피드 포워드
입력 데이터의 흐름이 앞으로만 전달되는 신경망
이전 장에서 배웠던 완전 연결 신경망과 합성곱 신경망이 모두 피드포워드 신경망에 속함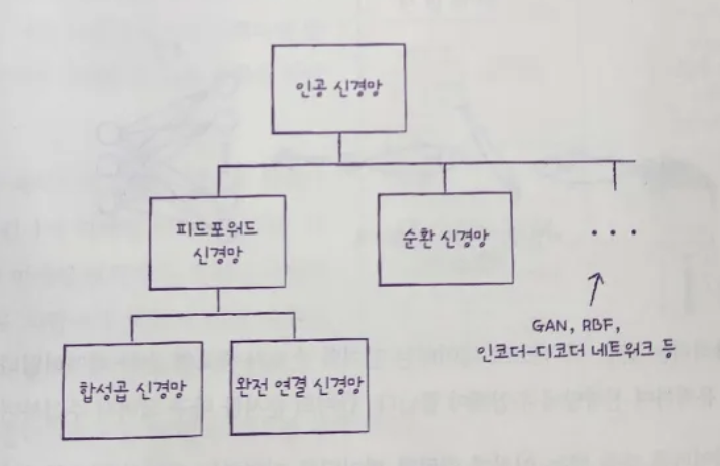
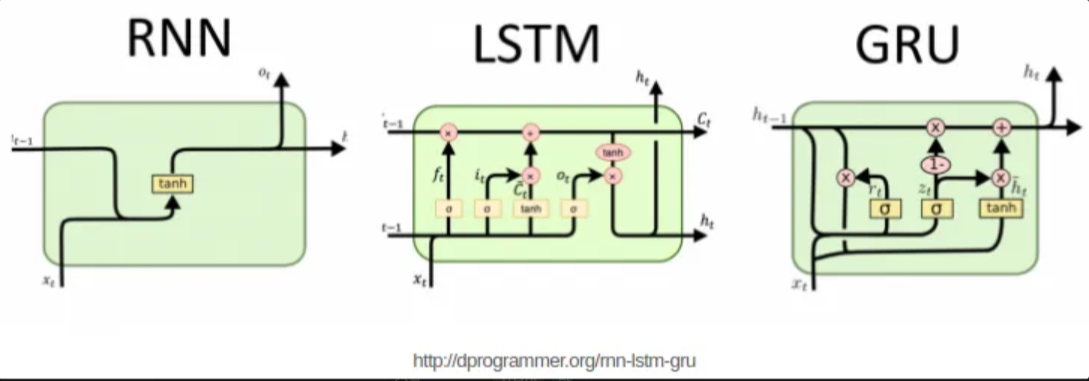
순환 신경망(RNN)
RNN은 일반적인 완전 연결 신경망과 거의 비슷
뉴런의 출력이 다시 자기 자신으로 전달
어떤 샘플을 처리할 때 바로 이전에 사용했던 데이터를 재사용(이전 샘플의 정보를 가지고있음)
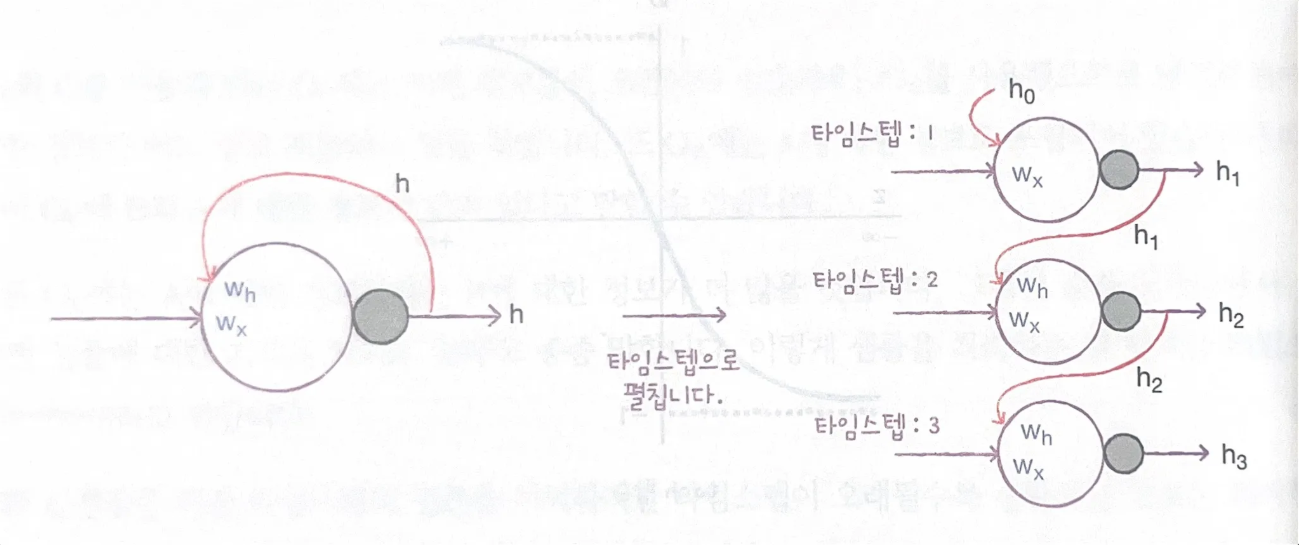
- 타임스텝 : 샘플을 처리하는 한 단계를 의미(한 샘플의 시퀀스의 길이)
- 셀 : 순환신경망에서의 층을 의미
- 은닉상태 : 셀의 출력을 의미tanh 함수
은닉층의 활성화 함수로 하이퍼볼릭 탄젠트 함수사용
tanh 함수는 s자 모양을 띄어 시그모이드 함수라고도 불리지만, 시그모이드 함수와 달리 -1 ~ 1 사이의 범위를 가짐
순환신경망의 활성화함수로 많이 사용순환 신경망의 가중치 크기(모델 파라미터 수)
완전연결망가중치(은닉층X뉴런) + 순환망가중치(뉴런^2) + 각 뉴런 절편순환층의 입력과 출력
샘플마다 2개의 차원을 가짐.
