Intro
개요
프로젝트에 적용할 skip-gram 기반의 item2vec 모델을 적용하기 위해 word2vec에 대한 개념을 더 깊게 파악해보고자 진행
논문 주제 및 제목
Efficient Estimation of Word Representations in Vector Spac
: 단어를 vector공간으로 표현하는 것을 목표로 함
:
논문 링크
논문 리뷰
Abstract
본 논문은 다양한 큰 텍스트데이터를 수치 차원으로 표현함으로써 단어간 유사도를 측정함으로써, 이전 Nueural Network 기반의 다른 모델을 활용한 기술들과 비교한다.
정확도를 높임과 동시에 계산량을 상당히 줄인다는 특징을 갖는다.
하루안에 약 160만개의 단어를 학습이 가능하다.
다양한 유사도 계산 결과에서 상당히 좋은 성능을 보였다.
1. Introduction
1.1 Goals of the Paper
수십억 개의 단어와 수백만 개의 단어를 가진 상당히 큰 데이터 집합으로부터 high-quality의 단어 벡터를 학습하는 데 사용될 수 있는 기술을 도입하는 것이다.
유사한 단어가 서로 근접하는 경향이 있을 뿐만 아니라, 단어가 여러 수준의 유사성을 가질 수 있을 것으로 예상하여 결과 벡터 표현의 품질을 측정하기 위해 최근에 제안된 기법을 사용한다.
예를 들어 명사는 여러 단어 어미를 가질 수 있으며, 원래 벡터 공간의 부분 공간에서 유사한 단어를 검색하면 유사한 어미를 갖는 단어를 찾을 수 있다.

특히, 위와같이 King - Man + Woman = Queen 과 같은 벡터연산을 통해 단어 표현의 유사성이 단순한 syntactic 규칙성을 넘어선다는 것이 발견되었다(?)
1.2 Previous Work
기존에도 이미 Neural network language model (NNLM) 아키텍쳐로 단어를 벡터화시키는 구조는 등장하였다. NNLM을 기반으로 NLP 다양한 어플리케이션에 적용이 가능했지만, 연산이 상당히 많이 필요했다.
2. Model Architectures
잠재 의미 분석(LSA)과 잠재 디리클레 할당(LDA)을 포함하여 단어의 연속적인 표현을 추정하기 위해 많은 다양한 유형의 모델이 제안되었다.
| 구분 | 설명 |
|---|---|
| LSA | - Latent Semantic Analysis : 잠재적 의미 분석- 단어 문서 행렬을 차원 축소하여 축소 차원에서 근접 단어들을 토픽으로 묶는다. |
| LDA | - Latent Dirichlet Allocation : 잠재 디리클레 할당 - 단어가 특정 토픽에 존재할 확률과 문서에 특정 토픽이 존재할 확률을 결합확률로 추정하여 토픽을 추출한다. |
본 논문에서, 우리는 이전에 신경망에 의해 학습된 단어의 분산 표현에 초점을 맞춘다.
LDA가 단어 간의 선형 규칙성을 보존하는 데 있어 LSA보다 훨씬 더 우수한 성능을 보인 것으로 나타났다.
또한 LDA는 대규모 데이터 세트에 대해 연산 비용이 상당히 비싸다.
2.1 Feedforward Neural Net Language Model (NNLM)
해당 아키텍쳐는 input, projection, hidden and output layer로 구성되었다.
