[실습 프로젝트 : Python ] 핀터레스트 착장 정보 데이터셋으로 만들기_01 : Python-selenium으로 Pinterest 착장 정보 크롤링해오기.
팀 프로젝트 정리 : 협업하기
목록 보기
5/8

[실습 프로젝트 : Python ] 핀터레스트 착장 정보 데이터셋으로 만들기_01 : Python-selenium으로 Pinterest 착장 정보 크롤링해오기.

사이드 프로젝트를 진행하면서, 코디 정보를 Raw Data로 싹~~~불러모아야 하는 필요가 생겨서
무신사나, 에이블리의 API를 활용할까 고민하다가
옷 정보가 개별적으로 들어오는게 너무 과하다 생각해서 pinterest에서 크롤링해오는걸로
방향을 잡았습니다.
Python의 크롤링 라이브러리인 뷰티플숩과 셀레니움 중에
셀레니움을 선택한 건
핀터레스트 사이트 자체가, 인위적인 접근을 방지하고 있기 때문에
브라우저를 직접 조정해서 우회할 수 있는 셀레니움을 선택하게 되었습니다.
https://github.com/croppedeyebrow/selenium_pinterest_crowling
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from webdriver_manager.chrome import ChromeDriverManager
import pandas as pd
import schedule
import time
import os
import random
import requests # 추가
from datetime import datetime
from urllib.parse import urlparse, parse_qs # URL 파싱을 위한 모듈 추가
def setup_driver():
"""웹 드라이버를 설정하고 반환하는 함수"""
try:
options = webdriver.ChromeOptions()
options.add_argument('--no-sandbox') # 샌드박스 모드 비활성화
options.add_argument('--disable-dev-shm-usage') # 공유 메모리 사용 비활성화
options.add_argument('--disable-blink-features=AutomationControlled') # 자동화 감지 비활성화
options.add_experimental_option('excludeSwitches', ['enable-automation']) # 자동화 스위치 제외
options.add_experimental_option('useAutomationExtension', False) # 자동화 확장 비활성화
service = Service(ChromeDriverManager().install()) # 드라이버 서비스 설정
driver = webdriver.Chrome(service=service, options=options) # 드라이버 인스턴스 생성
return driver # 드라이버 반환
except Exception as e:
print(f"드라이버 설정 중 오류 발생: {e}") # 오류 발생 시 메시지 출력
return None # 드라이버가 설정되지 않으면 None 반환
def login(driver, username, password):
"""Pinterest에 로그인하는 함수"""
driver.get("https://www.pinterest.com/login/") # 로그인 페이지로 이동
# 로그인 폼이 로드될 때까지 대기
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.NAME, "id")) # 사용자 이름 입력 필드 대기
)
# 사용자 이름과 비밀번호 입력
driver.find_element(By.NAME, "id").send_keys(username) # 사용자 이름 입력
driver.find_element(By.NAME, "password").send_keys(password) # 비밀번호 입력
# 로그인 버튼 클릭
driver.find_element(By.XPATH, "//button[@type='submit']").click() # 로그인 버튼 클릭
# 로그인 후 대기
WebDriverWait(driver, 10).until(
EC.url_changes("https://www.pinterest.com/login/") # 로그인 후 URL 변경 대기
)
def crawl_images(url, username, password):
"""지정된 URL에서 이미지 크롤링"""
# 이미지 저장 폴더 생성
img_folder = 'crowlingimg'
if not os.path.exists(img_folder):
os.makedirs(img_folder)
driver = setup_driver()
try:
# 로그인 수행
login(driver, username, password) # 로그인 함수 호출
# 로그인 후 잠시 대기
time.sleep(8) # 페이지 완전 로드를 위한 대기
# 웹페이지 로드
driver.get(url) # 지정된 URL로 이동
# URL에서 검색어 추출
parsed_url = urlparse(url) # URL 파싱
query_params = parse_qs(parsed_url.query) # 쿼리 매개변수 파싱
# 'q' 매개변수에서 검색어 추출 (키가 'q'인지 확인)
search_term = query_params.get('q', [''])[0] if 'q' in query_params else '' # 'q' 매개변수에서 검색어 추출
# 디버깅을 위한 출력
print(f"추출된 검색어: {search_term}") # 검색어 출력
# 스크롤 다운을 통해 더 많은 이미지 로드
for _ in range(15): # 10번 스크롤
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") # 페이지 맨 아래로 스크롤
time.sleep(5) # 스크롤 후 로딩 대기
