
#2에서 다룰 데이터
- 상권 데이터 : 상가의 종류, 위치, 분류 코드
- 유동인구 데이터 : 서울의 시간, 연령대 별 유동인구 수 데이터
데이터 분석의 4단계
1) 데이터 불러오기
import pandas as pd
commercial = pd.read_csv('./data/commercial.csv')
commercial2) 데이터 살펴보기
commercial.tail(5)컬럼 살펴보기(불러온 데이터들이 어떤 컬럼을 가지고 있는지 확인)
list(commercial)
살펴볼 컬럼 정하기
- 상가업소번호 : 가게가 중복이 되는지 확인
(상가업소번호로 그룹을 묶은 후 각 상가업소번호 당 상권업종소분류명으로 분류해 중복이 되는게 있는지 확임. 만약 한개의 상가업소번호를 여러 분류가 동시에 사용한다면 상가업소번호로 상가의 개수를 세기가 어려움.
데이터의 라인수 : 573680개, 상가번호 수 : 573680개)commercial.groupby('상가업소번호')['상권업종소분류명'].count().sort_values(ascending=False)
- 상권업종소분류명 : 치킨집을 분류하기 위한 이름
category_range = set(commercial['상권업종소분류명']) print(category_range, len(category_range))
- 도로명주소 : 치킨집의 위치를 파악하기 위해 필요
commercial['도로명주소']
3) 데이터 가공하기
도로명 잘라 정리해보기
- 구 별로 데이터를 분석하기 위해 한 덩어리인 도로명 주소를 시, 군, 나머지로 잘라줌.
commercial[['시', '구', '상세주소']] = commercial['도로명주소'].str.split(' ', n=2, expand=True) # 도로명주소 칼럼에 해당하는 내용을 split이라는 함수로 쪼개줌. # 문자열은 내부적으로 str이라는 클래스 타입. # str.split() : 특정 구분자를 기준으로 문자열을 분리하여 리스트를 리턴함. 위의 식은 띄어쓰기를 기준으로 분리하며, 2번만 분리하고, expand = True면 pandas의 데이터 타입으로 표현함. False면 series 타입으로 표현함 # df[['새 칼럼1', '새 칼럼2']]=df['분할대상칼럼'].str.split('구분기호', n=1, expand=True) commercial.tail(5)
참고) expand = True, False 차이

서울시 데이터만 남기기
- 서울 특별시 데이터만 필요하니 서울 특별시에 해당하는 데이터만 추출
seoul_data = commercial[commercial['시']=='서울특별시'] seoul_data.tail(5)
정말 서울특별시에 해당하는 데이터만 남았는지 set으로 확인해보기(set은 중복되는 데이터는 안나오는 데이터 형식이니까)city_type = set(seoul_data['시']) print(city_type, len(city_type)) # {'서울특별시'} 1참고) pandas DataFrame 타입이 지원하는 기능으로, DataFrame 타입 변수에 [‘컬럼명‘] 을 붙이면 특정 컬럼만 가져올 수 있다.
ex)commercial['시']
그리고 전체 행의 수와 같은 True 와 False 로 이루어진 리스트, Series, 튜플 등과 같은 Collection 자료구조를 넣으면 True 에 해당하는 행만 남기고 False 에 해당하는 줄의 데이터는 제거할 수 있다.
commercial['시'] == '서울특별시'는 commercial 의 '시' 컬럼에서 각 줄을 볼 때 '서울특별시' 인 경우 True, 아닌 경우 False 를 저장하는 결과가 나온다. 그래서 이 두가지를 이용해seoul_data = commercial[commercial['시'] == '서울특별시']는 commercial 에서 '시' 컬렴이 '서울특별시' 인 줄만 남겨 seoul_data 변수에 저장하겠다는 의미가 됩니다.