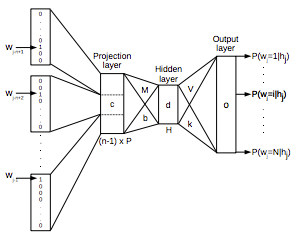
: 전체 어휘의 크기
: 한번에 학습할 단어의 크기
-
현재 보고 있는 단어 이전의 단어들 N개를 one-hot encoding으로 벡터화
-
사전의 크기를 (여기서는 n), Projection Layer의 크기를 P라고 했을 때, 각각의 벡터들은 x 크기의 Projection Matrix에 의해 다음 레이어로 넘어감
-
Projection Layer의 값을 인풋이라고 생각하고, 크기 짜리 hidden layer를 거쳐서 output layer에서 각 단어들이 나올 확률을 계산
-
이를 실제 단어의 one-hot encoding 벡터와 비교해서 에러를 계산하고, 이를 back-propagation해서 네트워크의 weight들을 최적화
-
최종적으로 Projection Layer의 값들을 사용하게 됨, 각 단어들은 크기 의 벡터가 됨
본 논문에서 는 10을 권장하며, Projection Layer의 차원의 수는 500~2000차원을 제안한다.
가장 큰 단점은 연산속도이다.
모든 Output에 대한 확률을 계산하기 위해 모든 입력값에 대한 X 연산을 진행한다.
2.2 Recurrent Neural Net Language Model (RNNLM)
위의 NNLM과의 차이점
- 값을 별도로 설정할 필요가 없다.
Projection Layer가 존재하지 않는다.
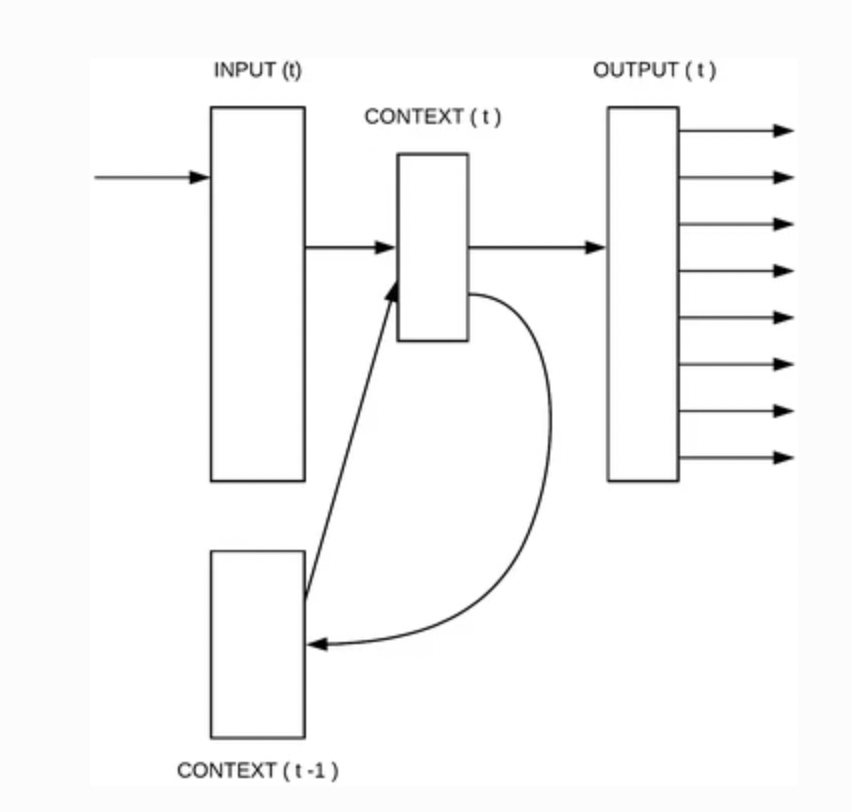
이전 단어를 활용하여 가중치를 업데이트 하는데에 활용할 수 있다.
의 연산을 hierarchical softmax를 사용함으로써 X 로 연산량을 줄일 수 있다.
2.3 Parallel Training of Neural Networks
DistBelief라는 대규모 분산 프레임워크에 여러 모델을 구현함으로써 병렬적인 학습을 진행
3. New Log-linear Models
이번 섹션에서는, 연산량을 최소화하면서 단어의 분산 표현을 학습할 수 있는 새로운 두 모델의 구조를 제안한다.
본 논문에서 제안하는 새로운 모델의 훈련은 두 단계로 이루어진다.
: CBOW, Skip-Gram
- NNLM, RNNLM에서는 대부분의 비용이 non-linear hidden layer에서 발생했다.
