
🔨 join데이터 얕은 object로 반환하기
sequelize의 find API에 include옵션을 설정해주면 테이블을 join할 수 있다.
하지만 이때 include에 작성된 테이블은 테이블 명의 객체안에 정의되어 반환된다.
프론트엔드 개발자가 간단한 데이터인데 Object가 너무 깊게 정의되어 있으면 사용하기가 어려울 것이다.
다음 예시를 한번 보자.
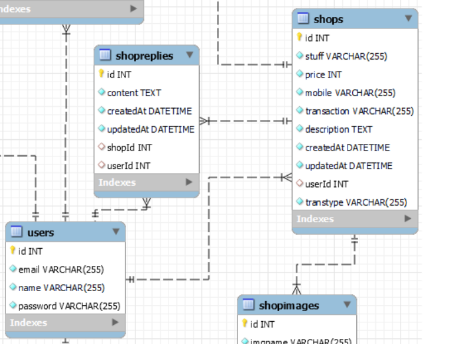
users는 shops와 일대다 연결을 이루고 있다.
return Shop.findOne(
attributes: ["id", "createdAt"],
include: {
model: User,
{ model: User, attributes: ["name"] },
},
});이와 같은 코드를 작성하여 쿼리를 날리면
{
id : ***,
createdAt : ***,
user : { name : ***}
}이렇게 데이터가 반환된다.
프론트엔드에서는 imgname에 접근하려면
const data = response.json()
const username = data.user.name이런식으로 객체 안의 객체안의 변수를 조회해야 한다.
백엔드에서 조금만 코드를 추가해주면 객체의 깊이를 줄여줄 수 있다.
return Shop.findByPk(id, {
attributes: {
include: ["id", "createdAt", [sequelize.col("user.name"), "username"]],
},
include: [
{ model: User, attributes: [] },
],
});User를 join한 데이터는 attributes를 빈 배열로 할당하여 반환데이터에 추가하지 않았다.
대신 Shop의 attributes 옵션에 [sequelize.col("user.name"), "username"]를 넣어 user.name을 username이라는 이름에 객체에 값을 할당하여 반환한다.
{
id : ***,
createdAt : ***,
username : ***,
}이제 최종 반환되는 데이터는 이렇게 깊지 않은 Object가 될 것이다.
🔨 join&order&group 한 번에 날리기
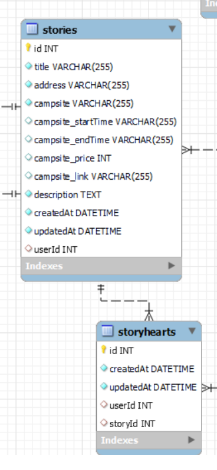
story가 있고 storyHeart는 story에 종속된 자식테이블로 이루어진 구조이다.
이 테이블로부터 내가 원하는 것은 storyHeart가 많이 존재하는 순, 그리고 그 수가 같을 경우엔 createdAt이 높은 순 즉 먼저 생성된 순으로 정렬된 데이터였다.
join, group, order 옵션을 설정하여 테이블을 JOIN하고 GROUP BY한뒤 ORDER함수로 정렬이 된 데이터를 조회했다.
return Story.findAll({
attributes: ["title", "address", "id", "createdAt"],
include: {
model: StoryHeart,
attributes: [],
},
group: "id",
order: [
[sequelize.fn("COUNT", sequelize.col("storyhearts.id")), "DESC"],
["createdAt", "DESC"],
],
});먼저 include옵션을 설정해줌으로써 join을 해주었다.
그리고 Group by의 기준을 story의 id로 잡아주면 그에 join된 storyHeart 데이터들이 하나로 그룹핑된다.
마지막으로 order옵션에 [기준, 정렬방향]을 우선순위 순으로 적어준다.
이때 COUNT 함수는 sequelize.fn()API를 사용해서 구현해줄 수 있다.
