🔗 Schedule & Conflict Serialiability
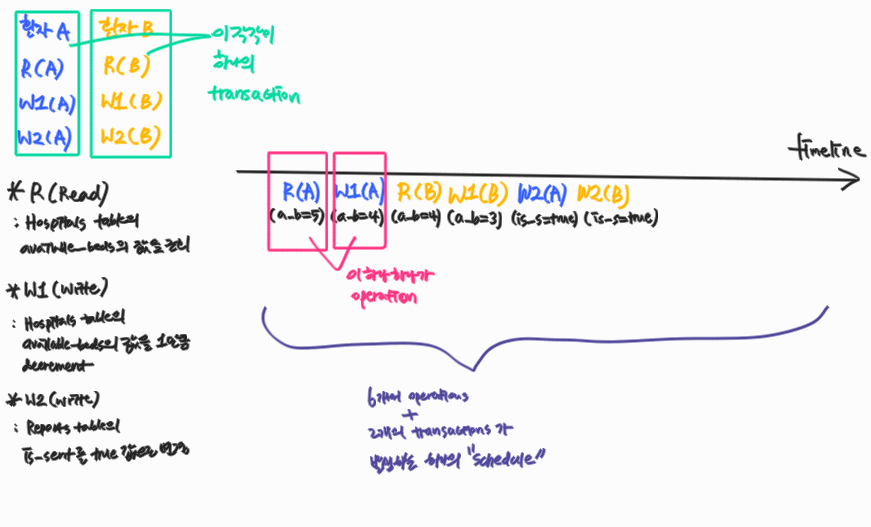
- Transaction: 환자 A, 환자 B가 각각 DB 접근을 하는 일련의 과정
- R (Read): Hospitals table의
available_beds의 값을 조회 - W1 (Write): Hospitals table의
available_beds의 값을 1만큼 decrement - W2 (Write): Reports table의
is_sent를true로 변경
- R (Read): Hospitals table의
- Operation: transaction에서 각각의 Read/Write를 수행하는 것
- Schedule: transaction들의 모든 operations들이 발생 순서대로 나열된 것
Schedule
여러 transaction들이 동시에 실행될 때 각 transaction에 속한 operation들의 실행 순서
-
각 tranaction 내의 operations들의 순서는 바뀌지 않는다.
-
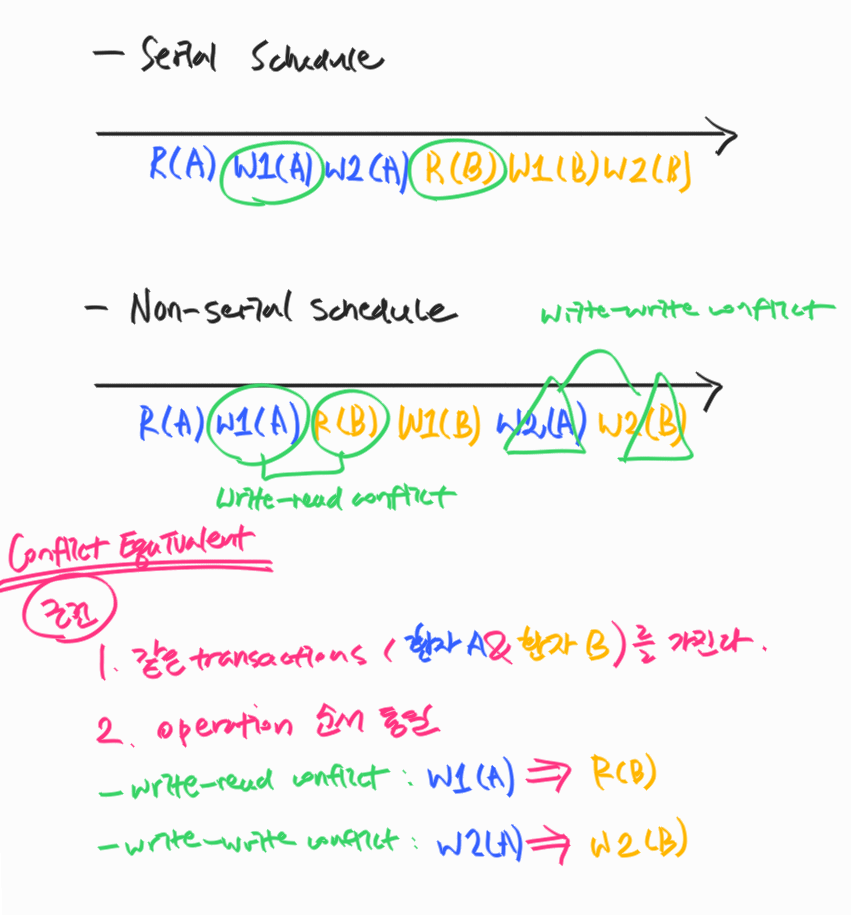
Serial Schedule: transaction들이 겹치지 않고 한 번에 하나씩 실행되는 schedule
- 한 번에 하나의 transaction만 실행되기 때문에 (동시성이 없음) 좋은 성능을 낼 수 없고, 현실적으로 사용할 수 없는 방식이다.