- 위의 방식만큼 정밀한 word vector가 아닐 수 있지만, 더 효율적으로 데이터를 처리할 수 있는 방법을 제공한다.
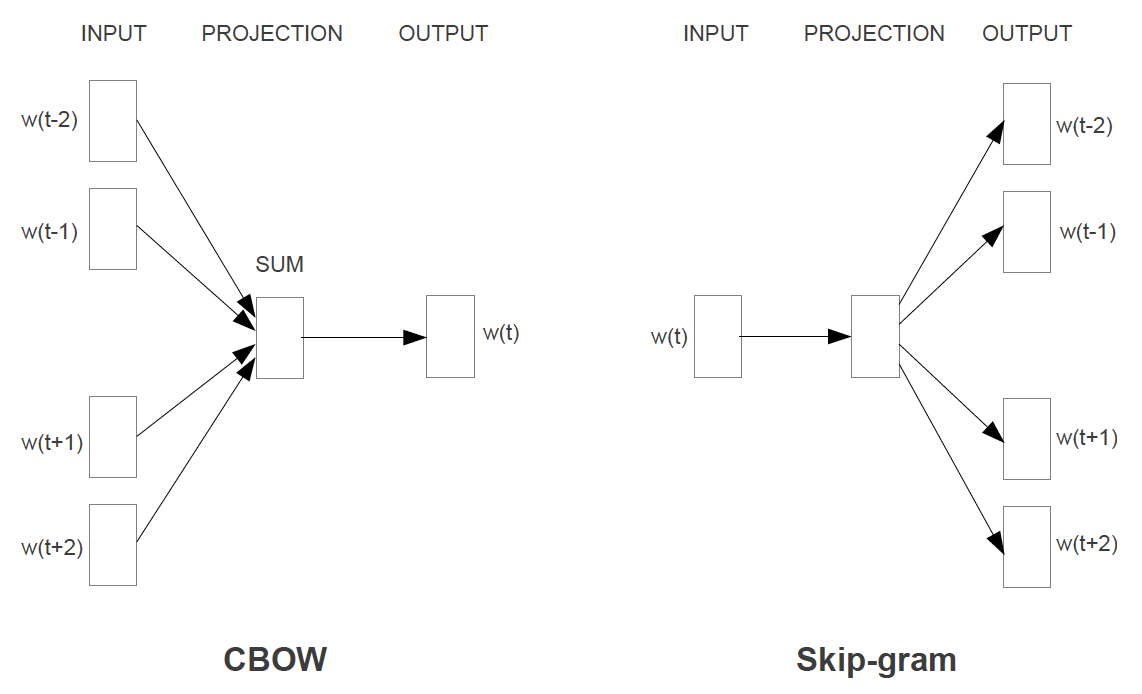
3.1 CBOW (ContinuousBag-of-Words) Model
non-linear hidden layer가 제거되었지만, NNLM처럼 Projection Layer가 존재한다.
전체 word vector의 평균값을 사용하게 된다 : Bag Of Words
➡️ 문맥의 특성을 이해할 수 없다는 특징이 존재하낟.
간단히 요약하면, 중간 단어를 예측하는 방식이다.
또한, 주목할 점은 입력과 투영 계층 사이의 가중치 매트릭스는 NNLM에서와 같은 방식으로 모든 단어 위치에 대해 공유된다는 점이다.
3.2 Continuous Skip-gram Model
CBOW와 다르게, 중간 단어를 이용해서 주변 단어를 예측하는 방식이다.
: the maximum distance of the words.
중심단어로부터의 학습 범위인 를 늘리면 결과 단어 벡터의 품질이 향상되지만 계산 복잡성도 증가한다는 것을 발견했다.
일반적으로 더 멀리 있는 단어가 가까운 단어보다 현재 단어와의 연관성이 적기 때문에, 훈련 예시에서 그 단어들을 덜 샘플링함으로써 멀리 있는 단어들에 덜 비중을 둔다.