치킨집 데이터만 남기기
- 후라이드/양념치킨 데이터만 남겨보자
seoul_chicken_data = seoul_data[seoul_data['상권업종소분류명']=='후라이드/양념치킨'] seoul_chicken_data.tail(5)
구 별로 정리하기
groupdata = seoul_chicken_data.groupby('구') # '구'를 기준으로 그룹으로 묶고 group_by_category = groupdata['상권업종소분류명'] # 그중에서 '상권업종소분류명'만 추출해서 chicken_count_gu = group_by_category.count() # 개수를 센다 sorted_chicken_count_gu = chicken_count_gu.sort_values(ascending=False) # 내림차순으로 정렬 sorted_chicken_count_gu

4) 데이터 시각화
바 그래프 그리기
import matplotlib.pyplot as plt
# Apple은 'AppleGothic', Windows는 'Malgun Gothic'
plt.rcParams['font.family'] = "Malgun Gothic"
plt.figure(figsize= (10,5)) # 그래프의 사이즈
plt.bar(sorted_chicken_count_gu.index, sorted_chicken_count_gu)
plt.title('구에 따른 치킨가게 수의 합계') # 그래프의 제목
plt.xticks(rotation=90)
plt.show() # 그래프 그리기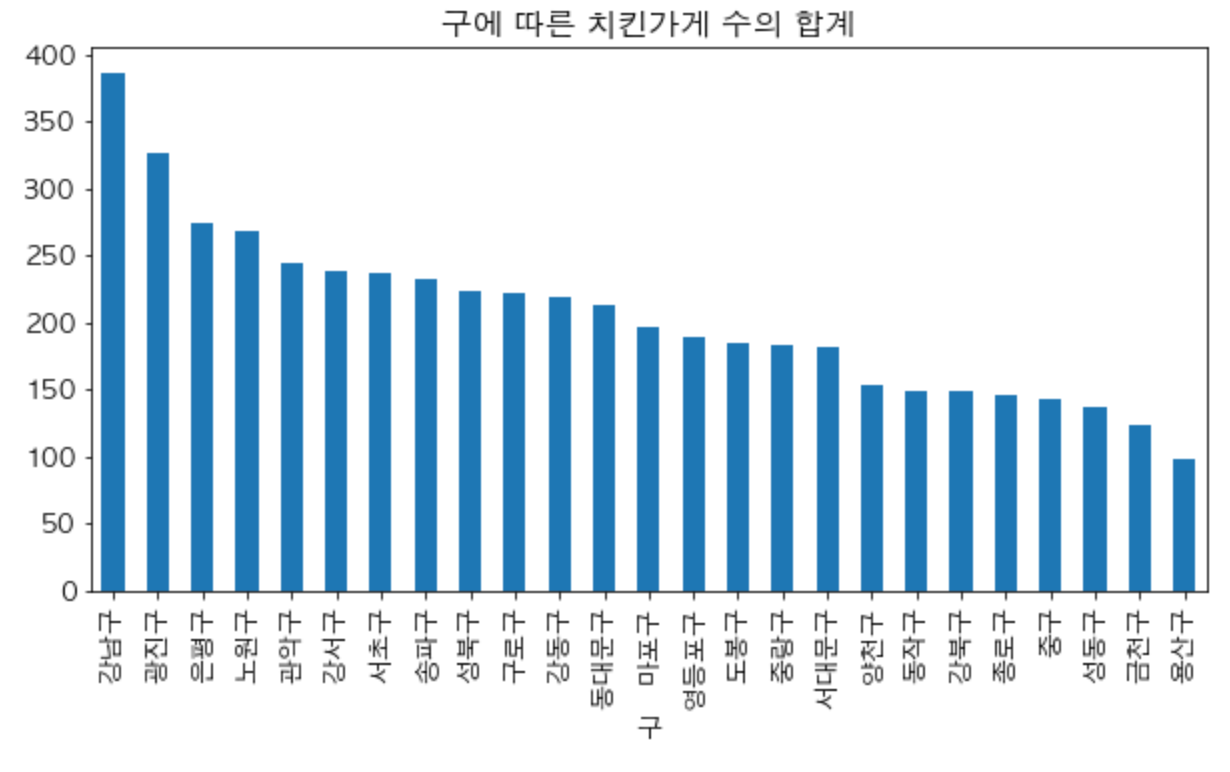
지도에 표현하기
folium 설치하기(복붙해서 설치하면 됨)
conda install -c conda-forge folium데이터 바인딩 : 원본 데이터와 화면에 나타나는 UI가 있다면 서로를 연결해서 원본 데이터가 바뀌면 UI 도 바뀌게 하는 것. 반대로 UI가 바껴도 원본 데이터가 바뀌게 하는 것.
