주식 데이터 분석하기
[1] 주식 데이터 전처리 하기
코드 데이터 불러오기
import pandas as pd
code = pd.read_csv('./data/corpgeneral.csv')
code참고) 온라인에서 최신코드 가져오기(최신 정보가 계속 업데이트 되므로)
import pandas as pd code = pd.read_html('http://kind.krx.co.kr/corpgeneral/corpList.do?method=download', header=0)[0] code.head(5)
필요한 데이터 자르기
code = code[['회사명', '종목코드']]
code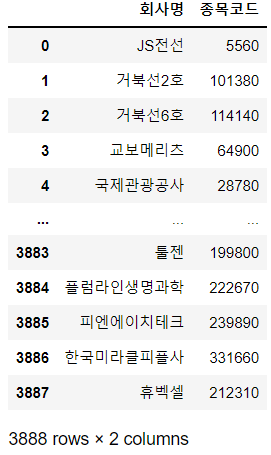
컬럼명 바꾸기
# 코딩할 때 한글 있으면 불편하니까 칼럼명을 영어로 바꿔줌.
code_result = code.rename(columns={'회사명': 'corp', '종목코드': 'code'})
code_result[2] 주식데이터 종가 그래프 그리기
종목 이름으로 원하는 종목 코드 가져오기
(이해 안되도 일단 그냥 따라하자)
corp_name = "카카오"
condition = "corp=='{}'".format(corp_name)
kakao = code_result.query(condition)
kakao = kakao['code']
kakao_string = kakao.to_string(index=False) #위에있는 'code' index 없이 가져오려고 index=False 하는거임.
kakao_string = kakao_string.strip() #문자 앞에 공백을 지워줄 때 쓰는 함수. 공백 없으면 안써도 됨.
kakao_string = kakao_string.rjust(6, '0') #kakao_string 값은 35720으로 나옴. code(종목코드)는 6자리 이므로 6자리로 바꾸고 공백은 0으로 채워줌.
kakao_code = kakao_string
kakao_code
#결과값 : '035720'종목 코드로 종목 데이터 가져오기
#라이브러리 설치
conda install -c anaconda pandas-datareaderimport pandas_datareader.data as web #코드를 통해 데이터를 가져오는 라이브러리를 불러옴.
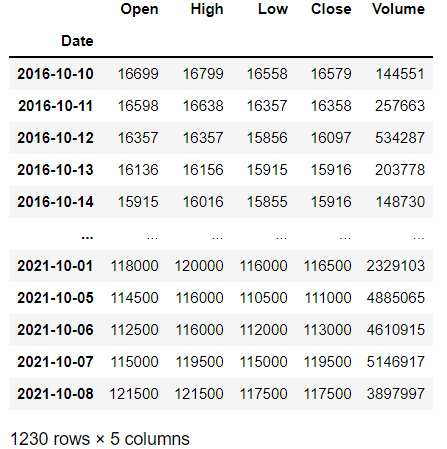
kakao_stock_df = web.DataReader(kakao_code, 'naver') #네이버에서 주식 데이터 가져올 것임.
kakao_stock_dfHigh: 최고가 / Low: 최저가 / Open: 시작가 / Close: 종가
종가 그래프 그리기
kakao_stock_df['Close'] #종가 데이터를 가지고 그래프를 그려야 하기 때문에 Close 칼럼을 씀
#이 데이터가 문자열이므로 숫자로 바꿔줘야함.
kakao_stock_df['Close'] = kakao_stock_df['Close'].astype(int)
kakao_stock_df['Close']
kakao_stock_df['Close'].plot()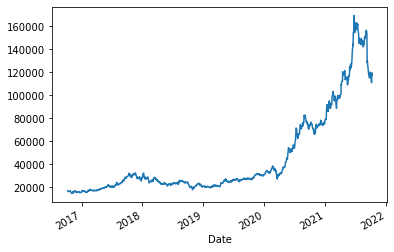
[3] 주식 데이터 상관관계란?
상관 분석이란?
두 데이터가 어느정도의 상관 관계를 가지고 있는지 분석함.
- 상관 계수는 1부터 -1까지 존재
- 기울기가 1이면 매우 강한 상관 관계
- 0이면 상관 관계를 찾을 수 없음.
- '보통은 0.6 ~ 0.4 사이의 값을 가지면 상관 관계가 있다'로 판단함.
