
하려는 것 : S3에 저장된 파일 속의 내용을 읽어서 원하는 형태로 mongoDB에 새 document로 생성하기!
저장할 파일 : 이전에 블로깅한 txt file => s3 upload진행한 내용
환경
- S3
[S3 내 구조]
.
├── 조건1
│ ├── 파일1
│ └── 파일2
├── 조건2
│ ├── 파일1
│ └── 파일2
└── 조건3
├── 파일1
├── 파일2
└── 파일3
# 파일 속 내용 : 다음의 형태가 string으로 기록됨
{time : 기록 날짜, name : 이름, age : 나이, hobby : 취미}
# 이때 기록날짜는 datetime.datetime 형태이다- DB : mongoDB
------------------------------
0. S3에 접근하기 : aws 액세스키
먼저 S3에 접근하는 경로를 선택해야 한다.
1. 퍼블릭 bucket에 접근한다
2. bucket에 접근할수 있는 정책을 가진 사용자를 사용한다.
나의 경우 처음에 퍼블릭 bucket임에도 불구하고 aws_access 키를 요구했어서.. 꽤나 고생하면서 액세스 키까지 발급받고 진행하긴 했다. 나중에 다시해보니 해당 키 내용을 제거하고 bucket이름만 명시해도 접근이 되더라! 그치만 둘다 해봤으므로 모두기록한다.
1) 유효한 정책을 지닌 사용자 이용하기
먼저 이용하고자 하는 사용자의 액세스 키를 발급받아야 한다.
이를 위해선 로그인 후 화면 우측 상단의 username을 클릭해 드롭다운박스에 보이는 내 보안 자격 증명을 들어간다.

이후 액세스 키를 들어가 새로운 액세스 키를 발급받도록 한다!
해당 정보가 기록된 문서는 생성시에만 다운 가능하다!! 이점유의해서 꼭 명확한 경로에 저장하도록 하자
(혹시나 분실했을 경우 해당 액세스 키를 삭제하고 다시 발급받으면 된다. 주기적으로 교체해 주는것도 보안상 중요!)
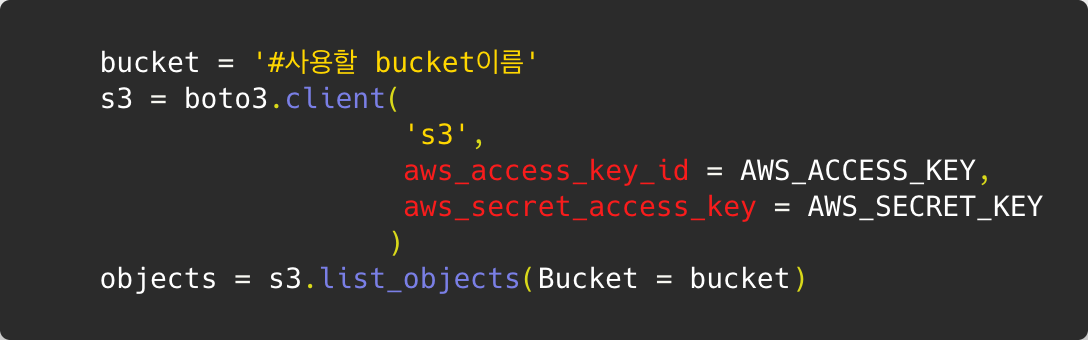
aws client
터미널상에 액세스키에 대한 정보를 입력하고 해당 계정으로 aws 서비스를 이용하는것으로 이해했다..! 처음엔 무조건 이를 수행해야 되는줄 알았는데 그냥 로직상에 액세스키 번호를 입력해주면 되더라! 일단 해보긴 했다.
=> 터미널상에서 aws client를 사용하기 위해 awscli 모듈을 설치해 준다. 그리고 액세스 키에 대한 정보를 입력한다.
> pip install awscli
> aws configure --profile #사용할name
>>> access_key 입력
>>> secret_key 입력
>>> region 입력 (나의 경우 ap-northease-2)그럼 설정 끝!
