
⚡ Postgres & SQL
👍 PostgreSQL 사용과 더불어 겸사겸사 SQL 재정리를 거친다. 대부분의 문법은 다른 RDB와 다르지 않으나 일부 알아두어야 할 것이 있어서 그렇다.
📌 ERD 작성
🔷 이왕 하는거 ERD부터 해본다.
- 처음 쓰는 툴로 작성해본다. DBDiagram.io
- 코드로 그리는 형식이라 좀 특별하다. 자세한 사용법은 홈페이지 문서 참조.
Table CUSTOMER {
customer_id varchar [pk]
customer_name varchar
customer_age int
customer_grade varchar
customer_job varchar
customer_cash int
}
Table ORDER {
order_num int [pk]
order_customer varchar
order_product int
order_ea int
order_loc varchar
order_date date
}
Table PRODUCT {
product_num int
product_name varchar
product_stock int
product_price int
product_made varchar
}
Ref: ORDER.order_customer > CUSTOMER.customer_id
Ref: ORDER.order_product > PRODUCT.product_num 
📌 CREATE
⭐ CREATE TABLE
🔷 일반적으로 관계형 데이터베이스는 여러 개의 관련된 테이블로 구성
-
테이블을 통해 고객, 제품, 직원과 같은 구조화된 데이터를 저장할 수 있음
-
새 테이블을 생성하려면
CREATE TABLE문을 사용
CREATE TABLE [IF NOT EXISTS] table_name (
column1 datatype(length) column_constraint,
column2 datatype(length) column_constraint,
...
table_constraints
);
🔷 CREATE TABLE 키워드 다음에 생성하려는 테이블의 이름 지정
-
테이블 이름은 스키마 내에서 유일해야 함. 이미 존재하는 이름으로 테이블을 생성하려고 하면 오류 발생
-
스키마는 테이블을 포함한 데이터베이스 객체들의 명명된 모음. 스키마 없이 테이블을 생성하면 기본값인 public 스키마에 테이블이 생성됨.
🔷 IF NOT EXISTS 옵션을 사용하면 테이블이 존재하지 않을 때만 새 테이블을 생성
IF NOT EXISTS옵션을 사용하고 테이블이 이미 존재하는 경우, PostgreSQL은 오류 대신 알림(notice)만 표시함.
🔷 쉼표로 구분된 테이블 컬럼들을 지정
-
각 컬럼 정의는
컬럼 이름,데이터 타입,크기,제약 조건으로 구성 -
컬럼의 제약 조건은 데이터 무결성을 보장하기 위해 컬럼 내 데이터에 적용되는 규칙을 지정
-
기본 키(primary key),외래 키(foreign key),NOT NULL,고유(unique),검사(check),기본값(default)등 -
ex)
NOT NULL제약 조건은 컬럼의 값이NULL이 될 수 없도록 보장
-
🔷 기본 키, 외래 키, 검사 제약 조건 등 테이블에 대한 제약 조건을 지정
-
테이블 제약 조건은 데이터 무결성을 유지하기 위해 테이블 내 데이터에 적용되는 규칙.
