학습 요약
schedulev2
schedulev2 lv1~lv4
현재 진행사항
lv1의 Schedulev2 crud 중에서 rud 아직 못 만듬, lv2,lv3는 다 했고 lv4의 filter까지 구현, login api 새로 작성완료, 다른 api 수정중
lv4의 인증처리만 적용하면 거의 다 할 것 같고 코드는 너무 많아서 깃허브 주소를 남기겠습니다.
깃허브 주소 -> https://github.com/byeongtaek12/ScheduleProject-Spring-JPA
Spring 숙련 - 3주차
객체와 관계형 데이터베이스
관계형 DB에 객체 저장 시 발생하는 문제점
- 리소스별 CRUD 반복
- 객체 수정
- SQL을 모두 수정 해야 함
- RDB를 사용하고, 데이터를 CRUD 하기 위해서는 SQL을 반드시 사용해야 함
- 결과적으로 SQL에 의존적인 개발을 해야 함
- 패러다임 불일치 문제
패러다임 불일치 문제 1
- 객체에서는 상속과 다형성을 통해 객체 관계를 표현할 수 있지만 RDB는 이 개념을 직접 지원하지 않고 별도 매핑이 필요
- 객체는 참조로 관계를 표현하고 RDB는 JOIN을 사용하여 관계를 결합
1. 상속
-
DB는 상속관계 없음
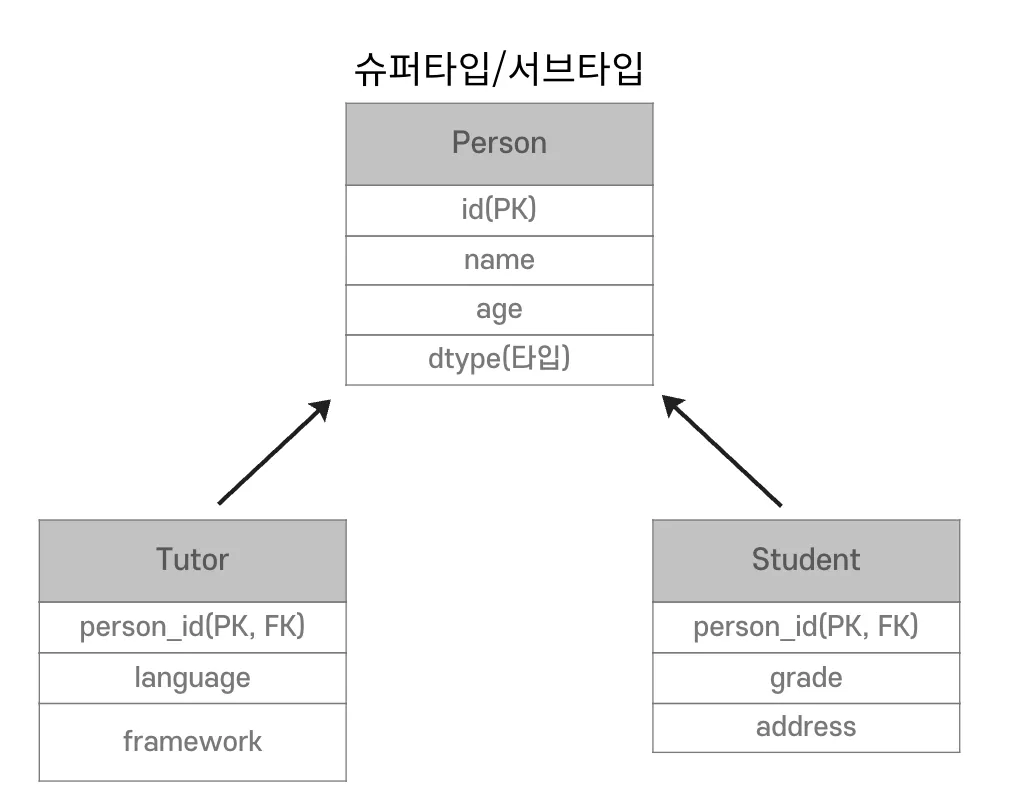
-
관계형 DB에서는 Data를 슈퍼타입, 서브타입 관계로 설정
- 각각의 객체별로 JOIN SQL 작성, 객체 생성 및 데이터 세팅이 필요
- 까다롭기 때문에 DB에 저장할 객체는 상속 관계를 사용X
2. 연관관계
-
테이블의 연관관계는 외래 키를 사용
- 하나의 INSERT SQL로 저장이 가능
- 조회하고자 하는 테이블만 조회하면 됨
-
객체의 연관관계는 참조를 사용
- 데이터베이스를 두번 조회 해야 함
- 알맞은 데이터를 직접 세팅 해야 함
-
조회 SQL
- 데이터베이스 성능을 위해 JOIN을 사용하여 한번에 조회
패러다임 불일치 문제 2
객체 지향 언어에서 데이터와 동작을 함께 캡슐화하는 방식과, RDB가 데이터를 정규화된 테이블에 관계 중심으로 저장하는 방식의 차이에서 발생하여 객체를 데이터베이스에 저장하거나 조회할 때 복잡한 매핑과 변환이 필요해지고 코드의 복잡성과 개발자의 부담이 증가
