나, 실패 시 모든 작업이 롤백
- Consistency: 트랜잭션이 데이터베이스를 일관된 상태로 유지
- Isolation: 동시에 실행되는 트랜잭션 간의 영향을 최소화
- Durability: 트랜잭션이 완료된 후 데이터의 변경 사항은 영구적으로 저장
-
백업 및 복구
- DBMS는 데이터 손실에 대비해 백업 및 복구 기능을 제공
- 정기적인 백업을 통해 데이터를 보호하며, 장애 발생 시 데이터 복구가 가능
-
동시성 제어
- 다수의 사용자가 동시에 데이터베이스에 접근하더라도 데이터 일관성이 유지되도록 동시성 제어를 제공 이를 통해 충돌이나 데이터 불일치를 방지할 수 있음
DBMS의 종류
1. 관계형 DMBS(RDBMS)
가장 많이 사용하는 데이터베이스- 데이터를 테이블 형태로 구조화하여 저장하고 관리하는 시스템
- 테이블 간의 관계를 이용해 데이터를 연결
ex) Oracle, MySQL, PostgreSQL, Microsoft SQL Server 등
- 비관계형 DBMS(NoSQL)
- 테이블이 아닌 key-value, document, graph 등의 다양한 형태로 데이터를 저장하고 관리
- 스키마가 고정되지 않고, 대규모 데이터 처리와 높은 확장성을 제공
ex) MongoDB, Cassandra, Redis 등
- 다중 모델 DBMS
- 하나의 데이터베이스 관리 시스템에서 여러 데이터 모델을 지원하는 시스템
- 동일한 DBMS에서 관계형 데이터뿐만 아니라 문서형, 그래프형 데이터를 함께 관리할 수 있음
ex) Amazon DynamoDB, Microsoft Azure Cosmos DB 등
트랜잭션(Transaction)
- 데이터베이스에서 하나의 논리적인 작업 단위
- 트랜잭션으로 묶여있는 작업들은 모두 성공적으로 완료되거나 하나라도 실패하면 전체가 취소
RDBMS
- 관계형 데이터베이스 RDB(Relational DataBase)를 관리할 수 있는 소프트웨어로 데이터를 테이블 형식으로 관리
- RDBMS는 데이터 간의 관계를 정의하고, 이러한 관계를 바탕으로 복잡한 Query를 실행할 수 있는 기능을 제공
관계형 데이터베이스 특징
-
테이블 (Table)
- RDBMS에서 데이터는 테이블이라는 구조에 저장되며 행(row)과 열(column)로 구성
- 열(column)은 데이터의 속성(유일한 이름)을 나타내고 타입(데이터 유형)을 가짐
- 행(row)은 관계된 데이터의 묶음을 의미하고 tuple 또는 record라고 불림
- 데이터 무결성
- 테이블은 특정 규칙과 제약 조건(기본 키, 외래 키, 유니크 등)을 통해 데이터를 저장함으로써 데이터의 무결성(정확성, 일관성, 유효성)을 유지
-
관계 (Relationships)
- 테이블 간의 관계는 외래 키(Foreign Key)를 통해 설정
- RDBMS는 다양한 유형의 관계를 지원
- 1:1 관계: 한 테이블의 한 행이 다른 테이블의 한 행과만 연결
- 1:다 관계: 한 테이블의 한 행이 다른 테이블의 여러 행과 연결
- 다:다 관계: 두 테이블의 여러 행이 서로 연결될 수 있음
-
SQL (Structured Query Language)