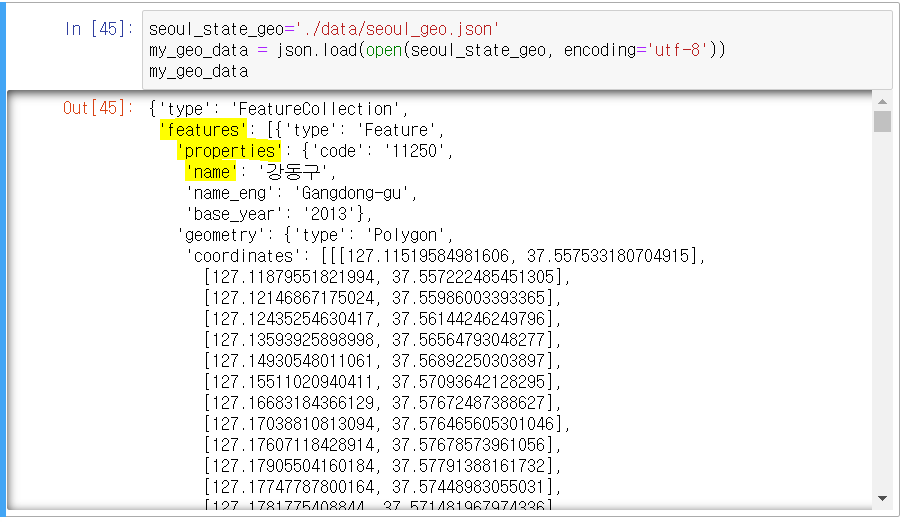
#라이브러리 가져오기 import folium import jsonseoul_state_geo = './data/seoul_geo.json' #seoul_geo.json은 json 형식의 각 구별 위도, 경도 데이터 my_geo_data = json.load(open(seoul_state_geo, encoding='utf-8')) #json을 load하는데 open해라! seoul_state_geo데이터를 encoding='utf-8'방법으로
map = folium.Map(location=[37.5502, 126.982], zoom_start=10) #서울 위도, 경도 folium.Choropleth(geo_data=my_geo_data, #geo_data = 지리데이터 or 파일 경로 data=chicken_count_gu, #data : GeoJson에 바인딩할 데이터, ***chicken_count_gu의 index와 key_on의 name에 있는 지역 이름이 반드시 같아야함. 지금은 chicken_count_gu의 index가 '구'인데 만약에 아니라면 앞에서 chicken_count_gu=chicken_count_gu.set_index['구']를 해줘야함. columns=[chicken_count_gu.index, chicken_count_gu], #columns : 데이터가 pandas dataframe일 경우 바인딩할 데이터의 칼럼. 1열에는 키값, 2열에는 그 값을 넣어줘야함. fill_color='PuRd', key_on='feature.properties.name').add_to(map) #key_on : 바인딩할 geo_data 파일의 변수. feature로 시작해야함. 근데 여기선 그냥 properties.name해도 나옴 map