보통 하나의 샘플을 하나의 시퀀스라고 말함.
시퀀스 안에는 여러 개의 아이템들이 있고 이 길이를 타임스텝이라고 함.
by. 정민님
순환 신경망(RNN, Recurrent Neural Network)
순차 데이터
텍스트나 시계열 데이터(일정한 시간 간격으로 기록된 데이터)와 같이 순서에 의미가 있는 데이터를 뜻한다
ex) “I am a boy” 는 이해되지만 “boy am a I”는 말이 되지 않는다
순환 신경망에서는 마지막 셀의 출력이 1차원이기 때문에 Flatten 클래스로 펼칠 필요가 없다. 셀의 출력을 그대로 밀집층에 사용할 수 있다.
SimpleRNN
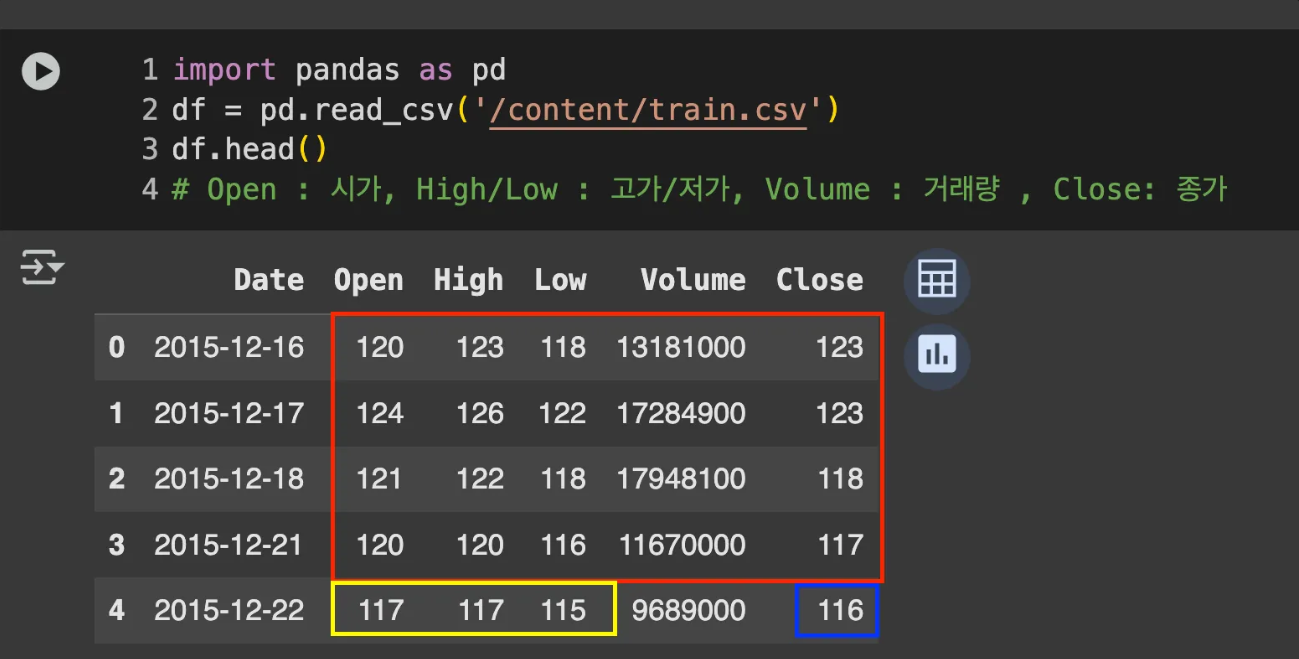
RNN은 이전 시점의 출력을 다음 시점의 입력으로 넘겨서, 시간 순서대로 한 스텝씩 도장 찍듯이 처리하는 신경망이다.
즉, 파란 네모(정답)을 예측하기 위해 노란 네모(같은 행의 값)를 주는 것이 아니라, 빨간 네모(4개행의 각 데이터/하나의 윈도우)를 제공하는 방식이다.