- RDBMS에서 데이터를 정의하고, 관리하기 위한 표준 언어
- 데이터를 생성(Create), 읽기(Read), 갱신(Update), 삭제(Delete)하는 작업을 수행
-
키 (Keys)
- 기본 키(Primary Key)
- 테이블 내에서 각 행을 고유하게 식별하는 열 또는 열의 조합
- 기본 키는 중복되지 않으며, NULL 값을 가질 수 없음
- 외래 키(Foreign Key)
- 한 테이블의 열이 다른 테이블의 기본 키를 참조하여 두 테이블 간의 관계를 설정하는 데 사용
- 테이블 간의 데이터 무결성을 유지할 수 있음
- 유일 키(Unique Key)
- 기본 키와 유사하지만, 하나의 테이블에서 여러 개가 존재할 수 있음
- 중복된 값을 허용하지 않지만, NULL 값은 허용할 수 있음
- 기본 키(Primary Key)
-
트랜잭션(Transaction)
- RDBMS는 트랜잭션이라는 단위를 통해 데이터베이스 작업을 처리하며, 이를 통해 데이터의 일관성과 무결성을 유지
- 트랜잭션은 원자성(Atomicity), 일관성(Consistency), 고립성(Isolation), 지속성(Durability)이라는 ACID 속성을 따름
-
정규화 (Normalization)
- 데이터의 중복을 줄이고, 일관성과 무결성을 유지하기 위해 데이터를 구조화하는 프로세스
- 여러가지 정규화 단계가 있으며, 각 단계는 데이터 중복을 줄이고 이상 현상을 방지하는 데 목적이 있음
-
데이터 무결성 (Data Integrity)
- 엔터티 무결성
- 각 테이블의 기본 키(PK)가 중복되지 않고 NULL 값이 아닌 상태를 유지
- 참조 무결성
- 외래 키(FK)를 통해 참조되는 데이터가 유효성을 유지하도록 보장
- 도메인 무결성
- 각 열이 정의된 데이터 타입과 제약 조건에 따라 유효한 값을 유지하도록 함
- 엔터티 무결성
-
인덱스 (Index)
- 특정 열의 검색 성능을 향상시키기 위해 사용
- 인덱스는 테이블의 데이터를 정렬하고, 효율적으로 접근할 수 있도록 지원
- 인덱스가 많아지면 삽입 및 수정 작업의 성능에 영향을 미칠 수 있음
- 대표적인 RDBMS
-
MySQL
- 오픈소스 기반의 RDBMS로 무료로 제공
- 빠른 속도와 높은 성능, 다양한 기능을 제공
- 광범위한 운영체제와 플랫폼에서 사용할 수 있음
- 전 세계적으로 널리 사용되며, 방대한 문서와 커뮤니티가 있어 학습 및 문제 해결이 용이
- 트래픽에 따라 확장할 수 있음
-
PostgreSQL
-
Oracle Database
-
Microsoft SQL Server
-
Database 2강
SQL(Structured Query Language)
관계형 데이터베이스 관리 시스템(RDBMS)에서 데이터를 정의, 조작, 제어, 조회하기 위해 사용되는 표준 프로그래밍 언어
SQL 특징
- 관계형 데이터베이스와의 상호작용을 표준화하고 효율적으로 수행할 수 있게 해줌
- 데이터베이스에서 원하는 정보를 추출하고 분석할 수 있게 해줌
- 대부분의 RDBMS(MySQL, PostgreSQL, Oracle 등)가 SQL을 지원
