문제 설명
나만의 카카오 성격 유형 검사지를 만들려고 합니다.
성격 유형 검사는 다음과 같은 4개 지표로 성격 유형을 구분합니다. 성격은 각 지표에서 두 유형 중 하나로 결정됩니다.
| 지표 번호 | 성격 유형 |
|---|---|
| 1번 지표 | 라이언형(R), 튜브형(T) |
| 2번 지표 | 콘형(C), 프로도형(F) |
| 3번 지표 | 제이지형(J), 무지형(M) |
| 4번 지표 | 어피치형(A), 네오형(N) |
4개의 지표가 있으므로 성격 유형은 총 16(=2 x 2 x 2 x 2)가지가 나올 수 있습니다. 예를 들어, "RFMN"이나 "TCMA"와 같은 성격 유형이 있습니다.
검사지에는 총 n개의 질문이 있고, 각 질문에는 아래와 같은 7개의 선택지가 있습니다.
매우 비동의비동의약간 비동의모르겠음약간 동의동의매우 동의
각 질문은 1가지 지표로 성격 유형 점수를 판단합니다.
예를 들어, 어떤 한 질문에서 4번 지표로 아래 표처럼 점수를 매길 수 있습니다.
| 선택지 | 성격 유형 점수 |
|---|---|
매우 비동의 | 네오형 3점 |
비동의 | 네오형 2점 |
약간 비동의 | 네오형 1점 |
모르겠음 | 어떤 성격 유형도 점수를 얻지 않습니다 |
약간 동의 | 어피치형 1점 |
동의 | 어피치형 2점 |
매우 동의 | 어피치형 3점 |
이때 검사자가 질문에서 약간 동의 선택지를 선택할 경우 어피치형(A) 성격 유형 1점을 받게 됩니다. 만약 검사자가 매우 비동의 선택지를 선택할 경우 네오형(N) 성격 유형 3점을 받게 됩니다.
위 예시처럼 네오형이 비동의, 어피치형이 동의인 경우만 주어지지 않고, 질문에 따라 네오형이 동의, 어피치형이 비동의인 경우도 주어질 수 있습니다.
하지만 각 선택지는 고정적인 크기의 점수를 가지고 있습니다.
매우 동의나매우 비동의선택지를 선택하면 3점을 얻습니다.동의나비동의선택지를 선택하면 2점을 얻습니다.약간 동의나약간 비동의선택지를 선택하면 1점을 얻습니다.모르겠음선택지를 선택하면 점수를 얻지 않습니다.
검사 결과는 모든 질문의 성격 유형 점수를 더하여 각 지표에서 더 높은 점수를 받은 성격 유형이 검사자의 성격 유형이라고 판단합니다. 단, 하나의 지표에서 각 성격 유형 점수가 같으면, 두 성격 유형 중 사전 순으로 빠른 성격 유형을 검사자의 성격 유형이라고 판단합니다.
질문마다 판단하는 지표를 담은 1차원 문자열 배열 survey와 검사자가 각 질문마다 선택한 선택지를 담은 1차원 정수 배열 choices가 매개변수로 주어집니다. 이때, 검사자의 성격 유형 검사 결과를 지표 번호 순서대로 return 하도록 solution 함수를 완성해주세요.
제한 조건
- 1 ≤
survey의 길이 ( =n) ≤ 1,000survey의 원소는"RT", "TR", "FC", "CF", "MJ", "JM", "AN", "NA"중 하나입니다.survey[i]의 첫 번째 캐릭터는 i+1번 질문의 비동의 관련 선택지를 선택하면 받는 성격 유형을 의미합니다.survey[i]의 두 번째 캐릭터는 i+1번 질문의 동의 관련 선택지를 선택하면 받는 성격 유형을 의미합니다.
choices의 길이 =survey의 길이choices[i]는 검사자가 선택한 i+1번째 질문의 선택지를 의미합니다.- 1 ≤
choices의 원소 ≤ 7
choices | 뜻 |
|---|---|
| 1 | 매우 비동의 |
| 2 | 비동의 |
| 3 | 약간 비동의 |
| 4 | 모르겠음 |
| 5 | 약간 동의 |
| 6 | 동의 |
| 7 | 매우 동의 |
입출력 예
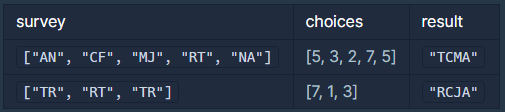
SOLVE
def solution(survey, choices):
keys = ["RT", "CF", "JM", "AN"]
Mtype = {"RT" : [0,0], "CF" : [0,0], "JM" : [0,0], "AN" : [0,0]}
for question,answer in zip(survey,choices):
if answer == 4 :
continue
if question[0] > question[1]:
question = question[::-1]
answer = 8 - answer
idx = int(answer > 4)
Mtype[question][idx] = Mtype[question][idx] + abs(answer-4)
result = ''
for key in keys:
item = Mtype[key]
result += key[int(item[0] < item[1])]
return result
keys: 각 지표를 사전순으로 정렬Mtype-key: 지표,item: 해당 지표의 각 유형별 얻은 점수를 저장하는 2차원 배열
ex. "RT" : [1, 4] => "RT"지표에서 "R" 유형이 1점, "T" 유형이 4점을 얻었다
아이디어
1.survey를 읽으며, 해당하는 각 유형에 점수를 부가.
2.keys를 읽으며, 해당하는 지표에서 더 높은 점수를 얻은 유형을 선택
survey를 읽으며, 해당하는 각 유형에 점수를 부가.
-zip(survey,choices)을 통해 질문과 해당 답변을 한번에 받아옴- 사전순으로 맞춰주기 위해,
survey를 사전순으로 맞춰주기- 만약, 사전순이 아니었다면,
survey와answer뒤집어주기 - ex. ("TR", 5) -> ("RT", 3)
- 만약, 사전순이 아니었다면,
Mtype에서 해당 지표(key)에 점수 더하기- 유형 선택 : 답변이 4보다 크면 : [1]유형에, 작으면 [0]유형에
- 점수 :
abs(answer-4)
- 사전순으로 맞춰주기 위해,
- 해당하는 지표에서 더 높은 점수를 얻은 유형을 선택
