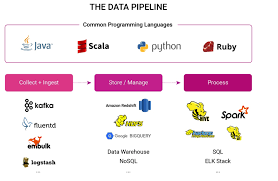
[ Data Engineering ] 데이터 엔지니어링 공부 05 : 데이터 웨어하우스 개념 공부.

▽데이터 웨어하우스 개념 공부.
목 차
1. 데이터 웨어하우스의 기본 개념
1-1. 데이터 웨어하우스의 정의와 진화
1-2. OLTP vs OLAP : 트랜잭션 처리와 분석 처리의 차이.
1-3. 데이터 웨어하우스의 핵심 특성
1-4. 비즈니스 인텔리전스 에코시스템에서의 역할
2. 데이터 웨어하우스 아키텍처
2-1. 전통적인 아키텍처 모델
2-1-1. Inmon의 엔터프라이즈 데이터 웨어하우스(EDW) 접근법.
2-1-2. Kimball의 차원 모델링 접근법
2-1-3. 하이브리드 및 데이터 볼트 접근법.
2-2. 현대적인 아키텍처 패턴.
2-2-1. 클라우드 네이티브 데이터 웨어하우스
2-2-2. 데이터 레이크하우스 아키텍처
2-2-3. 실시간 데이터 웨어하우징.
3. 데이터 모델링 및 스키마 설계.
3-1. 차원 모델링의 핵심 개념
3-1-1. 팩트 테이블과 차원 테이블
3-1-2. 스타 스키마 vs 스노우플레이크 스키마
3-1-3. 천천히 변화하는 차원(SCD) 처리 전략
3-2. 데이터 정규화 vs 비정규화 전략
3-3. 집계 테이블 및 구체화된 뷰 설계
3-4. 시간 차원 모델링 기법.
4. ETL/ELT 프로세스 및 데이터 파이프라인
4-1. ETL vs ELT : 언제 어떤 접근법을 사용할 것인가
4-2. 데이터 추출 전략 및 기술
4-2-1. 전체 추출 vs 증분 추출
4-2-2. CDC(Change Data Capture) 구현
4-2-3. API 기반 데이터 수집
4-3. 데이터 변환 및 품질 관리.
4-3-1. 데이터 클렌징 및 표준화
4-3-2. 비즈니스 규칙 적용 및 데이터 보강
4-3-3. 데이터 품질 프레임워크 구축.
4-4. 데이터 로딩 전략.
4-4-1. 벌크 로딩 vs 스트리밍 로딩
4-4-2. 병렬 처리 및 파티션 로딩
4-5. 현대적인 데이터 파이프라인 오케스트레이션.
5. 성능 최적화 및 튜닝
5.1 쿼리 성능 최적화
5-1-1. 실행 계획 분석 및 튜닝
5.1.2 인덱싱 전략
5.1.3 파티셔닝 및 샤딩 기법
5.2 데이터 분산 및 병렬 처리
5.2.1 MPP(Massively Parallel Processing) 아키텍처
5.2.2 컬럼 지향 저장소의 이점
5.2.3 데이터 분산 키 선택 전략
5.3 캐싱 및 메모리 최적화
5.4 리소스 관리 및 워크로드 관리
-------------------------------------

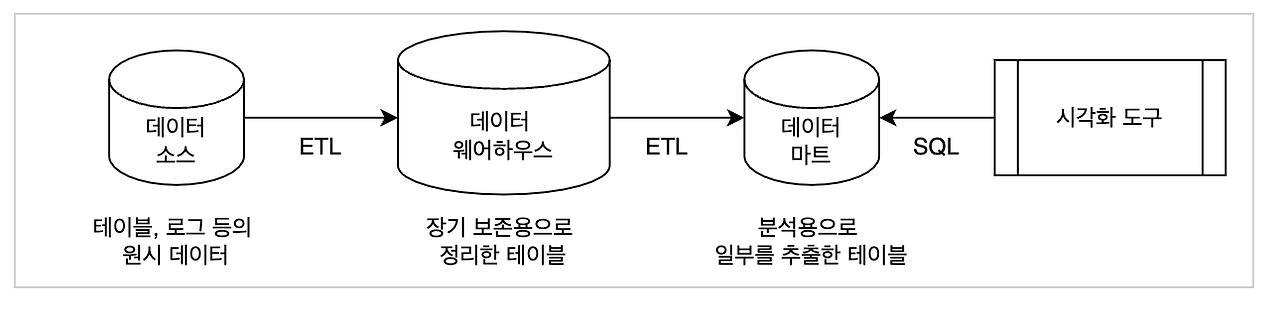
1. 데이터 웨어하우스의 기본 개념.
1-1. 데이터 웨어하우스의 정의와 진화.
-
데이터 웨어하우스는 의사 결정 지원을 위해 설계된 통합된 데이터 저장소로,
빌 인몬(Bill Inmon)에 의해 "주제 지향적이고, 통합되어 있으며,
시간에 따라 변하고, 비휘발성인 데이터의 집합"으로 정의되었습니다. -
1990년대 초기의 데이터 웨어하우스는 주로 배치 처리 중심이었으나,
현재는 실시간 처리 기능과 함께 클라우드 기반 솔루션으로 진화했습니다.