- 주의!⚠ 표준 SQL은 존재하지만, 제품마다 조금씩의 차이(함수명)가 존재
- SQL 명령문은 대소문자를 구분하지 않고, 대문자로 사용하면 가독성이 향상되어 오타를 방지
SQL 종류
- DDL(Data Definition Language)
데이터베이스 구조를 정의하는 데 사용
- CREATE
- 새로운 데이터베이스 및 테이블을 생성
- ALTER
- 기존 데이터베이스 및 테이블 구조를 수정
- DROP
- 데이터베이스 및 테이블을 삭제
- 데이터베이스 및 테이블을 삭제
- DML(Data Manipulation Language)
데이터베이스의 데이터를 조작하는 데 사용
- INSERT
- 데이터를 테이블에 삽입
- UPDATE
- 테이블의 기존 데이터를 수정
- DELETE
- 테이블의 데이터를 삭제
- 테이블의 데이터를 삭제
- DQL(Data Query Language)
- 데이터베이스에서 데이터를 검색하는 데 사용
- SELECT
- 데이터를 조회한다. 특정 조건을 추가할 수 있음
- 데이터를 조회한다. 특정 조건을 추가할 수 있음
- DCL(Data Control Language)
- 데이터베이스의 권한을 관리하는 데 사용
- GRANT
- 사용자에게 권한을 부여
- REVOKE
- 사용자의 권한을 회수
- 사용자의 권한을 회수
- TCL(Transaction Control Language)
여러 DML 작업을 하나의 논리적 단위로 묶어 트랜잭션으로 처리하는 데 사용
- COMMIT
- 트랜잭션이 성공한 것을 데이터베이스에 알리고 모든 변경 사항을 영구적으로 저장
- ROLLBACK
- 트랜잭션 중 발생한 모든 변경 사항을 취소하고, 데이터베이스를 트랜잭션 시작 시점의 상태로 되돌림
MySQL
1. 자료형
- MySQL Database에 사용할 수 있는 데이터 타입
- 숫자형
- 날짜형
- 문자형
- Boolean
2. 제약조건(Constraint)
- 데이터의 무결성을 지키기 위해 데이터를 입력받을 때 실행되는 검사 규칙
- 데이터 무결성
- 데이터의 정확성, 일관성, 완전성을 유지하는 것
- AUTO_INCREMENT
- 고유번호 자동생성(컬럼의 값이 중복되지 않게 1씩 자동으로 증가)
- NOT NULL
- 해당 필드는 NULL 값을 저장할 수 없게 됨
- UNIQUE
- 해당 필드는 서로 다른 값을 가져야만 함(동일한 값은 존재x)
- PRIMARY KEY(기본 키)
- FOREIGN KEY(외래 키)
- CASCADE
- 참조 무결성을 유지하기 위한 동작을 정의하는 규칙
- 외래 키(Foreign Key) 제약 조건과 관련된 변경 사항이 발생할 때 참조하는 레코드에 대한 동작을 자동으로 처리하는 기능
- DEFAULT
- 해당 필드의 기본 값을 설정
- 필드 값이 전달되지 않으면, 자동으로 기본 값을 저장
- 데이터 무결성
3. JOIN
- 두개 이상의 테이블을 연결하여 데이터를 검색하는 방법
- 테이블을 분리하여 데이터 중복을 최소화하고 데이터의 일관성을 유지하기 위해 사용
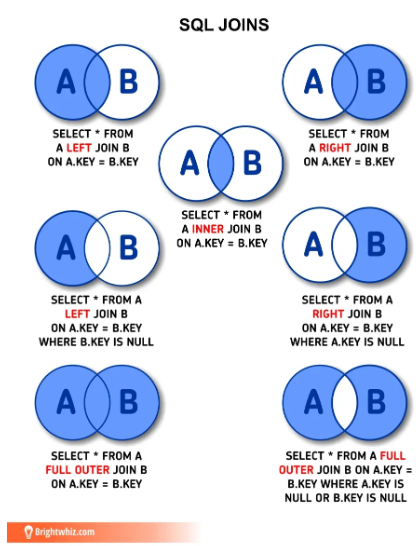
출처는 아래에 남겼습니다.