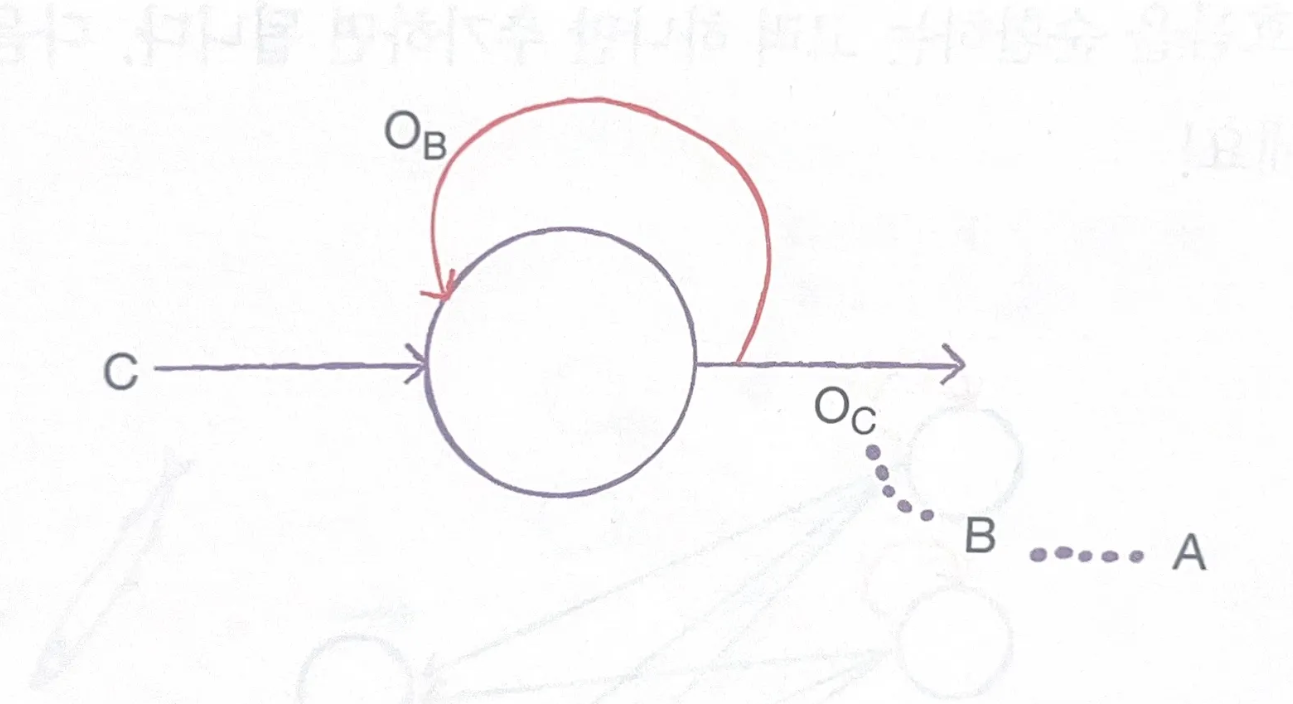
뉴런의 출력이 다시 자기 자신으로 전달된다
= 어떤 샘플을 처리할 때, 바로 이전에 사용했던 데이터를 재사용한다
즉, 이전 타임스텝의 샘플을 기억하지만 오래될수록 순환되는 정보는 희미해진다.
OA는 A를 처리 후 출력된 결과이다.
OA는 다시 뉴런으로 들어가, B를 처리할 때 같이 사용된다.
= OB는 A에 대한 정보가 어느정도 포함되어 있다.
OC에는 OB를 사용하므로, A와 B에 대한 정보가 어느정도 들어있다. 이때, 상대적으로 B에 대한 정보가 더 많이 들어있을 것이다.
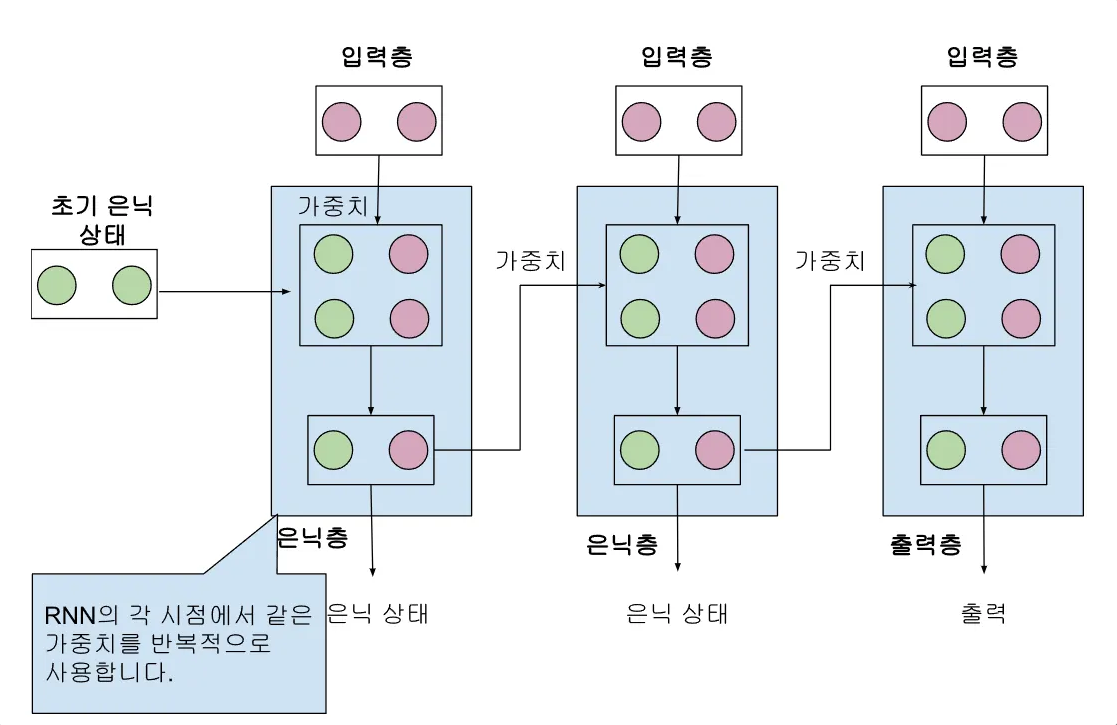
셀(cell) : 순환 신경망에서 층을 부르는 말
은닉상태(hidden state) : 셀의 출력
RNN 코드
-
데이터셋 생성
30일치 과거 데이터를 기반으로 다음날을 예측하기 위한 구조
from torch.utils.data import Dataset, DataLoader import pandas as pd import numpy as np class NetflixDataset(Dataset): def __init__(self,csv_path): df = pd.read_csv(csv_path) self.data = df.iloc[:,1:4].to_numpy() # 0과 1 사이로 정규화 self.data = self.data / np.max(self.data) # 정답(종가) self.label = df.iloc[:,-1].to_numpy() self.label = self.label / np.max(self.label) def __len__(self): return len(self.data) - 30 #시작일로부터 30일치 데이터이므로 (시계열 데이터이기때문에 가능) def __getitem__(self,idx): data = self.data[idx: idx+30] label = self.label[idx+30] return data, label왜 +30/-30을 하는가?
