데이터를 위한 C.S 지식 정리_네트워크 공부 : HTTP는 무엇일까.

▽ 데이터를 위한 C.S 지식 정리_네트워크 공부 : HTTP는 무엇일까.
목 차
1. HTTP란? : Hyper Text Transfer Protocol
2. HTTP의 통신 구조
3. HTTP의 무상태성
4. HTTP의 비연결성
5. HTTP의 상태 코드
6. HTTP 메세지
7. HTTP 메서드.
1. HTTP란? : Hyper Text Transfer Protocol
HTTP란 서버와 클라이언트가 서로 데이터를 주고받기 위해 사용되는 "통신 규약"을 의미.
- 웹 문서간에 링크를 통해 연결할 수 있는 프로토콜.
- 문서뿐 아니라 다음과 같은 여러 종류의 데이터들을 폭 넓게 전송 가능.
- ⓐ HTML, Text
- ⓑ IMAGE, 음성,영상,파일
- ⓒ JSON, XML(API)
- ⓓ 거의 모든 형태의 데이터가 전송 가능.
서버간에 데이터를 주고 받을 때도 대부분 HTTP라는 프로토콜을 사용해서 통신한다고 보면 됨.
- 예를들어 인터넷 주소를 지정할때 http://www.naver.com 와 같이 시작하는 것은
www.naver.com 이라는 인터넷 주소가 가진 데이터 정보 등의 교환을 HTTP의 통신 규약대로 처리하라는 것.
- 인터넷 기반 서비스에는 HTTP외에도 Email, FTP, DNS, NEWS 등이 있음.
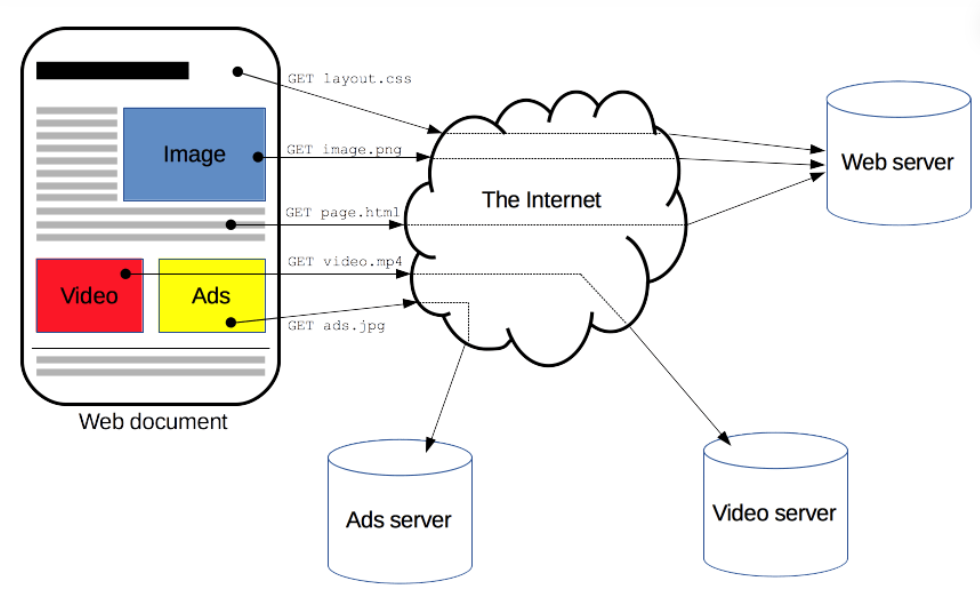

HTTP의 역사

① HTTP/0.9 (1991년) : GET 메서드만 지원, HTTP 헤더 X
② HTTP/1.0 (1996년) : 메서드, 헤더, 상태코드 추가
- ⓐ 요청 헤더 : http 버전이 생김
- ⓑ 응답 헤더 : 상태코드와 content-type이 생겨 html 파일 외 다른 타입의 파일도 전송
- ⓒ 단기커넥션:
- connection 하나당 1 요청, 1 응답만 처리 가능.