[4] 주식 데이터 준비하기
라이브러리 불러오기
import pandas as pd
import pandas_datareader.data as web
from datetime import datetime주식 데이터 받아오기
code = pd.read_csv('./data/corpgeneral.csv', header=0)
code = code[['회사명', '종목코드']]
code_result = code.rename(columns={'회사명':'corp', '종목코드':'code'})
code_result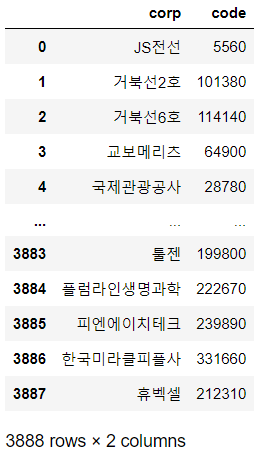
코드를 받아오는 함수 만들기
#이름만 입력하면 코드를 뱉어내는 녀석을 만들거임
def get_code(code_result, corp_name): #사용자 정의 함수로 get_code를 만드는 것. get_code(a, b)의 형태로 여기서 b의 값을 내가 정의해 주지 않아서 입력을 받아 사용하는 것.
condition = "corp=='{}'".format(corp_name) #계속 반복되는 코드를 함수로 묶어서 편하게 보겠다. #{}는 format 함수 때문에 들어간것임. 즉, "corp == corp_name"이 condition에 들어감.
code = code_result.query(condition)['code'].to_string(index=False) #code_result에서 쿼리를 날린다. 근데 condition이라는 조건("corp == corp_name")인 code_result 값을 가져옴. 그 결과를 문자로 바꿔줘라.
code = code.strip()
code = code.rjust(6,'0')
return code
#code_result와 기업 이름이 들어와서 코드를 돌고 마지막에 코드를 반환함.samsung_code = get_code(code_result, "삼성전자")
samsung_code참고) query() 사용팁.
df.query('A==b') 또는 ttt = "A == b" df.query(ttt)
[5] 주식 데이터 상관관계 분석
companies = ['삼성전자', 'LG전자', '카카오', 'NAVER', 'CJ', '한화', '현대자동차', '기아자동차']
companies
start = datetime(2020,1,1) #날짜를 만들어준다
end = datetime(2020,12,31)
stock_of_companies = pd.DataFrame({'Date':pd.date_range(start=start, end=end)}) #데이타를 만들어줌.
stock_of_companies
#여러기업들의 데이터를 이 날짜에 붙여서 만들거임.
#각 기업들 마다 돌려야 하니까 for문 사용
for company in companies:
company_code = get_code(code_result, company)
stock_df = web.DataReader(company_code,'naver',start,end) #company_code에서 나오는 코드를 가지고 데이터를 불러와야함. 어디서 가져오냐? → 네이버에서
stock_of_companies = stock_of_companies.join(pd.DataFrame(stock_df['Close'].astype(int)).rename(columns={'Close': company}), on='Date')
#가져온 데이터를 위에서 만든 stock_of_companies에 붙여야함. stock_df['Close'] : 종가 데이터stock_of_companies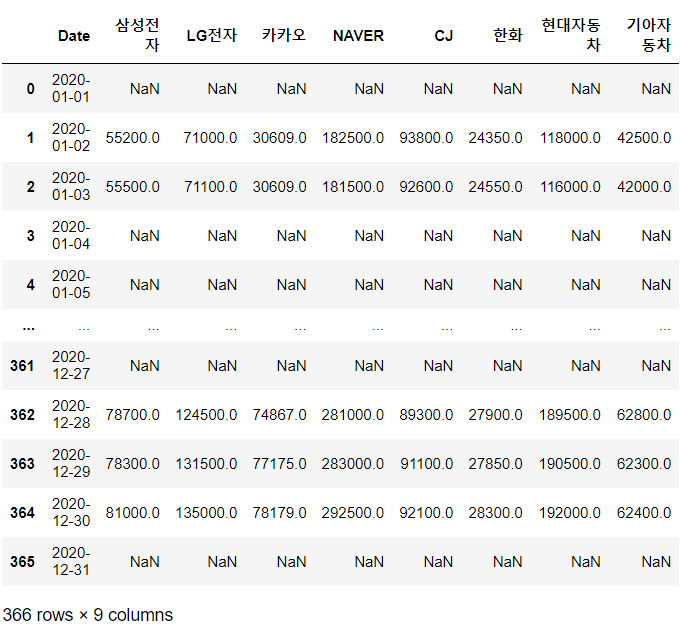
#corr() 함수 : 열간에 계산된 상관관계가 있는 Datafrmae을 반환함.