-
데이터 웨어하우스의 진화 과정은 다음과 같습니다:
-
1세대: 중앙 집중식 엔터프라이즈 데이터 웨어하우스(EDW)
-
2세대: 데이터 마트와 차원 모델링 접근법 도입
-
3세대: MPP(Massively Parallel Processing) 아키텍처와 컬럼 기반 저장소
-
4세대: 클라우드 네이티브 데이터 웨어하우스와 서버리스 아키텍처
-
1-2. OLTP vs OLAP : 트랜잭션 처리와 분석 처리의 차이.
OLTP(Online Transaction Processing)와 OLAP(Online Analytical Processing)는
데이터베이스 시스템의 두 가지 주요 유형입니다.
-
OLTP 시스템:
-
목적: 일상적인 비즈니스 트랜잭션 처리
-
특징: 많은 수의 짧은 트랜잭션, 높은 동시성, 정규화된 스키마
-
쿼리 패턴: 단순하고 표준화된 쿼리, 소량의 레코드 액세스
-
성능 지표: 트랜잭션 처리량, 응답 시간
-
예: ERP 시스템, 전자상거래 플랫폼, 은행 거래 시스템
-
.
-
OLAP 시스템:
-
목적: 복잡한 분석 및 의사 결정 지원
-
특징: 복잡한 쿼리, 대량 데이터 처리, 비정규화된 스키마
-
쿼리 패턴: 복잡한 집계 및 분석 쿼리, 대량의 레코드 스캔
-
성능 지표: 쿼리 처리 시간, 데이터 로드 시간
-
예: 데이터 웨어하우스, BI 도구, 분석 플랫폼
-
.
데이터 웨어하우스는 OLAP 워크로드에 최적화되어 있어, 복잡한 분석 쿼리를 효율적으로 처리할 수 있습니다.
1-3. 데이터 웨어하우스의 핵심 특성.
-
빌 인몬이 정의한 데이터 웨어하우스의 네 가지 핵심 특성.
-
주제 지향(Subject-oriented)
: 데이터는 특정 비즈니스 주제나 프로세스(예: 고객, 판매, 제품)를 중심으로 구성됩니다.
이는 운영 시스템의 애플리케이션 중심 관점과 대조됩니다. -
통합(Integrated)
: 다양한 소스 시스템의 데이터가 일관된 형식과 의미를 갖도록 통합됩니다.
이는 명명 규칙, 측정 단위, 인코딩 구조 등의 표준화를 포함합니다. -
시계열(Time-variant)
: 데이터는 특정 시점을 나타내며, 시간에 따른 변화를 추적할 수 있습니다.
이를 통해 트렌드 분석과 시계열 비교가 가능합니다. -
비휘발성(Non-volatile)
: 데이터가 웨어하우스에 로드되면 일반적으로 변경되지 않습니다.
이는 일관된 보고와 분석을 가능하게 합니다.
1-4. 비즈니스 인텔리전스 에코시스템에서의 역할.
-
데이터 웨어하우스는 비즈니스 인텔리전스(BI) 에코시스템의 중추적 역할을 합니다.
-
단일 진실 소스(Single Source of Truth): 조직 전체에서 일관된 데이터 뷰를 제공합니다.
-
데이터 통합 허브: 다양한 소스 시스템의 데이터를 통합합니다.
-
분석 기반: 보고서, 대시보드, 고급 분석을 위한 기초를 제공합니다.
-
데이터 품질 관리: 데이터 정제, 표준화, 검증을 통해 고품질 데이터를 보장합니다.
-
역사적 데이터 보존: 시간에 따른 비즈니스 성과를 추적할 수 있도록 합니다.
-

2. 데이터 웨어하우스 아키텍처.
2-1. 전통적인 아키텍처 모델.
2-1-1. Inmon의 엔터프라이즈 데이터 웨어하우스(EDW) 접근법.
-
빌 인몬의 EDW 접근법은 "하향식" 접근 방식으로, 전사적 관점에서 데이터 웨어하우스를 구축합니다.
-
중앙 집중식 저장소: 모든 기업 데이터를 통합하는 단일 중앙 저장소.
-
고도로 정규화된 데이터 모델: 3NF(Third Normal Form) 스키마를 사용하여 데이터 중복을 최소화.
-
주제 영역 데이터 마트: 중앙 EDW에서 파생된 부서별 데이터 마트.
-
기업 데이터 모델: 전사적 관점에서 데이터 관계를 정의.
-
인몬 방식의 장점은 데이터 일관성과 무결성이 높다는 것이지만,
구현이 복잡하고 초기 개발 시간이 길다는 단점이 있습니다.

2-1-2. Kimball의 차원 모델링 접근법.
-
랄프 킴볼의 접근법은 "상향식" 방식으로, 비즈니스 프로세스별 데이터 마트부터 시작합니다.
-
차원 모델링: 스타 스키마 또는 스노우플레이크 스키마를 사용
-
적합한 버스 아키텍처: 공유 차원을 통해 데이터 마트를 통합
-
비즈니스 프로세스 중심: 각 비즈니스 프로세스에 대한 개별 데이터 마트
-
일치 차원: 데이터 마트 간의 일관성을 보장하는 공통 차원
-
킴볼 방식의 장점은 구현이 빠르고 비즈니스 사용자가 이해하기 쉽다는 것이지만,
데이터 중복이 발생할 수 있고 전사적 관점이 부족할 수 있습니다.
2-1-3. 하이브리드 및 데이터 볼트 접근법.
-
많은 조직에서는 인몬과 킴볼의 접근법을 결합한 하이브리드 모델을 채택합니다.