- 그래서 매번 새로운 연결로 선능 저하 및 서버 부하 비용 증가
③ HTTP/1.1 (1997년) : 현재 가장 많이 사용하며, 대부분의 기능이 추가
- ⓐ Persistent connection : 지정한 timeout 동안 연속적인 요청 사이에 커넥션을 닫지 않음
- ⓑ Pipelining : 하나의 커넥션에서 응답을 기다리지 않고 순차적인 여러 요청을 연속적으로 보내 그 순서에 맞춰 응답을 받는 방식으로 지연 시간을 줄이는 방식. 그러나 Head Of Line Blocking와 같은 문제점이 많아 사장됨
- ⓒ Head Of Line Blocking : 우선순위로 들어온 요청의 응답 시간이 길어지면 후 순위에 있는 요청의 응답 시간도 길어진다는 단점
- ⓓ 우리가 아는 대부분의 HTTP 기능이 1.1에 구현 된 것이고, 2와 3에서는 성능 개선에 초점이 맞춰져 있음.
④ HTTP/2.0 (2015년) : HTTP 1.1 성능 개선 및 확장
- ⓐ 메시지 전송 방식의 변화 : 바이너리 프레이밍 계층 사용
- ⓑ 파싱, 전송속도 증가
- ⓒ 오류 발생 가능성 저하
- ⓓ 멀티플렉싱
- ⓔ HPACK 압축 : 헤더 중복값 개선
⑤ HTTP/3.0 (2019년 ~ 진행중): TCP 대신에 UDP를 이용한 QUIC 프로토콜 사용
- ⓐ UDP 기반의 QUIC 프로코콜 바탕으로 제작
- ⓑ 기존 TCP의 고질적인 지연시간(RTT)를 해결함
HTTP/1.1, HTTP/2는 TCP 기반이며 HTTP/3는 UDP 기반 프로토콜
- 기존 TCP는 3 way hanshake부터 내부적으로 포함하거나 추가해야하는 작업들이 너무 많아서
신뢰성이나 연결성은 보장되지만 속도가 떨어짐.- 그렇기에 UDP프로토콜을 애플리케이션 레벨에서 재설계를 해서 나오는게 HTTP/3.
2. HTTP의 통신 구조
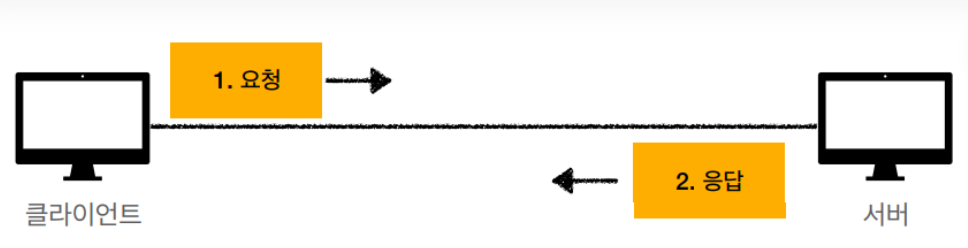
HTTP 통신은 "클라이언트(Front-End)"와 "서버(Back-End)"로 나뉘어진 구조.
- 클라이언트가 요청(Request)하면, 서버가 응답(Response)하는 것.
- 클라이언트가 HTTP 메시지를 보내고,
서버에서 요청에 대한 응답이 올 때까지 기다림. - 서버는 요청에 대한 결과를 만들어서 응답.