corr_data = stock_of_companies.corr()
corr_data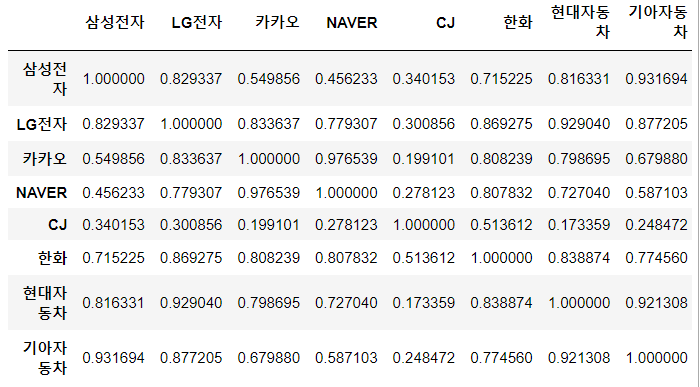
[6] 주식 데이터 그래프 그리기
seaborn라이브러리 설치
conda install -c anaconda seaborn라이브러리 불러오기
import matplotlib.pyplot as plt
import seaborn as sns
# Apple은 'AppleGothic', Windows는 'Malgun Gothic'을 추천
plt.rcParams['font.family'] = "Malgun Gothic"
plt.rcParams['axes.unicode_minus'] = False
#unicode_minus를 꺼준다. = 그래프를 그릴 때 마이너스 기호가 붙을 때 화면에서 깨지는걸 막아줌.seaborn으로 그래프를 그리기
plt.figure(figsize=(5,3)) #seaborn으로 그리는 데 matplotlib를 쓰는 이유: 그래프를 그릴 때 → seaborn, 그림을 그릴 도화지는 matplotlib
sns.lineplot(data=kakao_stock_df['Close'])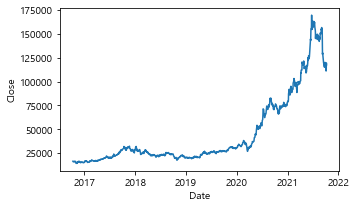
상관관계 그래프 그리기
#상관관계를 보여주는 히트맵
plt.figure(figsize=(10,10))
sns.heatmap(data= corr_data, annot=True, fmt='.2f', linewidths=.5, cmap='Blues') #annotation(주석): 각 칸위에 숫자를 넣을거냐, fmt(formatting): 문자열 서식 코드, cmap: color map
plt.show()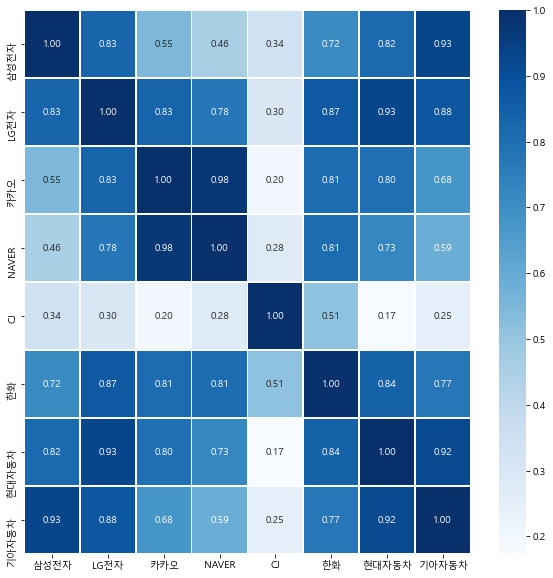
[7] 데이터 스튜디오 준비하기
구글 데이터 스튜디오
파이썬으로 보고서를 만들 수 있고 그래프도 그릴 수 있다. 하지만 공유하기 쉽지 않다. 또 언제 축 이름과 사이즈 색깔 지정하고 있나? 그래서 데이터만 있으면 그래프를 만들어서 공유할 수 있도록 도와주는 도구.
