
⚡ Influx DB와 Grafana
📌 Influx DB
⭐ Influx DB란?
- 다양한 DB의 종류 중 시계열 데이터베이스(TSDB, Time Series Database)의 일종이다.
💡 DB의 종류
1.관계형 데이터베이스(Related Database)
-> SQLite, MySQL 등
2.비관계형 데이터베이스(NoSQL)
-> Firebase 등
3.시계열 데이터베이스(TSDB, Time Series Database)
-> Influx DB 등
시계열 데이터베이스(TSDB, Time Series Database)- 시간에 따라 저장된 데이터(시계열 데이터)를 처리하기 위해 최적화된 데이터베이스
- 자세한 정보는 이곳에서 확인
- Influx DB
- 많은 쓰기 작업과 쿼리 부하를 처리하기 위해 2013년에 Go 언어로 개발된 오픈소스 시계열 데이터베이스
- Tick Stack(Telegraf + InfluxDB + Chronograf + Kapacitor)의 필수 컴포넌트 중 하나
- Restful API를 제공하고 있어 API 통신이 가능하다.
- 자세한 정보는 이곳에서 확인
⭐ 설치 및 사용
Docker를 이용한 Influx DB 설치

- Influx DB 홈페이지에 친절하게 설명이 잘 나와있다.

실행
- Docker의 Influx db 이미지를 검색하면 실행 하는 방법을 알려준다.

$ docker run \
-p 8086:8086 \
-v myInfluxVolume:/var/lib/influxdb2 \
influxdb:latest
- 기본적으로 8086:8086 port를 사용한다.
- 아이디와 비밀번호, 조직명과 버킷의 초기이름을 설정한다.
(필자는 조직명과 버킷 이름을 test로 통일했다.)❗ 완료되면 새로 토큰을 발급해줄텐데 그것을 꼭 저장해두어야한다.

사용
- 모든 설정이 완료되면 열리는 페이지에서 좌측 상단에서 3번째 아이콘(data explorer)을 들어간다.
- 이 화면에서 우린 만들어둔 버킷인 test를 사용한다. 그리고 이곳에 script로 입력할 dummy data가 필요한데 이것을 따로 준비했다.

- Influx DB에서 바로 사용할 수 있도록 만들어진 더미 데이터 중 하나다.
- 다른 더미 데이터들도 여기서 확인할 수 있다.
import "influxdata/influxdb/sample"
option task = {
name: "Collect NOAA NDBC sample data",
every: 15m,
}
sample.data(set: "noaa")
|> to(bucket: "example-bucket")
- 버킷 부분만 나의 버킷 이름을 넣고
RUN을 누르면 저장된 데이터를 모두 불러온다. - 시계열 데이터는 물론, measurement와 station 관련 데이터 등이 저장되어 있음을 확인할 수 있다.
🔷 그렇다면 그래프는?
Flux라는 언어를 사용한 쿼리문을 사용하면 그래프를 그릴 수 있다.
(위에서 샘플 데이터를 불러올 때 사용한 것이 그것이다.)
import "experimental/aggregate"
import "influxdata/influxdb/sample"
option task = {
name: "Collect USGS sample data",
every: 15m,
}
sample.data(set: "usgs")
|> to(bucket: "test")
|> range(start: 2023-04-20T00:00:00.000Z, stop: now())
|> filter(fn: (r) => r._measurement == "earthquake")
|> filter(fn: (r) => r._field == "depth")
|> group(columns: ["depth"], mode: "by")
|> aggregateWindow(every: 1h, fn: max)
|> map(fn: (r) => ({_value: r._value, _time: r._time, _field: "발생 깊이"}))
- 불러온 지진 관련 샘플 데이터를 쿼리문을 통해 원하는 정보만 뽑아낼 수 있다.
range: 데이터를 확인할 시간 범위를 지정한다.filter: 'earthquake' measurement와 'depth' field를 지정하여 지진이 일어났을 때의 그 depth를 확인한다.group: "depth" 열에 해당하는 정보만 그룹화하여 볼 수 있다.aggregateWindow: 시간 간격과 함수를 지정하여 그래프로 보여주는데 여기서 함수를 max로 사용하면 그 시간 내의 최댓값을 표시하고 sum을 사용하면 그 시간 동안 관측된 값의 합계를 표시한다.map: 그래프에 표시할 것들 중 필드의 이름을 "depth"에서 "발생 깊이"로 바꾼다.