- 클라이언트가 HTTP 메시지를 보내고,
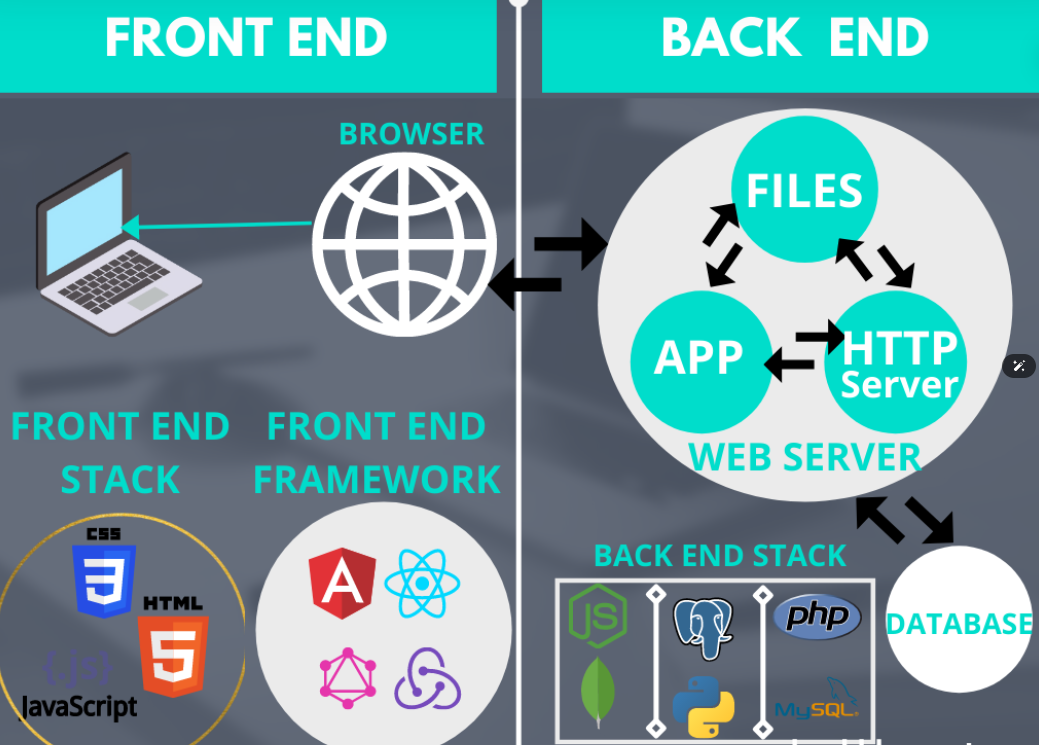
HTTP 통신하는데 있어서, 클라이언트와 서버를 분리해야만 하는 이유는?
각자의 역할에 집중할 수 있기 때문.
-
클라이언트에서는 복잡한 비즈니스로직이나 데이터를 다룰 필요없고,
UI를 그리는데 집중 가능. -
서버에서는 복잡한 비즈니스 로직이나, 데이터를 다루는데만 집중하면 됨.
만약 트래픽이 폭주해 고도화가 필요한 경우 클라이언트는 신경쓰지 않고 서버만 개선하면 됨. -
클라이언트와 서버를 독립적으로 구분한다는 것은 각자의 책임을 나눠 해당 책임에만 집중하여,
클라이언트와 서버 양쪽이 각각 독립적으로 고도화 할수 있다는 것
3. HTTP의 무상태성(Stateless)
무상태(Stateless) : 클라이언트와 서버 사이에 상태를 유지하지 않음.
- 장점: 서버 확장성 높음(스케일 아웃)
- 단점: 클라이언트가 추가 데이터 전송 (메모리 ↑)

상태 유지(Stateful)
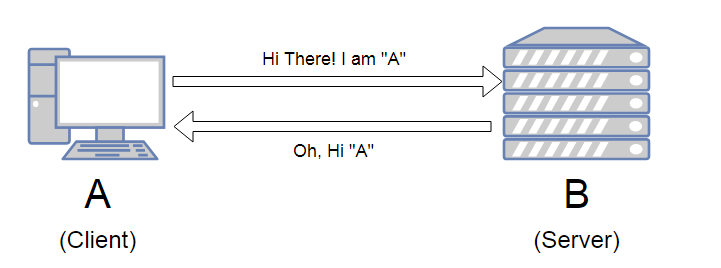
- 서버가 클라이언트의 상태를 보존.