-
일부 컬럼 제약 조건은 기본 키, 외래 키, 고유, 검사 제약 조건과 같이 테이블 제약 조건으로도 정의될 수 있음
⭐ 제약 조건
- PostgreSQL에는 다음과 같은 컬럼 제약 조건 지원
| 제약 조건 | 설명 |
|---|---|
| NOT NULL | 컬럼의 값이 NULL이 될 수 없도록 보장 |
| UNIQUE | 같은 테이블 내에서 해당 컬럼의 값이 고유해야 함 |
| PRIMARY KEY | 테이블의 행을 고유하게 식별하는 키. 테이블당 하나만 존재 가능하며 NOT NULL + UNIQUE의 성격을 가짐 |
| CHECK | 컬럼의 값이 특정 불리언 조건을 만족하도록 제한 예: price >= 0 |
| FOREIGN KEY | 다른 테이블의 특정 컬럼(일반적으로 PRIMARY KEY)에 존재하는 값만 허용. 다수 지정 가능 |
- 테이블 제약 조건은 컬럼 제약 조건과 유사하지만, 테이블 제약 조건에서는 두 개 이상의 컬럼을 포함할 수 있다는 차이가 있음
⭐ PostgreSQL 데이터 타입
- PostgreSQL은 다음과 같은 데이터 타입을 지원함
| 데이터 타입 | 설명 |
|---|---|
| Boolean | true, false 값을 저장하는 불리언 타입 |
| 문자 타입 | char, varchar, text 등. 문자열 저장에 사용 |
| 숫자 타입 | 정수 (int, bigint, 등)와 부동 소수점 (float, double, decimal 등) 숫자 저장 |
| 시간 관련 타입 | date, time, timestamp, interval 등. 날짜 및 시간 정보 저장 |
| UUID | 범용 고유 식별자 (Universally Unique Identifier) 저장에 사용. 중복 없이 고유한 ID 필요 시 유용 |
| 배열 (Array) | 문자열 배열, 숫자 배열 등. 복수 값 저장 가능 (일부 DBMS에서만 지원) |
| JSON | 구조화된 JSON 데이터 저장에 사용. 유연한 데이터 스키마 표현 가능 |
🔷 불리언(Boolean)
| 항목 | 설명 |
|---|---|
| 데이터 타입 | BOOLEAN 또는 BOOL |
| 저장 가능한 값 | TRUE, FALSE, NULL |
| 입력값 변환 | 1, yes, y, t, true → TRUE0, no, n, f, false → FALSE |
| 출력값 변환 | t → true, f → false, NULL은 공백 |
| 예시 | CREATE TABLE users (is_active BOOLEAN);INSERT INTO users VALUES (TRUE); |
🔷 문자(Character)
- PostgreSQL은 세 가지 문자 데이터 타입 제공:
CHAR(n),VARCHAR(n),TEXT
| 타입 | 설명 |
|---|---|
CHAR(n) 또는 CHARACTER(n) | 고정 길이 문자열. 길이가 부족하면 공백으로 채움. 길이 초과 시 오류 발생 |
VARCHAR(n) 또는 CHARACTER VARYING(n) | 가변 길이 문자열. 최대 n자까지 저장. 초과 시 오류 발생, 공백 미채움 |
TEXT | 제한 없는 가변 길이 문자열. 실질적으로 최대 길이 없음 |
🔷 숫자(Numeric)
- PostgreSQL은 두 가지 distinct 숫자 타입을 제공:
| 타입 | 설명 |
|---|---|
SMALLINT | 2바이트 부호 있는 정수. 범위: -32,768 ~ 32,767 |
INT / INTEGER | 4바이트 정수. 범위: -2,147,483,648 ~ 2,147,483,647 |
SERIAL | 자동 증가 정수. MySQL의 AUTO_INCREMENT와 유사 |
FLOAT(n) | 최소 n의 정밀도, 최대 8바이트 부동 소수점 |
REAL / FLOAT4 | 4바이트 부동 소수점 숫자 |
DOUBLE PRECISION / FLOAT8 | 8바이트 부동 소수점 숫자 |
NUMERIC(p,s) | 정밀도 p, 소수점 이하 s 자리의 고정 소수점 숫자 (정확한 계산에 적합) |
🔷 시간 관련 데이터 타입(Temporal data types)
- 시간 관련 데이터 타입은 날짜 및/또는 시간 데이터를 저장할 수 있게 함.