- 객체 그래프
- 객체는 연관된 객체를 탐색할 수 있어야 함
- SQL Query
SELECT p.*, c.* FROM product p JOIN category c ON p.category_id = c.id;- 실제로는 실행된 SQL 만큼만 탐색할 수 있음
- Entity의 신뢰성에 문제가 발생
- 객체의 비교
Product product1 = productRepository.findById(productId);
Product product2 = productRepository.findById(productId);
product1 == product2; // false- 데이터는 같지만, 새로운 인스턴스기 때문에 객체의 주소값이 다름
Java Collection 사용
Collection에 저장하면 편하게 사용할 수 있음
JPA
객체 지향 프로그래밍 언어인 Java와 관계형 데이터베이스 간의 패러다임 불일치 문제를 해결하여 데이터베이스 작업을 객체 지향적으로 수행할 수 있도록 지원
-
Java의 ORM 기술 표준(인터페이스)
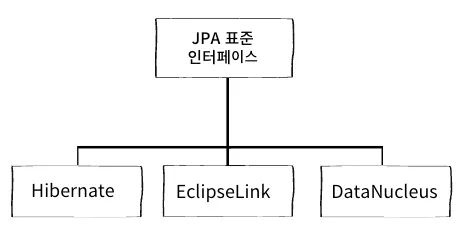
- 대표적인 구현체로 Hibernate를 주로 사용
- 표준으로 만들어지면 더욱 명확하게 정의하고 사용할 수 있는 장점이 생김
-
ORM(Object-Relational Mapping)
- 객체와 관계형 DB를 자동으로 Mapping하여 패러다임 불일치 문제를 해결한다.
- JDBC API
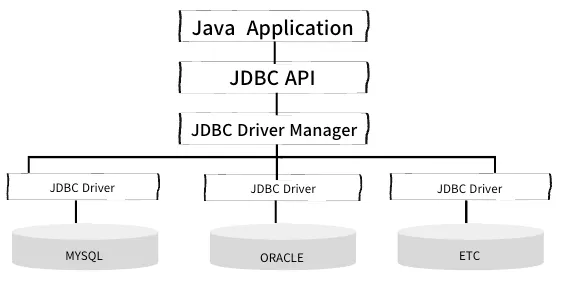
- 데이터베이스와 상호작용 하기위해 JDBC API를 개발자가 직접 사용
-
개발자가 아닌 JPA가 JDBC API를 내부적으로 사용하여 중간에서 개발자의 역할을 함
JPA를 사용하는 이유
- 생산성
- 유지보수성
- 패러다임 불일치 문제 해결
- 성능
hibernate.dialect
Hibernate가 사용하는 데이터베이스 방언(dialect)을 지정하는 설정으로 데이터베이스와 Hibernate가 상호작용할 때 특정 데이터베이스에 맞게 SQL 구문을 자동으로 조정하는 역할을 수행
영속성 컨텍스트 1강
영속성 컨텍스트
- Entity 객체를 영속성 상태로 관리하는 일종의 캐시 역할을 하는 공간