- 가장 대표적인 예로 홈페이지에서 회원 로그인을 하면,
페이지를 옮겨가도 서버는 클라이언트의 상태를 보존하기 때문에 그 클라이언트가 회원인지 인지. - 하지만 중간에 서버가 장애나면 클라이언트는 처음부터 다시 작업을 요청해야함.
- 그래서 서버가 바뀔때마다 클라이언트의 내용을 기록해서 상태를 유지해야 되는데 쉽지 않음.
무상태(Stateless)
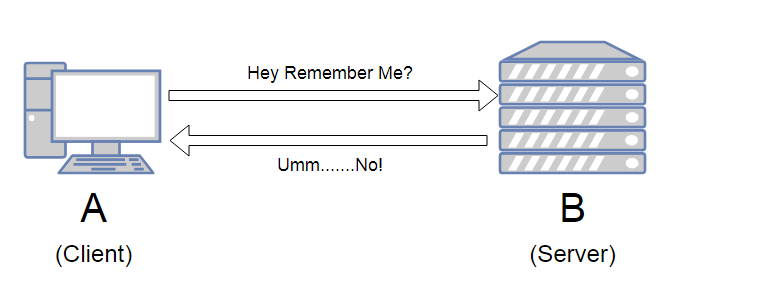
- 서버가 클라이언트의 상태를 보존하지 않는다.
- 홈페이지에서 회원 로그인을 하고 페이지를 옮겼는데 또 로그인을 하라는 페이지가 뜬다.
왜냐하면 서버는 클라이언트의 상태를 보존하지 않기 때문에 그 클라이언트가 회원인지 모르기 때문. - 따라서 무상태 환경에선 회원 정보를 서버가 아닌 클라이언트가 토큰 형태로 들고 있으면서,
서버와 통신할때 실어 보내 인증하는 식. - 이러한 무상태 환경은 클라이언트가 상태 정보를 갖고 있는 것이기 때문에,
아무 서버나 호출해도 되기 때문에 서버의 스케일아웃(수평확장)에 유리. - 하지만 상태유지(Stateful)보다 데이터를 많이 사용한다는 단점이 있음.
4. HTTP의 비연결성
-
HTTP는 기본이 연결을 유지하지 않는 모델이다.
-
즉, 서버와 클라이언트의 Connection 연결을 지속하지 않는다.
-
1시간동안 수천명 이상이 서비스를 사용해도 실제 서버에서 동시에 처리하는 요청은 수십개 이하로 적다.
- 예를들어 웹 브라우저 검색페이지에서 검색버튼만 연타하면서 이용하지는 않는듯이 말이다.
-
이러한 비연결성 특성 때문에 서버 자원을 매우 효율적으로 사용 가능.
[ Stateless 와 Connectionless 차이 ]
-
Stateless (무상태성):
- 필요한 상태에 대한 정보를 클라이언트가 가지고 오기 때문에
클라이언트의 요청에 어느 서버가 응답해도 상관 없음. - 따라서 클라이언트의 요청이 대폭 증가하면 서버를 증설해 해결할 수 있음.
- 필요한 상태에 대한 정보를 클라이언트가 가지고 오기 때문에
-
Connectionless (비연결성):
- 클라이언트가 서버에 요청을 하고 응답을 받으면 바로 TCP/IP 연결을 끊어 연결을 유지하지 않음으로써
서버의 자원을 효율적으로 관리하고 많은 클라이언트의 요청에 대응할 수 있게 함
- 클라이언트가 서버에 요청을 하고 응답을 받으면 바로 TCP/IP 연결을 끊어 연결을 유지하지 않음으로써
-
즉, 무상태성은 클라이언트와 서버 간에 상태 정보를 들고있지않아
클라이언트가 상태 정보를 일일히 http에 실어 요청해야되는 것을 말하고,
비연결성은 클라이언트와 서버 간에 네트워크 연결이 끊어져 단절된다고 이해하면 됨.
연결을 유지하는 모델
- 연결을 유지한다면, 서버와 클라이언트의 연결은 서로의 네트워킹 요청이 없더라도 계속해서 유지된다.