이걸 하면 로직상 액세스키를 입력안해줘도 되는거같긴한데 쓰는 방법은 모르겠다.. 그래서 그리고 나서 코드상에 boto3를 이용해 s3와 연결하면서 bucket에 접근할때 해당 키값을 다시 명시해 주었다. ㅎㅎ;
2) 퍼블릭 bucket에 접근하기
이거는 여러번 삽질끝에 한 것이라 한번에 성공하는 법은 모른다!
하지만 bucket의 버킷정책에 다음과 같이 입력하였다.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "PublicRead",
"Effect": "Allow",
"Principal": "*",
"Action": [
"s3:*Object",
"s3:*ObjectVersion"
],
"Resource": "arn:aws:s3:::{내 bucket이름}/*"
}
]
}*은 전부를 뜻한다는거!
이 설정의 경우 다음과 같이 접근할수 있는걸로 알고있다...! (이렇게 말하는 이유는 내가 한번에 성공하지 못했기 때문)

------------------------------
2. bucket내의 파일 이름 읽어오기 : list_objects
boto3.client의 속성을 검색해 보았다.
엄청많다...! 궁금하면 boto3가 설치된 환경에서
#python shell
>>> import boto3
>>> s3 = boto3.client('s3')
>>> s3. #입력 후 tap 키를 누른다.구글링 하면서 알아낸 것은 해당 bucket의 모든 object들을 읽어오는 s3.list_objects라는 속성이다.
하위개념 X
S3에 저장할때 폴더 내에 파일을 저장할 수 있다. 그렇게 되면 폴더와 파일의 이름형식은 다음과 같이 설정된다.
# 폴더1
폴더1/
# 폴더1 내의 파일1
폴더1/파일1하지만 위의 list_objects를 사용하면 폴더 자체로도 object로 여겨져 이를 불러온다.
# list_objects 결과
- 폴더1/
- 폴더1/파일1list_objects를 사용해 bucket에 저장된 object들을 확인해보자. 전부를 가져오면 hostid나 기타등등의 정보도 다 불러와지니까 딱 원하는 정보인 저장된 객체에 대한 것만 확인해보자 그러기 위해선 가져온 object의 Contents키의 내용을 확인하면 된다.
이말은 즉 list_objects로 가져온 s3의 objects들은 dictionary형태로 온다는 말이다.
import boto3
s3 = boto3.client('s3', accesskey, secretykey)
obj = s3.list_objects(Bucket='velog-practice')
print("저장된 것 :", obj['Contents']
>>>
저장된것 [
{'Key': '2021-06-20-PM05/green5.log', 'LastModified': datetime.datetime(2021, 6, 20, 14, 21, 49, tzinfo=tzutc()), 'ETag': '"~~~~"', 'Size': 78, 'StorageClass': 'STANDARD', 'Owner': {'ID': '~~~'}},
{'Key': '22021-06-20-PM05/purple5.log', 'LastModified': datetime.datetime(2021, 6, 20, 14, 21, 50, tzinfo=tzutc()), 'ETag': '"~~~~"', 'Size': 79, 'StorageClass': 'STANDARD', 'Owner': {'ID': '~~~'}},
{'Key': '2021-06-20-PM05/red5.log', 'LastModified': datetime.datetime(2021, 6, 20, 14, 21, 49, tzinfo=tzutc()), 'ETag': '"~~~~"', 'Size': 78, 'StorageClass': 'STANDARD', 'Owner': {'ID': '~~~'}},
{'Key': '2021-06-20-PM05/yellow5.log', 'LastModified': datetime.datetime(2021, 6, 20, 14, 21, 50, tzinfo=tzutc()), 'ETag': '"~~~~"', 'Size': 79, 'StorageClass': 'STANDARD', 'Owner': {'ID': '~~~'}},