-
하이브리드 접근법: 중앙 EDW와 차원 모델링의 장점을 결합
-
데이터 볼트 모델링: Dan Linstedt가 개발한 방법론으로, 역사적 데이터 추적에 중점을 둡니다
-
허브(Hub): 비즈니스 엔티티를 나타냄
-
링크(Link): 엔티티 간의 관계를 나타냄
-
새틀라이트(Satellite): 엔티티와 관계에 대한 설명적 정보를 저장
-
-
데이터 볼트는 변경 이력을 완벽하게 보존하고 감사 추적을 제공하지만,
구현이 복잡하고 초기 학습 곡선이 가파릅니다.
2-2. 현대적인 아키텍처 패턴.
2-2-1. 클라우드 네이티브 데이터 웨어하우스.
-
주요 클라우드 데이터 웨어하우스 플랫폼의 특징:
-
Amazon Redshift: MPP 아키텍처, 컬럼 기반 저장소, Redshift Spectrum을 통한 S3 데이터 쿼리
-
Google BigQuery: 서버리스 아키텍처, 자동 확장, 머신러닝 통합, 스트리밍 데이터 지원
-
Snowflake: 멀티 클라우드 지원, 마이크로 파티션 아키텍처, 데이터 공유 기능
-
Azure Synapse Analytics: 통합 분석 서비스, Spark 통합, 하이브리드 트랜잭션/분석 처리
-
2-2-2. 데이터 레이크하우스 아키텍처.
-
데이터 레이크하우스는 데이터 레이크의 유연성과 데이터 웨어하우스의 성능 및 관리 기능을 결합합니다:
-
통합 아키텍처: 구조화/비구조화 데이터를 단일 플랫폼에서 처리
-
스키마 적용: 데이터 레이크에 스키마 적용 기능 추가
-
트랜잭션 지원: ACID 트랜잭션을 통한 데이터 일관성 보장
-
성능 최적화: 인덱싱, 캐싱, 최적화된 파일 형식(Parquet, ORC)
-
SQL 엔진: 데이터 레이크 상의 데이터에 대한 고성능 SQL 쿼리
-
-
주요 데이터 레이크하우스 기술:
-
Delta Lake: Databricks에서 개발한 오픈 소스 스토리지 계층
-
Apache Iceberg: Netflix에서 개발한 테이블 형식
-
Apache Hudi: Uber에서 개발한 데이터 레이크 스토리지 추상화
-
2-2-3. 실시간 데이터 웨어하우징.
-
실시간 데이터 웨어하우스는 배치 처리와 스트리밍 처리를 결합하여,
최신 데이터에 대한 분석을 지원합니다:-
스트리밍 데이터 수집: Kafka, Kinesis 등을 통한 실시간 데이터 수집
-
변경 데이터 캡처(CDC): 소스 시스템의 변경 사항을 실시간으로 감지하고 전파
-
마이크로 배치 처리: 작은 배치로 데이터를 처리하여 지연 시간 최소화
-
실시간 분석 뷰: 최신 데이터를 반영하는 구체화된 뷰
-
Lambda/Kappa 아키텍처: 배치 레이어와 스피드 레이어를 결합한 아키텍처
-
-
실시간 데이터 웨어하우징의 과제:
-
데이터 일관성 유지
-
지연 시간과 처리량 균형
-
실시간 ETL 복잡성 관리
-
리소스 사용량 최적화
-
3. 데이터 모델링 및 스키마 설계.
3-1. 차원 모델링의 핵심 개념
3-1-1. 팩트 테이블과 차원 테이블.
-
차원 모델링은 분석 쿼리를 위해 최적화된 데이터 구조를 설계하는 기법입니다:
-
팩트 테이블:
-
비즈니스 프로세스의 측정값(metrics)을 저장
-
일반적으로 수치형 데이터 포함
-
외래 키를 통해 차원 테이블과 연결
-
대량의 데이터를 포함하며 지속적으로 증가
-
-
팩트 테이블 유형:
-
트랜잭션 팩트: 개별 이벤트 수준의 데이터 (예: 판매 트랜잭션)
-
주기적 스냅샷 팩트: 정기적인 간격으로 캡처된 측정값 (예: 월말 재고)
-
누적 스냅샷 팩트: 프로세스의 전체 수명 주기를 추적 (예: 주문부터 배송까지)
-
-
차원 테이블:
-
비즈니스 엔티티의 설명적 속성을 저장
-
텍스트 기반 속성으로 "어떻게, 언제, 어디서, 누가, 무엇을" 설명
-
상대적으로 작은 크기지만 많은 열 포함
-
계층 구조와 관계를 표현
-
-
주요 차원 예시:
-
날짜/시간 차원
-
고객 차원
-
제품 차원
-
지역 차원
-
조직 차원
-
-
3-1-2. 스타 스키마 vs 스노우플레이크 스키마.
