[DB] Normalization (정규화)
✂️ 정규화 (Normalization)란?
RDBMS 설계 과정에서 중복성과 비일관성을 제거하고 데이터를 구조화하는 방법으로, 데이터베이스의 효율성과 유연성 향상시킬 수 있다.
정규화가 필요한 이유
=> Anomaly (이상 현상)를 방지하기 위해
이상현상(Anomaly)의 종류
- 삽입 이상(Insertion Anomaly) : 튜플 삽입 시 특정 속성에 해당하는 값이 없어 NULL을 입력해야 하는 현상
- 삭제 이상(Deletion Anomaly) : 튜플 삭제 시 같이 저장된 다른 정보까지 연쇄적으로 삭제되는 현상
- 갱신 이상(Update Anomaly) : 튜플 갱신 시 중복된 데이터의 일부만 갱신되어 일어나는 데이터 불일치 현상
어떤 relation에 정규화를 해야할까?
정규화는 곧 "나쁜" relations의 attributes를 나누어서 "좋은" relations로 분해하는 것인데, 그럼 "나쁜" relations인지 어떻게 판단할 수 있을까?
이는 entity를 구성하고 있는 attribute 간에 함수적 종속성 (functional dependency)을 판단하여야 한다.
✂️ 함수적 종속성 (Funtional Dependency)이란?