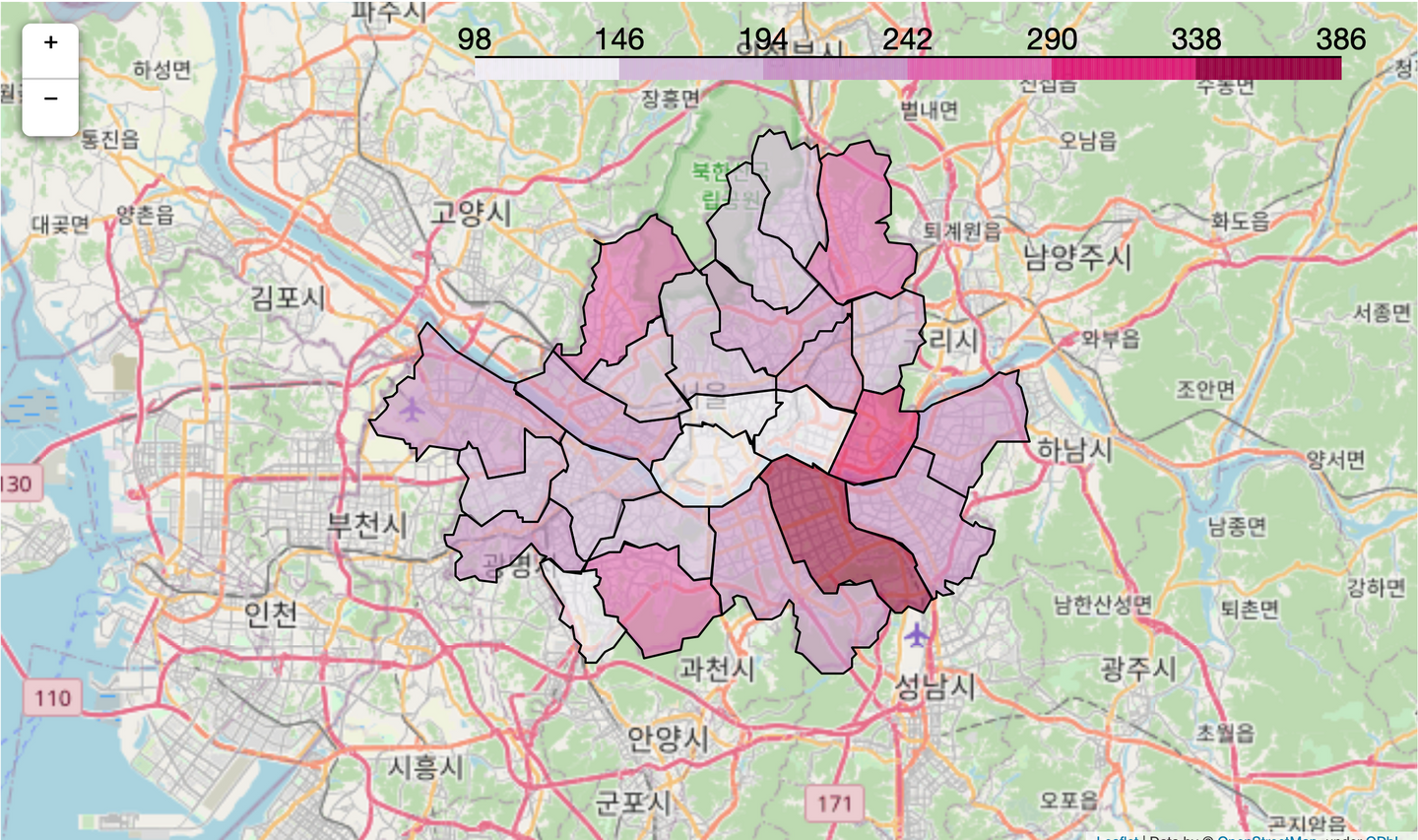
다른 그래프 사용 예시
강남구의 일별 유동량
population_gangnam = population[population['군구']=='강남구'] population_gangnam_daily = population_gangnam.groupby('일자')['유동인구수'].sum() population_gangnam_daily

선 그래프 → plt.plot
# 날짜를 string 타입으로 변경해야 숫자로 인식하지 않아 값이 줄여지지 않음. 여기에서 plt.plot(date ~~) 대신 plt.plot(population_gangnam_daily.index, ~~)를 사용하면 x축 값이 숫자로 인식해서 이상하게 줄여져서 나옴.plt.figure(figsize=(12, 5))date = [] for day in population_gangnam_daily.index: date.append(str(day)) #day를 문자열로 date에 넣어줄거임.plt.plot(date, population_gangnam_daily) plt.title('2020년 7월 서울 강남구 날짜별 유동인구 수') plt.xlabel('날짜') plt.ylabel('유동인구 수(천만명)') plt.xticks(rotation=-90) plt.show()
지도 그래프 한번 더! 대신
tiles='stamentoner'사용#라이브러리 가져오기 import folium import json# 지도 만들어주기 map = folium.Map(location=[37.5502, 126.982], zoom_start=11, tiles='stamentoner')