- Read, Write 작업은 I/O 작업이고, 새로운 transaction을 처리하는 것은 CPU 작업인데, serial schedule의 경우 하나의 transaction을 처리할 동안 다른 transaction을 처리하지 않기 때문에, 즉 CPU 작업은 아무것도 안하고 놀게되는 것이기 때문에 성능이 떨어진다.
-
Non-serial Schedule: transaction들이 겹쳐서 (interleaving) 실행되는 schedule
- transaction들이 겹쳐서 실행되기 때문에 동시성이 높아져서 같은 시간동안 더 많은 transaction들을 처리할 수 있다. 즉, 성능이 더 좋다.
- 한 transaction에 대한 I/O 작업을 하면서 CPU 작업이 놀지 않고 다른 transaction을 시작한다.

-
Non-serial Schedule의 문제점
transaction들이 어떤 형태로 겹쳐서 실행되는지에 따라 이상한 결과가 나올수 있다.
=> 고민거리: non-serial schedule로 실행해도 이상한 결과가 나오지 않을 수는 없을까?
=> 아이디어: serial schedule과 동일한 non-serial schedule을 실행하면 된다.
=> 이때 'schedule이 동일하다 (equivalent)'라는 것의 의미를 정의해야한다.
Conflict
두 개의 operations에 대해 세 가지 조건을 모두 만족하면 conflict라고 할 수 있다.
1. 서로 다른 transaction에 소속되어 있다.
2. 같은 데이터에 접근한다.
3. 최소 하나는 write operation이다. (read-write conflict or, write-write conflict)
- conflict operation은 순서가 바뀌면 결과도 바뀐다.
conflict equivalent
두 개의 schedules에서 두 조건을 모두 만족하면 conflict equivalent하다.
1. 두 schedules은 같은 transaction들을 가진다.
2. 어떤 (any) conflicting operations의 순서도 양쪽 schedule 모두 동일하다.
Conflict Serializability
serial schedule과 conflict equivalent할 때 conflict serializable하다.
- conflict serializable한 non-serial schedule은 우리의 문제점 (transaction들이 어떤 형태로 겹쳐서 실행되는지에 따라 이상한 결과가 나올수 있다)을 해결할 수 있다.
결론
동시성 제어는 어떤 (any) schedules도 serializable하게 만들 수 있다.
실제 구현
여러 transaction들을 동시에 실행해도 schedule이 conflict serializable하도록 보장하는 protocol을 적용
=> 이 protocol을 Lock & MVCC 등으로 만드는 것이다.
🔗 Recoverability
- 알아둬야할 것
- 이미 commit한 transaction은 durability 속성으로 인해 rollback할 수 없다.
- rollback을 하면 atomicity 속성으로 인해 마치 아무일도 일어나지 않은 것처럼 transaction 이전의 상태로 돌아간다.
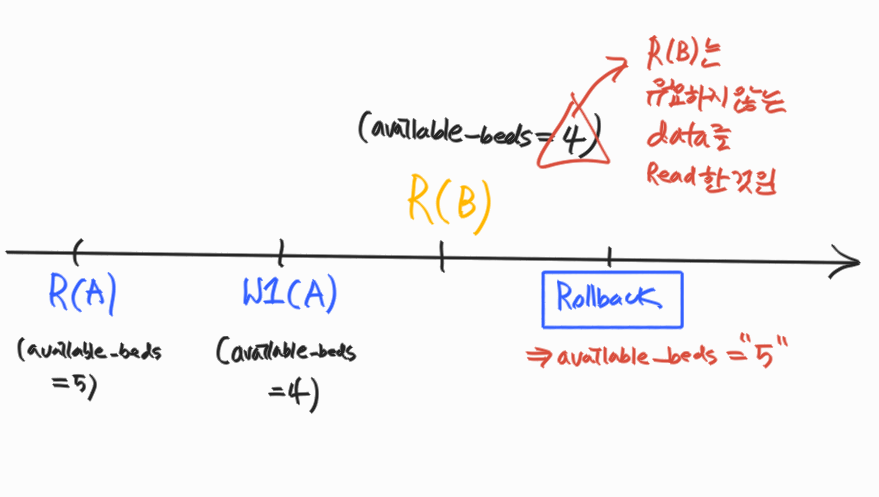
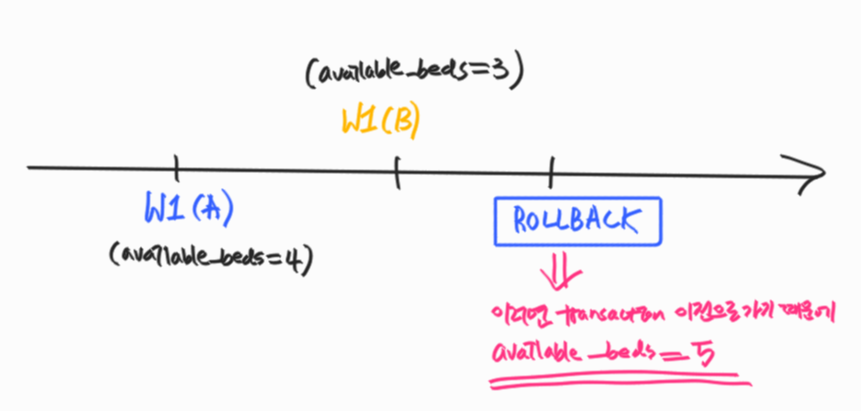
Unrecoverable Schedule
schedule 내에서 commit된 transaction이 rollback된 transaction이 write했었던 데이터 (유효하지 않은 데이터)를 읽은 경우
- rollback을 해도 이전 상태로 회복 불가할 수 있기 때문에 이런 schedule은 DBMS가 허용하면 안된다.