-
스타 스키마:
-
중앙의 팩트 테이블과 직접 연결된 비정규화된 차원 테이블
-
장점:
-
쿼리 성능 향상 (조인 감소)
-
이해하기 쉬운 구조
-
쿼리 작성 단순화
-
-
단점:
-
데이터 중복으로 인한 저장 공간 증가
-
차원 데이터 업데이트 복잡성
-
-
-
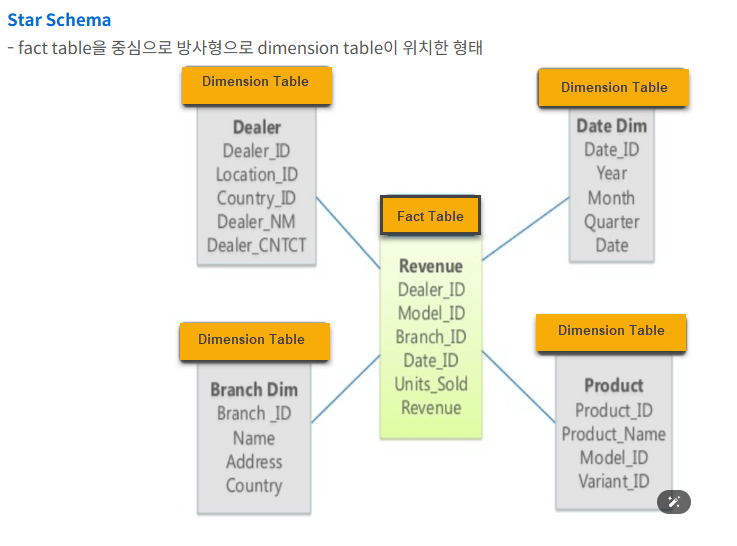
-
스노우플레이크 스키마:
-
차원 테이블이 정규화되어 여러 테이블로 분할.
-
장점:
-
저장 공간 효율성
-
차원 데이터 업데이트 용이
-
데이터 무결성 향상
-
-
단점:
- 더 많은 조인으로 인한 쿼리 성능 저하
- 복잡한 쿼리 구조.
- 유지 관리 복잡성 증가
-
-
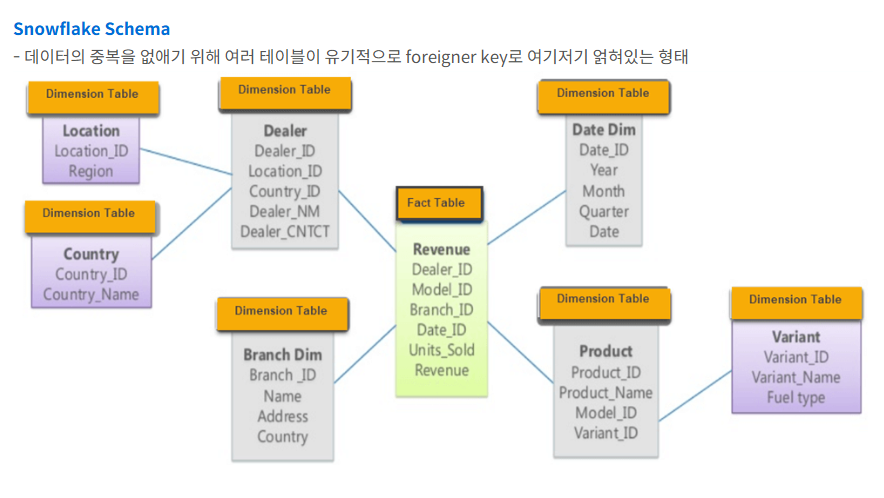
실무에서는 성능과 유지 관리 요구 사항에 따라 두 접근 방식을 혼합하여 사용하는 경우가 많습니다.
3-1-3. 천천히 변화하는 차원(SCD) 처리 전략.
차원 데이터는 시간이 지남에 따라 변경될 수 있으며, 이러한 변경을 관리하기 위한 여러 전략이 있습니다.
-
SCD 유형 0: 변경 무시
-
차원 속성이 절대 변경되지 않음
- 예: 출생일, 최초 가입일
-
-
SCD 유형 1: 덮어쓰기
-
기존 값을 새 값으로 대체
-
장점: 간단한 구현, 추가 저장 공간 불필요
-
단점: 이력 정보 손실
-
-
SCD 유형 2: 이력 보존
-
새 레코드를 추가하여 변경 이력 유지
-
유효 시작/종료 날짜 및 현재 플래그 사용
-
장점: 완전한 이력 보존
-
단점: 테이블 크기 증가, 쿼리 복잡성
-
-
SCD 유형 3: 이전/현재 값
-
이전 값과 현재 값을 모두 저장하는 별도의 열 추가
-
장점: 제한된 이력 유지, 간단한 쿼리
-
단점: 제한된 변경 이력(보통 한 번의 변경만)
-
-
SCD 유형 4: 이력 테이블
-
현재 값은 주 차원 테이블에, 이력은 별도 테이블에 저장
-
장점: 성능과 이력 보존 균형
-
단점: 추가 테이블 관리 필요
-
-
SCD 유형 6: 하이브리드 접근법 (1+2+3)
-
여러 SCD 유형의 조합
-
장점: 유연성, 다양한 사용 사례 지원
-
단점: 구현 및 유지 관리 복잡성
-
3-2. 데이터 정규화 vs 비정규화 전략.
- 데이터 웨어하우스 설계 시 정규화와 비정규화 간의 균형을 고려해야 합니다.
.
-
정규화:
-
데이터 중복 최소화
-
데이터 무결성 향상
-
저장 공간 효율성
-
업데이트 및 삽입 효율성
-
-
비정규화:
-
쿼리 성능 향상
-
조인 수 감소
-
쿼리 복잡성 감소
-
읽기 작업 최적화
-
-
데이터 웨어하우스에서는 일반적으로 쿼리 성능을 위해 어느 정도의 비정규화를 허용합니다.
