SSE + FastAPI + OpenAI 비동기 스트리밍
개요
- 이 매뉴얼에서는 FastAPI와
openai >=1버전의 Python 라이브러리를 사용하여 비동기 스트리밍을 구현하는 방법을 설명합니다. - 이를 통해 OpenAI의 GPT-3.5-turbo 모델을 사용하여 실시간으로 응답을 스트리밍하는 API를 구축할 수 있습니다.
- 또한 Server-Sent Events(SSE)를 활용하여 클라이언트에 실시간 데이터를 스트리밍하는 방법도 다룹니다.
환경 설정
1. 필요한 패키지 설치
pip install fastapi uvicorn openai httpx
# poetry add fastapi uvicorn openai httpx2. OpenAI API 키 설정
OpenAI API를 사용하기 위해 API 키를 준비합니다. 이 키는 OpenAI 대시보드에서 발급받을 수 있습니다.
SSE (Server-Sent Events)란?
- Server-Sent Events(SSE)는 서버에서 클라이언트로 자동으로 업데이트를 푸시하는 단방향 통신 방법입니다.
- 클라이언트가 서버에 요청을 보내면, 서버는 이벤트 스트림을 통해 지속적으로 데이터를 전송할 수 있습니다.
- HTTP 프로토콜을 사용하며, 클라이언트는 이벤트 스트림을 수신하기 위해 이벤트 소스(EventSource) 객체를 사용합니다.
- 이 방법을 사용하면, 추론 결과를 실시간으로 받아서 화면에 보여줄 수 있습니다.
데이터 흐름
클라이언트는 한 번의 요청으로 FastAPI 서버로부터 여러 번의 스트리밍 응답을 받습니다.
FastAPI 서버는 OpenAI API로부터 받은 스트리밍 응답을 클라이언트에게 실시간으로 전송합니다.
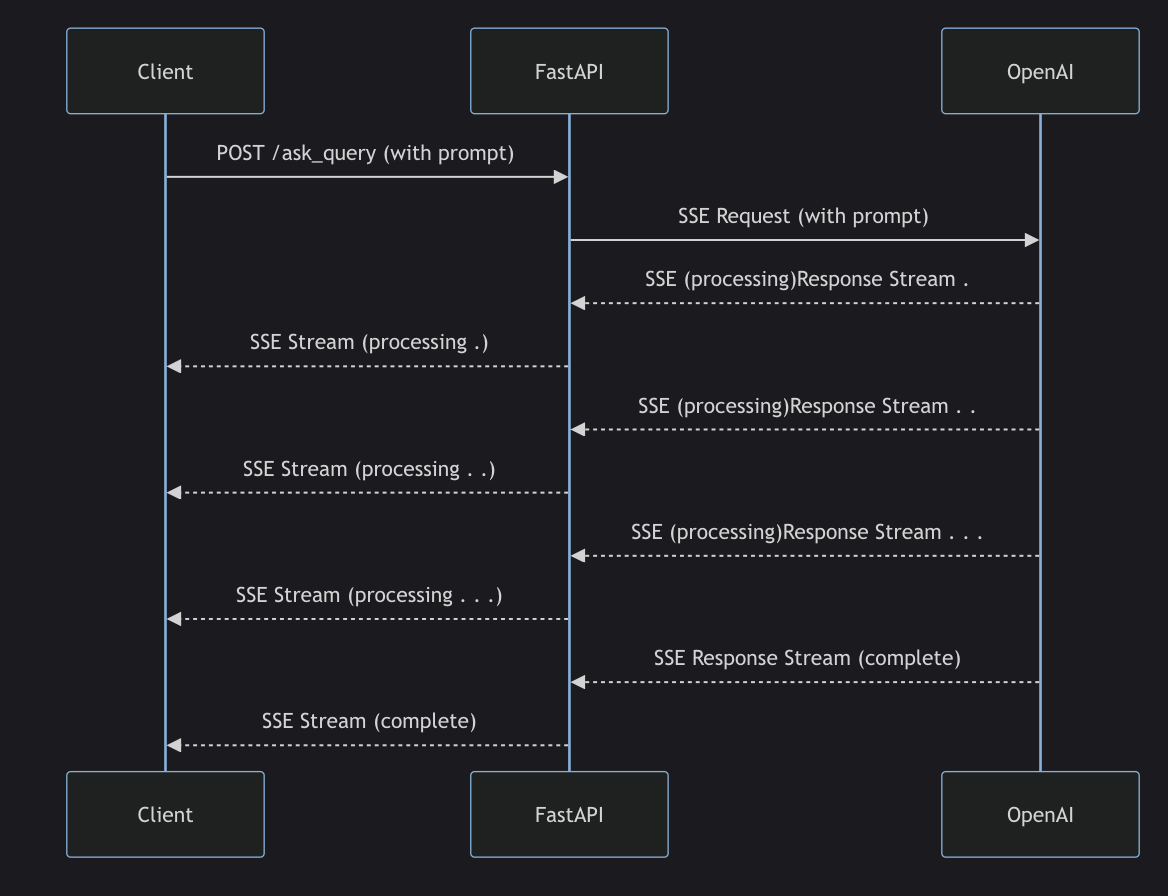
설명
이 다이어그램은 FastAPI와 OpenAI API를 사용하여 실시간 스트리밍 응답을 처리하는 과정을 나타냅니다. 각 단계는 다음과 같습니다:
- Client -> FastAPI: 클라이언트가
POST /ask_query요청을 FastAPI 서버에 보냅니다. 이 요청은 사용자가 입력한 프롬프트를 포함합니다. - FastAPI -> OpenAI: FastAPI 서버는 OpenAI API에 SSE 요청을 보냅니다. 이 요청은 클라이언트의 프롬프트를 포함합니다.