| 타입 | 설명 |
|---|---|
DATE | 날짜만 저장 (예: 2025-05-16) |
TIME | 하루 중 시간만 저장 (예: 14:30:00) |
TIMESTAMP | 날짜 + 시간 저장 (예: 2025-05-16 14:30:00) |
TIMESTAMPTZ | 시간대 정보 포함된 타임스탬프 (timestamp with time zone) |
INTERVAL | 시간 간격/기간 저장 (예: '2 days 3 hours') |
🔷 배열(Arrays)
| 타입 | 설명 |
|---|---|
text[], int[] 등 | 동일 타입 값들의 배열 저장. 예: 요일 목록, 월 이름 등 |
| 사용 예시 | SELECT ARRAY['Mon', 'Tue', 'Wed']; |
🔷 JSON
| 타입 | 설명 |
|---|---|
JSON | 일반 JSON 문자열 저장. 읽을 때마다 파싱 필요 |
JSONB | 바이너리 형태의 JSON. 읽기/검색 빠름, 인덱싱 가능. 다만 쓰기(삽입) 속도는 느림 |
🔷 UUID
| 타입 | 설명 |
|---|---|
UUID | RFC 4122 기반 범용 고유 식별자 저장용. SERIAL보다 더 강력한 고유성 보장 |
| 장점 | 외부 노출에도 안전하고, 분산 시스템에서도 충돌 위험 없음 |
⭐ PostgreSQL 시퀀스
-
PostgreSQL에서 시퀀스(sequence)는 고유한 정수 시퀀스를 생성할 수 있게 해주는 데이터베이스 객체
-
일반적으로 시퀀스는 테이블의 기본 키에 대한 고유 식별자를 생성하는 데 사용
-
또한 시퀀스를 사용하여 여러 테이블에 걸쳐 고유한 번호를 생성할 수도 있음
-
새 시퀀스를 만들려면
CREATE SEQUENCE문을 사용
CREATE SEQUENCE [ IF NOT EXISTS ] sequence_name
[ AS { SMALLINT | INT | BIGINT } ]
[ INCREMENT [ BY ] increment ]
[ MINVALUE minvalue | NO MINVALUE ]
[ MAXVALUE maxvalue | NO MAXVALUE ]
[ START [ WITH ] start ]
[ CACHE cache ]
[ [ NO ] CYCLE ]
[ OWNED BY { table_name.column_name | NONE } ]| 옵션 | 설명 |
|---|---|
sequence_name | 시퀀스 이름 지정. IF NOT EXISTS로 중복 생성 방지 |
AS | 데이터 타입 지정. 기본은 BIGINT |
INCREMENT | 증가 값 지정. 양수: 오름차순, 음수: 내림차순. 기본값 1 |
MINVALUE / MAXVALUE | 최소/최대값 설정. NO MIN/MAXVALUE 시 기본값 사용 |
START | 시퀀스 시작 값. 생략 시 기본값 사용 |
CACHE | 시퀀스 값을 미리 메모리에 저장 (성능 향상) |
CYCLE / NO CYCLE | 한계 도달 시 재시작 여부. 기본값은 NO CYCLE |
OWNED BY | 특정 테이블 컬럼과 연결되어 삭제 시 자동 제거 |
💡
OWNED BY절을 사용하면 시퀀스를 테이블 컬럼과 연결할 수 있어, 컬럼이나 테이블을 삭제할 때 PostgreSQL이 자동으로 관련 시퀀스도 삭제한다.
테이블의 컬럼에 SERIAL 가상 타입을 사용할 때, PostgreSQL이 내부적으로 자동으로 해당 컬럼과 연결된 시퀀스를 생성한다는 점을 참고할 것
🔷 아이덴티티 컬럼
-
PostgreSQL 버전 10에서는 컬럼에 자동으로 고유 번호를 할당할 수 있는 새로운 제약 조건인 GENERATED AS IDENTITY가 도입
-
GENERATED AS IDENTITY 제약 조건은 기존의 SERIAL 컬럼을 대체하는 SQL 표준을 준수하는 변형
column_name type GENERATED { ALWAYS | BY DEFAULT } AS IDENTITY [(sequence_options)]| 옵션 | 설명 |
|---|---|
GENERATED ALWAYS | 항상 자동 생성, 수동 삽입 시 오류 |
GENERATED BY DEFAULT | 자동 생성하되, 수동 삽입 가능 |
| 공통 | 내부적으로 SEQUENCE 사용 |
| 타입 | SMALLINT, INT, BIGINT 사용 가능 |
💡 PostgreSQL은 한 테이블에 여러 개의 아이덴티티 컬럼을 가질 수 있도록 허용한다.
SERIAL과 마찬가지로,GENERATED AS IDENTITY제약 조건도 내부적으로SEQUENCE객체를 사용한다.
