1. Multi-GPU
-
오늘날의 딥러닝은 엄청난 데이터와의 싸움이다. 이러한 데이터가 많아질수록 모델을 학습하는 데 많은 시간이 걸린다.
-
이를 해결하기 위해, GPU를 여러개 사용한다.
-
다중 GPU에 학습을 분산하는 방법에는 두 가지 방법이 있다.
- 모델 나누기
- 데이터 나누기
1.1. Data parallel
-
데이터 병렬화는 데이터를 나눠 GPU에 할당 후 결과의 평균을 취하는 방법이다.
-
minibatch 수식과 유사한데 한번에 여러 GPU에서 수행한다.
-
수행 과정은 아래와 같다.
- 각각의 GPU에서 batch size만큼 데이터를 읽고, local gradients를 구한다.
- Global gradient는 local gradients를 평균을 내는데, 각 GPU를 동기화 하는 것이 필요하다.
- 모든 GPU에 올라가 있는 model을 업데이트한다.
- 1~3을 훈련이 끝날 때까지 반복한다.
- PyTorch에서는
DataParallel,DistributedDataParallel두 가지 방식을 제공한다.
1.1.1. DataParallel
-
DataParallel은 단순히 데이터를 분배한 후, 한 곳에 모아서 평균을 취한다.
-
GPU 한 곳에 모아서 평균을 취할 때 동기화를 해야하는데, Python의 garbage collection과 reference counting 등의 메모리 할당 방법으로 GIL(global interpreter lock)을 사용한다.
-
이러한 이유들로, GPU 사용 불균형 문제가 발생하고, 병목 현상이 발생한다.
1.1.2. DistributedDataParallel
- DistributedDataParallel은 각 CPU마다 process를 생성하여 개별 GPU에 할당한다.
1.2. Model parallelism
-
모델을 나누는 것은 예전부터(alexnet) 사용되었다.
-
batch size만큼 데이터를 GPU에 올리고, 조작하기에 모델이 너무 클 때 사용된다.
-
적어도, 모델에 대한 슈퍼클래스의 정의나 모델의 순서를 완전히 재정의해야 하기 때문에 구현하기 어렵다. 특히 multi-node(컴퓨터 여러대)에서 구현하기 어렵다.
-
그렇기 때문에, 메모리 점유(occupation) 문제를 해결하기 위해 다른 최적화 방법(Gradient Checkpointing, ZeRO of DeepSpeed, …)을 사용하는 것을 권장한다.
-
앞 순서의 모델 결과를 기다려야 하기 때문에, 모델 병렬화는 학습을 가속화 하지 못한다. 심지어, GPU 간 데이터를 전달하는 시간으로 약간 더 걸릴 수 있다.
-
데이터
파이프라인 기술: batch splitting을 사용하면, 프로세스 최적화를 통해 시간을 줄일 수 있다. -
대기 시간을 제한하고, CPU가 준동시에(quasi-simultaneously) 작동하도록 batch를 micro-batch로 나눈다. 하지만 여전히 약간의 대기 시간이 있다.
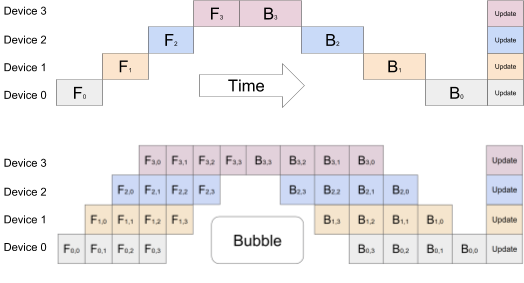
- 위 사진에서 batch를 4 micro-batches로 나눈 batch splitting을 볼 수 있다.
2. Hyperparameter Tuning
-
성능을 높이기 위한 방법으로 크게 3가지가 있다.
- 모델 바꾸기: 데이터에 따른 좋은 모델은 거의 정해져 있다.
- 데이터 바꾸기: 새로운 데이터 추가 및 기존 데이터 오류 제거
- Hyperparameter tuning
-
새로운 데이터를 추가하는 것이 모델 성능을 높이는 가장 좋은 방법이다. -
Hyperparameter는 모델 스스로 학습하지 않는 값으로, learning rate, 모델의 크기, optimizer 등이 있다.
-
Hyperparameter tuning은 마지막 0.01의 성능을 높이기 위해서 도전해볼만 하다.
0.01을 위해 여러 개의 GPU로 다시 모델을 학습시킨다...? → 중요성 낮아짐.
-
가장 기본적인 방법은 grid나 random으로 hyperparameter를 선택하는 것이다. 최근에는
베이지안 기반 기법들이 주도 한다. -
Hyperparameter Search를 위한 도구로
Ray를 추천한다. -
Ray는 multi-node multi processing을 지원하고, ML/DL의 병렬 처리를 위해 개발된 모듈이다. -
기본적으로 현재의 분산 병렬 ML/DL 모듈의 표준이다.
-
Tiny 모델을 위해 모델의 크기를 줄일 때, hyperparameter를 조정해 모델의 크기를 줄이기 전 성능과 유사하도록 할 때도 있다.
3. Trouble shooting
-
가장 많이 접하고 해결하기 어려운 오류는 OOM(out of memory)이다.
-
OOM은 대부분 반복문을 돌다가 발생하므로, 왜 발생했는지/어디서 발생했는지/이전 메모리 상황이 어떠한지를 파악하기 어렵다.
-
이를 해결하기 위한 간단하고 빠른 방법은 batch size를 줄이고 GPU를 초기화해서 돌리는 것이다.
-
GPUtil을 사용해 반복문을 시행하는 동안 GPU 상황을 살펴볼 수 있다.
-
반복문을 돌 때, 이전 캐시값을 지우기 위해
torch.cuda.empty_cache()를 사용할 수 있다. -
추론 시점에서는 torch.no_grad() 구문을 사용해 backward에 필요한 loss 값이 메모리 버퍼에 안 쌓이도록 할 수 있다.
-
tensor의 loat percision을 16bit로 줄여서 메모리를 확보할 수 있다. 하지만, 이것은 엄청 큰 사이크가 아니면 많이 사용하지 않는다.
-
OOM외에도 CNN 등에서 사이즈를 맞추지 않아 에러가 생길 수 있고 colab에서 너무 큰 사이즈를 실행해서 에러가 생길 수 있는데, 각 상황에 맞는 적절한 코드 처리가 필요하다.
References
