
1. 프로젝트 소개
- 데일리호텔을 모티브로한 프로젝트
- 개발기간 : 2021/8/17 ~ 2021/8/27
- 개발인원 : 프론트엔드 3명, 백엔드 2명
- 깃헙 주소 : https://github.com/wecode-bootcamp-korea/23-2nd-MAEILYHOTEL-backend
- 영상 시연 : https://www.youtube.com/watch?v=qDQXFb2oayE
- 내가 담당한 기능
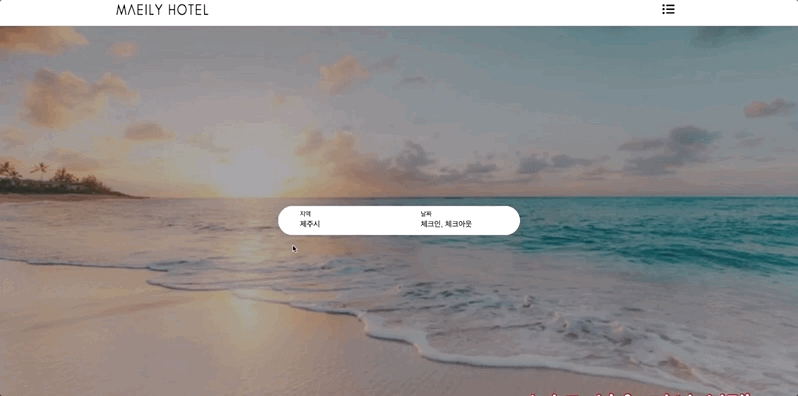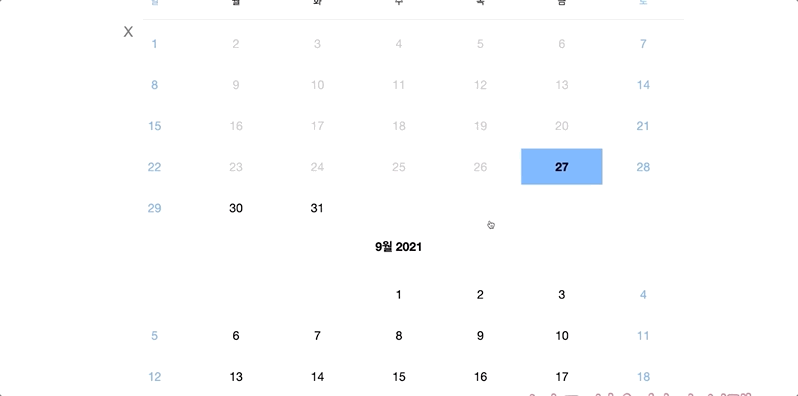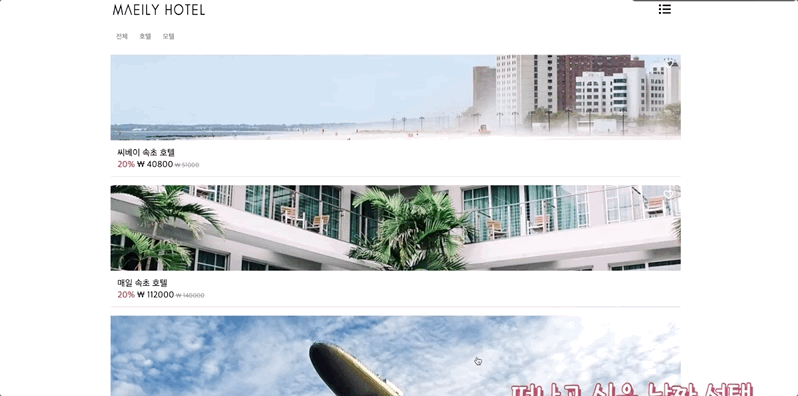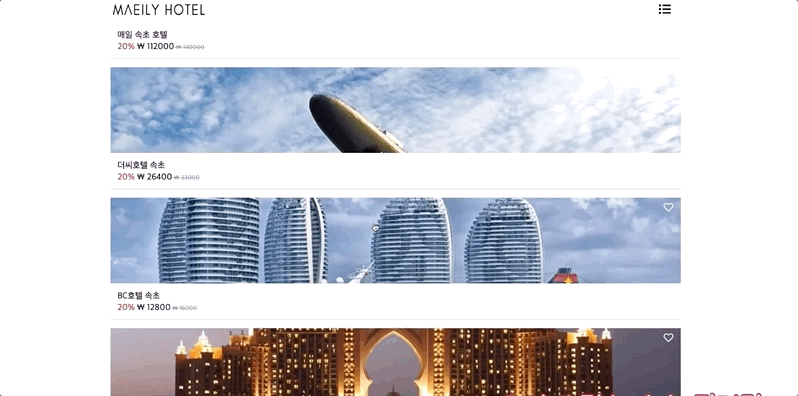