⭐ 테이블 생성
CREATE TABLE customer (
customer_id VARCHAR(50) PRIMARY KEY,
customer_name VARCHAR(100) NOT NULL,
customer_age INTEGER,
customer_grade VARCHAR(20) NOT NULL,
customer_job VARCHAR(50) NOT NULL,
customer_cash INTEGER DEFAULT 0
);
-- 데이터 삽입
INSERT INTO customer (customer_id, customer_name, customer_age, customer_grade, customer_job, customer_cash) VALUES
('apple', '장소화', 20, 'gold', '학생', 1000),
('banana', '김선우', 25, 'vip', '간호사', 2500),
('carrot', '고명석', 28, 'gold', '교사', 4500),
('orange', '김용욱', 22, 'silver', '학생', 0),
('melon', '성원용', 35, 'gold', '회사원', 5000),
('peach', '오형준', NULL, 'silver', '의사', 300),
('pear', '채광주', 31, 'silver', '회사원', 500);
CREATE TABLE product (
product_num VARCHAR(10) PRIMARY KEY,
product_name VARCHAR(100) NOT NULL,
product_stock INTEGER NOT NULL,
product_price INTEGER NOT NULL,
product_made VARCHAR(50) NOT NULL
);
-- 데이터 삽입
INSERT INTO product (product_num, product_name, product_stock, product_price, product_made) VALUES
('p01', '그냥만두', 5000, 4500, '대한식품'),
('p02', '매운쫄면', 2500, 5500, '민국푸드'),
('p03', '콩떡파이', 3600, 2600, '한빛제과'),
('p04', '맛난초콜릿', 1250, 2500, '한빛제과'),
('p05', '얼큰라면', 2200, 1200, '대한식품'),
('p06', '통통우동', 1000, 1550, '민국푸드'),
('p07', '달콤비스킷', 1650, 1500, '한빛제과');
⭐ 제약조건이 포함된 테이블 생성 구문
CREATE TABLE orders (
order_num INTEGER NOT NULL PRIMARY KEY,
order_customer VARCHAR(50) NOT NULL REFERENCES customer(customer_id),
order_product VARCHAR(10) NOT NULL REFERENCES product(product_num),
order_ea INTEGER NOT NULL CHECK (order_ea > 0),
order_loc VARCHAR(100) NOT NULL,
order_date DATE NOT NULL,
CONSTRAINT valid_order_date CHECK (order_date <= CURRENT_DATE)
);
-- 데이터 삽입
INSERT INTO orders (order_num, order_customer, order_product, order_ea, order_loc, order_date) VALUES
(01, 'apple', 'p03', 10, '서울시 마포구', '2022-01-01'),
(02, 'melon', 'p01', 5, '인천시 계양구', '2022-01-10'),