데이터 전처리를 한 후 파이썬으로 그래프 그려보고 잘 나오면 데이터 스튜디오 활용해서 공유.
https://datastudio.google.com/u/0/navigation/reporting
빈 보고서 → 파일 업로드 → CSV파일 업로드
사용할 csv 파일 없으면 아래 코드 실행하고 사용
import pandas as pd
import pandas_datareader.data as web
from datetime import datetime
code = pd.read_csv('./data/corpgeneral.csv', header=0)
code = code[['회사명', '종목코드']]
# 컬럼명 바꾸기
code_result = code.rename(columns={'회사명': 'corp', '종목코드': 'code'})
# 종목 코드 6자리만들기
code_result.code = code_result.code.map('{:06d}'.format)
def get_code(code_result, corp_name):
condition = "corp=='{}'".format(corp_name)
code = code_result.query(condition)['code'].to_string(index=False)
# 위와같이 code명을 가져오면 앞에 공백이 붙어있는 상황이 발생하여 앞뒤로 sript() 하여 공백 제거
code = code.strip()
code = code.rjust(6, '0')
return code
companies = ['삼성전자', 'LG전자', '카카오', 'NAVER', 'CJ', '한화', '현대자동차', '기아자동차']
start = datetime(2019,1,1)
end = datetime(2020,9,10)
stocks_of_companies = pd.DataFrame({'Date': pd.date_range(start=start, end=end)})
for company in companies:
company_code = get_code(code_result, company)
stock_df = web.DataReader(company_code, 'naver', start, end)
stocks_of_companies = stocks_of_companies.join(pd.DataFrame(stock_df['Close'].astype(int)).rename(columns={'Close':company}), on='Date')
stocks_of_companies.dropna()
stocks_of_companies.to_csv('./stock_change.csv',sep=',', na_rep='NaN',index = False)데이터스튜디오 그래프 그리기
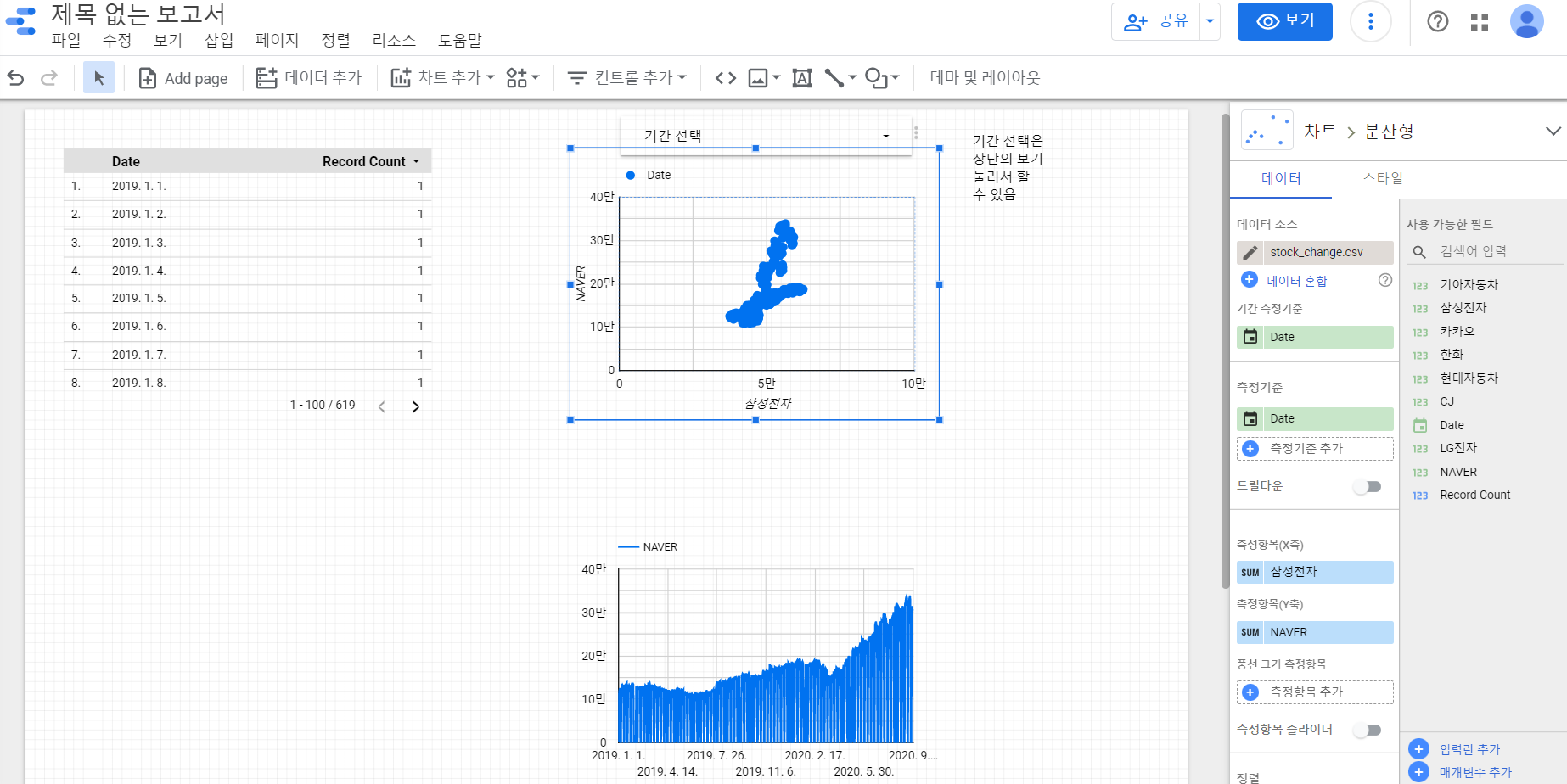
참고) pandas DataFrame(), date_range()
DataFrame()