Java와 Database 1강
JDBC
- Java 언어를 사용하여 DB와 상호 작용하기 위한 자바 표준 인터페이스
- 데이터베이스 관리 시스템(DBMS)과 통신하여 데이터를 삽입(C), 검색(R) , 수정(U) 및 삭제(D)할 수 있게 해줌
JDBC 구조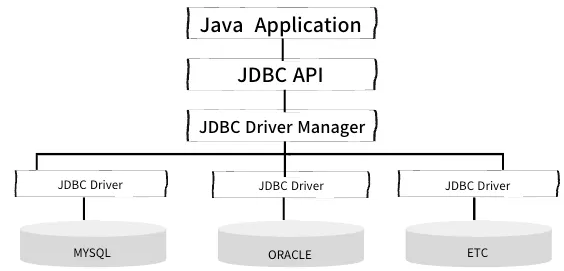
JDBC의 주요 특징
-
표준 API
- 대부분의 RDBMS에 대한 드라이버가 제공되어 여러 종류의 DB 대해 일관된 방식으로 상호 작용할 수 있음
ex) Database 종류가 바뀌어도 쿼리문이 실행된다. MySQL → ORACLE
-
데이터베이스 연결
-
SQL 쿼리 실행
-
Prepared Statement
-
결과 집합 처리(Result Set)
- 데이터베이스로부터 반환된 결과 집합을 처리할 수 있음
ex) 데이터를 조회하고 결과를 Java 객체로 매핑할 수 있음
-
트랜잭션 관리
- JDBC를 사용하여 데이터베이스 트랜잭션을 시작, 커밋(성공) 또는 롤백(실패)하는 등의 트랜잭션 관리 작업을 수행할 수 있음
Statement VS Prepared Statement
- Java에서 데이터베이스에 SQL 쿼리를 실행하기 위한 인터페이스
- 데이터베이스와의 통신을 통해 쿼리 결과를 반환하거나 데이터 조작을 수행하는 데 사용
- Statement
- DB와 연결되어 있는 Connection 객체를 통해 SQL문을 Database에 전달하여 실행하고, 결과를 반환받는 객체
public class StatementExample {
public static void main(String[] args) {
try {
// MySqlDriver 파일을 라이브러리에 추가한다.
// Driver연결
Class.forName("mysql.jdbc.driver.MySqlDriver");
// Database와 연결(계정 접속)
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost/mydatabase", "username", "password");
// Statement 인스턴스 생성
Statement statement = connection.createStatement();
// String SQL Query
String query = "SELECT * FROM MEMBER WHERE NAME = 'wonuk'";
// Query 실행 -> 결과는 ResultSet으로 반환된다.
ResultSet rs = statement.execute(query);
// 결과 처리
while (rs.next()) {
// 결과 처리 로직
}
// 연결을 수동으로 끊어줘야한다.
rs.close();
statement.close();
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}- SQL 쿼리를 직접 문자열로 작성하여 데이터베이스에 보내는 방법
- SQL 쿼리는 실행 전에 문자열 형태로 전달되고, 실행 시점에 데이터베이스에 직접 파싱되고 실행
- 매번 실행할 때마다 SQL 문을 다시 파싱하므로 성능에 영향을 미칠 수 있고, 보안 취약점을 가질 수 있습니다.
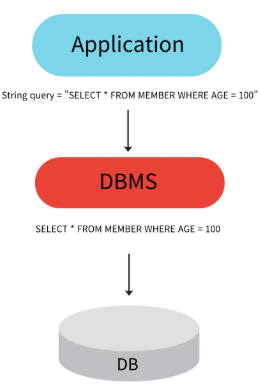
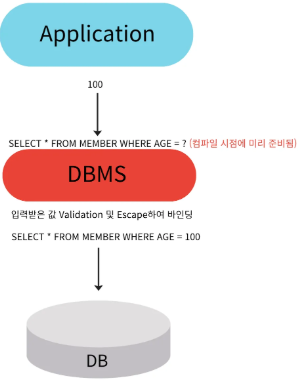
- Prepared Statement
- SQL문을 Complie 단계에서
?를 사용하여 preCompile 하여미리 준비해놓고 Query문을 파라미터 바인딩 후 실행하고 결과를 반환받음
public class PreparedStatementExample {
public static void main(String[] args) {
try {
// [Mysql.jdbc.driver.MysqlDriver] 파일을 라이브러리에 추가한다.