(03, 'banana', 'p06', 45, '경기도 부천시', '2022-01-11'),
(04, 'carrot', 'p02', 8, '부산시 금정구', '2022-02-01'),
(05, 'melon', 'p06', 36, '경기도 용인시', '2022-02-20'),
(06, 'banana', 'p01', 19, '충청북도 보은군', '2022-03-02'),
(07, 'apple', 'p03', 22, '서울시 영등포구', '2022-03-15'),
(08, 'pear', 'p02', 50, '강원도 춘천시', '2022-04-10'),
(09, 'banana', 'p04', 15, '전라북도 목포시', '2022-04-11'),
(10, 'carrot', 'p03', 20, '경기도 안양시', '2022-05-22');
📌 select
⭐ 조회 select
- 데이터베이스 작업 시 가장 일반적인 작업 중 하나는 SELECT 문을 사용하여 테이블에서 데이터를 검색하는 것
- SELECT 문은 다음과 같은 절들을 포함
select select_list
from table_name;DISTINCT연산자를 사용하여 중복 없는 고유한 행 선택ORDER BY절을 사용하여 행 정렬WHERE절을 사용하여 행 필터링LIMIT또는FETCH절을 사용하여 테이블에서 일부 행만 선택GROUP BY절을 사용하여 행을 그룹으로 묶기HAVING절을 사용하여 그룹 필터링INNER JOIN,LEFT JOIN,FULL OUTER JOIN,CROSS JOIN등의 조인을 사용하여 다른 테이블과 연결해서 데이터를 조회UNION,INTERSECT및EXCEPT를 사용하여 집합 연산 수행
⭐ GROUP BY
- GROUP BY 절은 SELECT 문에서 반환된 행들을 그룹으로 나눌 때 주로 사용
- 각 그룹에 대해 SUM()과 같은 집계 함수를 적용하여 그룹별 합계를 구하거나, COUNT()를 이용해 그룹 내 행의 개수를 구할 수 있음
🔷 GROUP BY 절의 기본 구문
SELECT column_1, column_2, ...,
aggregate_function(column_3)
FROM
table_name
GROUP BY
column_1,
column_2,
...;-
먼저, 그룹화하고자 하는 컬럼(column1, column2 등)과 집계 함수를 적용할 컬럼(column3)을
SELECT절에 지정 -
다음으로,
GROUP BY절에 그룹화할 컬럼들을 나열
GROUP BY절은GROUP BY절에 지정된 컬럼들의 값에 따라 행들을 여러 그룹으로 나눈 뒤, 각 그룹에 대해 지정된 집계 함수를 계산GROUP BY절은SELECT문의 다른 절들과 함께 사용할 수도 있음- PostgreSQL에서는
GROUP BY절이FROM과WHERE절 다음, 그리고HAVING,SELECT,DISTINCT,ORDER BY,LIMIT절들보다 먼저 실행됨
⭐ INNER JOIN
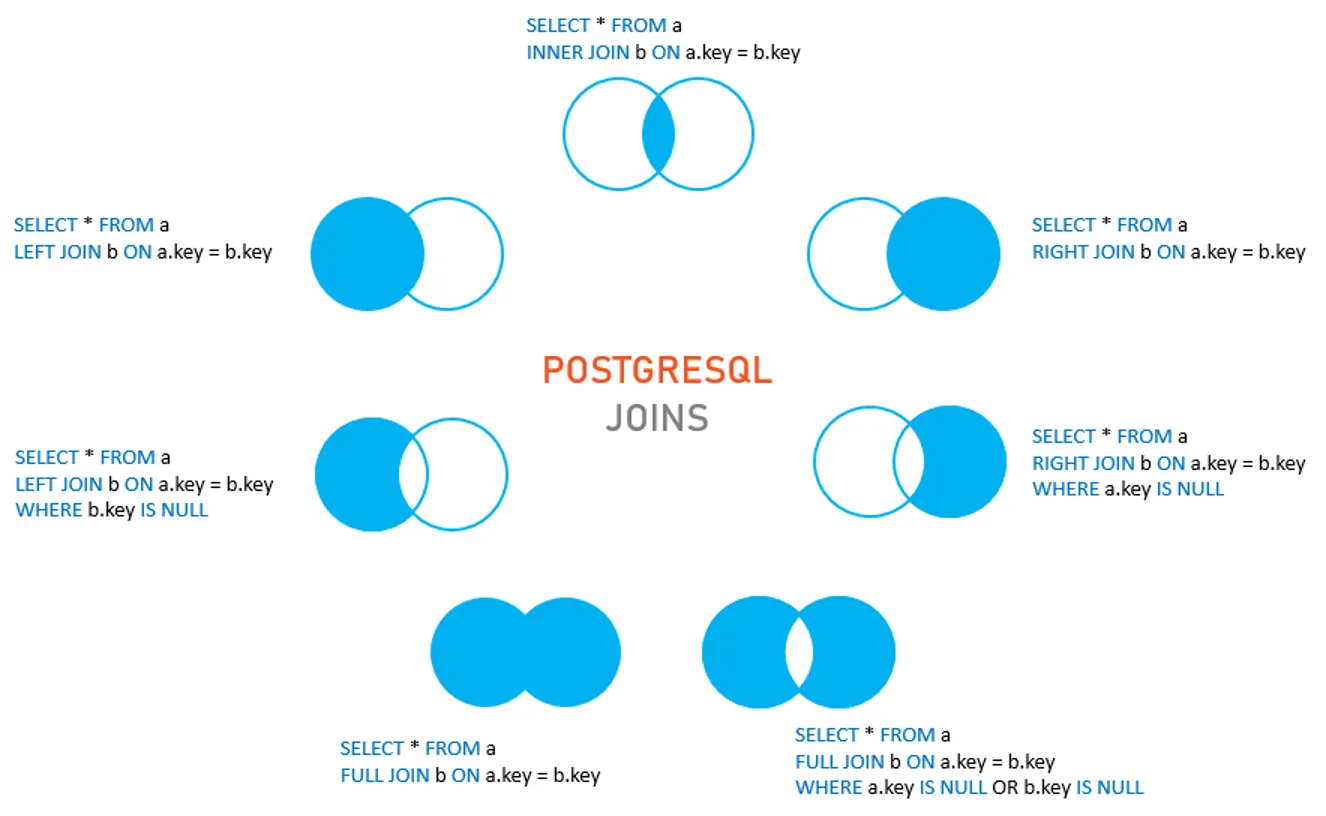
- 관계형 데이터베이스에서는 데이터가 일반적으로 여러 테이블에 분산되어 저장
- 보다 포괄적인 데이터를 조회하기 위해서는 여러 테이블에서 데이터를 함께 조회해야 할 때가 존재
🔷 두 테이블을 조인하는 INNER JOIN 절의 기본 구문:
SELECT
select_list
FROM
table1
INNER JOIN table2
ON table1.column_name = table2.column_name;- 먼저,
SELECT절의select_list에 두 테이블에서 조회할 컬럼 지정 - 다음으로,
FROM절에 데이터 조회의 기준이 되는 메인 테이블(table1) 지정 - 이후,
INNER JOIN키워드를 사용하여 조인할 두 번째 테이블(table2) 지정 - 마지막으로