X와 Y를 임의의 attributes 집합이라고 할 때, X의 값이 Y의 값을 유일하게 (unique)하게 결정한다면, X는 Y를 함수적으로 결정한다 (X -> Y).
즉, 어떤 속성 X의 값을 알면, 다른 속성 Y의 값이 유일하게 정해지는 관계를 종속성이라고 한다.
=> 테이블의 schema를 보고 의미적으로 (sementic) FD가 존재하는지 파악해야 한다.
예)
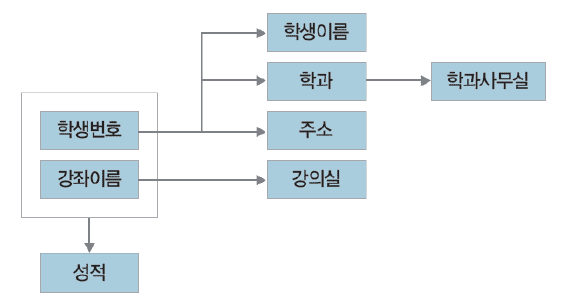
- 직사각형 => attributes
- 화살표 => FD
- 박스로 묶음 => 복합 속성 (X)
함수 종속성의 종류
✂️ 정규화 절차

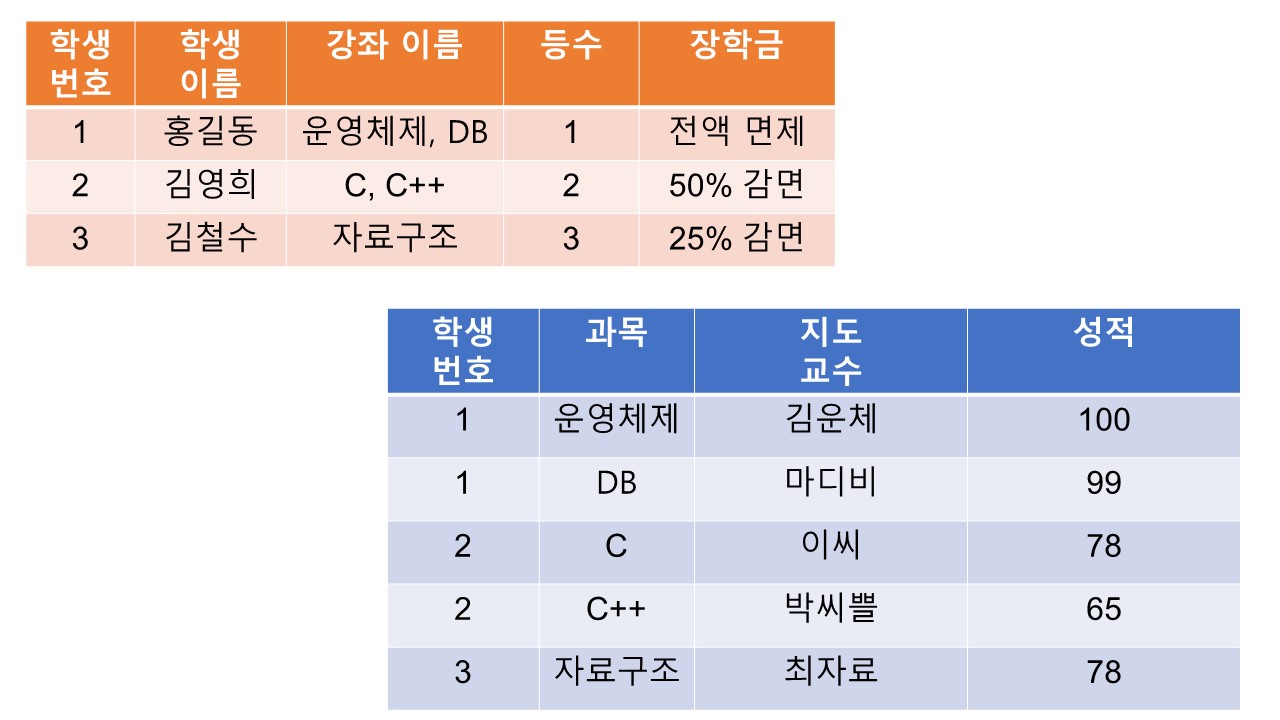
정규화 대상 테이블 예시
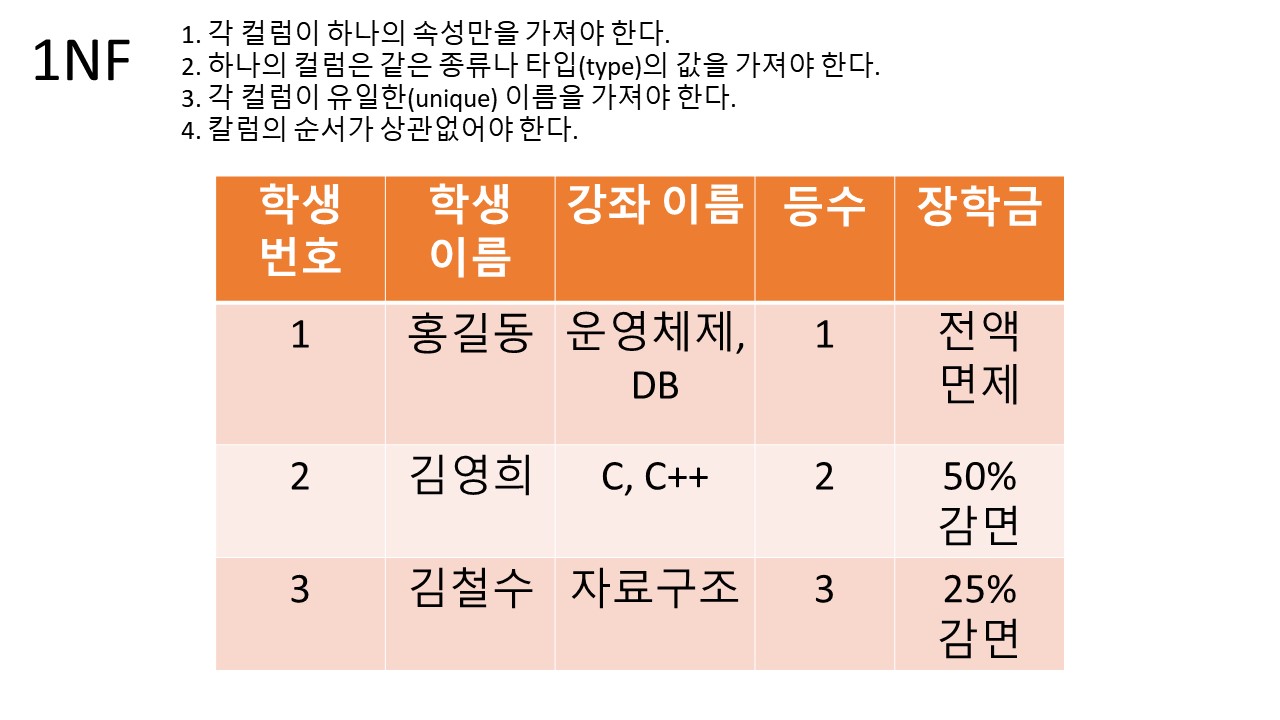
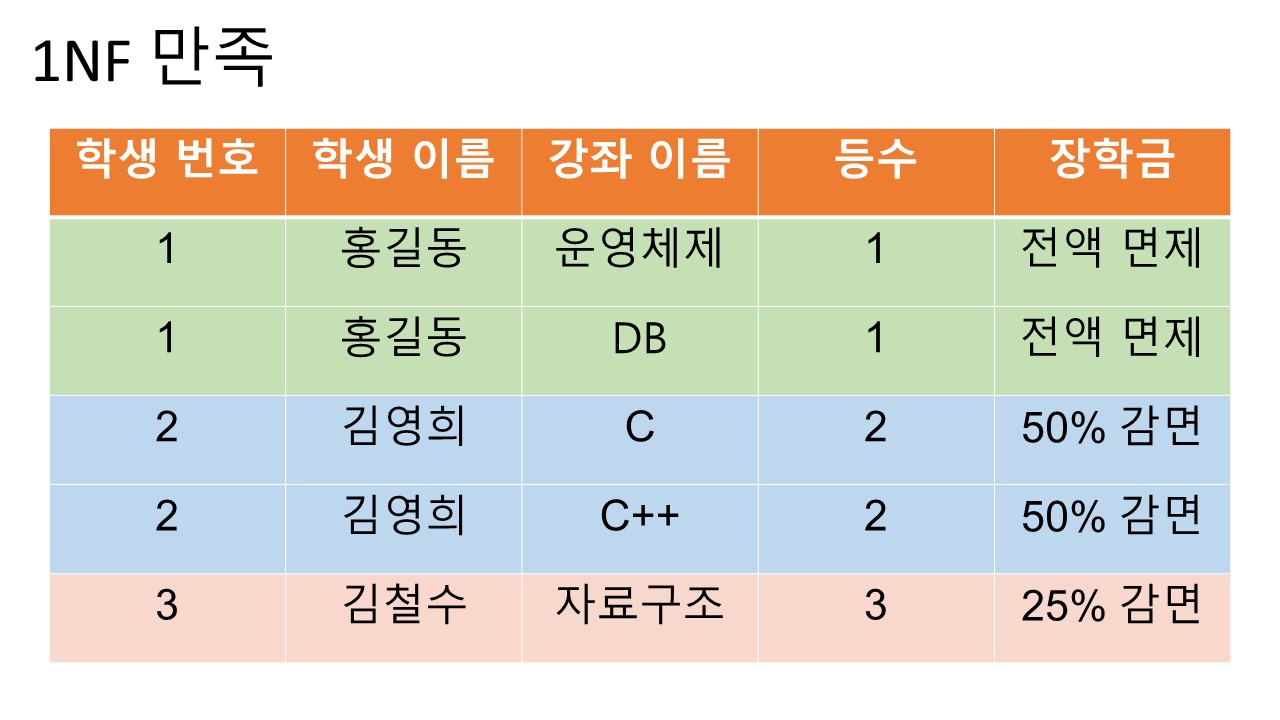
1. 1NF (1st Normal Form)
조건:
1. 각 컬럼이 하나의 속성만을 가져야 한다.
2. 하나의 컬럼은 같은 종류나 타입(type)의 값을 가져야 한다.
3. 각 컬럼이 유일한(unique) 이름을 가져야 한다.
4. 칼럼의 순서가 상관없어야 한다.