-
자주 조인되는 테이블
-
계층적 데이터
-
집계 데이터
-
룩업 테이블
-
3-3. 집계 테이블 및 구체화된 뷰 설계.
집계 테이블과 구체화된 뷰는 쿼리 성능을 크게 향상시킬 수 있습니다:
-
집계 테이블:
-
미리 계산된 요약 데이터를 저장
-
일반적인 집계 수준:
-
시간적 집계 (일별→월별→분기별→연도별)
-
지리적 집계 (도시→지역→국가→대륙)
-
제품 집계 (SKU→제품→카테고리→부서)
-
-
-
집계 테이블 설계 고려사항:
-
쿼리 패턴 분석
-
적절한 집계 수준 선택
-
집계 테이블 새로 고침 빈도
-
집계 테이블과 상세 데이터 간의 일관성
-
-
구체화된 뷰:
-
쿼리 결과를 물리적으로 저장
-
자동 또는 수동 새로 고침 옵션
-
쿼리 재작성을 통한 투명한 사용
-
-
구체화된 뷰 최적화:
-
증분 새로 고침
-
부분 새로 고침
-
쿼리 기반 새로 고침
-
3-4. 시간 차원 모델링 기법.
시간 차원은 데이터 웨어하우스에서 가장 중요한 차원 중 하나입니다:
-
날짜 차원 설계:
-
기본 날짜 속성 (년, 월, 일, 요일 등)
-
비즈니스 캘린더 속성 (회계 연도, 분기, 기간)
-
휴일 및 특별 이벤트 표시
-
비교 기간 속성 (전년 동기, 전월 등)
-
계절성 속성
-
-
시간 인텔리전스 구현:
-
롤링 기간 계산 (최근 30일, 12개월 이동 평균)
-
연도별/월별 비교
-
누적 계산 (YTD, QTD, MTD)
-
기간 간 성장률
-
-
시간 관련 특수 패턴:
-
슬로우리 변화하는 팩트 (Slowly Changing Facts)
-
반복 스냅샷 (Periodic Snapshots)
-
누적 스냅샷 (Accumulating Snapshots)
-
트랜잭션 팩트 테이블의 시간 스탬프
-
4. ETL/ELT 프로세스 및 데이터 파이프라인.
4-1. ETL vs ELT : 언제 어떤 접근법을 사용할 것인가.
-
ETL(Extract, Transform, Load):
-
데이터를 소스에서 추출하여 스테이징 영역에서 변환한 후 데이터 웨어하우스에 로드
-
특징:
-
데이터 로드 전 변환
-
중간 스테이징 영역 필요
-
소스 시스템에서 처리 부하 감소
-
데이터 품질 및 정제에 중점
-
-
-
ELT(Extract, Load, Transform):
-
데이터를 소스에서 추출하여 먼저 데이터 웨어하우스에 로드한 후 변환
-
특징:
-
데이터 로드 후 변환
-
대상 시스템의 처리 능력 활용
-
원시 데이터 보존
-
더 빠른 데이터 가용성
-
-
-
선택 기준:
-
ETL 선호 상황:
-
데이터 품질 문제가 많은 경우
-
소스 데이터에 민감한 정보가 포함된 경우
-
처리 로직이 복잡한 경우
-
데이터 웨어하우스 리소스가 제한적인 경우
-
-
ELT 선호 상황:
-
대용량 데이터 처리
-
클라우드 데이터 웨어하우스 사용
-
데이터 탐색 및 발견 중심
-
유연한 변환 요구사항
-
-
현대 데이터 웨어하우스에서는 ELT 접근법이 점점 더 인기를 얻고 있으며,
특히 Snowflake, BigQuery, Redshift와 같은 클라우드 데이터 웨어하우스에서 효과적입니다.
4-2. 데이터 추출 전략 및 기술.
4-2-1. 전체 추출 vs 증분 추출.
- 전체 추출:
- 소스 데이터 전체를 매번 추출
-
장점:
-
구현 단순
-
데이터 일관성 보장
-
소스 시스템 변경에 덜 민감
-
-
단점:
-
리소스 집약적
-
처리 시간 길어짐
-
네트워크 부하 증가
-
-
증분 추출:
-
마지막 추출 이후 변경된 데이터만 추출
-
유형:
-
타임스탬프 기반: 수정 날짜/시간 사용
-
시퀀스/키 기반: 자동 증가 ID 사용
-
상태 기반: 상태 플래그 사용
-
로그 기반: 트랜잭션 로그 사용
-
-
장점:
-
효율적인 리소스 사용
-
처리 시간 단축
-
소스 시스템 부하 감소
-
-
단점:
-
구현 복잡성
-
변경 감지 메커니즘 필요
-
데이터 불일치 가능성
-
-
4-2-2. CDC(Change Data Capture) 구현.
-
데이터베이스에서 CDC(Change Data Capture)는 변경된 데이터를 확인하고 추적하여,
그 변경된 데이터를 사용하여 작업을 수행할 때 사용되는 소프트웨어 설계 패턴의 집합입니다. -
데이터 소스의 변경 사항을 식별, 캡처 및 전달하는 것을 기반으로 하는 데이터 통합 접근 방식입니다.