- 여기에 저장된 Entity는 데이터베이스와 자동으로 동기화되며 같은 트랜잭션 내에서는 동일한 객체가 유지
- 눈에 보이지 않는 공간이 생기고 Entity Manager를 통해 접근
Entity
데이터베이스에서 Entity란 저장할 수 있는 데이터의 집합
- JPA에서 Entity란 데이터베이스의 테이블을 나타내는 클래스
Entity 생명주기
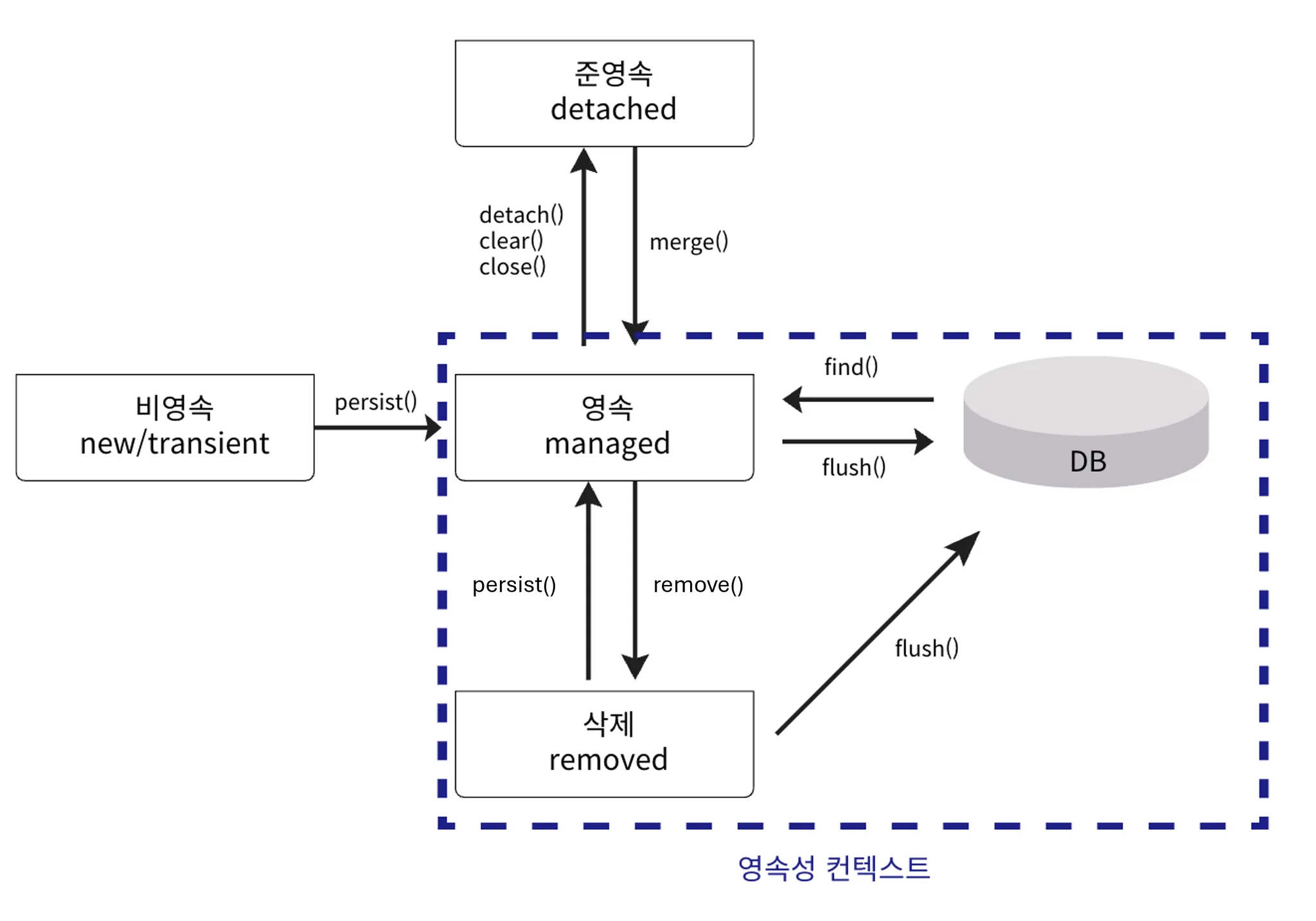
- 비영속(new/transient)
- 영속성 컨텍스트가 모르는 새로운 상태
- 데이터베이스와 전혀 연관이 없는 객체
- 영속(managed)
- 영속성 컨텍스트에 저장되고 관리되고 있는 상태
- 데이터베이스와 동기화되는 상태
- 준영속(detached)
- 영속성 컨텍스트에 저장되었다가 분리되어 더 이상 기억하지 않는 상태
- 삭제(removed)
- 영속성 컨텍스트에 의해 삭제로 표시된 상태
- 트랜잭션이 끝나면 데이터베이스에서 제거
Entity 상태
비영속, 영속, 준영속, 삭제 상태로 나뉘며 영속 상태일 때만 JPA의 영속성 컨텍스트가 데이터를 관리
- 비영속
Tutor tutor = new Tutor(1L, "이름", 100);- 영속
em.persist(tutor);
transaction.commit();- 트랜잭션 커밋 시점에서 SQL 실행
- 준영속
- 준영속 상태로 만드는 방법
em.detach()- 특정 Entity만 준영속 상태로 변경
em.clear()- 영속성 컨텍스트를 초기화
em.close()- 영속성 컨텍스트를 종료
- 삭제
em.remove(tutor);영속성 컨텍스트 2강
1차 캐시
- 엔티티를 영속성 컨텍스트에 저장할 때 생성되는 메모리 내 캐시
- 엔티티는 먼저 1차 캐시에 저장되고 이후 같은 엔티티를 요청하면 DB를 조회하지 않고 1차 캐시에서 데이터를 반환하여 성능을 높일 수 있음
// 비영속
Tutor tutor = new Tutor(1L, "이름", 100);
// 영속, 1차 캐시에 저장
em.persist(tutor);
// 1차 캐시에서 조회
Tutor findTutor = em.find(Tutor.class, 1L);1차 캐시가 없다면?