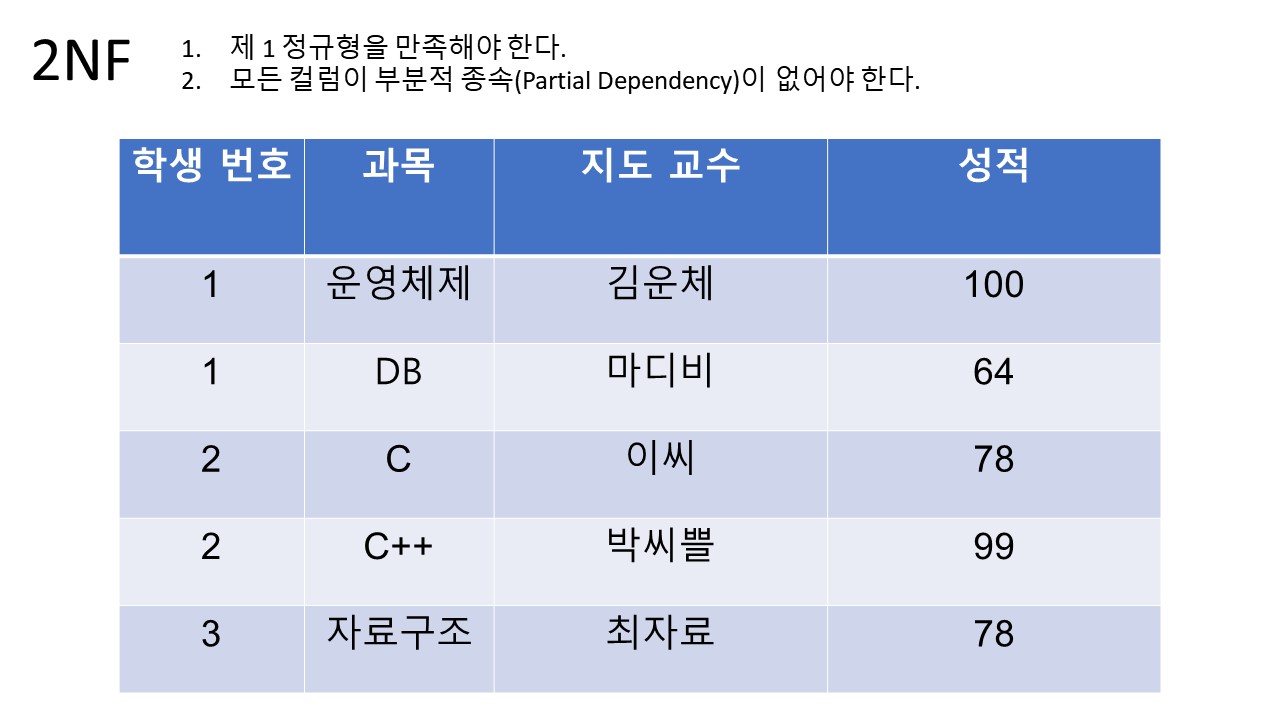
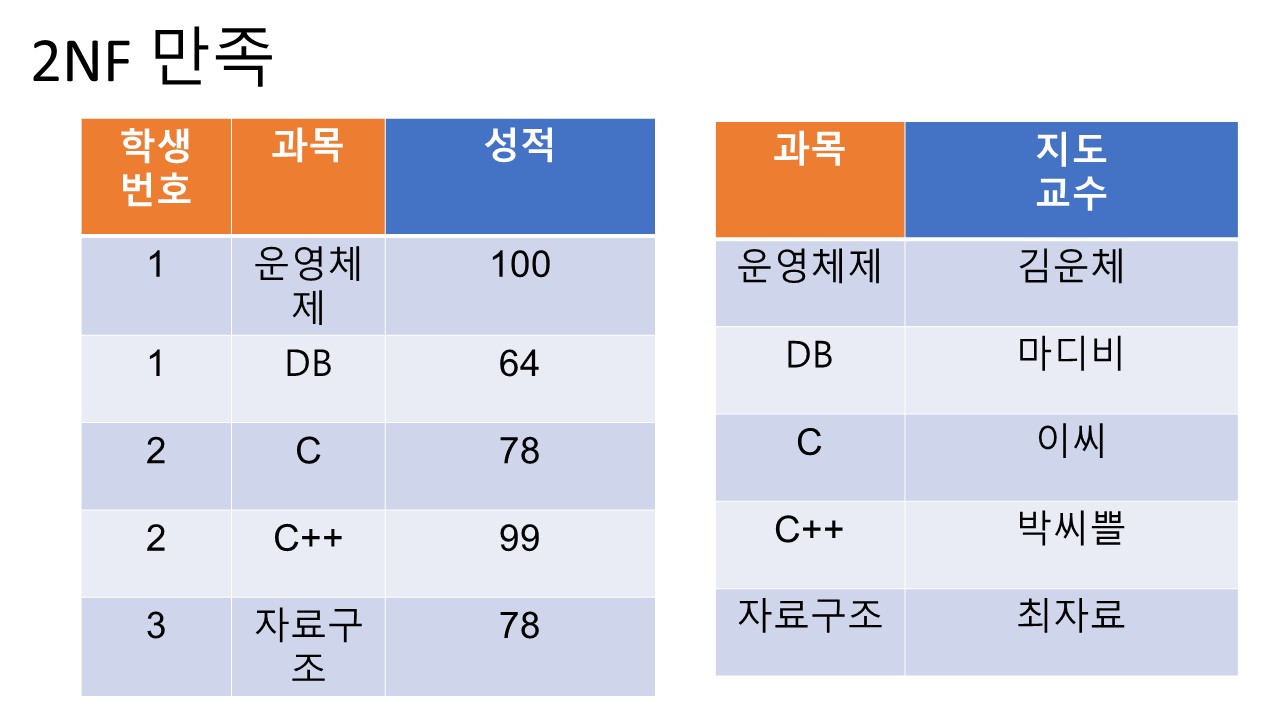
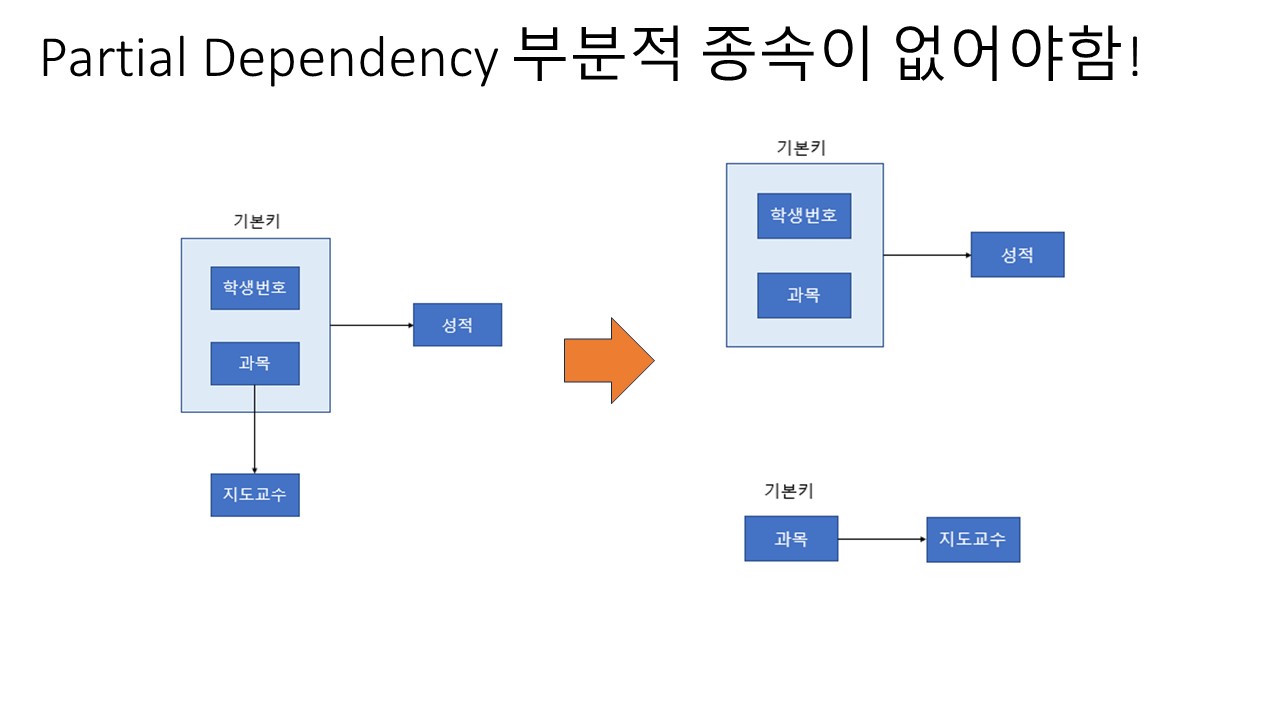
2. 2NF (2nd Normal Form)
조건:
1. 제 1 정규형을 만족해야 한다.
2. 모든 컬럼이 부분적 종속(Partial Dependency)이 없어야 한다. == 모든 칼럼이 완전 함수 종속을 만족해야 한다.