Class.forName("mysql.jdbc.driver.MysqlDriver");
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost/mydatabase", "username", "password");
String query = "SELECT * FROM employees WHERE department = ?";
PreparedStatement preparedStatement = connection.prepareStatement(query);
// 값을 설정
preparedStatement.setString(1, "HR");
ResultSet resultSet = preparedStatement.executeQuery();
while (resultSet.next()) {
// 결과 처리 코드
}
resultSet.close();
preparedStatement.close();
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}- SQL 쿼리를 미리 컴파일하여 데이터베이스에 전송할 때 값만 바뀌는 형태로 전달
- 쿼리가 한 번 컴파일되면 여러 번 실행할 수 있으며, 성능이 향상되고 보안 측면에서 더 안전
- 동적인 입력값을 placeholder
?로 대체하고 파라미터 바인딩을 통해 쿼리를 삽입 즉, 사용자 입력을 직접적으로 쿼리에 삽입하지 않음 - 이스케이핑 처리를 지원한다. 말그대로 탈출(Escape), 입력값이 자동으로 쿼리에 안전하게 이스케이핑. 이스케이핑은 입력 데이터에서 잠재적인 SQL 쿼리 문자열을 무력화
웹 보안
1. SQL Injection
-
악의적인 사용자가 애플리케이션에서 입력 데이터를 이용하여 SQL 쿼리를 조작하고 데이터베이스에 무단 접근하거나 데이터를 변조하는 공격
-
SQL Injection 종류
- Error Based SQL Injection
- Database에 고의적으로 오류를 발생시켜 에러 응답을 통해 DB 구조를 파악하는 방법
- Union Based SQL Injection
- 컬럼의 개수와 데이터 형식이 같아야 함
- DB의 UNION 연산자를 사용하여 쿼리 결과값의 조합을 통해 정보를 조회
- Blind Based SQL Injection
- Stored Procedure SQL Injection
- Time Based SQL Injection
- Error Based SQL Injection
ex)
# 아이디를 입력하는 email에 WONUK or 1=1 #를 입력
SELECT * FROM MEMBER
WHERE email = 'WONUK or 1=1 #' AND password = 'tutor';// 검증
public String login(String id, String password) {
// 매개변수 id, password 가 문제없는지 검증하는 로직 Escape 등
String query =
"SELECT * FROM MEMBER WHERE ID = " + id + "AND PASSWORD = " + password;
return query;
}- 해결방법
- 클라이언트에게 에러 메세지 노출을 차단
- 위 자바 코드와 같이 입력값을 검증(Validation)
- Prepared Statements를 사용
2. XSS(Cross Site Scription)
-
악성 스크립트를 웹사이트에 주입하는 Code Injection 기법 중 하나
-
공격자가 웹 어플리케이션에 보낸 악성 코드가 다른 사용자에게 전달될 때 발생
-
XSS의 종류
- Stored XSS
-
공격자가 취약점이 있는 Web Application에 악성 스크립트를 영구적으로 저장하여 다른 사용자에게 전달하는 방식
ex) 게시판(HTML) 글 작성
<script>alert(document.cookie);</script> -
해당 script를 게시글에 삽입하면 HTML로 구성되어 있기 때문에 해당 스크립트가 조회하는 사용자에게 실행된다.
-
- Reflected XSS
-
외부 링크 페이지로 이동시킴
ex) 메일 내 첨부된 링크 클릭 → 가짜 사이트로 연결
-
- DOM based XSS
- Stored XSS
-
해결방법
- 입/출력 값을 검증(Validation)하고 필터링하여 해결
- 외부 보안관련 라이브러리를 사용
- 보안 솔루션을 사용
Java와 Database 2강
Persistence Framework
애플리케이션에서 데이터를 영구적으로 저장하고 관리하기 위해 데이터베이스와 같은 저장소와의 상호 작용을 단순화하는 소프트웨어 도구
JDBC의 한계
- 간단한 SQL을 실행하는 경우에도 중복된 코드가 너무 많음
public class PreparedStatementExample {
public static void main(String[] args) {
try {
// ojdbc6.jar[oracle.jdbc.driver.OracleDriver] 파일을 라이브러리에 추가한다.
Class.forName("oracle.jdbc.driver.OracleDriver");
// 1. Connection
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost/mydatabase", "username", "password");
String query = "SELECT * FROM employees WHERE department = ?";
// 2. Statement
PreparedStatement preparedStatement = connection.prepareStatement(query);
// 값을 설정
preparedStatement.setString(1, "HR");
// 3. ResultSet
ResultSet resultSet = preparedStatement.executeQuery();
while (resultSet.next()) {
// 결과 처리 코드
}
resultSet.close();
preparedStatement.close();
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}- Connection, Prepared Statement, ResultSet 등
- DB에 따라 일관성 없는 정보를 가진 채로 Checked Exception(SQL Exception) 처리
- Checked Exception인 SQLException은 개발자가 명시적으로 처리해야 함
- 각 DBMS는 고유한 SQL 문법과 오류 코드 체계를 가지고 있다.
