Overview
- Google Research에서 연구한 DreamFusion(ICLR ‘23)에서 처음 제안됨
- Text-to-3D Generation Model에서 사용하는 Diffusion Model 기반의 score Loss
- 2D Diffusion Model이 parametric image generator의 prior로 작동하는 Probability Density distillation에 기반한 Loss
- DreamFusion의 architecture에서 오른쪽 부분과 관련된 Loss Function
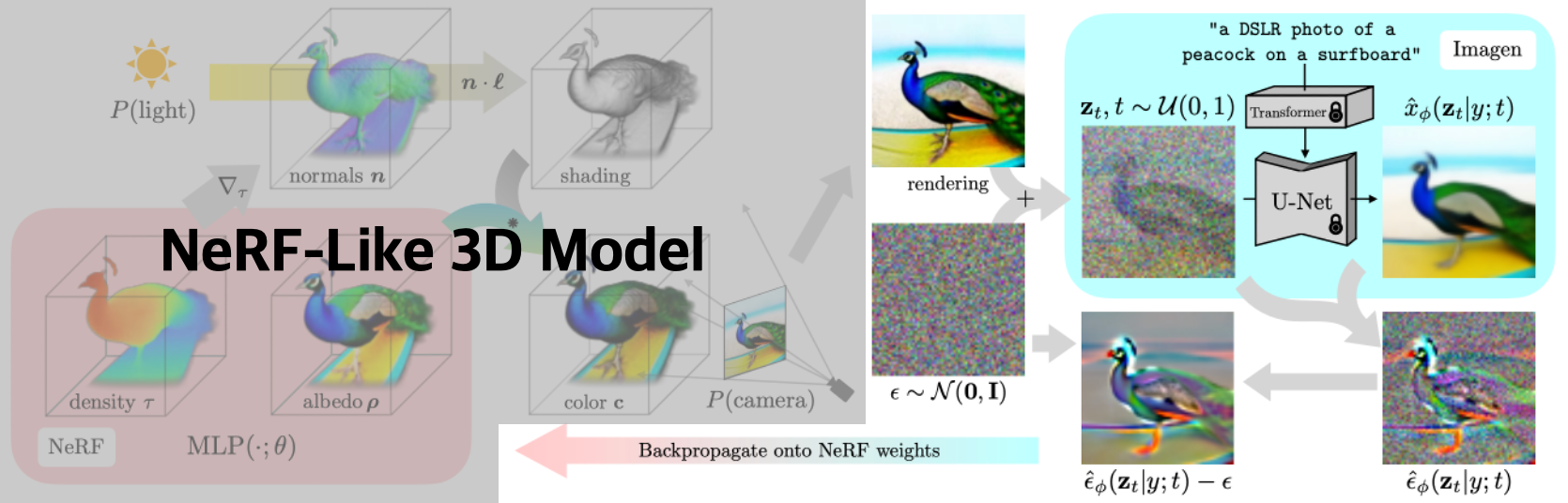
Introduction
- 3D Data Synthesis를 위해서는 1. 학습을 위한 큰 규모의 labeled 3D data 2. 3D Denoising architecture가 필요하지만 둘 다 존재 X
- 기존 Diffusion Model : 학습 데이터와 같은 종류/차원(Pixel Space)에서 Sampling을 수행함
- Goal : Create 3D Models that look like good images when rendered from random angles
- 3D Model로는 DIP(입력받은 를 이미지로 만들어주는 generator)를 사용
- 3D Model의 output 이 diffusion model의 샘플처럼 보이도록 Diffusion Model의 구조를 이용하여 parameter 를 최적화함
Method
- Data point 에 대해 loss를 최소화하는 방법
- (: Diffusion Model의 Loss) - BUT, 실험 결과 realistic한 sample을 생성하지 못함
- Gradient of
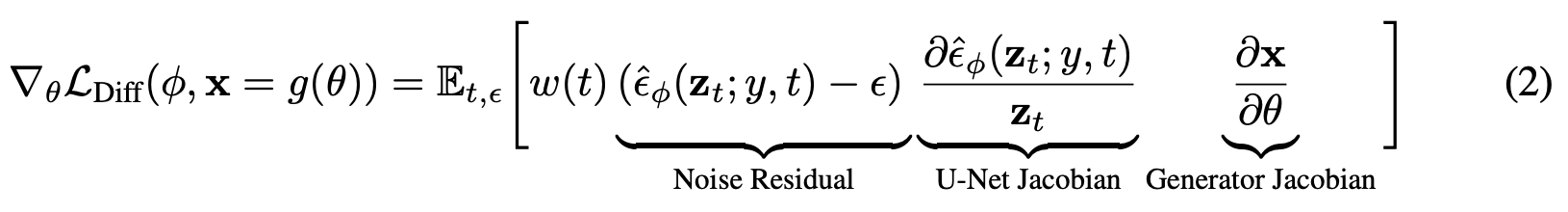
- U-Net Jacobian Term은 계산 비용도 너무 크고 작은 noise 차이에 따라 좌우된다
→ 생략하는 것이 DIP를 최적화하는 데 효과적임
