Sequence-to-Sequence (seq2seq)
: 번역기에서 대표적으로 사용되는 모델
ex. 챗봇, 기계번역
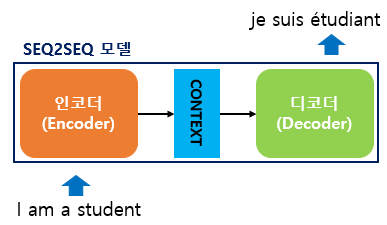
seq2seq의 원리
- 구성 : 인코더 모듈 & 디코더 모듈
- Encoder : 시계열 데이터를 압축해 하나의 벡터로 만듬 (생성된 벡터 - Context Vector)
- Decoder : 압축된 데이터를 다른 시계열 데이터로 변환
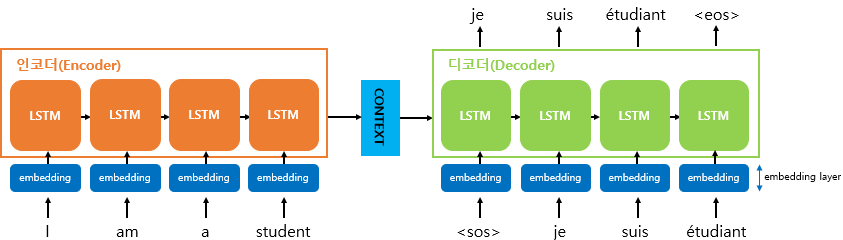
💡 임베딩 처리
기계는 텍스트보더 숫자를 더 잘 처리 ⇒자연어 → 벡터로 변환
- seq2seq에서도 모든 단어들을 임베딩 벡터로 변환 후 입력으로 사용
- 변환을 수행하는 층 -
embedding layer
Encoder 모듈
시계열 데이터를 압축해 하나의 벡터로 만듬
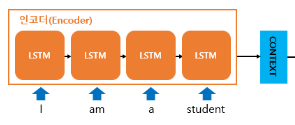
- RNN(or LSTM, GRU)을 거쳐 ‘데이터 → Hidden State Vector’로 나온다.
- 생성된 벡터 -
Context Vector: 인코더 RNN 셀의 마지막 시점의 은닉상태- 디코더 RNN셀의 첫번째 은닉상태에 이용
Decoder 모듈
압축된 데이터를 다른 시계열 데이터로 변환
-
기본적으로 RNNLM (RNN Language Model)
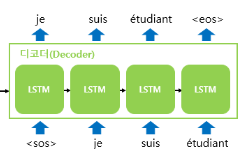
-
Decoder에서의 RNN셀 입/출력
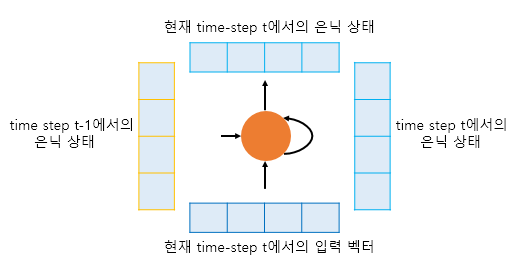
- 입력
- (t-1) 시점의 hidden state (처음 : Encoder로부터 Context Vector)
- 현재 (t) 시점 입력 벡터 (처음 : 심볼)
- 출력
1. (t) 시점의 hidden state (즉, hidden state 갱신)
+. 만약 위에 은닉층 or 출력층이 존재 ⇒ 현재 (t)에서의 hidden state 보냄
- 입력
-
RNN셀을 거쳐 나온 hidden state를 통해 다음에 나올 값 예측
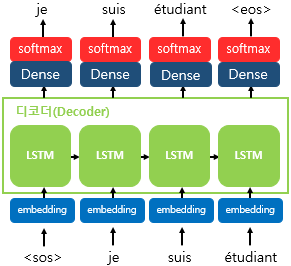
- Dense, softmax layer 사용 : RNN셀을 통해 나온 새로운 hidden state를
Dense layer,Softmax layer를 통해 다음에 등장할 확률이 높은 문장 예측
- Dense, softmax layer 사용 : RNN셀을 통해 나온 새로운 hidden state를
-
<sos>,<eos>토큰 사용하는 이유: 입/출력 시퀀스가 가변적이기 때문에 문장의 시작, 끝을 확인할 요소 필요
seq2seq의 한계점
- 하나의 고정된 크기의 벡터에 모든 정보 압축 ⇒ 정보 손실 발생
- RNN의 고질적인 문제인 기울기 소실(vanishing gradient) 문제 존재
⇒Attention Mechanism제안.

🦴피곤행🦴