-
그래프 형식을 정하고 RUN을 누르면 추출한 데이터가 그래프로 시각화된다.
- 하지만 보기에도 불편하고 매번 쿼리문을 새로 작성하기가 참 번거롭다...
- 그래서 이 Influx DB에 들어온 데이터를 Grafana라는 시각화 도구를 사용하여 더 보기 좋은 형태로 만들 것이다.
📌 Grafana
⭐ Grafana란?
- 오픈소스 메트릭 데이터 시각화 도구
💡
메트릭(metric)
타임스탬프와 보통 한두 가지 숫자 값을 포함하는 이벤트- 서버 리소스의 매트릭 정보나 로그 같은 데이터를 시각화하는 데 많이 사용한다.
- 특정 수치 이상의 값이 들어올 때 알림을 받는 기능도 존재한다.
- 그라파나 공식 웹사이트
⭐ 설치 및 사용
Docker를 이용한 grafana 설치
docker run -d -p 3000:3000 grafana/grafana- 해당 명령어를 터미널에 입력하면 알아서 grafana의 image를 pulling하고 3000 port에서 실행 역시 가능하게 한다.
실행

- 그라파나를 실행하면 나오는 로그인 화면에서 초기 계정 이름과 비밀번호는
admin이다. - 로그인을 한 이후에 비밀번호를 바꾸는 화면이 등장하니 바꿔준다.

- 첫 메인화면에서 configration -> Data soureces -> Add data source를 클릭한다.

- Influx DB를 선택한다.

- Influx DB는 현재 Flux를 쿼리문으로 채택하고 있다고 언급했었다. 그래서 Flux로 선택한다.
- URL에는
http://host.docker.internal:8086을 입력한다.
❗ 아래 URL은 Influx DB를 열었던 포트번호가 들어간 URL을 입력할 수도 있다. (localhost:8086)
하지만 만약 위처럼 docker를 이용해 Influx DB를 빌드한 경우에는 localhost를 이용한 URL을 넣을 경우 다른 OS와의 호환이 되지 않기 때문에 읽어들이지 못한다. 비슷한 오류가 발생한 사람들은 참고하길 바란다.

- 다음으로 Auth Details에 Influx DB의 계정 ID와 password를 입력한다.
- 마지막으로 InfluxDB Details에 InfluxDB를 생성할 때 지었던 조직명과 디폴트 버킷명, 처음 저장했던 토큰을 입력한다.
- 그리고 Save&Test를 눌러 사진과 같은 표시가 나타나면 연동에 성공한 것이다.

- 다음으로 Dashboard를 생성한다.
- 본인이 직접 만들 수도 있지만
import를 통해 이미 제작된 탬플릿을 가져올 수도 있다.

- Grafana Labs에서 InfluxDB Metrics 탬플릿을 검색하면 이런 탬플릿이 나타난다. JSON파일을 다운받거나 대시보드 ID를 복사한다.

import-> 다운 받은 JSON파일을 넣거나 복사한 ID를 입력한다.

- Internal로 아까 생성한 InfluxDB를 지정하고 Import한다.