-
idx=0일 때:
data:self.data[0:30]→ 0~29일까지 총 30일치 입력 데이터label:self.label[30]→ 30번째 날(즉, 31번째 날)의 종가 = 우리가 예측해야 할 값
-
len(self.data) = 1000이면, 가능한 샘플 개수는1000 - 30 = 970개
idx=0 → 예측은 30번째 날idx=969 → 예측은 999번째 날idx=970 → self.label[1000]← 이건 존재하지 않음 (오버 인덱스!)
-
-
데이터 분류
시계열 데이터는 shuffle 금지!!!
netflix_dataset = NetflixDataset('/content/train.csv') data, label = next(iter(netflix_dataset)) netflix_dataloader = DataLoader(netflix_dataset, batch_size=32) data, label = next(iter(netflix_dataloader)) data.shape, label.shape -
모델 정의
import torch import torch.nn as nn class NetflixRnn(nn.Module): def __init__(self): super().__init__() #RNN 계층: 입력 feature의 수 / batch_first: 입력의 모양을 배치우선으로 (B, Seq_len, input_size) 로 만든다는 뜻 self.rnn = nn.RNN(input_size=3, hidden_size = 10,num_layers=5,batch_first=True) # RNN 출력 (batch_size, seq_size,hidden_size) (32,30,10) # RNN 출력 전체를 flatten 후 Linear 통과 self.linear1 = nn.Linear(in_features=30*10, out_features=100) self.linear2 = nn.Linear(in_features=100, out_features=1) #값을 예측하고 있으니까 출력은 1개 self.relu = nn.ReLU() def forward(self,x,h0): #h0는 초기 은닉 상태 # RNN 통과: x -> 모든 시점의 hidden output, hn -> 마지막 hidden state들 x, hn = self.rnn(x,h0) # x shape: (batch_size, 30, 10) x = torch.flatten(x,start_dim=1) # x shape: (batch_size, 300) # 분류기 부분 통과 x = self.relu(self.linear1(x)) x = self.linear2(x) return x -
모델 생성 및 학습
from tqdm import tqdm #모델 생성 netflix = NetflixRnn() device = "cuda" if torch.cuda.is_available() else 'cpu' # 손실 함수: 평균 제곱 오차(회귀 문제이므로) loss_fn = nn.MSELoss() # 학습률, 에포크 설정 lr = 1e-4 epocs = 200 # 옵티마이저: Adam 사용 optim = torch.optim.Adam(netflix.parameters(),lr=lr) # 모델을 디바이스에 할당 netflix = netflix.to(device) # 모델 학습 루프 for epoch in range(epocs): iterator = tqdm(netflix_dataloader) epoch_loss = 0.0 for data, label in iterator: # 텐서의 학습은 기본인 torch.float32 타입, 형태: (batch_size, 1) label = label.reshape(-1,1).to(torch.float32).to(device) # 입력 데이터도 float32 data = data.clone().detach().to(torch.float32).to(device) # float -> 32bit # 초기 은닉 상태 0으로 초기화 h0 = torch.zeros(5,data.shape[0],10).to(device) # num_layers, batch_size, hidden_size # 예측 pred = netflix(data,h0) # 손실 계산 및 역전파 loss = loss_fn(pred,label) loss.backward() # 가중치 업데이트 optim.step() optim.zero_grad() epoch_loss += loss.item() iterator.set_description(f"loss : {loss.item()}") # 에포크별 평균 손실 출력 print(f'epoch : {epoch + 1} loss : {epoch_loss / len(netflix_dataloader)}') # 학습된 모델 저장 torch.save(netflix.state_dict(), "netflix.pth") -
평가
# 저장된 모델 불러오기 loaded_model = NetflixRnn() loaded_model.load_state_dict(torch.load('netflix.pth', map_location=device)) loaded_model.eval() pred_lists = [] total_loss = 0.0 # 평가 시 batch_size=1로 설정 loader = DataLoader(netflix_dataset,batch_size=1) # 평가 루프 with torch.no_grad(): for data ,label in loader: h0 = torch.zeros(5,data.shape[0],10).to(device) # 예측 수행 predict = loaded_model(data,h0) # 예측 결과 저장 pred_lists.extend([p.item() for p in predict]) # 손실 누적 loss = loss_fn(predict,label) total_loss += loss.item() # 전체 평균 손실 출력 print(f"loss : {total_loss / len(loader.dataset)}")평가 시 batch_size = 1 인 이유
loader = DataLoader(netflix_dataset, batch_size=1)이 코드는 평가 시 모든 샘플을
하나씩모델에 넣는다는 뜻.보통 시계열 예측에서는 “입력 → 예측 → 그 다음” 식으로 시간 순서를 따라가면서 예측한 값을 차례대로 저장하고 비교하기 때문에
batch_size =1로 하면 예측값이 시간 순서대로pred_lists에 쌓이기 때문에 나중에 분석하기에 용이하다(정확도 평가만 빠르게 하고 싶다면
batch_size > 1로 해도 문제되지 않는다. 하지만 시계열 예측 결과를 하나씩 저장하거나 시각화하는 것이 목적이라면1로 하는게 안정적이다) -
시각화
import matplotlib.pyplot as plt # 전체 데이터 비교 plt.figure(figsize=(15,5)) plt.subplot(1,2,1) plt.plot(pred_lists,label="prediction") plt.plot(netflix_dataset.label[30:], label='real') plt.legend() # 일부 영역 확대 plt.subplot(1,2,2) plt.plot(pred_lists,label="prediction") plt.plot(netflix_dataset.label[30:], label='real') plt.xlim(200,400) plt.legend() plt.show()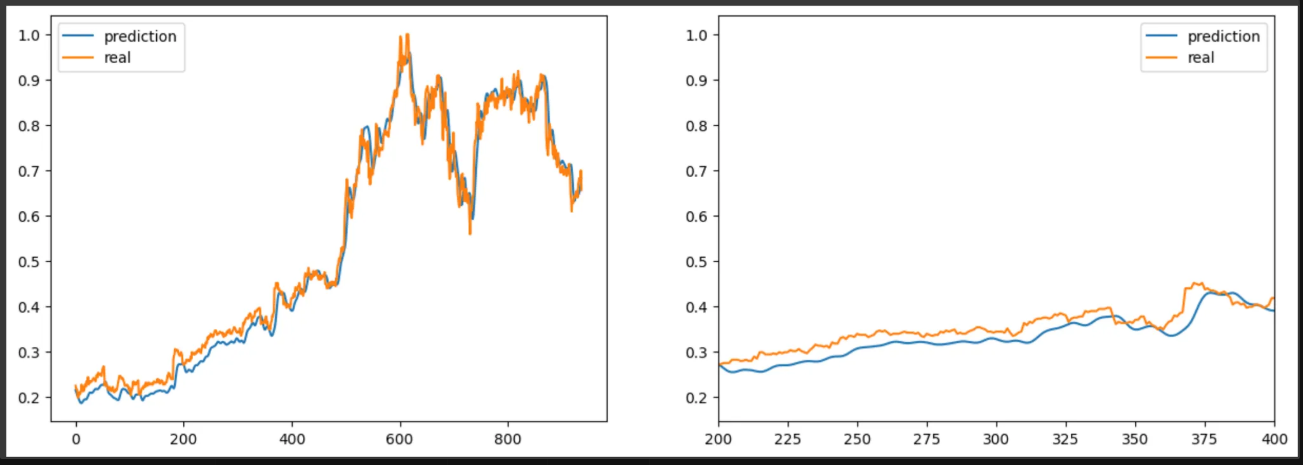
LSTM(Long Short-Term Memory)
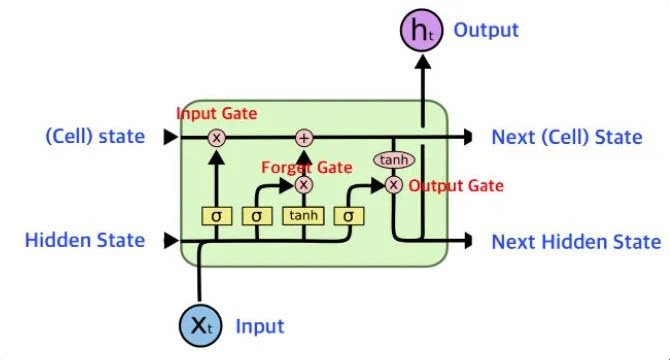
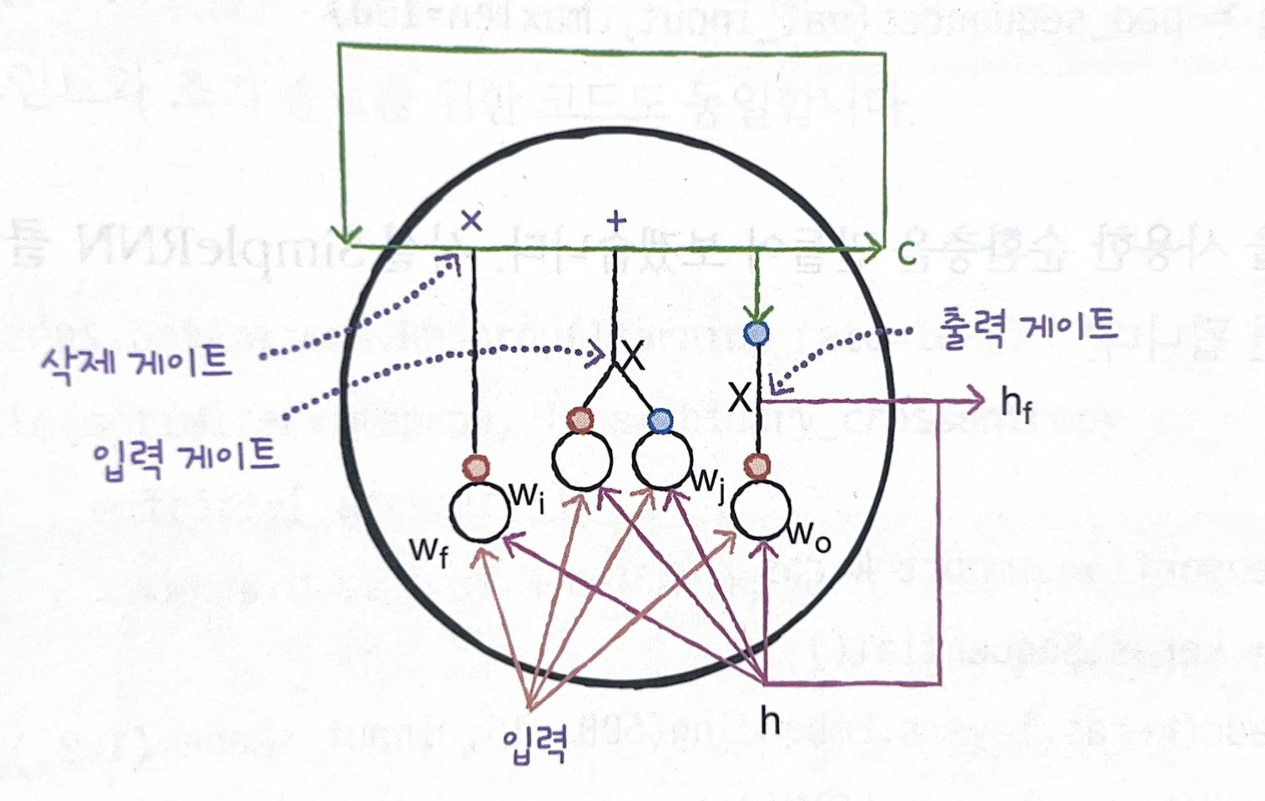
단기 기억을 오래 보존하기 위해(RNN의 단점 보완) 고안되었다.