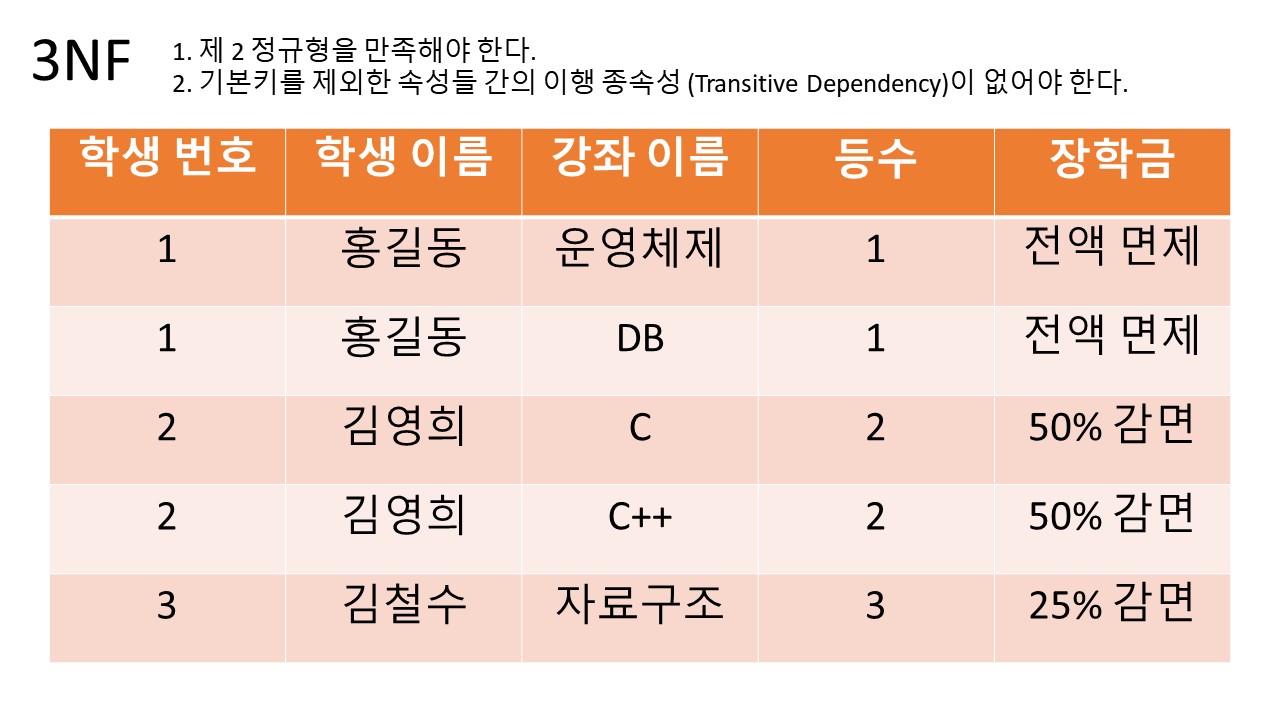
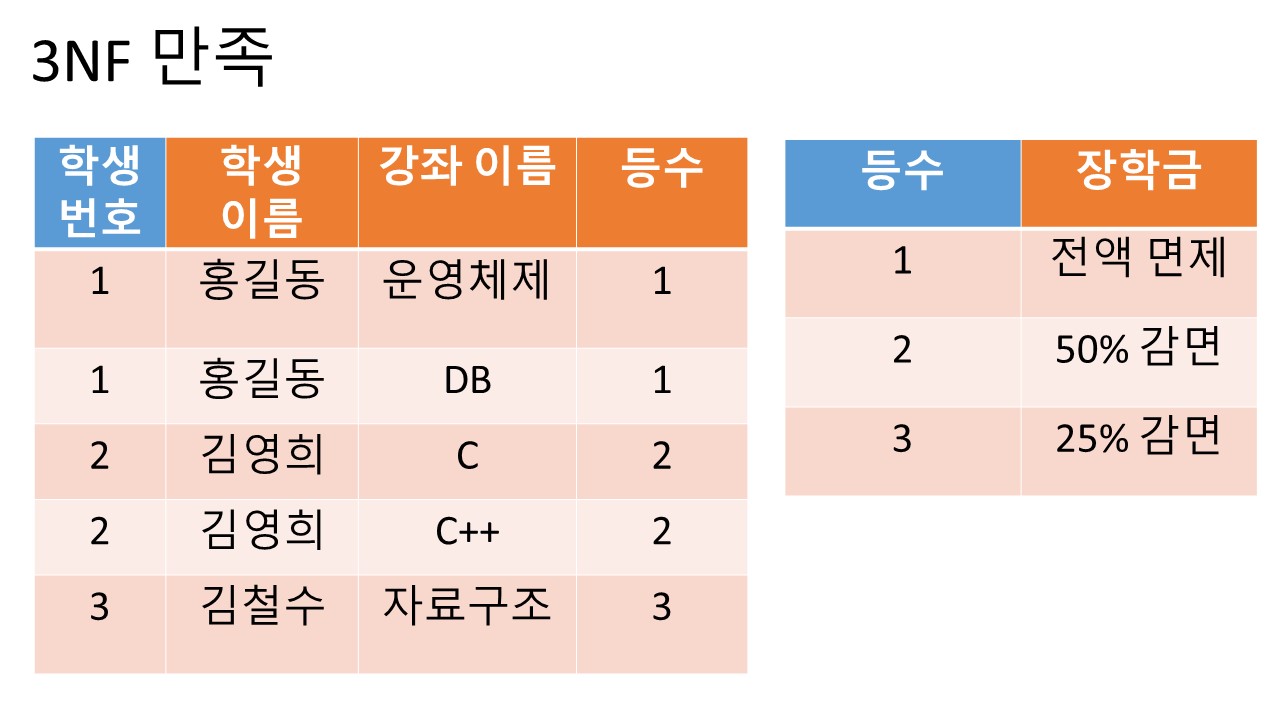
3. 3NF (3rd Normal Form)
조건:
1. 제 2 정규형을 만족해야 한다.
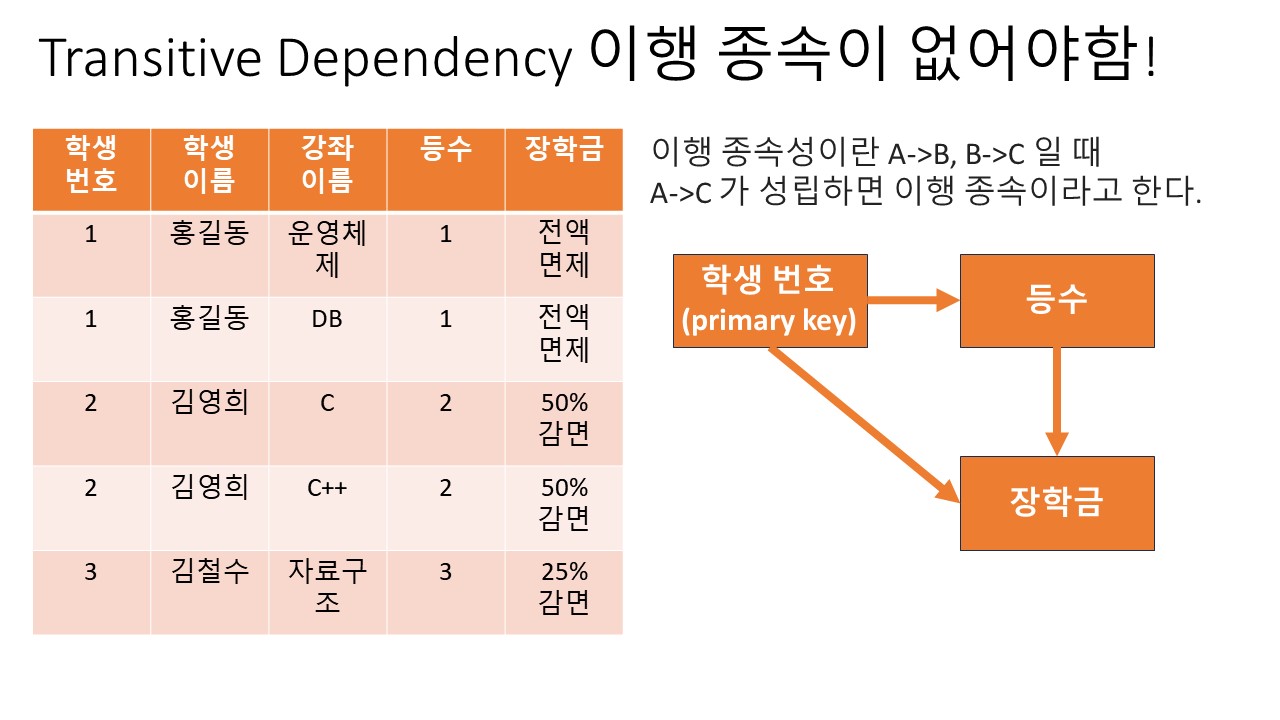
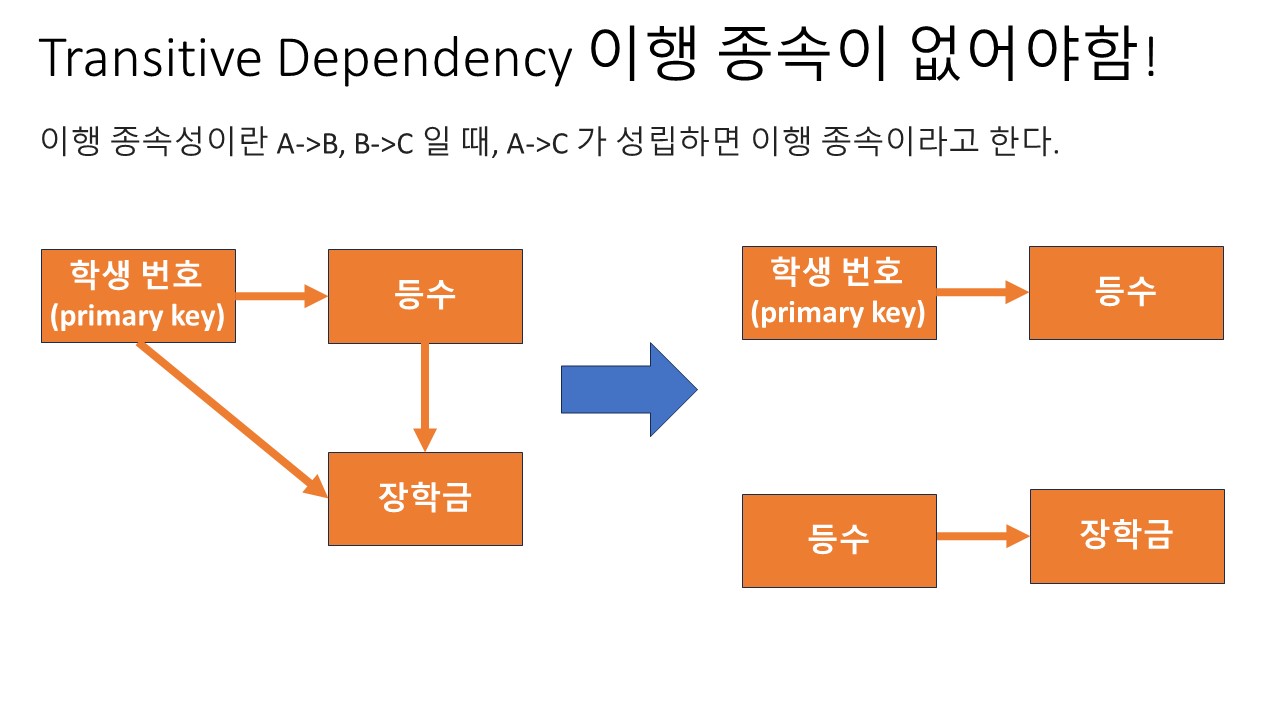
2. 기본키를 제외한 속성들 간의 이행 종속성 (Transitive Dependency)이 없어야 한다.