ON뒤에 조인 조건 정의. 이 조건은 두 테이블에서 어떤 컬럼(column_name)이 일치해야 조인이 이루어지는지 나타냄
INNER JOIN의 작동 방식- table1의 각 행마다, 조인 조건이 지정된 column_name의 값과 table2의 해당 컬럼 값을 비교
- 이 값들이 같으면,
INNER JOIN은 두 테이블의 모든 컬럼을 포함하는 새로운 행을 생성해서 결과 집합(result set)에 추가 - 반대로 값이 같지 않으면, 현재 조합을 무시하고 다음 행으로 넘어가 동일한 과정을 반복
⭐ LEFT JOIN
LEFT JOIN절은 왼쪽 테이블과 오른쪽 테이블을 조인하며, 왼쪽 테이블의 모든 행을 반환- 이때 오른쪽 테이블에 일치하는 행이 있는 경우 해당 행이 함께 반환되고, 일치하는 행이 없는 경우 오른쪽 테이블의 컬럼에는 NULL 값이 반환
LEFT JOIN은 한 테이블에는 존재하지만 다른 테이블에는 일치하는 행이 없는 데이터를 조회할 때 유용하게 사용
🔷 LEFT JOIN 절의 기본 구문
SELECT
select_list
FROM
table1
LEFT JOIN table2
ON table1.column_name = table2.column_name;- 먼저,
SELECT절의 select_list에 두 테이블에서 조회할 컬럼 지정 - 다음으로,
FROM절에 기준이 되는 왼쪽 테이블(table1) 지정 - 그 다음,
LEFT JOIN키워드로 조인할 오른쪽 테이블(table2) 지정 - 마지막으로, 조인 조건(
table1.column_name=table2.column_name)을 지정하는데, 이 조건은 두 테이블의 어떤 컬럼이 서로 일치해야 하는지를 나타냄
⭐ SELF JOIN
- 셀프 조인이란, 하나의 테이블을 자기 자신과 조인하는 일반적인 조인 방식
- 실무에서는 보통 계층적 데이터를 조회하거나, 같은 테이블 내의 행끼리 비교할 때 셀프 조인을 활용
- 셀프 조인을 수행하려면, 같은 테이블을 두 번 지정하고 각각 다른 테이블 별칭을 부여한 뒤, ON 키워드 뒤에 조인 조건(join predicate)을 지정
🔷 테이블 자신과 조인하는 INNER JOIN 예시
SELECT select_list
FROM table_name t1
INNER JOIN table_name t2 ON join_predicate;- 이 구문에서, table_name을
INNER JOIN으로 자기 자신과 조인하고 있음 - 또는,
LEFT JOIN이나RIGHT JOIN절을 사용해서도 자신과 조인할 수 있음
📌 INSERT
INSERT문은 테이블에 새로운 행(row)을 추가할 때 사용
INSERT INTO table1(column1, column2, …)
VALUES (value1, value2, …);- 먼저,
INSERT INTO키워드 다음에 데이터를 추가할 테이블 이름(table1)과, 콤마로 구분된 컬럼 목록(column1, column2, ...) 지정 - 그 다음,
VALUES키워드 뒤에 괄호로 감싼 콤마로 구분된 값 목록(value1, value2, ...)을 지정 - 컬럼 목록과 값 목록의 순서는 반드시 일치해야 함
INSERT문이 실행되면 다음과 같은 형식의 커맨드 태그(command tag)를 반환
INSERT oid countOID는 오브젝트 식별자(object identifier)로, PostgreSQL이 시스템 테이블의 기본 키로 내부적으로 사용- 일반적으로
INSERT문은OID가 0인 값을 반환 count는 성공적으로 추가된 행(row)의 개수를 의미- 테이블에 새로운 행을 성공적으로 추가하면, 일반적으로 다음과 같은 결과가 반환
INSERT 0 1🔷 RETURNING 절
