배경
회사에서 한달치의 엑셀 데이터를 한번에 업로드하는 기능을 구현하였다.
초기에는 Batch INSERT 방식을 통해 데이터를 삽입하였다. 하나의 SQL 문으로 여러행을 삽입할 수 있었고 초기에는 충분히 빠르게 작동했었다.
그런데 해당 서비스 특성 상, 한달치 데이터의 양이 점진적으로 늘어나는 구조였고, 점점 처리속도가 느려졌다.
검색을 통해, 속도 저하의 원인이 SQL 문 실행 시 파싱에 대한 오버헤드임을 파악하였고,
파싱 오버헤드가 없는 Postgres의 COPY 로 대체하여 약 140%로 처리 속도를 감축하였다. (4000개 데이터 기준)
이번 글에서는 해당 문제 해결 과정에서 학습한 내용들을 정리하고자 한다.
개요
우선 Batch INSERT 문과 COPY문에 대해 간단한 설명을 하고 넘어가겠다.
Batch INSERT문
INSERT INTO … VALUES … 의 형식을 갖추고 있다.
values 절에 여러 개의 행 데이터를 넣으면, 여러개의 행을 한번에 삽입할 수 있다.
COPY문
PostgreSQL 전용 기능으로, 대용량 데이터를 한번에 처리할 때 사용한다.
파일이나 스트림에서 데이터를 불러와, 테이블에 삽입하거나 테이블의 데이터를 파일로 내보낼 때 사용된다.
테이블 삽입 예시
COPY employees (employee_id, name, department_id, hire_date)
FROM '/tmp/data.csv'
DELIMITER ','
CSV HEADER;참고
DELIMITER ’,‘: 필드의 구분자로,를 쓰겠다는 뜻CSV: 파일형식이 CSV임을 나타냄.HEADER: 맨 첫줄은 필드가 아닌 헤더임으로, 첫줄을 읽지 않도록 설정.
또는
COPY my_table (col1, col2) FROM STDIN WITH (FORMAT CSV);테이블을 파일로 내보내기 예시
COPY employees
TO '/employees_backup.txt'
WITH (DELIMITER E'\t');참고
WITH (DELIMITER E'\t'): 필드간의 구분은\t(탭) 으로 하겠다는 뜻
지금은 COPY와 INSERT 문을 비교할 것이기 때문에, 테이블 삽입에 대한 내용만 다룰 것이다.
비교 실험
대용량 데이터 처리 시, Batch INSERT문보다 COPY문이 더 빠른 속도를 보인다.
실험을 통해 속도 차이를 확인해보자.
실험 내용은 간단하다.
같은 개수의 데이터를, Batch INSERT로 삽입했을 때의 시간과
COPY문으로 삽입하였을 때의 시간을 비교한다.
코드는 아래와 같다.
코드
import psycopg2
import time
from io import StringIO
# 1. DB 연결 설정
conn = psycopg2.connect(
host="127.0.0.1",
database="pg-test",
user="jeongyun",
password="jeongyun",
port="5434"
)
# 테스트 데이터 생성 함수 (5,000개)
def generate_data(num_rows):
data = []
for i in range(1, num_rows + 1):
data.append({
'value1': f'TestValue_{i}',
'value2': i * 10
})
return data
NUM_ROWS = 5000 # 10,000개, 50,000개 바꿔가며 테스트
test_data = generate_data(NUM_ROWS)
# --- 1. 배치 INSERT 테스트 ---
def test_batch_insert(data, connection):
with connection.cursor() as cur:
# 트랜잭션 시작
cur.execute("BEGIN;")
# 튜플 리스트로 변환
insert_values = [(item['value1'], item['value2']) for item in data]
# VALUES (...), (...), (...) 형태의 배치 SQL 생성
placeholders = ', '.join(['%s'] * len(insert_values[0]))
query = f"INSERT INTO test_data (value1, value2) VALUES ({placeholders})"
# executemany를 사용하여 내부적으로 배치 INSERT를 시도 (드라이버 최적화)
start_time = time.time()
cur.executemany(query, insert_values)
end_time = time.time()
cur.execute("COMMIT;")
return end_time - start_time
# --- 2. COPY FROM STDIN 테스트 ---
def test_copy(data, connection):
with connection.cursor() as cur:
# 1. 데이터 문자열 생성 (CSV 형태)
csv_data = StringIO()
for item in data:
# COPY는 필드 순서와 정확히 일치하는 문자열이 필요
csv_data.write(f"{item['value1']},{item['value2']}\n")
csv_data.seek(0)
# 2. COPY 실행
start_time = time.time()
cur.copy_from(
csv_data,
'test_data',
columns=('value1', 'value2'),
sep=','
)
end_time = time.time()
connection.commit()
return end_time - start_time
# --- 테스트 실행 및 결과 출력 ---
# 테이블 초기화
with conn.cursor() as cur:
cur.execute("TRUNCATE TABLE test_data RESTART IDENTITY;")
conn.commit()
# 배치 INSERT 실행
batch_time = test_batch_insert(test_data, conn)
# 테이블 초기화
with conn.cursor() as cur:
cur.execute("TRUNCATE TABLE test_data RESTART IDENTITY;")
conn.commit()
# COPY 실행
copy_time = test_copy(test_data, conn)
print(f"--- {NUM_ROWS}개 데이터 로드 결과 ---")
print(f"1. 배치 INSERT 시간: {batch_time:.4f} 초")
print(f"2. COPY FROM STDIN 시간: {copy_time:.4f} 초")
print(f"\nCOPY가 배치 INSERT보다 약 {(batch_time / copy_time):.2f}배 빠릅니다.")