{'Key': '22021-06-20-PM12/green.log', 'LastModified': datetime.datetime(2021, 6, 20, 14, 21, 49, tzinfo=tzutc()), 'ETag': '"~~~~"', 'Size': 76, 'StorageClass': 'STANDARD', 'Owner': {'ID': '~~~'}},
{'Key': '2021-06-20-PM12/purple.log', 'LastModified': datetime.datetime(2021, 6, 20, 14, 21, 50, tzinfo=tzutc()), 'ETag': '"~~~~"', 'Size': 77, 'StorageClass': 'STANDARD', 'Owner': {'ID': '~~~'}},
{'Key': '2021-06-20-PM12/red.log', 'LastModified': datetime.datetime(2021, 6, 20, 14, 21, 49, tzinfo=tzutc()), 'ETag': '"~~~~"', 'Size': 79, 'StorageClass': 'STANDARD', 'Owner': {'ID': '~~~'}},
{'Key': '2021-06-20-PM12/yellow.log', 'LastModified': datetime.datetime(2021, 6, 20, 14, 21, 50, tzinfo=tzutc()), 'ETag': '"~~~~"', 'Size': 80, 'StorageClass': 'STANDARD', 'Owner': {'ID': '~~~'}}
]내가 원한것은 폴더 안에 속한 파일들은 dictionary속 list로 묶는 형태였으므로 이를 위해 가공이 필요했다.
3. {폴더 : [폴더 내 파일들]} : python의 lambda
저장된 objects의 형태를 보면 폴더명/파일명의 형태이다. 폴더명은 통일되도록 일시로 저장되게 하였고, 같은 일시에 작성된 것들은 같은 폴더에 저장된다.
오랜만에 python의 lambda 함수를 사용해 보자!
순서는 다음과 같다.
- s3의 Contenst내용을 가져온다. 이때 file들은 list형태의 Contenst의 dictionary속
Key값에 저장되어 있다.- folder이름만을 담은 list를 선언한다.
- lambda를 활용해 folder명이 같은 file들끼리 묶어준다.
# 과정
obj = s3.list_objects(Bucket=bucket)['Contents']
obj_key = [row['Key'] for row in obj]
folder_list = []
for row in obj_key:
if row[:15] not in folder_list:
folder_list.append(row[:15])
res_list = []
for row in folder_list:
gather_files = list(filter(lambda x:x[:15] == row, obj_key))
tmp_dict = {}
for row in gather_files:
if not tmp_dict:
tmp_dict = {row[:15]: []}
else:
tmp_dict[row[:15]].append(row[16:])
if tmp_dict:
res_list.append(tmp_dict)
>>> res_list = [
{'2021-06-20-PM05': ['purple5.log', 'red5.log', 'yellow5.log']},
{'2021-06-20-PM12': ['purple.log', 'red.log', 'yellow.log']}
]
4. 파일 내 data 읽기 : get_object
반복문을 통해서 진행한다.
from ast import literal_eval
for row in res_list:
for file_name in list(row.values())[0]:
folder_name = row.keys()
log_file = s3.get_object(Bucket='velog-practice', Key=(list(folder_name)[0]+'/'+file_name))
tmp_content = log_file['Body'].read().decode('utf-8')
log_content = literal_eval(tmp_content)여기서 get_object가 사용되었는데 흐름상 알수 있듯이 해당 파일 속의 내용을 읽는 속성이다. 이때 byte
타입으로 기록되기 때문에 decoding을 해주어야 하며, 단순 string 형태이기 때문에 dictionary 형태를 원한다면 형변환을 해주어야 한다. 따라서 literal_eval을 사용하였다.