- U-Net Jacobian Term은 계산 비용도 너무 크고 작은 noise 차이에 따라 좌우된다
- : NeRF로 생성된 이미지 (입력 이미지 X)
- : NeRF parameter θ를 가진 differentiable generator
- : Text Embedding 값 (Image-to-3D의 경우 입력 이미지를 넣으면 됨) → condition이라고 볼 수 있음
- Diffusion Model에서 학습된 score function을 이용한 weighted probability density distillation loss(논문)의 gradient라고 볼 수 있음 (Appendix A.4)
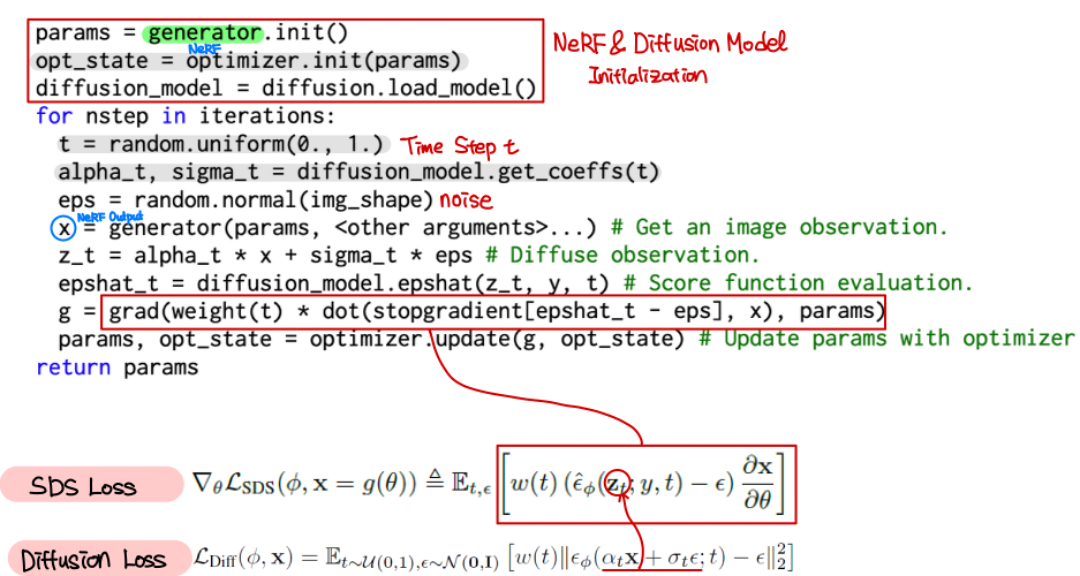
Code
- 논문에 나온 수도 코드에 대한 설명
References
githubDreamFusionAcc : Minimal PyTorch implementation of Dreamfusion [Link]- [개념 정리] SDS (Score Distillation Sampling) Loss : Text-to-3D Loss [Link]
- Score Distillation Sampling [Link]
- [Paper Review] DreamFusion 논문 리뷰 [Link]
- [논문리뷰] DreamFusion: Text-to-3D using 2D Diffusion [Link]
- PR-416: DreamFusion [Link]
- [논문 리뷰] Dreamfusion : Text to 3D using 2d diffusion [Link]
- Differentiable Image Parameterizations [Link]
- [논문리뷰] Parallel WaveNet: Fast High-Fidelity Speech Synthesis (ICML18) [Link]

개발 외의 일들에 더 흥미를 가지는 개발자. Interested in Web, Generative AI, UI/UX.