- OpenAI -> FastAPI: OpenAI API는 SSE 스트림을 통해 여러 개의
processing상태의 응답을 FastAPI 서버로 보냅니다. 이 응답들은 스트리밍 형식으로 실시간으로 전송됩니다. - FastAPI -> Client: FastAPI 서버는 OpenAI API에서 받은
processing상태의 응답을 클라이언트로 다시 SSE 스트림을 통해 전송합니다. 이 단계는 OpenAI API에서 응답을 받을 때마다 반복됩니다. - OpenAI -> FastAPI: OpenAI API는
complete상태의 응답을 여러 번 FastAPI 서버로 보냅니다. 이는 응답이 완료되었음을 나타냅니다. - FastAPI -> Client: FastAPI 서버는
complete상태의 응답을 클라이언트로 전송하여 스트림을 마칩니다.
이 과정에서 두 번의 SSE가 발생합니다:
1. FastAPI 서버가 OpenAI API로부터 SSE를 통해 스트리밍 응답을 수신합니다.
2. FastAPI 서버가 받은 스트리밍 응답을 클라이언트로 다시 SSE를 통해 전송합니다.
이를 통해 클라이언트는 실시간으로 OpenAI API의 응답을 스트리밍 방식으로 받을 수 있게 됩니다.
코드 작성
1. FastAPI 앱 생성
아래와 같이 FastAPI 애플리케이션을 설정합니다.
from fastapi import FastAPI, Request
from fastapi.responses import StreamingResponse
import openai
import asyncio
import json
app = FastAPI()
openai_api_key = "YOUR_OPENAI_API_KEY"
client = openai.Client(api_key=openai_api_key)
@app.post("/ask_query")
async def ask_query(request: Request) -> StreamingResponse:
body = await request.json()
prompt = body.get("prompt", "")
async def stream_openai_response(prompt):
stream = await client.chat.completions.create(
messages=[{"role": "user", "content": prompt}],
model="gpt-3.5-turbo",
stream=True,
)
async for chunk in stream:
chunk_content = chunk.choices[0].delta.get("content", "")
yield json.dumps({"status": "processing", "data": chunk_content}, ensure_ascii=False) + "\n"
yield json.dumps({"status": "complete", "data": "Stream finished"}, ensure_ascii=False) + "\n"
return StreamingResponse(stream_openai_response(prompt), media_type="text/event-stream")
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)실행
FastAPI 서버를 실행하려면 아래 명령어를 사용하세요.
uvicorn myproject.main:app --reload클라이언트에서 SSE 사용
브라우저나 HTTP 클라이언트를 사용하여 SSE 스트림을 수신할 수 있습니다. 예를 들어, 자바스크립트를 사용하여 SSE를 수신하려면 다음과 같이 작성할 수 있습니다:
JavaScript 코드
document.getElementById('queryForm').addEventListener('submit', function(event) {
event.preventDefault();
const prompt = document.getElementById('promptInput').value;
fetch('http://localhost:8000/ask_query', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Accept': 'text/event-stream' // 이 헤더가 SSE를 위한 응답을 수신하기 위해 필요합니다.
},
body: JSON.stringify({ prompt: prompt })
})
.then(response => {
if (!response.ok) {
throw new Error('Network response was not ok');
}
const reader = response.body.getReader();
const decoder = new TextDecoder('utf-8');
function read() {
reader.read().then(({ done, value }) => {
if (done) {
return;
}
const chunk = decoder.decode(value, { stream: true });
const lines = chunk.split('\n');
lines.forEach(line => {
if (line.trim()) {
const parsedLine = JSON.parse(line);
const status = parsedLine.status;
const data = parsedLine.data;
console.log(`[${status}] ${data}`);
}
});
read();
});
}
read();
})
.catch(error => {
console.error('Fetch error:', error);
});
});이제 브라우저나 HTTP 클라이언트를 사용하여 http://localhost:8000/ask_query 엔드포인트로 POST 요청을 보내면 스트리밍 응답을 받을 수 있습니다.

AI Application Engineer
안녕하세요!
좋은글 잘 보았습니다.
궁금한 점이 있는데, yield 구문에 json.dumps()는 반드시 사용해야 하나요?
json.dumps()를 사용하지 않고, string 값을 그대로 yield해도 되는 것인지 궁금합니다!