5. mongoDB에 저장하기
나는 반복문을 통해 s3내용을 읽을때마다 mongoDB에 저장하는걸 택했다. 따라서 위의 반복문에 이 코드를 추가한다.
db.velog_practice.insert_one(log_content)6. 저장된것 확인하기
tool로 확인할수도 있지만 귀찮으니 명령어로 확인하자.
for row in list(db.velog_practice.find({})):
print("db에 저장된 data==========> : ", row)
db에 저장된 data==========> : {'_id': ObjectId('60cf5e051ea5f74dca0ab836'), 'name': 'purple5', 'age': 4, 'hobby': 'hiking', 'time': '2021-06-20-17-00-00'}
db에 저장된 data==========> : {'_id': ObjectId('60cf5e051ea5f74dca0ab837'), 'name': 'red5', 'age': 1, 'hobby': 'dancing', 'time': '2021-06-20-17-00-45'}
db에 저장된 data==========> : {'_id': ObjectId('60cf5e051ea5f74dca0ab838'), 'name': 'yellow5', 'age': 2, 'hobby': 'reading', 'time': '2021-06-20-17-00-30'}
db에 저장된 data==========> : {'_id': ObjectId('60cf5e051ea5f74dca0ab839'), 'name': 'purple', 'age': 4, 'hobby': 'hiking', 'time': '2021-06-20-12-00-00'}
db에 저장된 data==========> : {'_id': ObjectId('60cf5e051ea5f74dca0ab83a'), 'name': 'red', 'age': 1, 'hobby': 'dancing', 'time': '2021-06-20-12-00-30'}
db에 저장된 data==========> : {'_id': ObjectId('60cf5e051ea5f74dca0ab83b'), 'name': 'yellow', 'age': 2, 'hobby': 'reading', 'time': '2021-06-20-12-00-20'}------------------------------
끝!!!
그런데 일할때랑 혼자 연습할때랑 다른점이있다...! 연습때는 list_objects로 s3 버킷 내 모든 objects들을 불러올때 folder만 불러와지진 않은듯..? 이거때문에 구분하는 고생을 한건데.. 다시 확인해 보았다.
이를 위해 연습때는 aws 사이트에서 폴더생성없이 바로 file명에 "/"를 붙여 폴더 속에 파일로 생성되게 했었다.
이번에는 비교를 위해 aws 사이트에서 폴더를 생성하고, 그 속에 log 파일을 넣은 뒤 확인해 보았다.
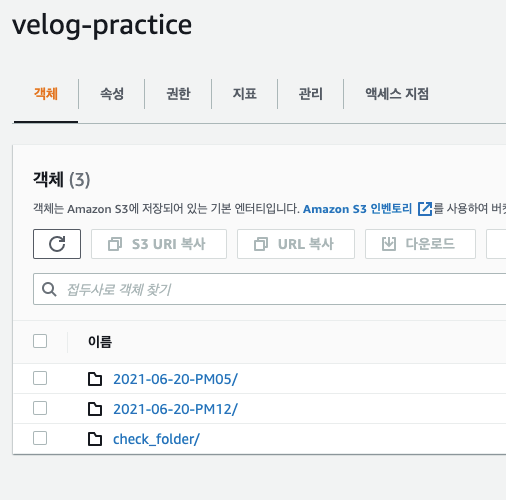
# list_objects로 확인 결과
['2021-06-20-PM05/green5.log', '2021-06-20-PM05/purple5.log', '2021-06-20-PM05/red5.log', '2021-06-20-PM05/yellow5.log',
'2021-06-20-PM12/green.log', '2021-06-20-PM12/purple.log', '2021-06-20-PM12/red.log', '2021-06-20-PM12/yellow.log',
'check_folder/', 'check_folder/check.log']
즉, aws내에서 임의로 폴더를 생성하고, 그 속에 file을 넣을 경우 list_objects로 읽을 시 folder만도 같이 읽힌다.
이와 달리 s3에 없로드 시 "/"사용을 통해 folder가 자동으로 생성되고, 그 속에 file이 저장되게 하면 list_objects사용 시 정확히 내가 넣은 file들만 읽힌다. 단, 폴더명/파일명으로 읽힌다.
오.. 코드 수정할 수 있겠는걸? 월요일이 기대된다! 헷! 🥰