// 데이터베이스에서 조회 후 1차 캐시에 저장
Tutor findTutor = em.find(Tutor.class, 1L);✔1차 캐시는 동일한 트랜잭션에서만 사용 가능
동일성 보장
- 동일한 트랜잭션 안에서 특정 엔티티를 여러 번 조회해도 항상 같은 객체 인스턴스를 반환
- 1차 캐시를 사용하여 같은 엔티티를 중복 조회해도 동일한 객체를 참조하게 하여 일관성을 유지
쓰기 지연
- 엔티티 객체의 변경 사항을 DB에 바로 반영하지 않고 트랜잭션이 커밋될 때 한 번에 반영하는 방식
- 이를 통해 성능을 최적화하고 트랜잭션 내에서의 불필요한 DB 쓰기 작업을 최소화
영속성 컨텍스트 3강
변경 감지(Dirty Checking)
영속성 컨텍스트가 엔티티의 초기 상태를 저장하고 트랜잭션 커밋 시점에 현재 상태와 비교해 변경 사항이 있는지 확인하는 기능
Tutor tutor = em.find(Tutor.class, 1L);
tutor.setName("수정된 이름");- em.persist(tutor); 로 저장하지 않아도 update SQL이 실행
✔오히려 쓰게 되면 에러가 날 수도 있어서 사용하지 않아야 실수 방지 가능
내부 동작
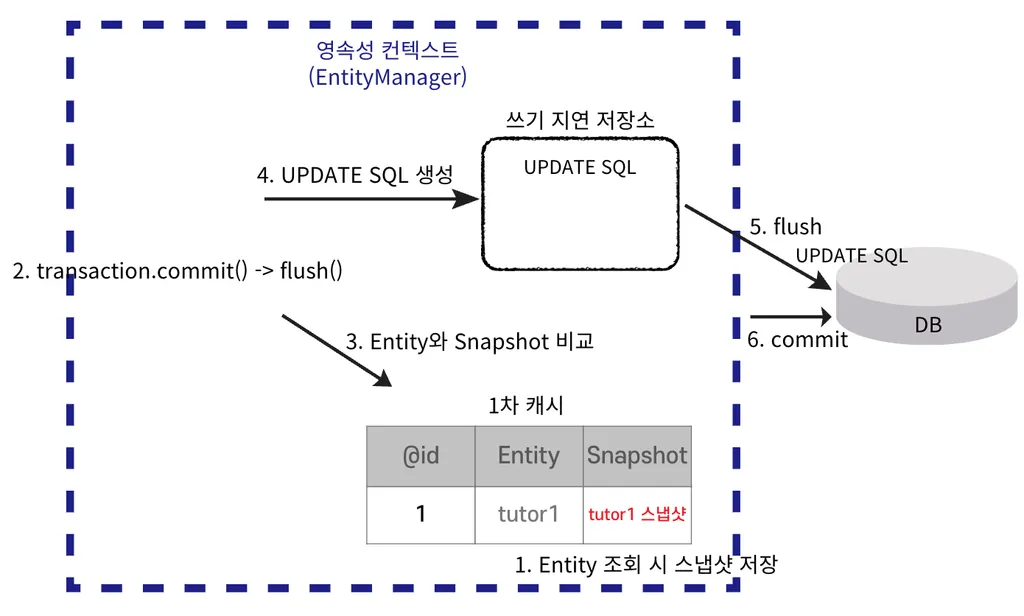
- 미리 찍어둔 스냅샷과 비교하여 알아서 UPDATE SQL 생성, DELETE도 마찬가지임
flush
- 영속성 컨텍스트의 변경 내용을 데이터베이스에 반영하는 기능
- 변경된 엔티티 정보를 SQL로 변환해 데이터베이스에 동기화
- 트랜잭션 커밋 시 자동으로 실행되지만 특정 시점에 데이터베이스 반영이 필요할 때 수동으로 호출할 수도 있음
Entity 만들기 1강
@Entity
클래스에 @Entity를 붙이면 JPA가 관리하는 Entity가 됨
- JPA를 사용하여 객체를 테이블과 매핑할 때 사용
- PK 값이 필수
- 기본 생성자가 필수
- final, enum, interface, inner 클래스에는 사용X
- 필드에 final 키워드를 사용X
@Table
- 속성
name- Entity와 매핑할 테이블 이름을 지정
- 기본 값은 Entity 이름(Tutor)을 사용
catalog- 데이터베이스 catalog 매핑
schema- 데이터베이스 schema 매핑
uniqueConstraints- DDL 생성 시 유니크 제약 조건 설정
hibernate.hbm2ddl.auto
- JPA는 Application 로딩 시점에 DDL을 자동으로 생성하는 기능을 지원
- 방언(dialect)을 사용하여 Entity Mapping만 하여도 데이터베이스에 맞는 적절한 DDL이 생성