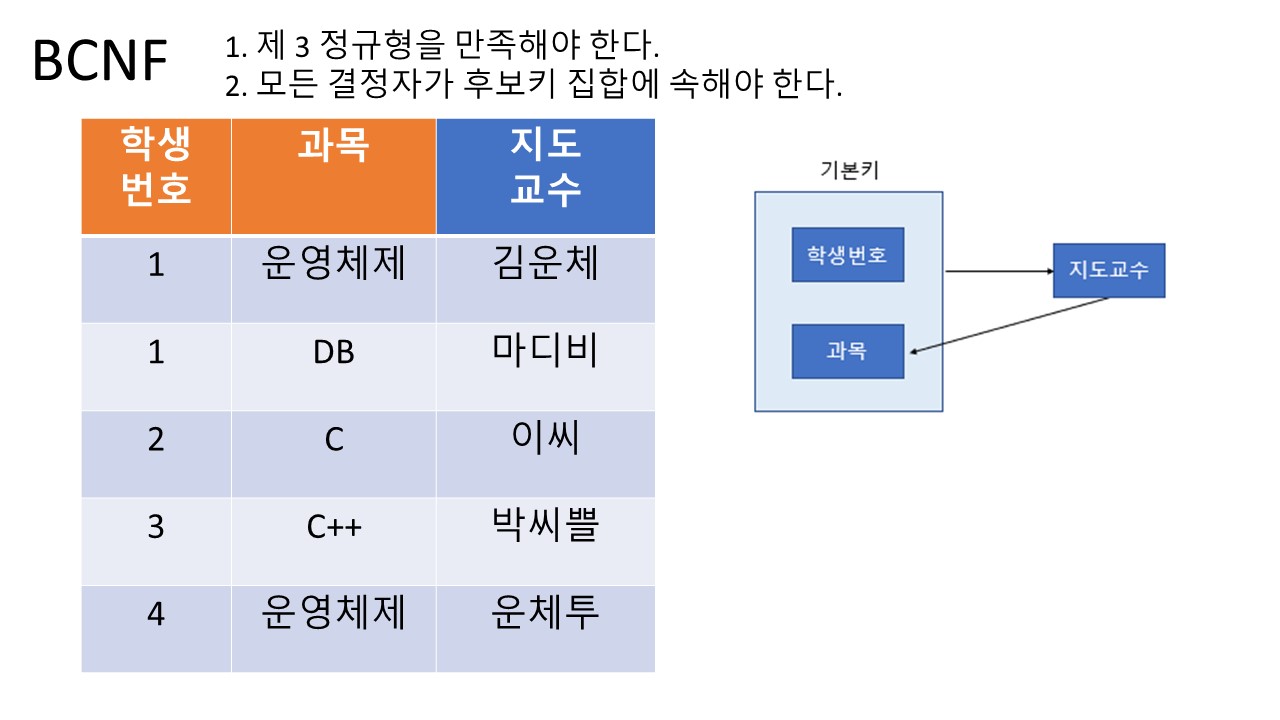
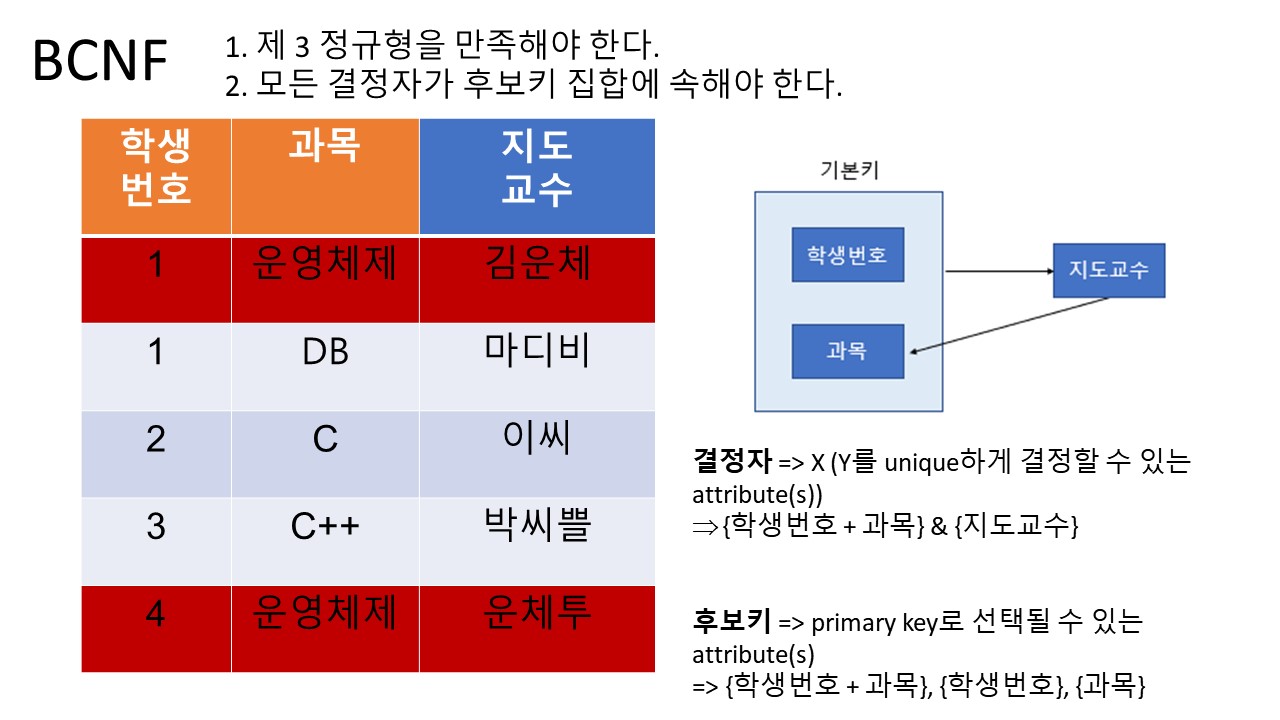
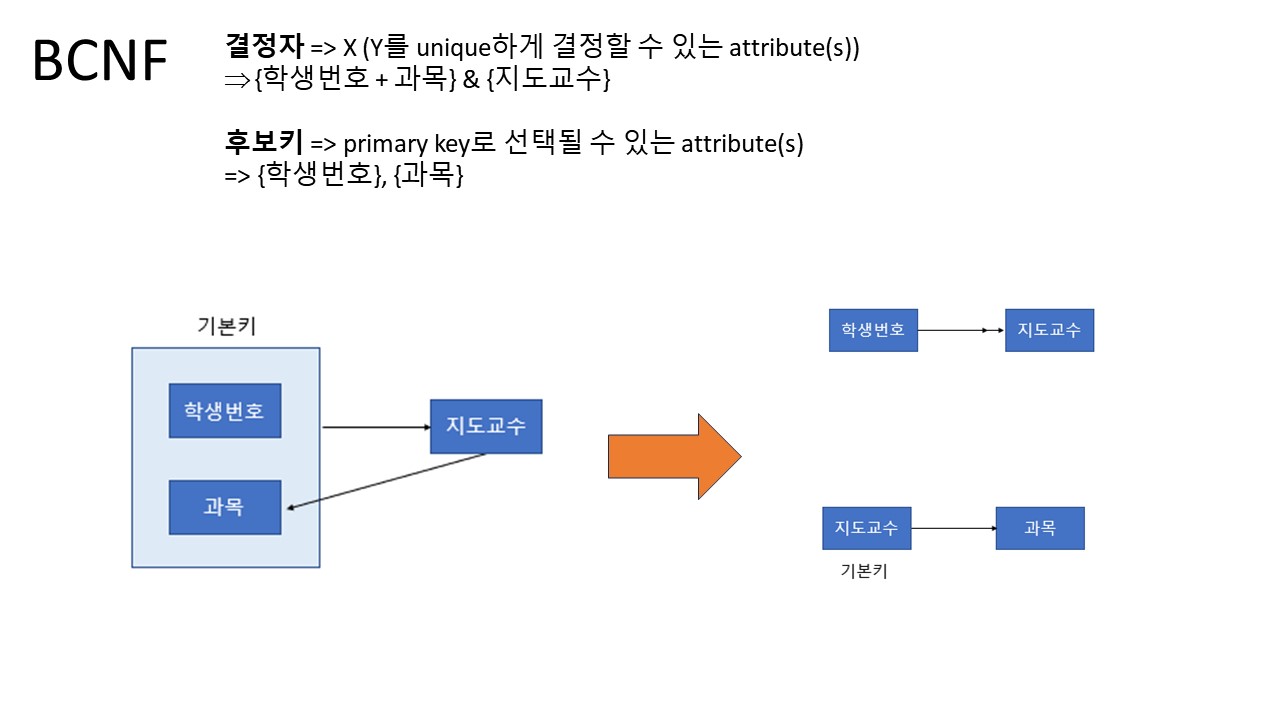
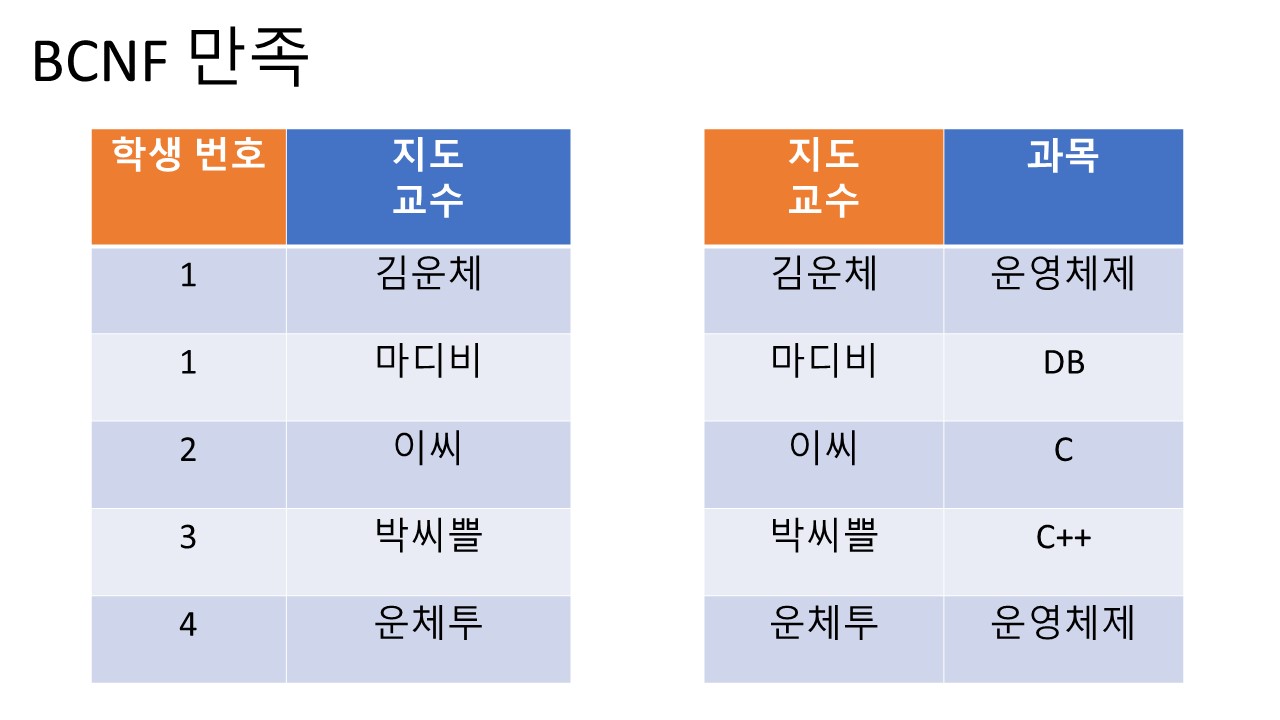
4. BCNF (Boyce-Codd Normal Form)
조건:
1. 제 3 정규형을 만족해야 한다.
2. 모든 결정자가 후보키 집합에 속해야 한다.