https://www.geeksforgeeks.org/different-ways-to-create-pandas-dataframe/
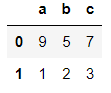
기본yu = pd.DataFrame([[9,5,7],[1,2,3]], columns=['a','b','c']) yu
변형
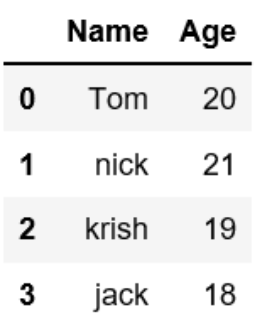
DataFrame에 넣을 데이터의 column(열)을 하나의 열에 새로 형태로 넣으려면#'칼럼명':[내가 넣을 데이터] 이 형식으로 데이터를 만들어줌. data = {'Name':['Tom', 'nick', 'krish', 'jack'], 'Age':[20, 21, 19, 18]} df = pd.DataFrame(data)
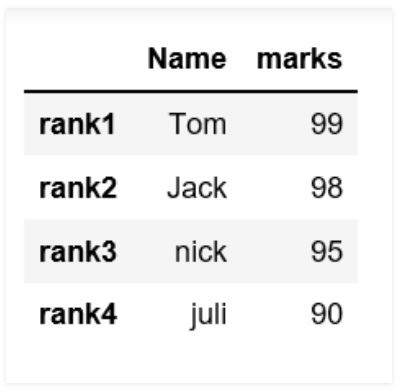
index를 바꾸려면data = {'Name':['Tom', 'Jack', 'nick', 'juli'], 'marks':[99, 98, 95, 90]} # Creates pandas DataFrame. df = pd.DataFrame(data, index =['rank1', 'rank2', 'rank3', 'rank4'])
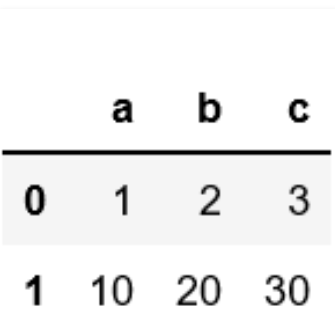
딕셔너리형data = [{'a': 1, 'b': 2, 'c':3}, {'a':10, 'b': 20, 'c': 30}] # Creates DataFrame. df = pd.DataFrame(data)
date_range()
https://pandas.pydata.org/docs/reference/api/pandas.date_range.htmlpd.date_range(start='1/1/2018', end='1/08/2018') → DatetimeIndex(['2018-01-01', '2018-01-02', '2018-01-03', '2018-01-04', '2018-01-05', '2018-01-06', '2018-01-07', '2018-01-08'], dtype='datetime64[ns]', freq='D')pd.date_range(start='1/1/2018', periods=8) → DatetimeIndex(['2018-01-01', '2018-01-02', '2018-01-03', '2018-01-04', '2018-01-05', '2018-01-06', '2018-01-07', '2018-01-08'], dtype='datetime64[ns]', freq='D')pd.date_range(start='2018-04-24', end='2018-04-27', periods=3) → DatetimeIndex(['2018-04-24 00:00:00', '2018-04-25 12:00:00', '2018-04-27 00:00:00'], dtype='datetime64[ns]', freq=None)