# Pinterest의 실제 이미지 요소 선택자로 변경
images = driver.find_elements(By.CSS_SELECTOR, "img[srcset]") # 이미지 요소 선택
image_data = [] # 이미지 데이터를 저장할 리스트
# 각 이미지의 정보 추출
for img in images:
try:
src = img.get_attribute('src')
if src and not src.endswith('gif'):
# 이미지 파일명 생성 (검색어와 타임스탬프 포함)
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
img_filename = f"{search_term}_{timestamp}_{len(image_data)}.jpg"
img_path = os.path.join(img_folder, img_filename)
# 이미지 다운로드 및 저장
try:
response = requests.get(src)
if response.status_code == 200:
with open(img_path, 'wb') as f:
f.write(response.content)
image_data.append({
'image_url': src,
'image_filename': img_filename,
'crawled_at': datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
'search_term': search_term
})
except Exception as e:
print(f"이미지 다운로드 중 오류: {e}")
except Exception as e:
print(f"이미지 처리 중 오류 발생: {e}")
return image_data
finally:
# 브라우저 자원 해제
driver.quit() # 드라이버 종료
def download_image(url, filename):
"""이미지를 다운로드하여 저장하는 함수"""
try:
response = requests.get(url) # 이미지 URL에서 데이터 요청
if response.status_code == 200: # 요청이 성공적일 경우
with open(filename, 'wb') as f: # 파일 열기
f.write(response.content) # 이미지 데이터 저장
print(f"이미지 저장 완료: {filename}") # 저장 완료 메시지 출력
else:
print(f"이미지 다운로드 실패: {url}") # 실패 메시지 출력
except Exception as e:
print(f"이미지 다운로드 중 오류 발생: {e}") # 오류 발생 시 메시지 출력
def save_to_csv(data, filename='pinterestcrowling.csv'):
"""크롤링한 데이터를 CSV 파일로 저장"""
# 데이터프레임 생성
df = pd.DataFrame(data) # 데이터프레임으로 변환
# CSV 파일 존재 여부 확인 및 처리
try:
if os.path.exists(filename): # 문자열로 파일명 지정
# 기존 CSV 파일이 있다면 읽어와서 새 데이터와 병합
existing_df = pd.read_csv(filename) # 기존 데이터프레임 읽기
df = pd.concat([existing_df, df], ignore_index=True) # 데이터 병합
# CSV 파일로 저장 (한글 깨짐 방지를 위해 utf-8-sig 인코딩 사용)
df.to_csv(filename, index=False, encoding='utf-8-sig') # CSV 파일로 저장
print(f"데이터가 {filename}에 저장되었습니다.") # 저장 완료 메시지 출력
except Exception as e:
print(f"CSV 파일 저장 중 오류 발생: {e}") # 오류 발생 시 메시지 출력
def job():
"""크롤링 작업 실행"""
# 크롤링할 URL 목록 설정
urls = [
"https://kr.pinterest.com/search/pins/?q=short%20sleeve%20classy%20outfit%20for%20women&rs=typed",
"https://kr.pinterest.com/search/pins/?q=demure%20outfit%20for%20women&rs=typed",
"https://kr.pinterest.com/search/pins/?q=daily%20outfit%20for%20korean%20women&rs=typed",
"https://kr.pinterest.com/search/pins/?q=summer%20daily%20outfit%20for%20korean%20women&rs=typed",
"https://kr.pinterest.com/search/pins/?q=winter%20daily%20outfit%20for%20korean%20women&rs=typed",
"https://kr.pinterest.com/search/pins/?q=resort%20outfit%20for%20korean%20women&rs=typed",
"https://kr.pinterest.com/search/pins/?q=cute%20outfit%20for%20korean%20women&rs=typed",
"https://kr.pinterest.com/search/pins/?q=spring%20cute%20outfit%20for%20korean%20women&rs=typed",
"https://kr.pinterest.com/search/pins/?q=summer%20cute%20outfit%20for%20korean%20women&rs=typed",
"https://kr.pinterest.com/search/pins/?q=authum%20cute%20outfit%20for%20korean%20women&rs=typed",
"https://kr.pinterest.com/search/pins/?q=winter%20cute%20outfit%20for%20korean%20women&rs=typed",