folium.Map은 설정값을 넣어주어야 함.- 위도경도를 나타내주는,
location- 지도의 초기 확대 정도를 나타내주는
zoom_starttiles='stamentoner'옵션값은 지도의 길과 강 위주로 보여줌.# https://raw.githubusercontent.com/southkorea/seoul-maps/master/kostat/2013/json/seoul_municipalities_geo_simple.json seoul_state_geo = './data/seoul_geo.json' my_geo_data = json.load(open(seoul_state_geo, encoding='utf-8')) folium.Choropleth(geo_data=my_geo_data, data=sum_of_population_by_gu, columns=[sum_of_population_by_gu.index, sum_of_population_by_gu], fill_color='PuRd', key_on='feature.properties.name').add_to(map) map
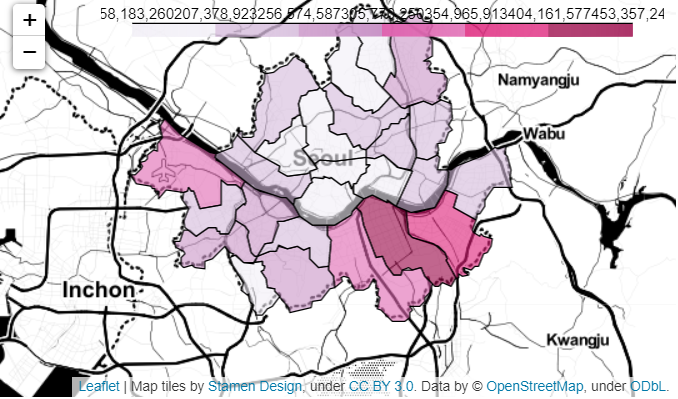
데이터 합치기
구 이름을 기준으로 정렬했던 데이터를 새로운 데이터 프레임에 넣어서 만듬
new_chicken_count_gu = pd.DataFrame(chicken_count_gu).reset_index() new_chicken_count_gunew_sum_of_population_by_gu = pd.DataFrame(sum_of_population_by_gu).reset_index() new_sum_of_population_by_gu