Recoverable Schedule
schedule 내에서 그 어떤 transaction도 자신이 읽은 데이터를 write한 transaction이 먼저 commit/rollback 전까지는 commit을 하지 않는 경우
- rollback을 할 때 이전 상태로 온전히 돌아갈 수 있기 때문에 DBMS는 이런 schedule만 허용하여야 한다.
Cascading Rollback
하나의 transaction이 rollback하면 의존성이 있는 다른 transaction도 rollback 해야한다.
- 문제점: 여러 transaction의 rollback이 연쇄적으로 일어나면 처리하는 비용이 많이 든다.
- 해결법: 데이터를 write한 transaction이 commit/rollback한 뒤에 데이터를 read하는 schedule만 허용하자 => cascadeless schedule
Cascadeless Schedule
schedule 내에서 어떤 (any) transaction도 commit되지 않은 transaction들이 write한 데이터는 read하지 않는 경우 = avoid cascading rollback
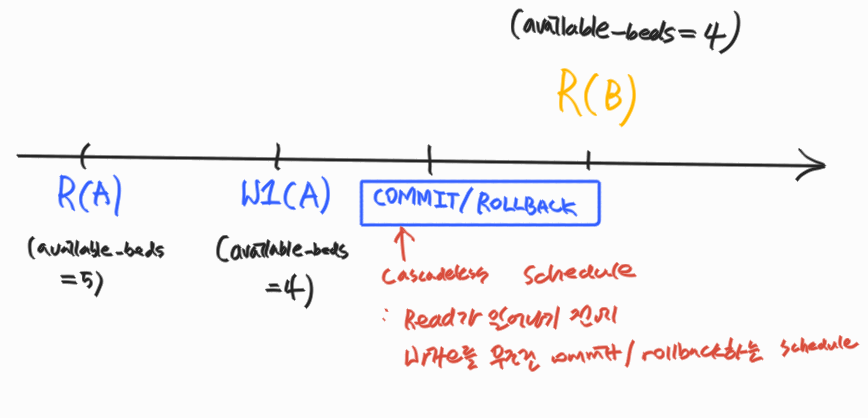
- 문제점: read가 발생하지 않고 write만 발생하는 schedule에서는 아예 cascadeless schedule이 적용 대상이 아니게 된다.
Strict Schedule
schedule 내에서 어떤 (any) transaction도 commit되지 않은 transaction들이 write한 데이터는 write도, read도 하지 않는 경우
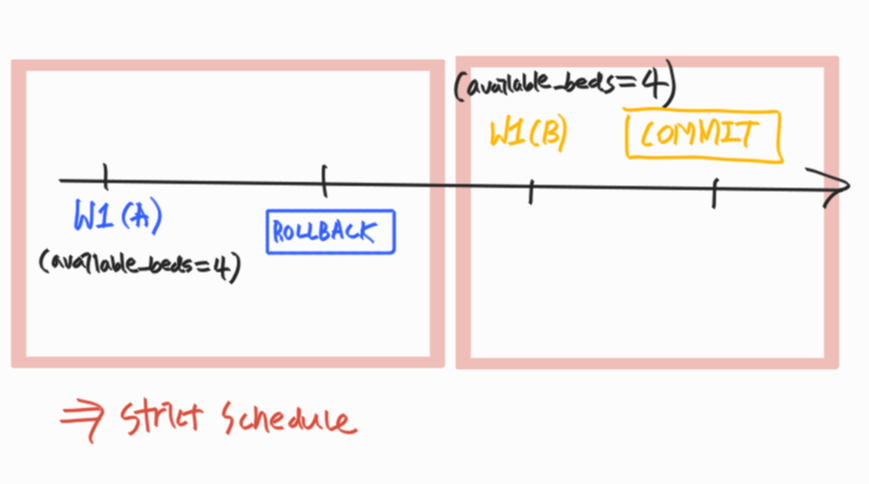
- 즉, 두 번의 write operation이 일어난다면, 무조건 하나의 write가 commit/abort 되고 다음 write를 수행해야한다.
- rollback할 때 recovery가 쉽다. transaction 이전 상태로 돌려놓기만 하면 된다.