-
CDC는 데이터 웨어하우스(DW)의 핵심 기능 중 하나이기 때문에
데이터 웨어하우스 환경에서 자주 발생하지만,
CDC는 모든 데이터베이스 또는 데이터 저장소 시스템에서 활용할 수 있다.
-
CDC 구현 방법:
-
로그 기반 CDC:
-
데이터베이스 트랜잭션 로그를 분석하여 변경 사항을 캡처
-
예: MySQL binlog, PostgreSQL WAL, Oracle LogMiner
-
장점: 낮은 오버헤드, 모든 변경 사항 캡처 가능
-
단점: 데이터베이스 벤더 종속성, 구성 복잡성
-
-
-
타임스탬프 기반 CDC:
-
테이블 내 마지막 변경 시점을 기록하는 타임스탬프 칼럼을 사용
-
더 최근의 타임스탬프 값을 갖는 레코드를 변경된 것으로 식별
-
장점: 구현이 간단하고 다양한 데이터베이스에서 사용 가능
-
단점: 타임스탬프가 없는 논리는 대용량 데이터 테이블에서 실패할 수 있음
-
-
버전 번호 기반 CDC:
-
테이블 내 레코드의 버전을 기록하는 칼럼을 사용
-
더 높은 버전을 보유한 레코드를 변경된 것으로 식별
-
일반적으로 레코드들의 최신 버전을 기록, 관리하는 '참조 테이블'을 함께 운영
-
-
상태 기반 CDC:
-
데이터 변경 여부를 True/False의 불린(boolean) 값으로 저장하는 칼럼 사용
-
타임스탬프 및 버전 번호 기법에 대한 보완 용도로 활용
-
-
트리거 기반 CDC:
-
데이터베이스 트리거를 활용해 변경 사항을 캡처
-
장점: 모든 변경 사항 즉시 캡처 가능
-
단점: 소스 시스템 성능에 영향, 유지 관리 부담 증가
-
-
이벤트 프로그래밍:
-
데이터 변경 식별 기능을 애플리케이션에 구현
-
장점: 다양한 조건에 의한 CDC 메커니즘 구현 가능
-
단점: 애플리케이션 개발 부담과 복잡도 증가
-
-
CDC 구현 방식:
-
푸시 방식: Source DB에서 변경을 식별하고 Target DB에 변경 데이터를 적재
-
풀 방식: Target DB에서 Source DB를 정기적으로 살펴보고 필요시 데이터를 다운로드
-
.
- CDC의 주요 장점은 데이터의 실시간 동기화를 가능하게 하여 데이터의 신선도를 유지하고,
시스템 간의 데이터 일관성을 보장한다는 점입니다.
이는 특히 실시간 분석, 이벤트 기반 아키텍처, 마이크로서비스 간의 데이터 동기화에 유용합니다.
4-2-3. API 기반 데이터 수집.
-
API(Application Programming Interface)를 통한 데이터 수집은
외부 시스템이나 서비스에서 데이터를 가져오는 효과적인 방법입니다. -
특히 SaaS(Software as a Service) 애플리케이션이나 웹 서비스에서 데이터를 수집할 때 유용합니다.
-
API 기반 데이터 수집의 주요 특징:
-
실시간 또는 준실시간 데이터 액세스:
-
API를 통해 최신 데이터에 접근 가능
-
웹훅(Webhook)을 사용하여 이벤트 기반 데이터 수집 가능
-
-
구조화된 데이터 형식:
-
대부분의 API는 JSON, XML과 같은 구조화된 형식으로 데이터 제공
-
데이터 파싱 및 변환 작업 간소화
-
-
인증 및 권한 관리:
-
API 키, OAuth, JWT 등의 인증 메커니즘 사용
-
데이터 접근 권한 관리 및 보안 강화
-
-
속도 제한 및 할당량:
-
대부분의 API는 요청 횟수나 데이터 양에 제한 존재
-
속도 제한을 고려한 데이터 수집 전략 필요
-
-
페이지네이션 및 배치 처리:
-
대용량 데이터를 여러 요청으로 나누어 수집
-
커서 기반 페이지네이션, 오프셋 기반 페이지네이션 등 다양한 방식 지원
-
-
-
API 기반 데이터 수집 구현 전략:
-
폴링(Polling):
-
정기적으로 API를 호출하여 데이터 변경 사항 확인
-
간단하게 구현 가능하지만 불필요한 API 호출 발생 가능
-
-
웹훅(Webhook):
-
이벤트 발생 시 API 제공자가 지정된 엔드포인트로 데이터 전송
-
실시간 데이터 수집에 효과적이지만 수신 엔드포인트 구현 필요
-
-
스트리밍 API:
-
지속적인 연결을 통해 데이터 변경 사항을 실시간으로 수신
-
실시간성이 높지만 연결 관리 및 장애 처리 복잡
-
-
배치 API:
-
특정 시점의 대량 데이터를 한 번에 요청
-
대용량 데이터 처리에 효율적이지만 실시간성 떨어짐
-
-
API 기반 데이터 수집은 다양한 외부 데이터 소스를 데이터 웨어하우스에 통합하는 데 효과적인 방법이며, 특히 클라우드 기반 서비스와의 통합에 유용합니다.
4-3. 데이터 변환 및 품질 관리.
- 데이터 변환과 품질 관리는 ETL/ELT 프로세스의 핵심 단계입니다.
- 이 단계에서는 원시 데이터를 분석에 적합한 형태로 변환하고,
데이터의 정확성과 일관성을 보장합니다.