- JDBC에서 발생하는 SQLException은 이러한 DBMS에 따라 달라질 수 있으며, 예외 메시지나 코드도 DB마다 다를 수 있다. 즉, 모두 그에 맞게 처리해야 함
-
Connection과 같은 공유 자원을 제대로 반환하지 않으면 한정된 시스템 자원(CPU, Memory)에 의해 서버가 다운되는 등의 문제가 발생
-
SQL Query를 개발자가 직접 작성
- 중복 적인 쿼리 및 코드 작성이 필요
- 대부분의 테이블에 CRUD하는 쿼리가 포함
Persistence Framework의 등장
- JDBC 처럼 복잡함이나 번거로움 없이 간단한 작업만으로 Database와 연동되는 시스템
- 모든 Persistence Framework는 내부적으로 JDBC API를 이용
- preparedStatement를 기본적으로 사용
→ 위에서 JDBC를 설명한 이유. - 크게 SQL Mapper, ORM 두가지로 나눌 수 있다.
JDBC, SQL MAPPER, ORM의 공통점
- 영속성(Persistence) 데이터를 생성한 프로그램의 실행이 종료되더라도 사라지지 않는 데이터의 특성, 영구히 저장되는 특성
SQL Mapper
- 직접 작성한 SQL 문의 실행 결과와 객체(Object)의 필드를 Mapping하여 데이터를 객체화
- 대표적인 SQL Mapper는 Spring JDBC Template, MyBatis
Spring JDBC Template
- Spring Framework에서 제공하는 JDBC 작업을 단순화하고 개선한 유틸리티 클래스
JDBC Template의 장점
- 간편한 데이터베이스 연결
- 손수 적었던 Connection 관련 코드들을 yml 혹은 properties 파일에 설정만으로 해결
- Prepared Statement를 사용
- 예외 처리와 리소스 관리
- DB Connection을 자동으로 처리하여 리소스 누수를 방지
- 결과 집합(ResultSet) 처리
- 데이터를 자바 객체로 변환할 수 있도록 도움
- 배치 처리 작업을 지원한다.
- 매일 동일한 시간에 수행되는 쿼리, 주로 통계에 사용
ex)
// 1. XML OR Gradle에 Spring JDBC 의존성 추가
// 2. application.properties OR application.yml에 데이터베이스 연결 설정
@RestController
public class MemberController {
private final MemberRepository memberRepository;
public MemberController(MemberRepository memberRepository) {
this.memberRepository = memberRepository;
}
@GetMapping("/members")
public List<Member> findById(Long id) {
return memberRepository.findById(id);
}
}
// Member Object
public class Member {
private Long id;
private String name;
private int age;
// Getter and Setter methods
}
@Repository
public class MemberRepository {
private final JdbcTemplate jdbcTemplate;
public MemberRepository(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
// Member 객체로 리턴한다.