# 더 많은 URL을 여기에 추가할 수 있습니다.
]
username = "" # 실제 사용자 이름 입력
password = "" # 실제 비밀번호 입력
print(f"크롤링 시작: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}") # 크롤링 시작 시간 출력
try:
for url in urls: # URL 목록을 순회
print(f"크롤링 중: {url}") # 현재 크롤링 중인 URL 출력
# 이미지 크롤링 수행
image_data = crawl_images(url, username, password) # 이미지 크롤링 함수 호출
if image_data:
# 수집된 데이터가 있으면 CSV 파일로 저장
save_to_csv(image_data) # 데이터 저장 함수 호출
print(f"총 {len(image_data)}개의 이미지 정보를 수집했습니다.") # 수집된 이미지 수 출력
except Exception as e:
print(f"크롤링 중 오류 발생: {e}") # 크롤링 중 오류 발생 시 메시지 출력
def main():
"""메인 함수"""
# 첫 번째 실행 후 5분 후에 다른 URL로 크롤링
schedule.every(5).minutes.do(job) # 3분마다 job 함수 실행
# 프로그램 시작 시 최초 1회 실행
job() # 최초 크롤링 실행
# 스케줄러 무한 루프
# 60초마다 pending 상태의 작업이 있는지 확인하고 실행
while True:
schedule.run_pending() # 예약된 작업 실행
time.sleep(80) # 80초 대기
if __name__ == "__main__":
main() # 메인 함수 실행
전체적인 코드는 위처럼 진행을 하였고,
검색어를 지정해서, 그에 맞는 url로 접근을 하고
접근해서 얻은 이미지 파일들의 url/이미지파일/검색어 소팅/
이런식으로 가져오도록 했습니다.

◆결과는
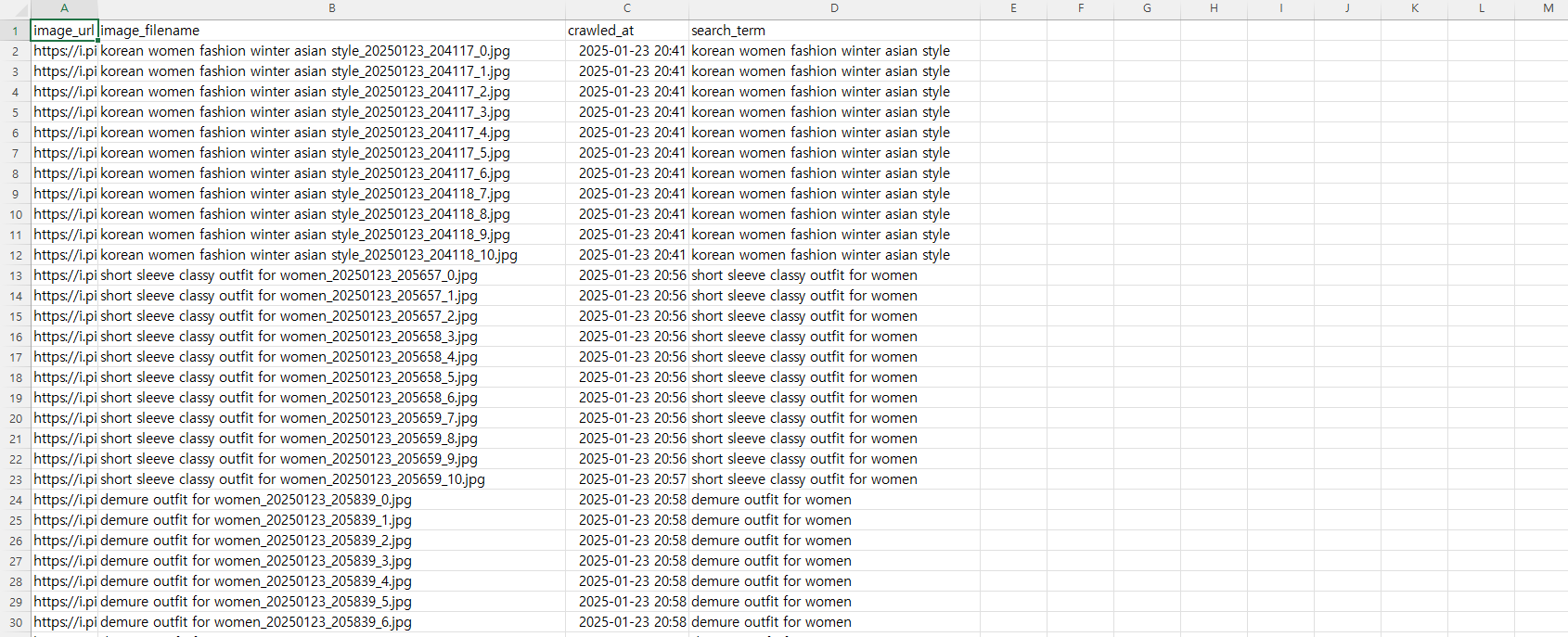
이런식으로 CSV 파일에 저장을 하고,
이미지 자체 파일들은
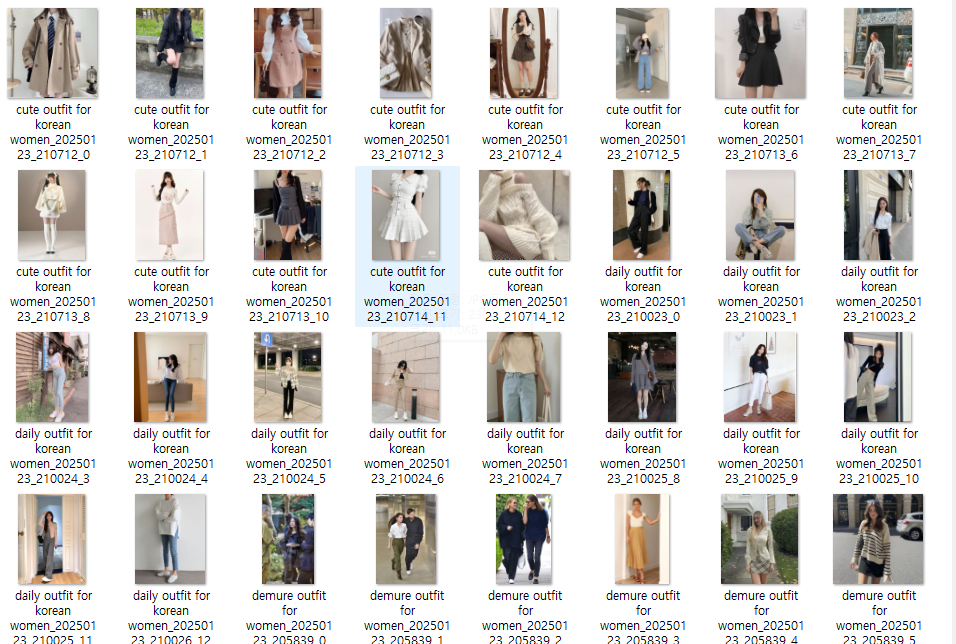
이런식으로 독자적인 폴더에 모이도록 했습니다.
이제 이 결과들을 전처리해서, 사이드프로젝트에 필요한 데이터로 만들어야겠습니다.


Roll with the punches