- 탬플릿이 정상적으로 잘 불러져왔다면 이번엔 우측 그래프+ 버튼을 눌러 Panel로 쿼리문을 넣어줄 차례다.
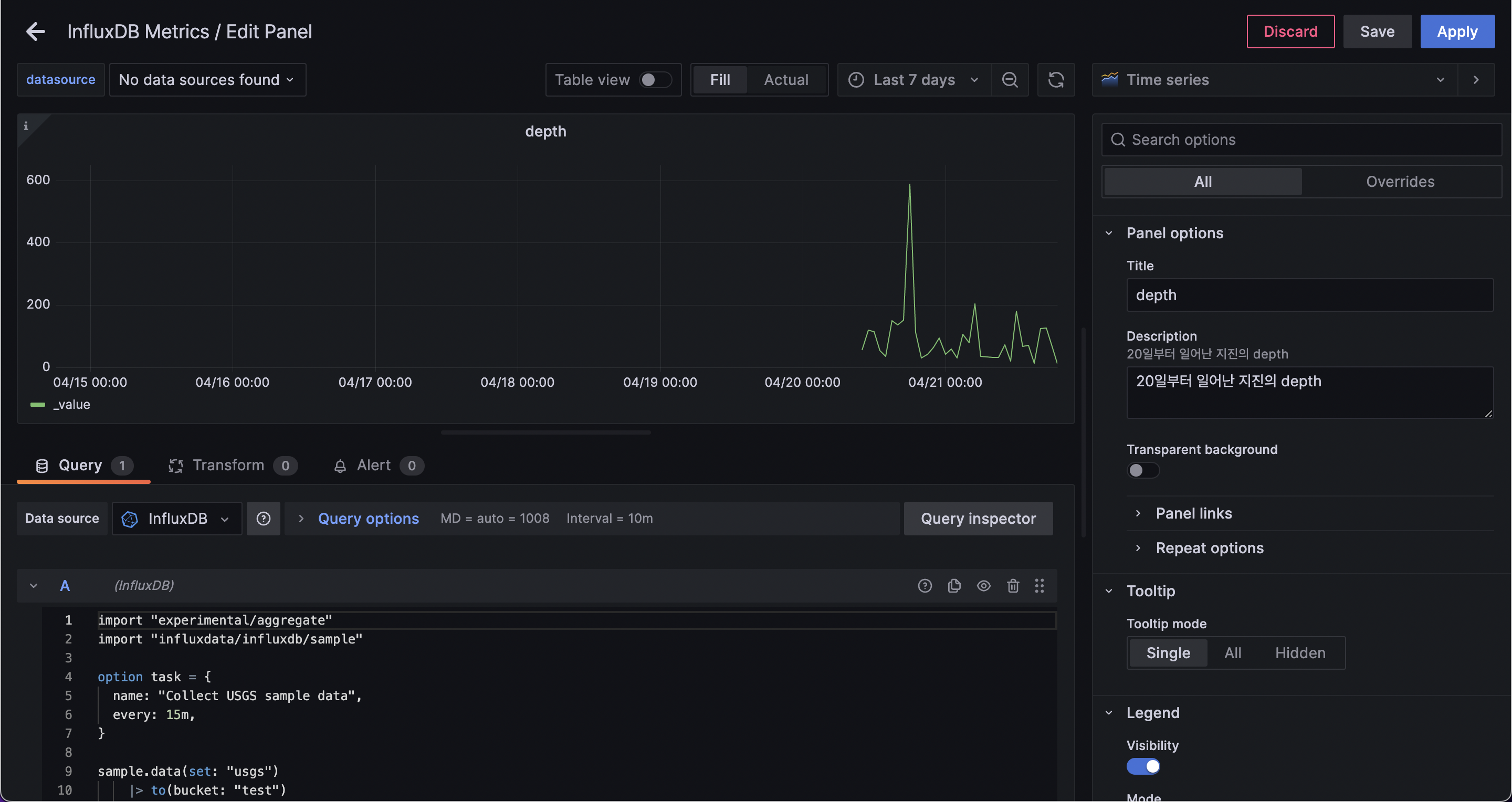
- 이전에 influx DB에서 그래프를 띄우기 위해 사용했던 쿼리문을 그대로 아래에 붙여넣기 한다.
- 위에서 Last 7 Days로 지정하고 기다리면 그래프가 빌드된다.
- 쿼리문에서 20일 이후의 데이터만 보여달라고 했기 때문에 그 이전의 데이터는 그래프에 나타나지 않는 모습이다.

- 그리고 apply를 누르면 그대로 대시보드에 나타난다.
- 이런 식으로 import한 탬플릿 내에서도 새로 생성할 수 있다.
- 알맞는 탬플릿을 골라 기존의 패널들을 입맛에 맞게 수정하여 사용하거나 추가하는 것이 좋다.

Hodie mihi, Cras tibi