Input gate(입력 게이트): 얼마나 새 정보를 셀 상태에 반영할지
Forget gate(망각 게이트): 얼마나 기존 셀 상태를 유지할지 결정
Output gate(출력 게이트): 어떤 정보를 은닉 상태로 보낼지
차이점
- 은닉 상태에 활성화 함수를 통과시켜 다음 은닉 상태로 만들 때,
sigmoid함수를 사용한다. 또,tanh함수를 통과한 어떤 값과 곱해져서 은닉 상태를 만든다 - LSTM은 순환되는 상태가 2가지: 은닉 상태(
h), 셀 상태(c)-
셀 상태: 은닉층과 달리 다음 층으로 전달되지 않고 LSTM 셀에서 순환만 하는 값
-
두 값에 곱해지는 가중치 처리 방식이 다르다(셀 상태는 별도의 가중치 행렬을 통해 선형변환되지 않고, 게이트 값과 단순 곱셉으로만 업데이트된다)
항목 은닉 상태 ( h)셀 상태 ( c)가중치 곱? U_f,U_i,U_o,U_c등 가중치 있음가중치 없음, 단순 곱( f_t ⊙ c_{t-1})정보 흐름 출력을 위한 정보 장기 기억 유지용 정보 업데이트 방식 게이트 출력과 tanh, σ 등 다양한 연산 forget/input 게이트와 원소곱으로 조절
-
from tensorflow import keras
model = keras.Sequential()
model.add(keras.layers.Embedding(500,16,input_shape=(100,)))
model.add(keras.layers.LSTM(8))
model.add(keras.layers.Dense(1,activation='sigmoid'))→ 파라미터 수: SimpleRNN의 4배(LSTM안에 작은 셀 4개 있어서)
- LSTM → LSTM 넘어갈 때는 첫 번째 층이 return_sequences=True, 마지막 층은 False 여야 함 ! from 문영님
2개의 층을 연결하기
-
케라스의 순환층에서 모든 타임스텝의 은닉 상태를 출력하려면 마지막을 제외한 다른 모든 순환층에서 return_sequences 매개변수를 True로 지정하면 됨
model3 = keras.Sequential() model3.add(keras.layers.Embedding(500, 16, input_shape=(100,))) model3.add(keras.layers.LSTM(8, dropout=0.3, return_sequences=True)) model3.add(keras.layers.LSTM(8, dropout=0.3)) model3.add(keras.layers.Dense(1, activation='sigmoid')) model3.summary()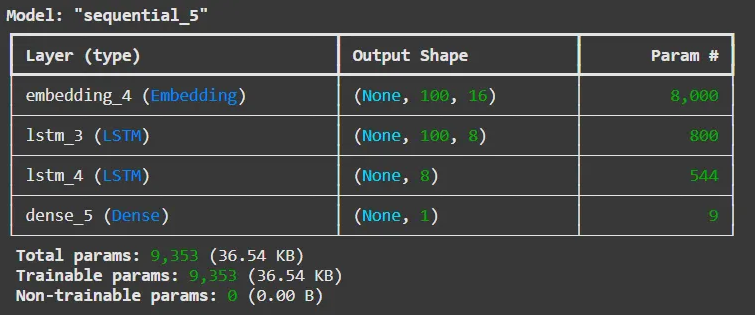
-
- 첫 번째 LSTM 층은 모든 타임스텝(100개)의 은닉 상태를 출력하기 때문에 출력 크기가 (None, 100, 8)로 표시됨. 그러나 두 번째 LSTM 층의 출력 크기는 마지막 타임스텝의 은닉 상태만 출력하기 때문에 (None, 8)으로 표시됨.
- 첫 번째 LSTM : 시퀀스 전체 정보 유지
두 번째 LSTM : 그 시퀀스를 종합해서 최종 정보 하나로 요약
LSTM → LSTM 넘어갈 때는 첫 번째 층이 return_sequences=True, 마지막 층은 False 여야 함 !GRU
LSTM을 간소화한 버전으로, 성능은 비슷한데 구조는 더 단순하다.
- 은닉 상태와 입력에 가중치를 곱하고 절편을 더하는 작은 셀 3개(2개는
sigmoid, 1개는tanh)
Update gate
Reset gate
Candidate hidden state
from tensorflow import keras
model = keras.Sequential()
model.add(keras.layers.Embedding(500,16,input_shape=(100,)))
model.add(keras.layers.GRU(8))
model.add(keras.layers.Dense(1,activation='sigmoid'))→ 파라미터 수: 624개
- 하나의 게이트를 계산할 때 필요한 파라미터 : 200개
- 입력에 곱하는 가중치 16 x 8 = 128개
- 은닉 상태에 곱하는 가중치 8 x 8 = 64개
- 절편은 뉴런마다 하나씩이므로 8개
- 이러한 작은 셀(게이트)가 3개이므로 200 x 3 = 600개
- keras 내부 동작으로 bias가 추가되어서 + 24개 !