join을 사용해서 합쳐줌gu_chicken = new_chicken_count_gu.join(new_sum_of_population_by_gu.set_index('군구'), on='구') gu_chicken
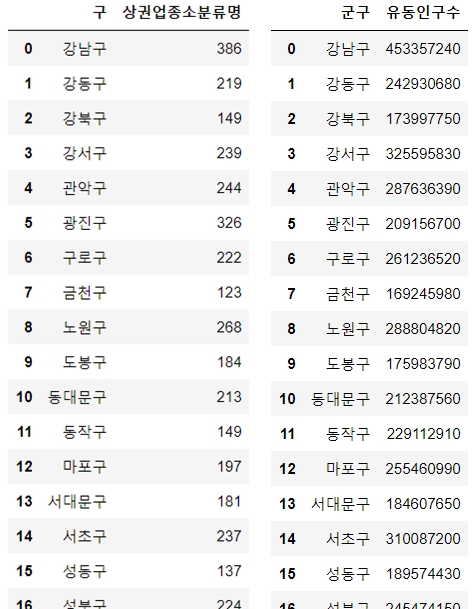
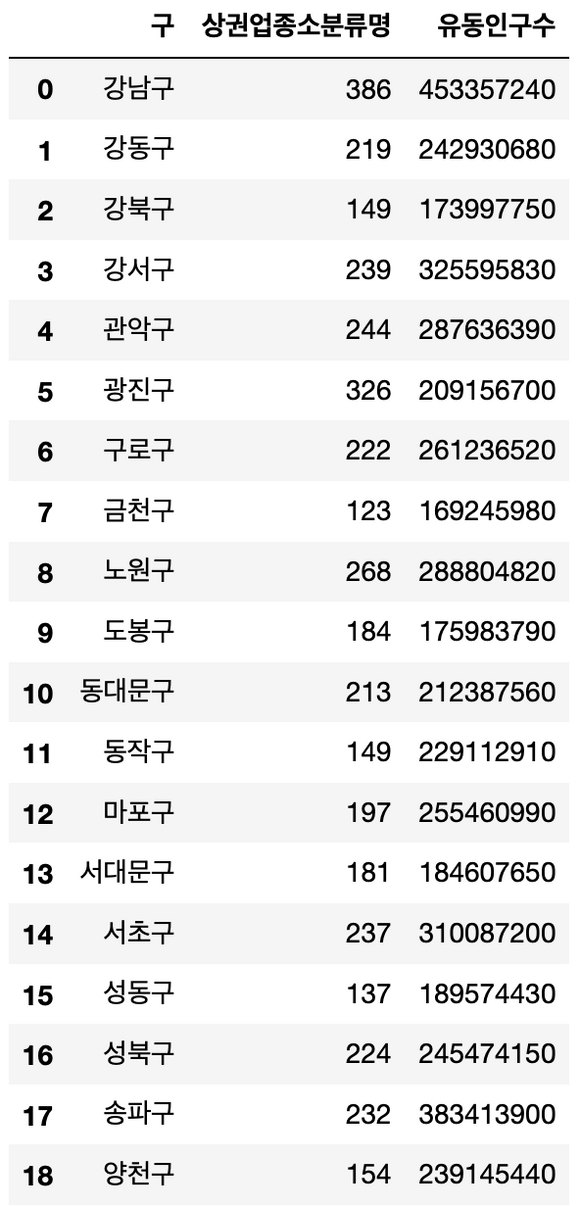
치킨집 당 유동인구수 구하기
gu_chicken['유동인구수/치킨집수'] = gu_chicken['유동인구수']/gu_chicken['상권업종소분류명']
gu_chicken = gu_chicken.sort_values(by='유동인구수/치킨집수')
gu_chicken그래프 그려서 확인하기
plt.figure(figsize=(10,5))
plt.bar(gu_chicken['구'], gu_chicken['유동인구수/치킨집수'])
plt.xlabel('구')
plt.ylabel('유동인구수/치킨집수')
plt.xticks(rotation=90)
plt.show()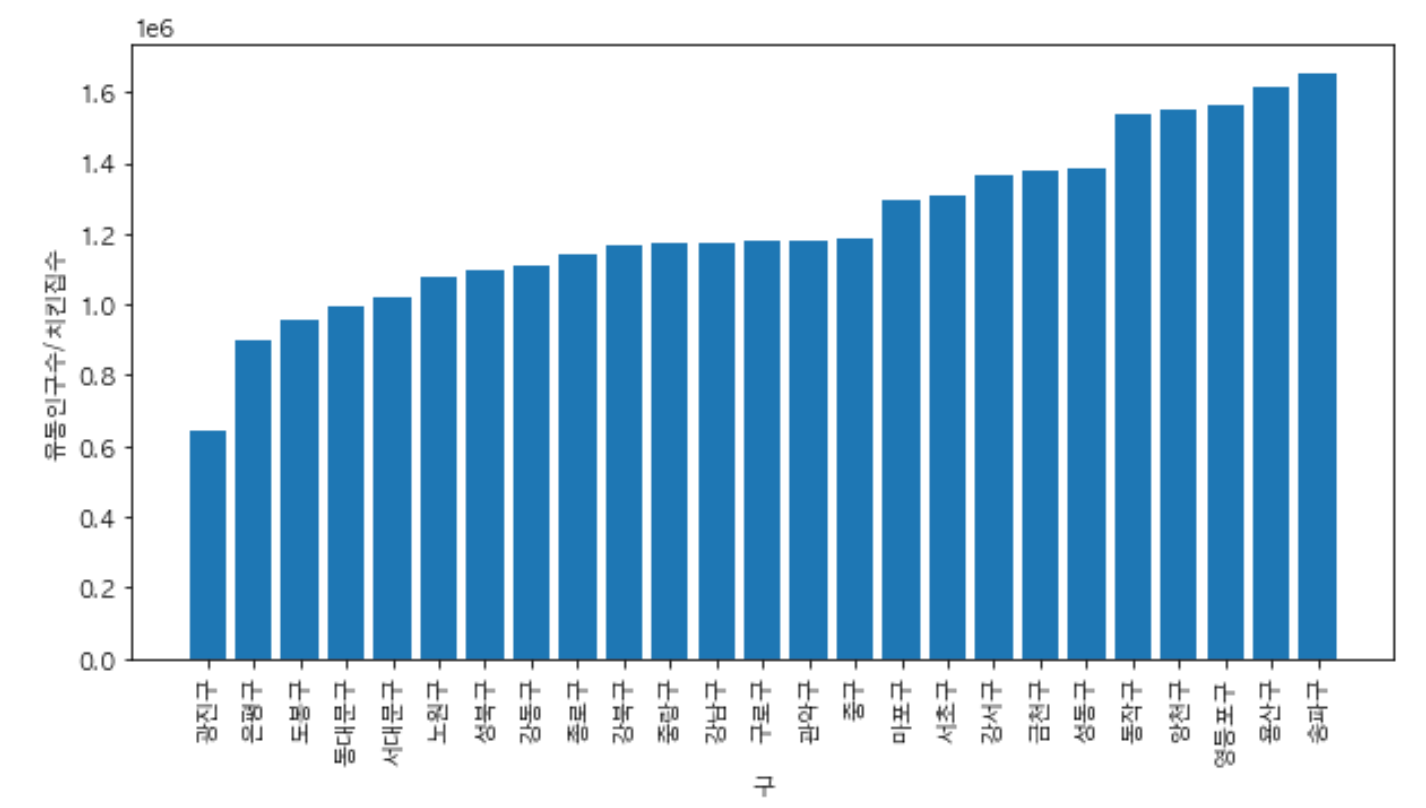
그래프 두개 붙이기
아래 예시처럼 그냥 한 번 더 써주면 됨.
date=[]
for day in sum_of_population04_gangnamgu.index:
date.append(str(day))
plt.figure(figsize=(20,5))
plt.plot(date, sum_of_population04_gangnamgu)
date2=[]
for day in sum_of_population07_gangnamgu.index:
date2.append(str(day))
plt.plot(date2, sum_of_population07_gangnamgu)
plt.title('4월과 7월의 일별 유동인구 수')
plt.xticks(rotation=-90)
plt.show