public List<Member> findById(Long id) {
String query = "SELECT * FROM MEMBER WHERE id = " + id;
return jdbcTemplate.query(query, (rs, rowNum) -> {
Member member = new Member ();
member.setId(rs.getLong("id"));
member.setName(rs.getString("name"));
member.setAge(rs.getInt("age"));
return member;
});
}
}MyBatis
- SQL 쿼리들을 XML 파일에 작성하여 코드와 SQL을 분리하여 관리되도록 만들어줌
- SQL과 Java Code의 분리가 핵심
- Query를 JAVA에서 XML로
- 복잡한 JDBC 코드가 사라짐
- ResultSet과 같이 결과값을 맵핑하는 객체X
- 설정이 간단
- 관심사를 분리 → SQL 을 따로 관리
- XML 안에있는 SQL을 Java의 메소드에 매핑
MyBatis 장점
- 자동으로 Connection 관리를 해주면서 JDBC 사용할 때의 중복 작업 대부분을 없애줌
- DB 결과 집합을 자바 객체로 매핑할 수 있음
- 복잡한 쿼리나 다이나믹하게(동적쿼리) 변경되는 쿼리 작성이 쉬움
- 상황에 따라 분기처리(IF)를 통해 쿼리를 동적으로 만들어주는것
- 관심사 분리 - DAO로부터 SQL문을 분리하여 코드의 간결성 및 유지보수성이 향상
- 쿼리 결과를 캐싱하여 성능을 향상시킬 수 있음ex)
Mapper XML SQL 쿼리와 객체 매핑을 정의// User 클래스 public class User { private Long id; private String userName; private String email; // Getter and Setter methods } // Mapper Interface 생성 : SQL 쿼리와 매핑을 정의하는 인터페이스 public interface UserMapper { User getUserById(Long id); } public class Main { public static void main(String[] args) { String resource = "mybatis-config.xml"; try (Reader reader = Resources.getResourceAsReader(resource)) { SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(reader); try (SqlSession session = sqlSessionFactory.openSession()) { UserMapper userMapper = session.getMapper(UserMapper.class); User user = userMapper.getUserById(1L); System.out.println(user.getId() + ", " + user.getUsername() + ", " + user.getEmail); } } catch (IOException e) { e.printStackTrace(); } } }
MyBatis 설정 파일 작성<mapper namespace="com.example.UserMapper"> <select id="getUserById" resultType="com.example.User"> SELECT id, userName, email FROM users WHERE id = #{id} </select> </mapper><configuration> <environments default="development"> <environment id="development"> <transactionManager type="JDBC" /> <dataSource type="POOLED"> <property name="driver" value="com.mysql.jdbc.Driver" /> <property name="url" value="jdbc:mysql://localhost:3306/mydb" /> <property name="userName" value="userName" /> <property name="password" value="password" /> </dataSource> </environment> </environments> <mappers> <mapper resource="com/example/UserMapper.xml" /> </mappers> </configuration>
SQL Mapper의 한계
-
SQL을 직접 다룸
-
특정 DB에 종속적으로 사용하기 쉬움
- DB마다 Query문, 함수가 조금씩 다름
→ 다른 DB를 사용하면 쿼리도 변경해야할 가능성이 높음
-
테이블마다 비슷한 CRUD SQL, DAO(Data Access Object) 개발이 반복 → 코드 중복
-
테이블 필드가 변경될 시 이와 관련된 모든 DAO의 SQL문, 객체의 필드 등을 수정해야 함
- 코드상으로 SQL과 JDBC API를 분리했지만 논리적으로 강한 의존성을 가지고 있음
-
객체와의 관계는 사라지고 DB에 대한 처리에 집중하게 됨
→ SQL 의존적인 개발
관계형 DB와 객체지향의 패러다임 불일치
-
객체지향으로 설계된것을 관계형 DB에 저장하기란 어려움
-
테이블에 저장한 데이터를 다시 객체화 하는 것도 어려움
// 1. 객체 안의 객체 public class Member { // 필드들.. private Team team; } -> ERD? // 2. 상속 구조 public class Member extends Person { // 필드들.. } -> ERD? // 3. extends, implements public class Member extends Person implements Workable { // 필드들.. } -> ERD? -
객체지향 : 캡슐화, 추상화, 상속, 다형성 → 객체 중심
-
관계형 데이터베이스(RDB) → 데이터 중심의 구조
-
각각 지향하는 목적이 다르기 때문에 사용 방법과 표현 방식에 차이가 있음
SQL JOINS 사진 출처 : https://medium.com/@aakriti.sharma18/joins-in-sql-4e2933cedde6
느낀 점
오늘은 내일 쉬니까 강의를 정말 열심히 들었고 TIL도 많이 따라잡고 있다. 조금만 더 힘내보자! 주말에 쉬면서 복습도 쉬엄쉬엄 하고 TIL도 조금 쓰고 회복 잘해서 다음 주도 열심히 해보는 걸로~ (☆▽☆)