INSERT문은 선택적으로RETURNING절을 사용할 수 있음RETURNING절을 사용하면 새로 삽입된 행의 정보를 반환받을 수 있음- 삽입된 전체 행을 반환 받고 싶을 때는
RETURNING키워드 뒤에 별표(*)를 사용
INSERT INTO table1(column1, column2, …)
VALUES (value1, value2, …)
RETURNING *;- 삽입된 행의 일부 컬럼 값만 반환하고 싶을 때는,
RETURNING뒤에 원하는 컬럼명을 지정할 수 있음
INSERT INTO table1(column1, column2, …)
VALUES (value1, value2, …)
RETURNING id;- 반환되는 값을 다른 이름으로 표시하고 싶을 때는
AS키워드를 사용하여 별칭(output_name)을 지정할 수도 있음
INSERT INTO table1(column1, column2, …)
VALUES (value1, value2, …)
RETURNING output_expression AS output_name;⭐ 테이블에 여러 행 삽입하기
- 하나의
INSERT문으로 테이블에 여러 행을 삽입하려면 다음과 같은 구문 사용
INSERT INTO table_name (column_list)
VALUES
(value_list_1),
(value_list_2),
...
(value_list_n);- 먼저,
INSERT INTO키워드 뒤에 데이터를 삽입할 테이블 이름 지정 - 그 다음, 테이블 이름 뒤 괄호 안에 필요한 컬럼 목록 또는 모든 컬럼 목록(column_list) 지정
- 그리고
VALUES키워드 뒤에 삽입할 각 행의 값을 괄호로 묶고, 콤마로 구분하여 나열
🔷 여러 행을 삽입하면서 동시에 삽입된 행들을 반환하려면 RETURNING 절을 다음과 같이 추가
INSERT INTO table_name (column_list)
VALUES
(value_list_1),
(value_list_2),
...
(value_list_n)
RETURNING * | output_expression;- 여러 행을 한 번에 삽입하는 것은 한 행씩 개별적으로 삽입하는 것에 비해 다음과 같은 장점이 있음
- 성능(Performance): 여러 행을 한 번에 삽입하면, 애플리케이션과 PostgreSQL 서버 사이의 왕복 횟수가 줄어들어 성능이 향상
- 원자성(Atomicity): 전체 INSERT 문이 원자적으로 처리되기 때문에, 모든 행이 한 번에 삽입되거나, 하나도 삽입되지 않음. 이를 통해 데이터의 일관성을 보장할 수 있음
📌 UPDATE
UPDATE문은 테이블의 하나 또는 여러 행의 하나 또는 여러 컬럼에 있는 데이터를 갱신할 때 사용
UPDATE table_name
SET column1 = value1,
column2 = value2,
...
WHERE condition;- 먼저,
UPDATE키워드 다음에 데이터를 갱신할 테이블 이름 지정 - 다음으로,
SET키워드 다음에 갱신할 컬럼과 새로운 값을 지정함. SET 절에 포함되지 않은 컬럼들은 원래 값을 유지 - 마지막으로,
WHERE절의 조건을 사용하여 어떤 행들을 갱신할지 결정
WHERE절은 선택사항이지만,WHERE절을 생략하면,UPDATE문은 테이블의 모든 행을 갱신UPDATE문이 성공적으로 실행되면, 다음과 같은 커맨드 태그를 반환
UPDATE count- 여기서
count는 값이 실제로 변경되지 않은 행을 포함하여 갱신된 행의 총 개수를 나타냄
🔷 갱신된 행 반환하기
- UPDATE 문은 선택적으로 RETURNING 절을 사용할 수 있음
- RETURNING 절을 사용하면 갱신된 행들의 정보를 반환 받을 수 있음
UPDATE table_name
SET column1 = value1,
column2 = value2,
...