- 자원이 계속해서 사용된다. (이러한 점 때문에, HTTP는 기본적으로 연결을 유지하지 않는 모델이다)
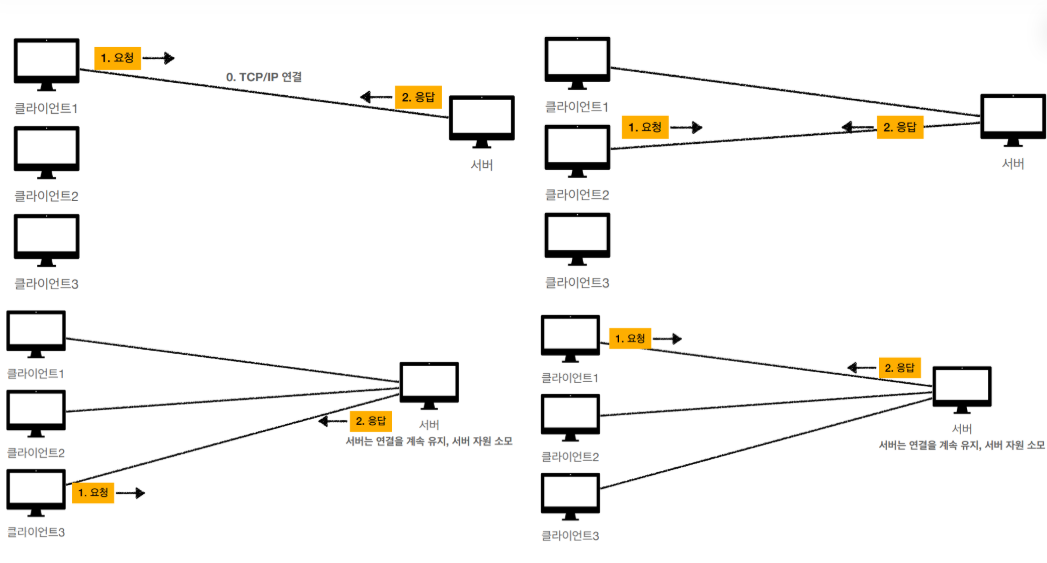
연결을 유지하지 않는 모델.
- 연결을 유지하지 않는다면, 서버의 자원을 효율적으로 사용할 수 있다.
- 다만, 클라이언트가 연결을 계속 끊는 다는 것은 TCP/IP 연결을 매번 새롭게 맺어야 한다는 것을 뜻한다.
- 즉, TCP 3 way handshake를 매번 해야하고, 이는 시간이 걸린다.
- 이러한 문제는 지금 HTTP 지속 연결(Persistent Connections)로 문제 해결하고 있다.
- HTTP/2, HTTP/3에서 더 많은 최적화가 이루어 졌다.
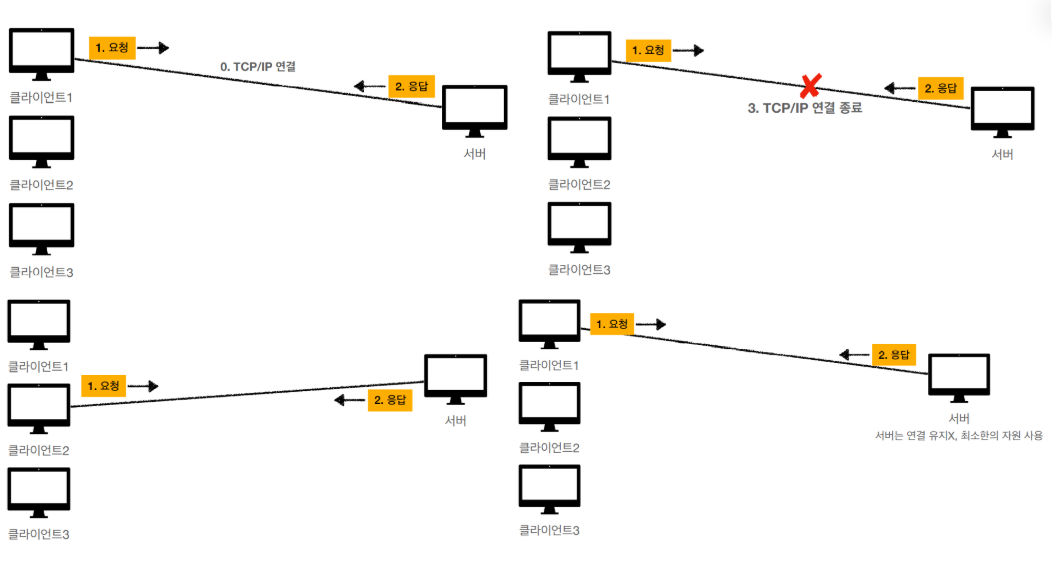
비연결성의 한계 - 단기 커넥션.