DDL 자동 생성 속성
create: 기존 테이블을 삭제(DROP) 후 다시 생성(CREATE)
create-drop: DROP 후 CREATE 하고 종료시점에 테이블을 삭제(DROP), 테스트 시 사용
update: 변경된 사항만 DDL에 반영
validate: Entity와 테이블이 정상적으로 매핑 되었는지 확인. 실패 시 예외 발생
none: 속성 사용X
- application.properties 에서 사용
제약조건 설정
- JPA를 사용하면 DDL 생성 시 제약조건을 설정할 수 있음
- 실행 로직과는 별개로 DDL 생성시에만 활용
@Column(unique = true, length = 20, nullable = false)Entity 만들기 2강
필드 매핑
JPA로 관리되는 클래스인 Entity의 필드는 테이블의 컬럼과 매핑
사용되는 Annotation
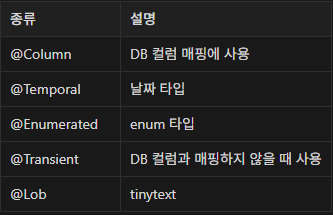
@Column 속성
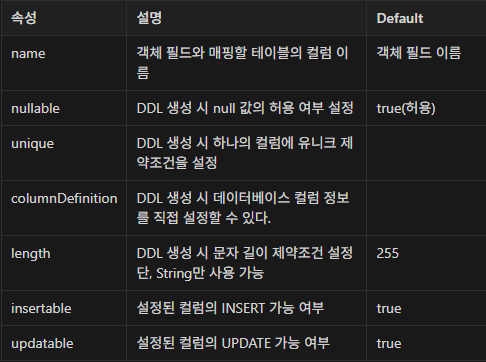
기본 키
JPA Entity를 생성할 때 기본키는 필수로 생성해야 함
- 사용되는 Annotation
- @Id
- 수동 생성
Tutor tutor = new Tutor(1L, "이름"); - 수동 생성
- @GeneratedValue
- 자동 생성
@Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id;
- @Id
- PK 생성 전략
- 영속성 컨텍스트는 PK가 필수
- 가장 권장되는 방식은
LongType의 기본 키를 사용하는 것
- 가장 권장되는 방식은
- strategy 속성
GenerationTypeIDENTITY: MySQL, PostgreSQL에서 사용, 데이터베이스가 PK 자동 생성SEQUENCE: Oracle에서 사용,@SequenceGenerator와 함께 사용TABLE: 키 생성용 테이블을 사용,@TableGenerator와 함께 사용AUTO: dialect에 따라 자동 지정, 기본값- MySQL이면
IDENTITY, Oracle이면SEQUENCE로 설정
- MySQL이면
- 영속성 컨텍스트는 PK가 필수
✅ 기본적으로 AUTO_INCREMENT는 DB에 INSERT SQL이 실행된 이후 PK를 알 수 있지만 IDENTITY 전략은 트랜잭션 Commit 후가 아닌 em.persist() 시점에 즉시 INSERT SQL을 실행하여 PK를 바로 조회할 수 있음
연관관계 Mapping 1강
단방향
- 단방향 연관관계는 객체 간의 관계가 한쪽에서만 참조될 수 있는 관계