- 이 단계에서는 원시 데이터를 분석에 적합한 형태로 변환하고,
4-3-1. 데이터 클렌징 및 표준화.
-
데이터 클렌징: 오류, 중복, 불일치 데이터 제거
-
이상치(outlier) 식별 및 처리
-
중복 레코드 제거
-
일관성 없는 형식 수정
-
-
데이터 표준화: 일관된 형식과 단위로 데이터 변환
-
날짜/시간 형식 통일
-
통화 및 측정 단위 표준화
-
텍스트 데이터 정규화(대소문자, 공백 처리 등)
-
-
결측치 처리: 누락된 데이터에 대한 전략 수립
-
평균값, 중앙값, 최빈값으로 대체
-
예측 모델을 통한 값 추정
-
레코드 삭제 또는 특수 값 할당
-
4-3-2. 비즈니스 규칙 적용 및 데이터 보강.
-
비즈니스 규칙 적용: 조직의 정책과 규정에 맞게 데이터 변환
-
계산된 필드 생성(예: 총액, 비율, 평균)
-
조건부 로직 적용(예: 고객 세그먼트 분류)
-
데이터 집계 및 요약
-
-
데이터 보강: 외부 소스의 추가 정보로 데이터 풍부화
-
지리적 정보 추가(위도, 경도, 지역 코드)
-
인구통계학적 데이터 결합
-
시장 데이터 또는 산업 벤치마크 통합
-
-
파생 변수 생성: 기존 데이터를 기반으로 새로운 인사이트 제공 변수 생성
-
고객 생애 가치(CLV) 계산
-
제품 추천 점수
-
위험 또는 기회 지표
-
4-3-3. 데이터 품질 프레임워크 구축.
-
데이터 프로파일링: 데이터의 구조, 내용, 품질 특성 분석
-
데이터 분포 및 패턴 분석
-
열 간 관계 및 의존성 파악
-
데이터 유형 및 범위 검증
-
-
데이터 검증 규칙 정의: 정확성, 완전성, 일관성 등을 검증하는 규칙 설정
-
무결성 제약 조건(예: 기본 키, 외래 키)
-
도메인 유효성 검사(예: 이메일 형식, 전화번호 패턴)
-
비즈니스 로직 검증(예: 주문 금액 > 0)
-
-
품질 메트릭 모니터링: 주요 품질 지표의 지속적인 추적 및 보고
-
완전성(Completeness): 필수 필드의 채움 비율
-
정확성(Accuracy): 참조 데이터와 비교한 정확도
-
일관성(Consistency): 시스템 간 데이터 일치도
-
적시성(Timeliness): 데이터 최신성 및 업데이트 주기
-
-
이상치 탐지: 통계적 방법을 사용한 비정상 데이터 식별
-
Z-점수 기반 이상치 감지
-
클러스터링 기반 이상 감지
-
시계열 이상 패턴 식별
-
4-4. 데이터 로딩 전략.
- 효율적인 데이터 로딩은 데이터 웨어하우스의 성능과 가용성에 직접적인 영향을 미칩니다.
- 다양한 로딩 전략을 상황에 맞게 적용하는 것이 중요합니다.
4-4-1. 벌크 로딩 vs 스트리밍 로딩.
-
대량의 데이터를 일괄적으로 로드
-
주기적인 배치 처리에 적합(일별, 주별, 월별)
-
리소스 효율적이지만 실시간성 떨어짐
-
최적화 기법: 병렬 로딩, 파티션 로딩, 인덱스 비활성화
-
-
스트리밍 로딩:
-
실시간 또는 준실시간으로 데이터 로드
-
지연 시간이 중요한 애플리케이션에 적합
-
지속적인 처리 필요로 리소스 사용량 높음
-
구현 기술: Kafka, Kinesis, Pub/Sub 등의 메시징 시스템
-
4-4-2. 병렬 처리 및 파티션 로딩.
-
병렬 처리:
-
여러 스레드 또는 프로세스를 사용하여 동시에 데이터 로드
-
대용량 데이터 처리 시간 단축
-
리소스 할당 및 조정 전략 필요
-
데이터 의존성 고려 필요
-
-
파티션 로딩:
-
데이터를 논리적 또는 물리적 파티션으로 나누어 로드
-
쿼리 성능 향상 및 데이터 관리 용이성 제공
-
파티션 키 선택이 중요(날짜, 지역, 제품 카테고리 등)
-
파티션 관리 전략(병합, 분할, 교체 등)
-
4-5. 현대적인 데이터 파이프라인 오케스트레이션.
- 데이터 파이프라인의 복잡성이 증가함에 따라,
효과적인 오케스트레이션 도구의 필요성이 커지고 있습니다. - 현대적인 오케스트레이션 도구들은 데이터 흐름의 자동화, 모니터링, 오류 처리를 지원합니다.