- 숙소 지역별, 날짜별 검색 조회 기능
- 숙소 종류별 조회 기능
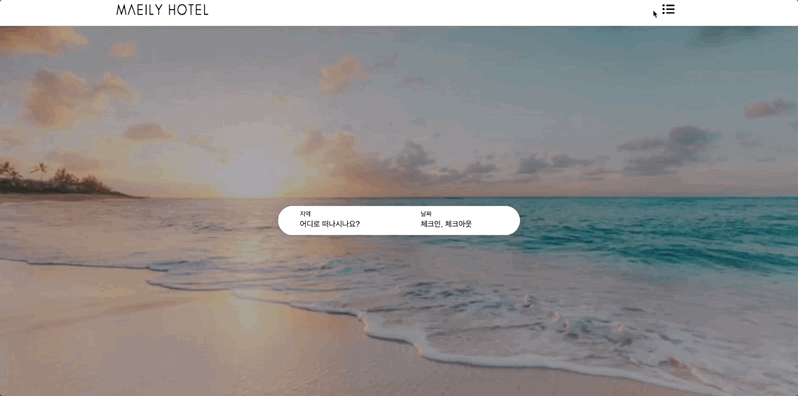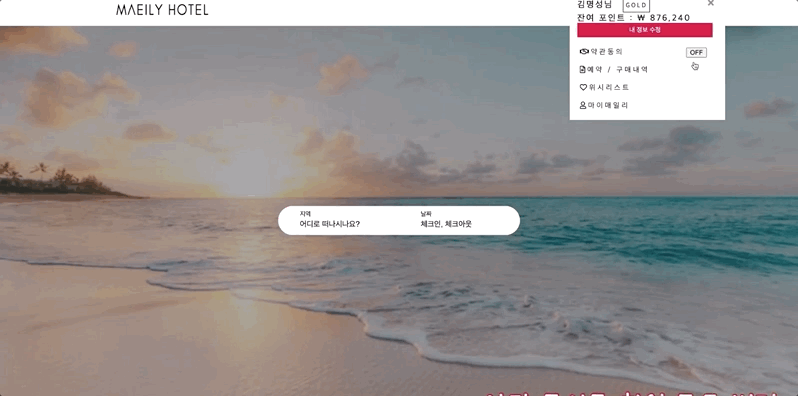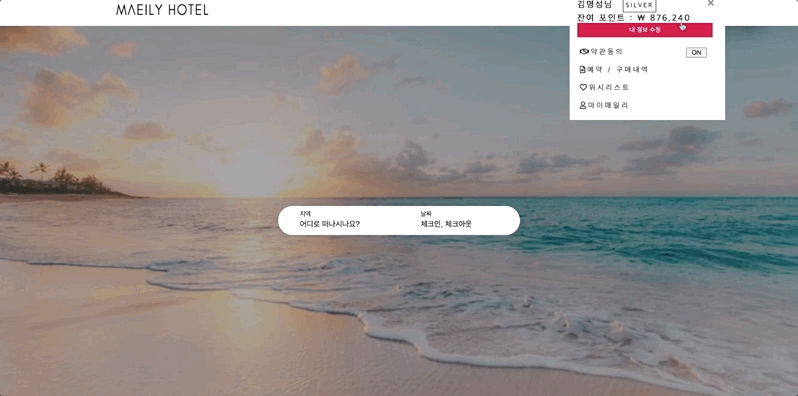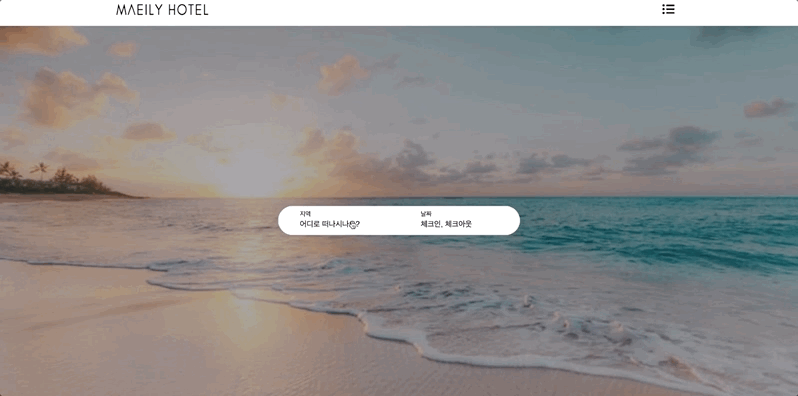
- 회원등급 변경 기능
- 리뷰 생성 기능
숙소 지역별, 날짜별 검색 조회 기능
숙소 종류별 조회 기능

회원등급 변경 기능
리뷰 생성 기능

2. 가치있는 코드
1차 프로젝트 때에 다뤄보지 못한 Q객체를 사용해보고자 숙소를 조건별로 필터링하여 조회하는 기능을 맡았다. 필터링 조건은 아래 3가지이고 쿼리 파라미터로 request 받기로 하였다.