- 설정이 단순하고 유지 관리가 쉬우며 불필요한 데이터 접근을 방지할 수 있음
객체 설계
- 데이터베이스 중심
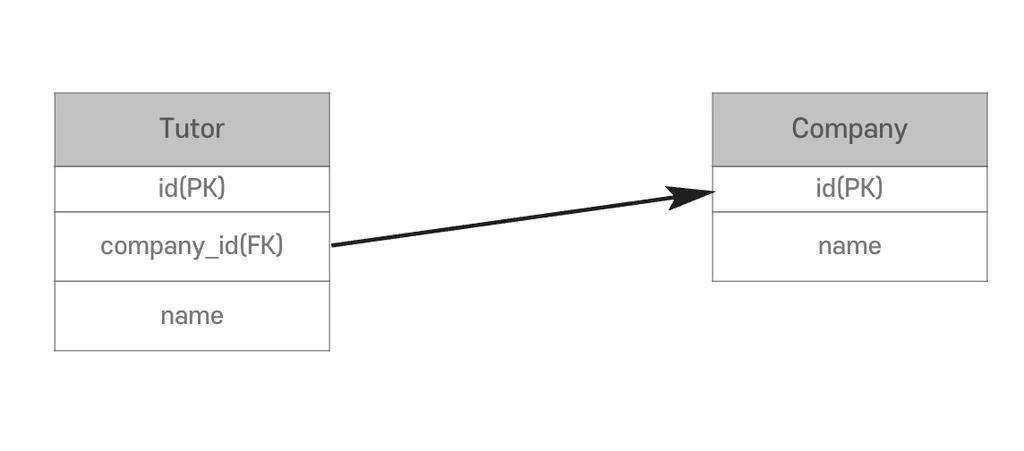
- FK 값은 Tutor가 가지고 있음
- Tutor만 참조할 수 있음
- N:1, 다대일 연관관계, 가장 많이 사용
- 여러명(N)의 Tutor가 어떤 Company(1)에 소속 되어있는지 설정할 수 있음
- Java Collection을 사용하는 것처럼 tutor.getCompany() 를 사용X
- 객체 지향
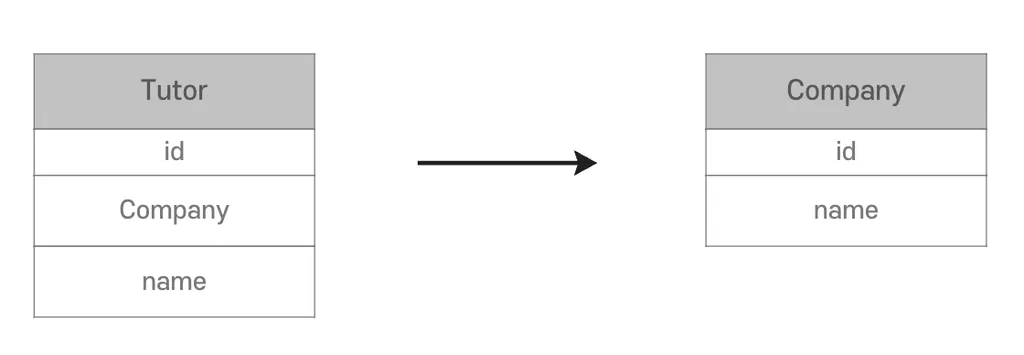
- 객체는 다른 객체를 참조
- N:1 관계는
@ManyToOne,@JoinColumn을 사용 - Tutor의 FK와 Company의 PK를 @JoinColumn으로 매핑하면 Java Collection을 사용하는 것처럼 tutor.getCompany() 가능
양방향
- 양방향 연관관계는 객체 간의 관계가 양쪽에서 서로를 참조할 수 있는 관계를 의미
- 이를 통해 양쪽에서 데이터를 쉽게 접근할 수 있지만 관계를 관리할 때 한쪽에서만 연관관계를 설정하거나 삭제하지 않도록 주의가 필요
단방향 연관관계
Tutor findTutor = em.find(Tutor.class, 1L);
Company findCompany = findTutor.getCompany();
// 단방향 연관관계에서 아래 코드는 실행이 불가능
findCompany.getTutor();- 양쪽으로 참조 하고자 한다면, 양방향 연관관계를 설정
양방향 연관관계
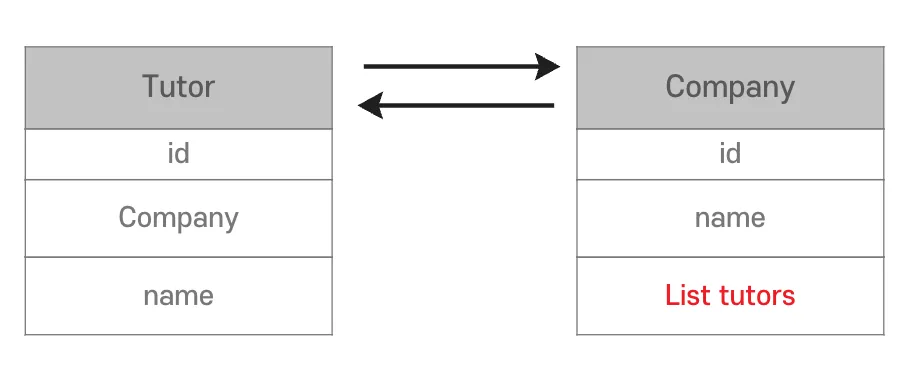
- 양방향 연관관계 설정을 위해
mappedBy속성을 설정- Tutor의
company필드와 매핑
- Tutor의
- 반대 방향으로 객체 그래프를 탐색 가능
양방향 연관관계의 주인
- mappedBy는 JPA 양방향 연관관계 설정 시 사용되는 속성으로 두 엔티티 간의 관계에서 연관관계의 주인이 아닌 쪽에 선언
- 이를 통해 외래 키 관리 책임을 주인 엔티티에 두고 매핑이 중복되지 않도록 함
연관관계의 주인 선정 기준
- 항상 FK가 있는 곳을 연관관계의 주인으로 지정
- Company가 주인인 경우
- Company를 수정할 때 Tutor를 Update하는 SQL이 실행
- 두번의 SQL이 실행
Spring Data JPA 1강
Spring Boot와 JPA
- Spring Boot는 JPA 설정을 자동으로 구성해 주어 JPA를 쉽게 사용할 수 있도록 도와줌