conn.close()결과
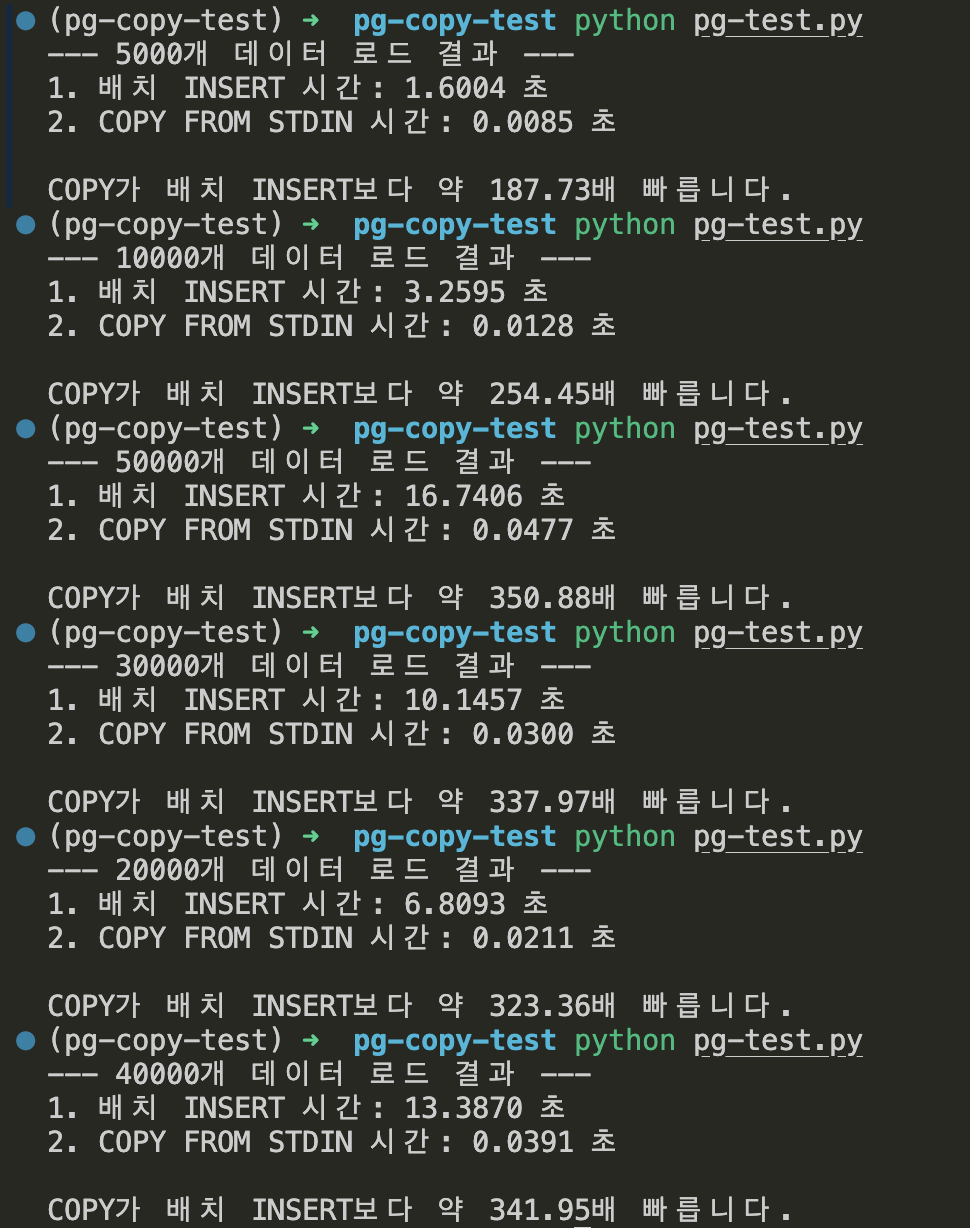
5,000-10,000-50,000-30,000-20,000-40,000 순
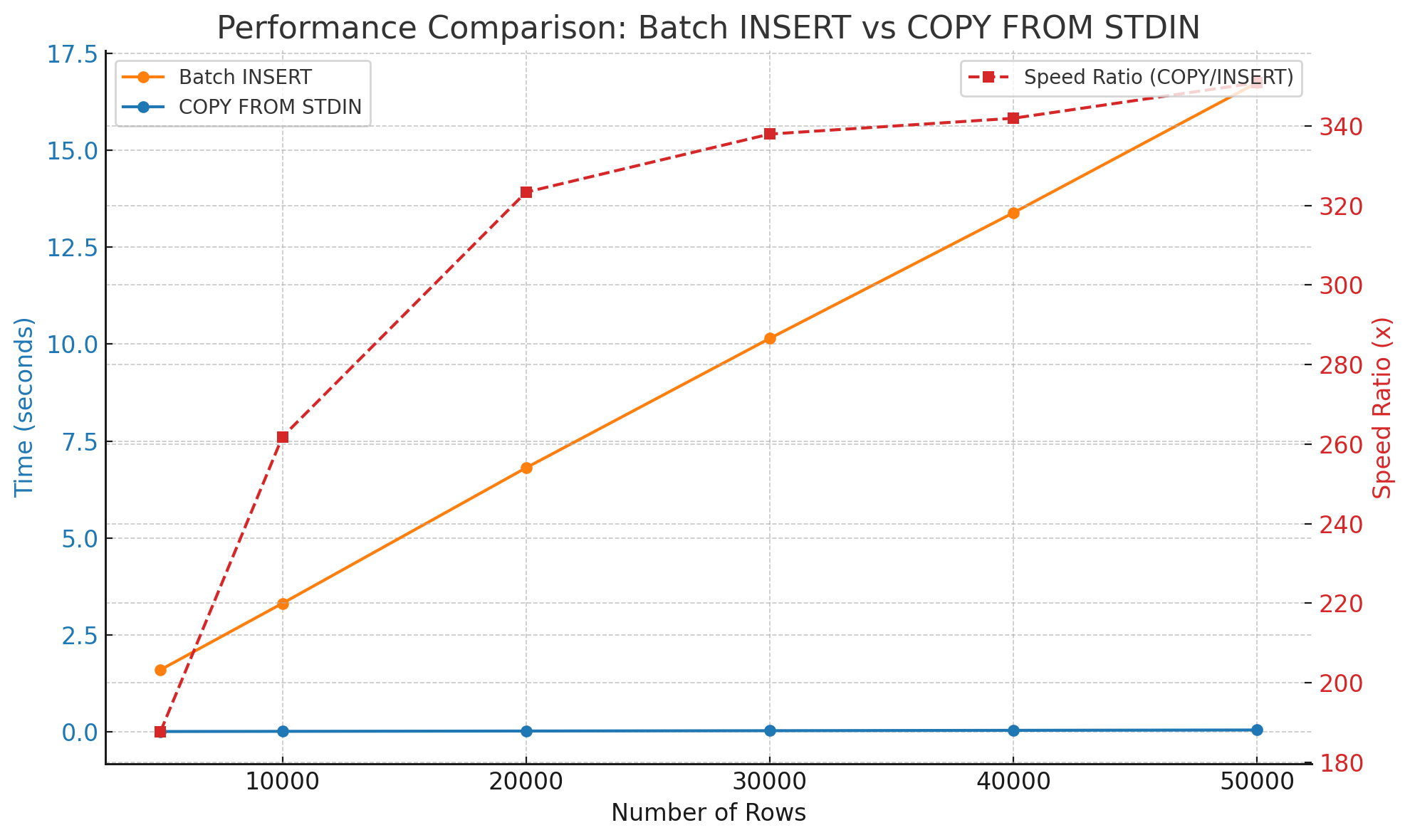
| 데이터 개수 (rows) | 배치 INSERT 시간 (초) | COPY FROM STDIN 시간 (초) | 속도 비율 (COPY/INSERT, 배) |
|---|---|---|---|
| 5,000 | 1.6004 | 0.0085 | 187.73 |
| 10,000 | 3.3135 | 0.0127 | 261.81 |
| 20,000 | 6.8093 | 0.0211 | 323.36 |
| 30,000 | 10.1457 | 0.0300 | 337.97 |
| 40,000 | 13.3870 | 0.0391 | 341.95 |
| 50,000 | 16.7406 | 0.0477 | 350.88 |
INSERT 문과, COPY 문 모두 데이터 개수에 비례하게 속도가 증가하긴 하나, 증가폭은 INSERT 문이 현격히 높은 것을 알 수 있다.