- 보통 3NF나 BCNF까지 정규화를 거친다. 그 이상의 정규화를 하면 정규화의 단점이 나타날 수 있다.
- 각각의 정규형은 무손실 JOIN을 보장해야 한다.
(무손실 JOIN: 두 개 이상의 테이블을 조인할 때, 조인 결과가 원본 테이블들의 정보를 완벽하게 보존하는 것)
✂️ 정규화 장단점
- 장점
- Anomaly 제거
- 재사용성: DB 구조 확장시 스키마 설계 구조를 변경하지 않아도 되거나 일부만 변경할 수 있다.
- 단점
- Relation 분해로 인해 JOIN 연산이 많아진다. => 응답 시간 느려짐
=> 조회하는 SQL 쿼리에서 JOIN이 많아서 성능저하가 발생하는 경우 반정규화를 적용하는 전략이 필요하다.
✂️ 반정규화 (De-normalization)
반정규화는 정규화된 엔티티, 속성, 관계를 시스템의 성능 향상 및 개발과 운영의 단순화를 위해 중복 통합, 분리 등을 수행하는 데이터 모델링 기법 중 하나이다. 디스크 I/O 량이 많아서 조회 시 성능이 저하되거나, 테이블끼리의 경로가 너무 멀어 조인으로 인한 성능 저하가 예상되거나, 칼럼을 계산하여 조회할 때 성능이 저하될 것이 예상되는 경우 반정규화를 수행하게 된다. 일반적으로 조회에 대한 처리 성능이 중요하다고 판단될 때 부분적으로 반정규화를 고려하게 된다.
어떤 경우 반정규화를 해야할까?
- 자주 사용되는 테이블에 액세스하는 프로세스의 수가 가장 많고, 항상 일정한 범위만을 조회하는 경우
- 테이블에 대량 데이터가 있고 대량의 범위를 자주 처리하는 경우, 성능 상 이슈가 있을 경우
- 테이블에 지나치게 조인을 많이 사용하게 되어 데이터를 조회하는 것이 기술적으로 어려울 경우