- 기본적으로 필요한 EntityManagerFactory와 TransactionManager를 자동으로 설정하고 데이터베이스 관련 설정을 application.properties 파일에서 간단히 지정할 수 있게 해줌
Spring Data JPA
- Spring Data JPA는 Spring Framework에서 제공하는 모듈로 JPA를 쉽게 사용할 수 있도록 지원
- 이를 통해 데이터베이스와 상호작용을 간편하게 구현할 수 있고 코드를 간소화
- JPA 추상화 Repository 제공
CrudRepository,JpaRepository인터페이스를 제공- SQL이나
EntityManager를 직접 호출하지 않아도 기본적인 CRUD 기능을 손쉽게 구현
- JPA 구현체와 통합
- 일반적으로 Hibernate를 통해 자동으로 SQL이 생성
- QueryMethods
- Method 이름만으로 SQL을 자동으로 생성
@Query를 사용하여 JPQL 또는 Native Query를 정의할 수 있음
- 트랜잭션 관리와 LazyLoading
- 트랜잭션 기능을 Spring과 통합하여 제공
- 연관된 Entity를 필요할 때 로딩하는 지연로딩 기능을 지원
SimpleJpaRepository
- Spring Data JPA의 기본 Repository 구현체로 JpaRepository 인터페이스의 기본 메서드들을 실제로 수행하는 클래스
- 내부적으로 EntityManager를 사용하여 JPA Entity를 DB에 CRUD 방식으로 저장하고 관리하는 기능을 제공
사용방법
public interface MemberRepository extends JpaRepository<Member, Long> {
} // <"@Entity 클래스", "@Id 데이터 타입">Spring Data JPA 2강
Query Methods
- Spring Data JPA에서 메서드 이름을 기반으로 데이터베이스 쿼리를 자동 생성하는 기능
- 직접 SQL을 작성하지 않고도 복잡한 쿼리를 쉽게 수행O
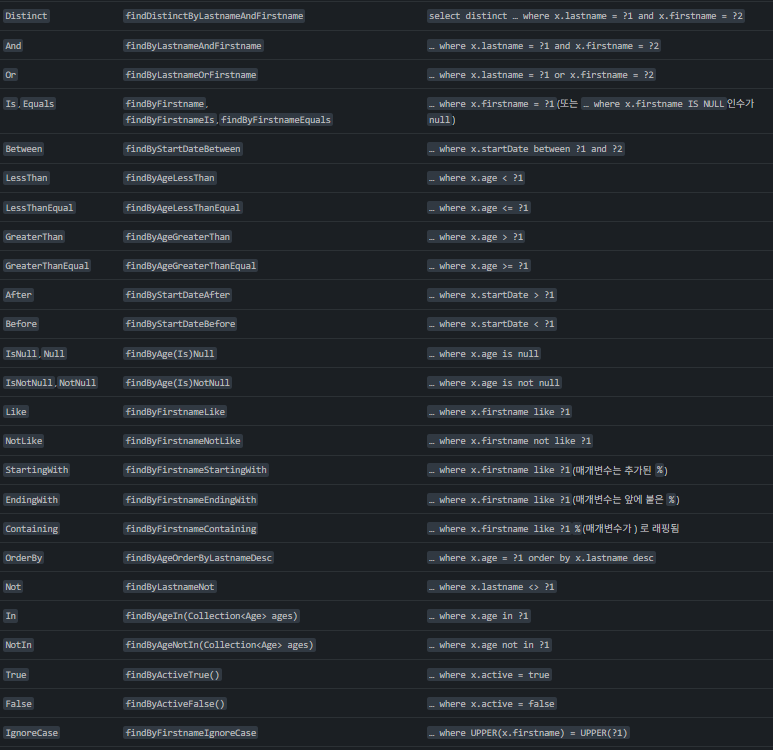
출처: 쿼리 공식문서 https://docs.spring.io/spring-data/jpa/reference/jpa/query-methods.html
JPA Auditing
- 엔티티의 생성 및 수정 시간을 자동으로 관리해주는 기능
- 개발자는 엔티티가 언제 생성되고 수정되었는지를 자동으로 추적
JPA Auditing 적용예시
@MappedSuperclass
public class BaseEntity{
@Column(updatable = false)
private LocalDateTime createdAt;