-
Apache Airflow:
-
Python 기반의 워크플로우 관리 플랫폼
-
DAG(Directed Acyclic Graph)를 사용한 작업 의존성 정의
-
확장성과 커스터마이징 용이성
-
풍부한 운영자(Operator) 생태계
-
-
Prefect:
-
현대적인 데이터 워크플로우 관리 도구
-
동적 작업 생성 및 실시간 모니터링 지원
-
클라우드 네이티브 아키텍처
-
파이썬 중심 워크플로우 정의
-
-
Dagster:
-
데이터 오케스트레이션과 관찰성에 중점
-
소프트웨어 정의 자산(Software-defined assets) 개념 도입
-
테스트 및 유지보수 용이성 강조
-
데이터 계보(lineage) 추적 기능
-
-
데이터 파이프라인 모니터링 및 알림:
-
파이프라인 실행 상태 및 성능 모니터링
-
SLA(Service Level Agreement) 위반 알림
-
오류 및 예외 처리 메커니즘
-
재시도 및 복구 전략
-

5. 성능 최적화 및 튜닝
5.1 쿼리 성능 최적화
- 쿼리 성능 최적화는 데이터 웨어하우스의 응답 시간과 처리량을 향상시키는 핵심 요소입니다.
- 효율적인 쿼리는 리소스 사용을 최소화하면서 빠른 결과를 제공합니다.
5-1-1. 실행 계획 분석 및 튜닝
-
쿼리 실행 계획 이해:
-
실행 계획 생성 및 해석 방법
-
비용 추정 및 최적화 기회 식별
-
병목 현상 및 비효율적인 연산 식별
-
-
쿼리 재작성 기법:
-
서브쿼리 vs 조인 최적화
-
필터 푸시다운(Filter pushdown) 활용
-
윈도우 함수 및 분석 함수 효율적 사용
-
5.1.2 인덱싱 전략
-
인덱스 유형 및 선택:
-
B-트리 인덱스: 범위 쿼리에 효과적
-
비트맵 인덱스: 낮은 카디널리티 열에 적합
-
해시 인덱스: 동등 조건 쿼리에 최적화
-
-
인덱스 관리:
-
인덱스 생성 및 재구성 전략
-
미사용 인덱스 식별 및 제거
-
인덱스 통계 유지 관리
-
5.1.3 파티셔닝 및 샤딩 기법
-
테이블 파티셔닝:
-
범위 파티셔닝: 날짜, 숫자 범위 기반
-
리스트 파티셔닝: 이산적 값 집합 기반
-
해시 파티셔닝: 데이터 균등 분배
-
-
데이터 분산 전략:
-
샤딩 키 선택 기준
-
핫스팟 방지 및 부하 균형
-
분산 조인 최적화
-
5.2 데이터 분산 및 병렬 처리
- 대규모 데이터 처리를 위해 데이터 웨어하우스는 분산 아키텍처와 병렬 처리 기능을 활용합니다.
- 이를 통해 대용량 데이터를 효율적으로 처리할 수 있습니다.
5.2.1 MPP(Massively Parallel Processing) 아키텍처
-
MPP 원리 및 구성 요소:
-
노드 간 데이터 분산 메커니즘
-
쿼리 분해 및 병렬 실행
-
결과 집계 및 통합
-
-
MPP 시스템 최적화:
-
노드 수 및 구성 조정
-
데이터 분산 균형 유지
-
네트워크 통신 최소화
-
5.2.2 컬럼 지향 저장소의 이점
-
컬럼 지향 저장 원리:
-
데이터 압축 효율성
-
I/O 최소화 및 쿼리 성능 향상
-
분석 워크로드에 최적화
-
-
컬럼 지향 저장소 활용:
-
열 프루닝(Column pruning) 최적화
-
벡터화된 처리 활용
-
압축 알고리즘 선택
-
5.2.3 데이터 분산 키 선택 전략
-
분산 키 선택 기준:
-
데이터 균등 분포
-
조인 및 집계 패턴 고려
-
스큐(Skew) 방지
-
-
분산 키 최적화:
-
복합 분산 키 설계
-
데이터 분포 모니터링
-
재분산 전략 및 타이밍
-
5.3 캐싱 및 메모리 최적화
-
메모리 관리와 캐싱 전략은 데이터 웨어하우스의 성능을 크게 향상시킬 수 있습니다.
- 효율적인 메모리 사용은 디스크 I/O를 줄이고 쿼리 응답 시간을 단축합니다.
-
결과 캐싱 전략:
-
쿼리 결과 캐싱 메커니즘
-
캐시 무효화 및 갱신 정책
-
캐시 적중률 모니터링
-
-
메모리 내 처리:
-
인메모리 분석 기법
-
컬럼 스토어 압축 활용
-
메모리 사용량 관리 및 모니터링
-
-
메모리 스필(Spill) 관리:
-
메모리 부족 상황 처리
-
디스크 스필 최소화 전략
-
워크로드에 따른 메모리 할당 조정
-
5.4 리소스 관리 및 워크로드 관리.
데이터 웨어하우스의 리소스를 효율적으로 관리하고 다양한 워크로드를 조율하는 것은
전체 시스템 성능과 사용자 경험에 중요한 영향을 미칩니다.
-
워크로드 분류 및 우선순위 지정:
-
워크로드 특성에 따른 분류(보고, 분석, 배치 등)
-
우선순위 정책 설정
-
리소스 할당 규칙 정의
-
-
동시성 제어:
-
동시 쿼리 수 제한
-
쿼리 대기열 관리
-
장기 실행 쿼리 처리 전략
-
-
리소스 풀 및 할당:
-
사용자/부서별 리소스 할당
-
탄력적 리소스 확장
-
피크 시간 및 오프 피크 시간 관리
-
-
워크로드 모니터링 및 조정:
-
리소스 사용량 추적
-
성능 병목 현상 식별
-
자동 조정 메커니즘 구현
-