1. 지역별
2. 날짜별 (체크인, 체크아웃)
3. 숙소 종류별
2-1 모델링
# stays.models.py
# 숙소
class Staytype(models.Model):
category = models.ForeignKey('Category', on_delete = models.PROTECT)
name = models.CharField(max_length = 45)
# 객실
class Room(models.Model):
staytype = models.ForeignKey('Staytype', on_delete = models.PROTECT)
name = models.CharField(max_length = 45)
quantity = models.IntegerField()
# books.models.py
# 예약
class Book(TimeStampModel):
user = models.ForeignKey('users.User', on_delete = models.CASCADE)
room = models.ForeignKey('stays.Room', on_delete = models.CASCADE)
room_option = models.ForeignKey('stays.RoomOption', on_delete = models.CASCADE)
check_in = models.DateField()
check_out = models.DateField()
데일리호텔은 숙소 플랫폼이기 때문에 객실 호수별 재고 관리를 하지 않는다고 생각했다. 모델링을 할 때 Room객체는 객실의 종류(예. 스위트룸, 디럭스룸) 이며 quantity 필드에 각 객실별 총 개수를 담기로 했다. 데일리호텔의 이러한 특징들이 날짜별 필터링을 할 때 가장 까다롭게 작용했다.
2-2 여러 시행착오들
예)
Room qunatity = 5
input_check_in = 8/1
input_check_out = 8/4
그리고 Book 객체의 room 1번은 아래와 같이 예약되어 있다.

첫번째 접근
Book.objects.filter(check_in = input_check_in, check_out__gte = input_check_out)이 경우에는 Book 3,4번의 경우가 누락된다.
두번째 접근
결과적으로 Staytype 객체가 조회되어야 하므로, 날짜별 객실 재고관리를 해야한다는 방향으로 나아갔다. 요청받은 체크인과 체크아웃 날짜, 그 사이의 날짜들을 리스트화 한다. for문을 이용해 각각의 날짜가 Book의 체크인 체크아웃 사이에 속하는지 체크한다.
이 방법으로 날짜별 숙소의 객실 재고를 파악하여 아래와 같이 딕셔너리 형태로 만들었다. 하지만 이 중 예약 가능한 숙소를 거르는 작업에서 막혔다. value는 리스트 형태로 되어있고, 리스트의 길이가 저마다 다르다. 또한 요청받은 체크인, 아웃 날짜에 상관없이 객실 재고를 파악하는 for문을 사용하는 것이 비효율적이라는 생각이 들었다.
{
"8/1" : [{"staytype_id" :1, "quantity" : 2},
{"staytype_id" :2, "quantity" : 4}],
"8/2" : [{"staytype_id" :1, "quantity" : 2},
{"staytype_id" :3, "quantity" : 3},
{"staytype_id" :4, "quantity" : 3}]
}여기까지 도달하는데 며칠이 걸렸지만, 어떤 식으로 접근하는 것이 맞는지 뚜렷하지 않았다. 또한 맘속으로 정한 코드 완성기간이 이미 지나버렸다. 팀 프로젝트이고 기간이 한정되어 있기 때문에 이 부분을 멘토분의 조언을 받더라도 얼른 해결을 해야겠다는 생각이 들었다. 우선 데일리 미팅때 팀원들에게 날짜별 필터링이 Bloker이고 해결 가능성을 퍼센티지화 하여 공유하였다.
q1 = Q(room__book__check_in__range = [check_in, check_out])
q2 = Q(room__book__check_out__range = [check_in, check_out])
q3 = Q(room__book__check_in__lte = check_in, room__book__check_out__gte = check_out)1주차 금요일에 멘토 병민님과 날짜별 필터링을 여러 경우의 수로 생각해보는 시간을 함께 가졌다. 왜 진작 여러 경우로 생각해보지 않고 하나의 조건으로만 생각했는지..