-
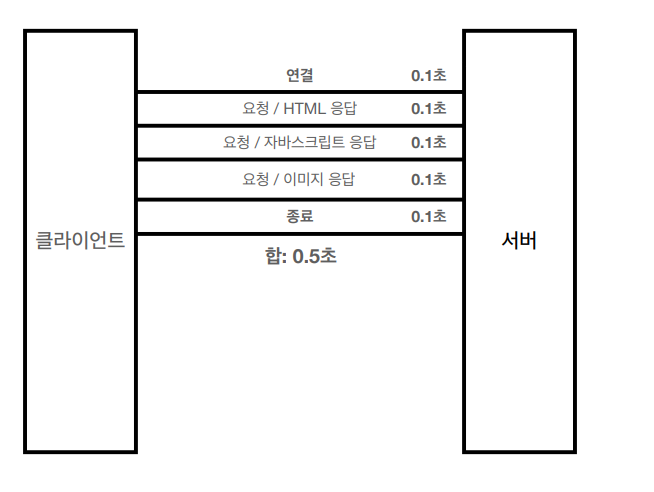
HTTP 초기 - 연결, 종료 낭비
-
웹 브라우저로 사이트를 요청하면 HTML 뿐만 아니라 자바스크립트, css, 추가 이미지 등등
수 많은 자원이 함께 다운로드 되는데, 새로 연결을 맺을 때 마다 TCP Handshake가 발생한다는 문제점이 있음 -
그래서 HTTP 초기에는 모든 자료에 대해서 비연결성으로
각각의 자원에 대해 연결/응답/종료를 반복하다보니 대략적으로 1초가량 소모
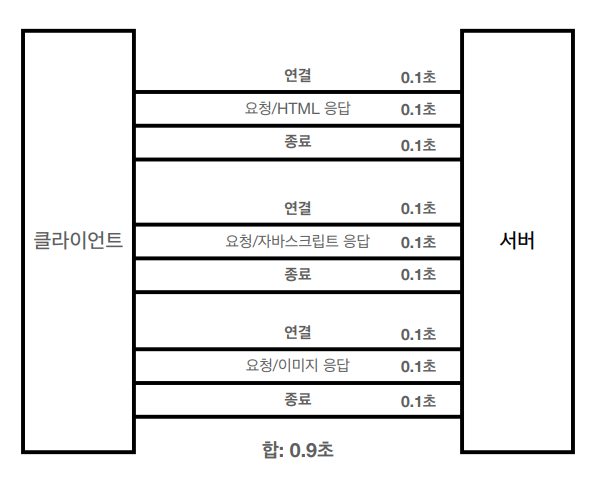
비연결성 극복 - HTTP 지속 연결.
-
클라이언트는 서버와 소켓 연결을 한 다음 필요한 자원을 요청/응답으로 다운로드.
-
소켓 연결을 일정 시간 동안 더 유지함으로써,
필요한 자원들을 모두 다운받을때까지 연결이 종료되지않고 요청/응답이 반복된 뒤 종료.

5. HTTP의 상태 코드
6. HTTP 메세지
7. HTTP 메서드.