private LocalDateTime updatedAt;
@PrePersist
public void prePersist(){
LocalDateTime now = LocalDateTime.now();
created_at = now;
updated_at = now;
}
@PreUpdate
public void preUpdate() {
updated_at = LocalDateTime.now();
}
}Spring Data JPA Auditing
적용예시 1
@EnableJpaAuditing // JPA Auditing 기능을 활성화
@SpringBootApplication
public class SpringDataJpaApplication {
public static void main(String[] args) {
SpringApplication.run(SpringDataJpaApplication.class, args);
}
}- 일반적으로 Spring Boot를 실행하는 Application 클래스 상단에 선언
적용예시 2
@Getter
@MappedSuperclass // 해당 어노테이션이 선언된 클래스를 상속받는 Entity에 공통 매핑 정보를 제공
@EntityListeners(AuditingEntityListener.class) // Entity를 DB에 적용하기 전, 커스텀 콜백을 요청할 수 있는 어노테이션
public abstract class BaseEntity {
@CreatedDate // 생성 시점의 날짜를 자동으로 기록
@Column(updatable = false)
@Temporal(TemporalType.TIMESTAMP) // 날짜 타입을 세부적으로 지정
private LocalDateTime createdAt;
@LastModifiedDate // 수정 시점의 날짜를 자동으로 기록
@Temporal(TemporalType.TIMESTAMP)
private LocalDateTime modifiedAt;
}@EntityListeners(AuditingEntityListener.class)
- Auditing 기능을 사용할 수 있도록 Listener를 설정
- 내부적으로
@PrePersist을 사용
느낀 점
확실히 배우면 배울수록 재밌는 것 같다. 이 바닥 희로애락이 다 담겨있어서 나쁘지 않네요. 직업으로 삼기에 내일은 필수 마무리 짓고 도전 조금 맛만 보겠습니다. 아 맞다 오늘 zep에서 오토바이 한대 뽑았습니다. 포인트 열심히 모아서~
소확행이네요ㅎㅎ 😁 차 여러 대 뽑으려면 포인트 많이 모아야겠습니다. 화이팅!