첫번째 유레카였다!
remain = Staytype.objects.annotate(Sum('room__quantity') - Count('room__book__id',filter=(q1|q2|q3)))날짜별 필터링을 마친 뒤 남은 숙소 Staytype 객체들 중 빈 객실들을 찾아야 하는 단계로 넘어갔다. 여기서도 안 풀렸던 문제는 아래와 같이 객실 총합에서 예약 객실 개수를 차감했을 때 총합보다 더 큰 수치가 반환된다는 점이었다. 우선 Sum과 Count 에 대해서 따로 따로 annotate 해보았고, 제대로 된 수치가 반환되는 것을 확인했다.
결국 같이 사용할 때 어떤 이유에서 이상한 수치가 나왔다는 생각이 들었고, 이 부분을 구글링해보았다. 나와 똑같은 문제를 가진 사람을 stackoverflow에서 찾을 수 있었고, MySQL에서 쿼리문으로 바꿀때 JOIN을 중첩해서 사용하기 때문이라는 것과 Subquery를 사용하면 해결할 수 있다는 것을 알았다. 두번재 유레카였다!
여기까지는 해결이 되었으나 여러개의 쿼리셋에 대해서는 subquery returns more than 1 column 이라는 에러가 발생했다. 이 부분을 같은 백엔트 팀원 민님과 슬랙으로 공유하면서 각자 집에서 코딩하지만 같은 문제를 해결해나갔다. 민님께서 OuterRef를 사용하면 여러개의 쿼리셋도 반환된다는 것을 공유해주셨다. 덕분에 아래와 같은 코드를 완성할 수 있었다.
2-3 완성한 코드
# stays.views.py
stays = Staytype.objects.filter(q)
total = stays.annotate(total = Sum('room__quantity')).filter(pk = OuterRef('pk'))
booked = stays.annotate(booked = Count('room__book__id',filter=(q1|q2|q3))).filter(pk = OuterRef('pk'))
stays = stays.annotate(
total = Subquery(total.values('total')),
booked = Subquery(booked.values('booked')),
remain = F('total')-F('booked'),
is_available = Case(
When(remain = 0),
then = False,
default = True)
).exclude(is_available= False)Refactoring 후
# stays.views.py
stays = Staytype.objects.filter(q).prefetch_related('room_set', 'room_set__book_set').annotate(
total_room_count = Sum('room__quantity'),
booked_room_count = Subquery(
Staytype.objects.annotate(booked_count = Count('room__book__id', filter = (q1|q2|q3))).filter(pk = OuterRef('pk')).values('booked_count')
),
is_available = Case(
When(total_room_count__gt = F('booked_room_count'), then = True),
default = False
)
).exclude(is_available = False) 이 코드가 가치있다고 느끼는 것은 단순히 기능을 구현해내서가 아니다. 이 코드를 완성시키는데 주말까지 이어진 관계로 슬랙으로 같은 문제에 대해 접근방법과 관련 자료도 공유했다. '여기까지 해결됐고 이 부분이 막혀요' 라고 하면 '이 방법을 쓰면 될 것 같아요' 처럼 문제를 해결하기 위해 같이 힘을 썼다. 코드가 완성되자 기쁨의 희열을 느꼈고 이 코드는 팀원분과 함께 이루어낸거라 생각한다. 이 때 공유를 하면서 시너지 효과가 날 수 있다는 개발자들의 공유 문화를 조금은 느낀 것 같다.
3. 배움의 연속
1차 프로젝트에서는 소통의 중요성을 느꼈다면, 2차 프로젝트에서는 배움의 연속이었다. 기능 및 로직의 난이도가 올라감으로써 Subquery, Case, When 등 장고의 새로운 개념들을 익힐 수 있었다. 이미지 파일을 업로드하기 위해 s3를 다뤘고, docker도 생성해보았다.
팀원들에게도 배울 점들이 많았다.
PM 동우님은 첫날부터 우리가 어떤 식으로 가야할 지 리드해주었다. 또한 백엔드에서 소셜로그인 기능 구현이 1순위라고 하자 바로 방향을 틀어 같이 1순위로 맞추어 나갔다. 이 때 동우님의 리더쉽이 빛났던 것 같다.
명성님은 팀원들을 잘 케어해주시고 항상 분위기를 좋게 만들어주셨다.
주영님은 힘들 수 있는 상황에서도 본인의 일을 끝까지 해내주셨다.
민님과는 각자의 기능만 구현하는 것이 아닌 서로의 코드를 공유하는 시간을 가졌다. 본인 것만 하기에 바쁠 수 있는 상황에서도 같이 하는 시간을 가지는 것이 좋아보였다.
1,2차 프로젝트의 피로가 쌓이고 기능의 난이도가 올라가면서 모두가 힘들 수 있는 상황에서도 서로에 대한 배려심이 있기에 잘 마무리할 수 있었던 것 같다. 유머러스했고 기분 좋은 팀 프로젝트로 매듭지은 것 같다.