WHERE condition
RETURNING * | output_expression AS output_name;📌 DELETE
DELETE문은 테이블에서 하나 또는 여러 행을 삭제할 때 사용
DELETE FROM table_name
WHERE condition;- 먼저,
DELETE FROM키워드 다음에 데이터를 삭제할 테이블 이름(table_name)을 지정 - 다음으로,
WHERE절에 조건을 지정하여 어떤 행들을 삭제할지 결정
WHERE절은 선택사항이지만,WHERE절을 생략하면DELETE문은 테이블의 모든 행을 삭제DELETE문은 삭제된 행의 개수를 반환. 만약DELETE문이 어떤 행도 삭제하지 않았다면 0을 반환- 삭제된 행(들)을 클라이언트에게 반환하려면 다음과 같이
RETURNING절을 사용
DELETE FROM table_name
WHERE condition
RETURNING (select_list | *)- 별표(*)를 사용하면 삭제된 행(들)의 모든 컬럼을 반환할 수 있음. 특정 컬럼의 값만 반환하고 싶다면,
RETURNING키워드 다음에 해당 컬럼을 지정할 수 있음 - 예를 들어, 다음 문장은 테이블에서 행들을 삭제하고 삭제된 행들의 id 값을 반환
DELETE FROM table_name
WHERE condition
RETURNING id;- 다른 테이블의 데이터를 기반으로 테이블에서 데이터를 삭제하려면
DELETE JOIN문을 사용할 수 있음 - 외래 키 관계가 있는 데이터를 삭제하려면
ON DELETE CASCADE옵션을 사용 DELETE문은 테이블에서 데이터만 삭제하고 테이블의 구조는 변경하지 않는다는 점을 유의- 컬럼 제거와 같이 테이블의 구조를 변경하려면 대신
ALTER TABLE문을 사용해야 함
📌 UPSERT
Upsert는update와insert의 조합. 즉,Upsert는 기존 행이 존재할 경우 업데이트하고, 존재하지 않을 경우 새로운 행을 삽입할 수 있게 해 줌- PostgreSQL은
UPSERT라는 명령어를 직접 제공하지는 않지만,INSERT...ON CONFLICT문을 통해upsert기능을 지원 - PostgreSQL 15 이상 버전을 사용한다면,
UPSERT와 동등한 기능을 하는MERGE문을 사용할 수도 있음
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...)
ON CONFLICT (conflict_column)
DO NOTHING | DO UPDATE SET column1 = value1, column2 = value2, ...;table_name: 데이터를 삽입하려는 테이블의 이름(column1, column2, ...): 테이블에 값을 삽입하려는 컬럼 목록VALUES(value1, value2, ...): 지정된 컬럼들(column1, column2, ...)에 삽입하려는 값들ON CONFLICT (conflict_column): 이 절은 충돌 대상을 지정. 충돌 대상은 충돌이 발생할 수 있는 고유 제약 조건(unique constraint) 또는 고유 인덱스(unique index)DO NOTHING: 충돌이 발생했을 때 아무것도 하지 않도록 PostgreSQL에 지시DO UPDATE: 충돌이 발생했을 때 업데이트를 수행SET column = value1, column = value2, ...: 충돌이 발생한 경우 업데이트할 컬럼 목록과 해당 값들을 지정
🔷 INSERT ... ON CONFLICT 문의 작동 방식
-
먼저,
ON CONFLICT절은 충돌 대상을 식별함. 이는 주로 고유 제약 조건(또는 고유 인덱스). 삽입하려는 데이터가 이 제약 조건을 위반하면 충돌이 발생 -
다음으로,
DO UPDATE는 충돌이 발생했을 때 작업을 중단하는 대신 기존 행을 업데이트하거나 아무 작업도 하지 않도록 PostgreSQL에 지시 -
마지막으로,
SET절은 업데이트할 컬럼과 값을 정의함. 새로운 값을 사용하거나,EXCLUDED키워드를 사용하여 삽입하려고 시도했던 값을 참조할 수 있음