둘다 하나의 SQL인데, 왜 COPY가 더 빠를까?
그 이유를 알기 위해서는 SQL의 실행과정을 알아야 한다.
해석
SQL 문의 실행과정
여타 언어와 같이, SQL도 결국 일종의 명령어다.
명령어는 해석이 되어야 한다.
SQL은 아래와 같이 네 단계를 거쳐 해석된다.
- 파싱 단계
- SQL문을 토큰 단위(ex.
SELECT,*,FROM,table_name등)로 자르는 Lexing 단계를 거쳐, - 토큰들을 조합하여 문법에 맞는지 확인 후, Parse Tree를 만든다.
- SQL문을 토큰 단위(ex.
- 분석 단계
- 의미 확인 : SQL 문에서 사용된 테이블명, 함수명 등이 실제로 시스템 상에 존재하는지 확인하고,
- 권한 확인 : 해당 명령어를 사용할 수 있는 권한이 있는지를 확인하며,
- 쿼리 정규화 : 테이블 명을 DB 내부 id로 대체하는 등의 작업을 하여 parse tree → query tree 로 변환한다.
- 플래닝 단계
- 옵티마이저 실행: 인덱스 유무, 통계 정보 등을 고려하여 가장 비용이 적게 드는 Execution Plan을 생성한다.
- 실행 단계
- 플래닝 단계에서 생성한 Execution Plan대로 실행한다.
Batch INSERT 문의 경우, SQL문 자체가 굉장히 길어진다.
5,000개를 넣는다고 하면 VALUES 절 다음에 5,000개의 행에 대한 데이터 내용이 들어갈 것이고,
50,000개를 넣는다고 하면 VALUES 절 다음에 50,000개의 행에 대한 데이터 내용이 들어갈 것이다.
그말인 즉슨, INSERT 문을 사용할 경우, 데이터가 늘어날수록 데이터베이스 엔진이 파싱해야할 SQL양도 계속 늘어난다는 뜻이다.
반면, COPY의 경우, SQL 문은 데이터 개수와 관계없이
COPY test_data (value1, value2) FROM STDIN WITH (FORMAT CSV);
으로 고정이다.
데이터가 50,000개든 5,000,000개든 SQL 문 길이는 늘어나지 않는다는 말이다.
그렇기 때문에, COPY 문을 사용할 경우 SQL문 파싱에 드는 속도는 항상 동일하며, 데이터 양에 따라 데이터 스트리밍 시간만 변동되는 것이다.
정리
이번 글에서는 PostgreSQL에서 대용량 데이터를 삽입할 때 Batch INSERT와 COPY 방식 간의 성능 차이를 확인하고, 그 원인에 대해서 분석해보았다.
두 방식 모두 대량의 데이터를 저장하나,
Batch INSERT는 데이터가 많아질수록 SQL 문이 길어져, SQL 파싱에 많은 시간을 소요하는 반면,
COPY는 SQL 문이 고정된 형태로 유지되며 내부적으로 스트리밍 방식으로 데이터를 처리하기 때문에 SQL 파싱에 대한 오버헤드가 거의 없었다.
각 방식의 내부 동작 원리를 이해해야, 데이터 특성과 서비스 구조에 가장 적합한 접근 방식을 선택할 수 있다.
결국 핵심은 ‘되느냐’ 가 아니라 ‘왜 되느냐’ 임을 다시 한번 느낀다.