학습 복잡도는 아래와 같다.
4. Results
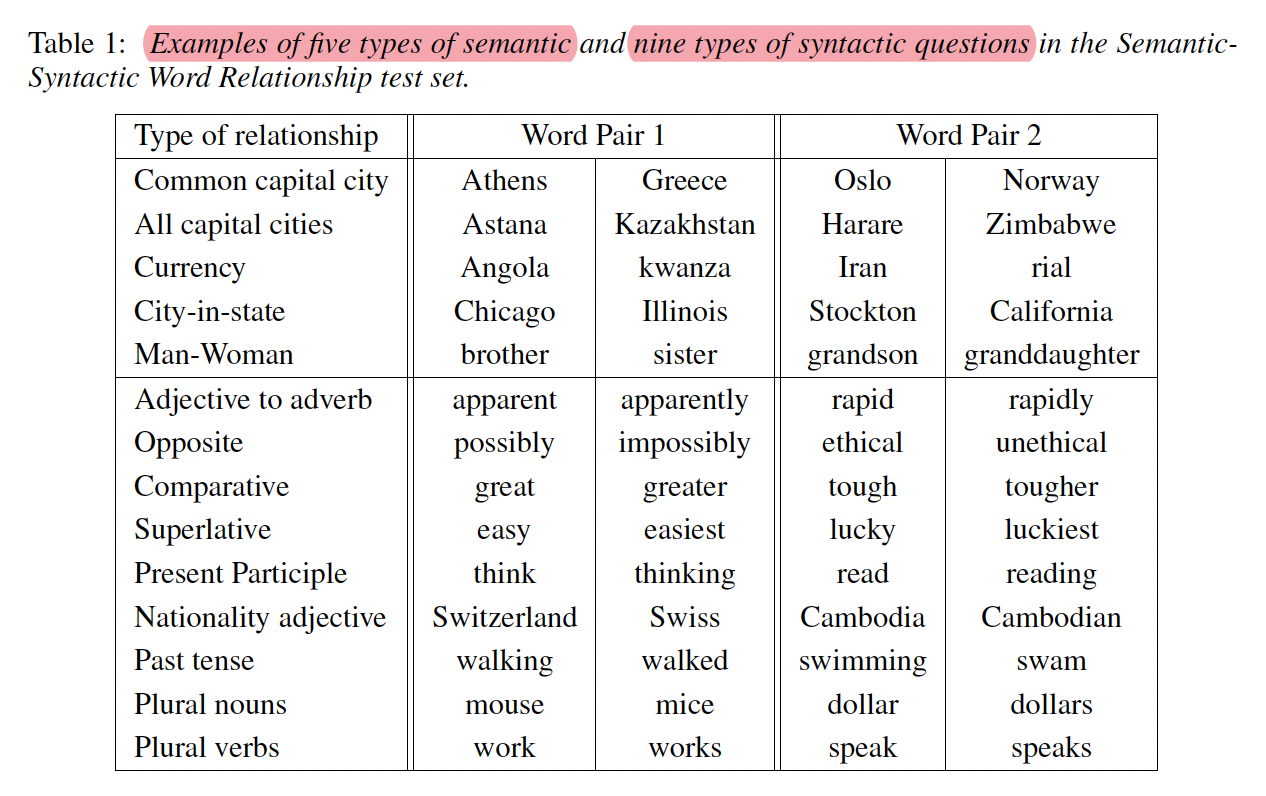
예시로써 확인해보면 아래와 같은 결과를 얻을 수 있다고 한다.
Paris - France + Italy = Rome
biggest - big + small = smallest
물론 각각의 단어는 차원으로 이뤄진 Vector이다.
그 밖에 예시는 아래와 같다.
Review
Skip-gram 에 더 수식적으로 자세히 알아보고자 해당 논문을 읽어본 것이였으나, 이론적인 내용들 위주로 담겨있었음. 추후 다시 skip-gram위주로 다룬 논문에 대한 리뷰가 필요할것같음