GAN(캡챠)
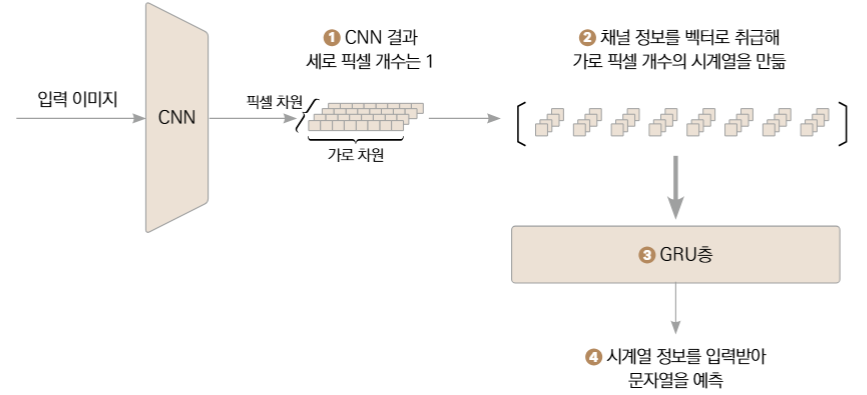
CNN + RNN 의 구조로, 이미지나 시계열에서 공간적 특징과 순차적 흐름을 함께 처리하는 모델이다. 캡차 인식처럼, 이미지로 된 문자가 들어오면 CNN으로 문자 특징을 추출한 다음 RNN으로 문자의 순서를 해석해서 예측하는 것이다.
- CNN (합성곱): 입력 이미지에서 특징 추출
- RNN (GRU): CNN의 출력 시퀀스를 기반으로 시계열 처리
- FC (MLP): 각 시점마다 어떤 문자인지 분류
- CTC 손실 대응: 최종 출력에
log_softmax적용
class CRNN(nn.Module):
def __init__(self,output_size):
super().__init__()
# batch_size 모르니까 None으로
# CNN 계층: (None, 3, 50, 200)
self.block = nn.Sequential(
BasicBlock(3,64), # (None, 64, 24, 196)
BasicBlock(64,64), # (None, 64, 11, 192)
BasicBlock(64,64), # (None, 64, 5, 188)
BasicBlock(64,64), # (None, 64, 2, 184)
#세로 방향의 정보를 한줄(1픽셀)로 압축 -> 가로축만 남아서 시퀀스로 사용 가능
nn.Conv2d(64,64,kernel_size=(2,5)) #(None, 64, 1, 180)
# kernel_size 에서 w:5 는 단어 또는 문자 패턴 뽑기 위함이다(약 5개 안에 하나의 단어가 들어올거다 라고 가정하고)
)
# GRU 정의
self.gru = nn.GRU(64,64, batch_first=False)
# 입력: (seq_len=180, batch, input_size=64)
# (H,B,input_size)
#분류 MLP
self.fc = nn.Sequential(
nn.Linear(64,128),
nn.ReLU(),
nn.Linear(128,output_size) # 각 시점마다 문자 예측
)
def forward(self,x):
x = self.block(x) # CNN 통과: (1, 3, 50, 200) -> (1, 64, 1, 180)
# (B, C, H, W) -> 1,64,180(B,C,W)(0,1,2) 하려면 permute(2,0,1) 필요
x = x.squeeze(2) # 세로(H) 제거 : (1, 64, 180)
x = x.permute(2,0,1) # (180, 1, 64) GRU 입력 형태로 변환
#초기 은닉층(num_layers, batch_size, hidden_size)
h0 = torch.zeros(1,x.size(1), 64)
# GRU 처리
x, _ = self.gru(x,h0)
# 각 시점마다 문자 분류
x = self.fc(x)
#CTC 손실계산
x = F.log_softmax(x, dim=-1)
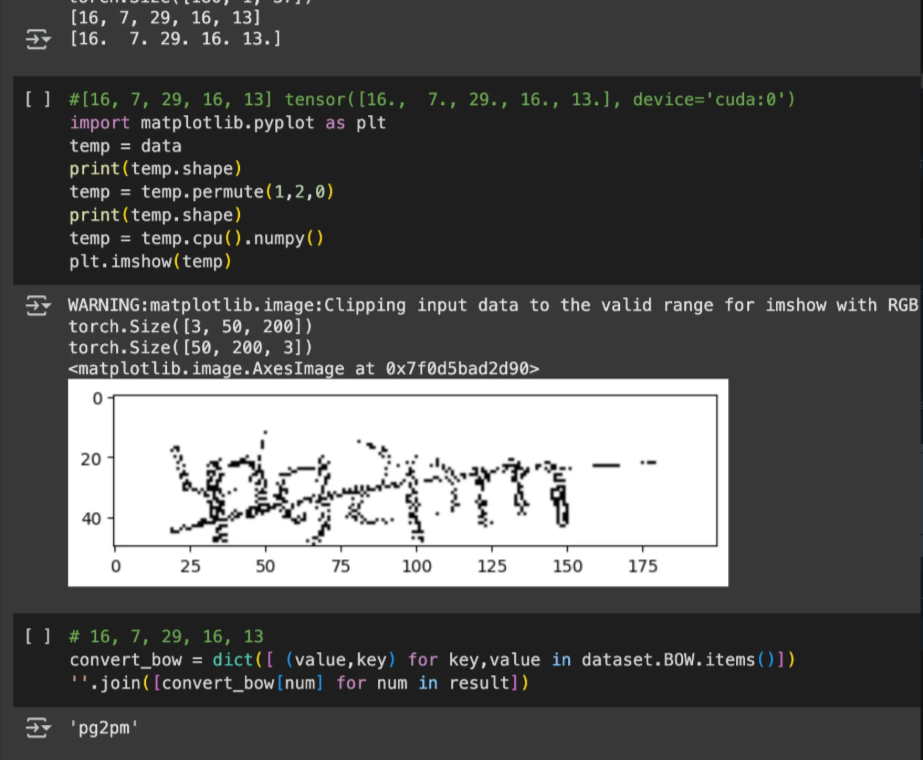
return x데이터 처리 단계 요약
- CNN 거치기 전 이미지는
(B,C,H,W) - 합성곱 층을 전부 통과하면
(B, 64, 1, 180): 텍스트 이미지의 가로 방향 흐름이 180개의 '타임스텝'이 된다 - GRU 입력 형태로 변환하면
(180, B, 64) - MLP : 각 가로 픽셀 하나가 어떤 문자(class)에 속하는지 예측
- chatgpt: 왜 reshape이 필요한가 아주 좋은 질문이에요! 👏 "차원을 맞추기 위해
flatten()하는 것"과 "GRU 입력 형태로 맞추기 위해 세로길이를squeeze()하는 것"은 비슷한 맥락도 있고, 중요한 차이점도 있어요. 아래에서 둘을 비교해서 설명드릴게요:공통점:
둘 다 모델에 맞는 입력 차원으로 데이터를 reshape(재구성) 하기 위한 작업입니다.목적 차원 조정 모델이 원하는 입력 형태에 맞추기 위해 차원을 줄이거나, 바꾸거나, 펼치는 작업 차이점:
항목 flatten()squeeze()(orpermute, reshape for RNN)목적 완전히 1D 벡터로 만들어 MLP(선형 계층)에 넣기 위함 시퀀스 데이터로 바꾸기 위해 차원을 재배열 사용 위치 CNN → MLP 연결 전에 주로 사용 CNN → RNN 연결 전에 사용 결과 (B, C×H×W)형태의 벡터(Seq_len, B, Feature)또는(B, Seq_len, Feature)예시 비교
①
flatten():x = x.view(batch_size, -1) # or torch.flatten(x, start_dim=1)-
예:
(B, 64, 7, 7)→(B, 3136) -
목적: MLP (
nn.Linear)에 넣기 위해 1차원 벡터로 펼침②
squeeze()+permute()(for RNN like GRU):x = x.squeeze(2) # (B, 64, 1, 180) → (B, 64, 180) x = x.permute(2, 0, 1) # → (180, B, 64) -
목적: 가로 방향 픽셀을 시간 축으로 보고 GRU에 넣기 위한 변형
-
여기서는
flatten하지 않고 "시퀀스 처리"에 적합한 구조로만 바꿈
핵심 요약
개념 flatten squeeze & permute 쓰는 위치 CNN → MLP CNN → RNN 결과 형태 (B, Feature) (Seq_len, B, Feature) 목적 벡터로 펼쳐서 선형계층에 넣기 시퀀스 구조로 변환해서 RNN에 넣기 데이터 의미 유지 여부 공간 구조 무시 시퀀스 의미 유지 (예: 가로 방향 문자 순서)
비유로 설명하면:
-
flatten()은 이미지를 일렬로 쫙 펼치는 것 (의미 상실 가능) -
squeeze()+permute()는 시퀀스 구조를 유지한 채로 배치하는 것 (의미 보존)
필요하다면
flatten,view,reshape,permute등의 차이도 더 정리해드릴 수 있어요!좋은 질문이에요!
-
*"가로 방향 픽셀을 시간축으로 본다"는 말을 이해하려면 먼저 GRU 같은 순환 신경망이 입력을 어떻게 처리하는지**를 이해해야 해요.
GRU의 입력 형태
GRU는 입력을 보통 다음과 같은 형태로 받습니다:
(seq_len, batch_size, input_size)즉, 하나의 시퀀스 = 여러 개의 시점(time step) 으로 구성되어 있고,
각 시점마다 하나의 벡터 (input_size) 를 입력받습니다.
CNN의 출력 (예: 문자 이미지)
CNN을 통과한 뒤의 출력 텐서:
(B, C, H, W) = (batch_size, channel, height, width)이제 이걸 RNN에 연결해야 하니까, 어느 방향을 시퀀스로 볼지 정해야 해요.
왜 "가로(W)를 시간축"으로 보는가?
문자나 문장의 이미지를 보면 보통 글자들이 가로 방향으로 나열되어 있죠?
예시: "CRNN" -> 이미지에서 왼쪽부터 C → R → N → N -
그래서 가로 방향(W) 을 시간 순서로 보고,
-
세로 방향(H) 은 글자의 세부적인 시각적 정보 (높이, 세로 모양 등)라고 보면 됩니다.
그럼 왜 세로(H)를 삭제(squeeze)하나?
CNN을 거친 후에는 보통 다음처럼 나옵니다:
(B, 64, 1, 180)여기서:
-
64: 채널 (특징 맵의 개수) -
1: 세로 방향 (높이) -
180: 가로 방향 (폭, 시퀀스 길이)즉, CNN을 통해 세로 방향 정보는 이미 모두 요약되었고,
H = 1이 되어 더 이상 시퀀스 정보로서 쓸모가 없습니다.그래서 이걸
squeeze(2)해서 차원을 없애주면:(B, 64, 180)이제 이걸 GRU에 넣기 위해 permute 하면:
(180, B, 64) # → 시퀀스 길이 180, 배치 B, 특성 64이렇게 되면 각 가로 픽셀 위치가 하나의 시점(time step) 이 되고,
그 시점마다의 정보가 64차원의 벡터로 표현되는 거예요.
정리
항목 의미 왜 가로(W)가 시간축인가? 문자가 가로로 나열되니까 시간 순서로 볼 수 있음 세로(H)는 왜 1인가? CNN에서 세로 방향을 다 통합했기 때문 그래서 squeeze(H)? 쓸모 없는 차원이니까 없애서 RNN에 넣기 좋게 만듦
-
