
챗봇관련 과제를 받았는데 가능하다면 부하 관련하여 성능을 향상시켜달라는 요청도 있었다. 이와 관련하여 원래 공부하고, 적용해보려고 했던 Redis를 사용하기로 했다.!
짧은 시간 안에 얼마나 깊게 파악할수 있을진 모르겠지만 과제를 떠나서 일단 개념 정리하고, 적용해 보는것을 목표로!
메모리 캐싱
"메모리 캐싱"을 하는 이유는 무엇?? 이라고 하면 다음과 같다.
- 서비스 요청의 증가 (매우많이)
- DB요청이 매우 많아진다 => DB server의 부하가 증가한다
- 🔥 메모리 캐시 적용 🔥
- 성능 및 처리 속도가 향상된다. (DB Read의 부하 감소 가능)
그렇다면 DB server의 부하란 무엇인가?
DB server 부하
---------------------------
성능 알아보기 :
측정 대상은 지난 1차 프로젝트때 작성한 "Sweethome" 의 posting 관련 로직이다.
1. loadtest
먼저 npm install로 설치되는 loadtest를 통해 간단히 호출에 걸리는 시간을 알아보자.
설치방법은 공식문서를 참고하였다.
npm install loadtest로는 가동이 안되어서
sudo npm install -g loadtest로 설치해주었다.
1) 단일 쓰레드 환경
설치 후 python manage.py runserver로 서버를 켠 뒤 명령어를 통해 loadtest 결과 확인.
loadtest -n 10 http://127.0.0.1:8000/posting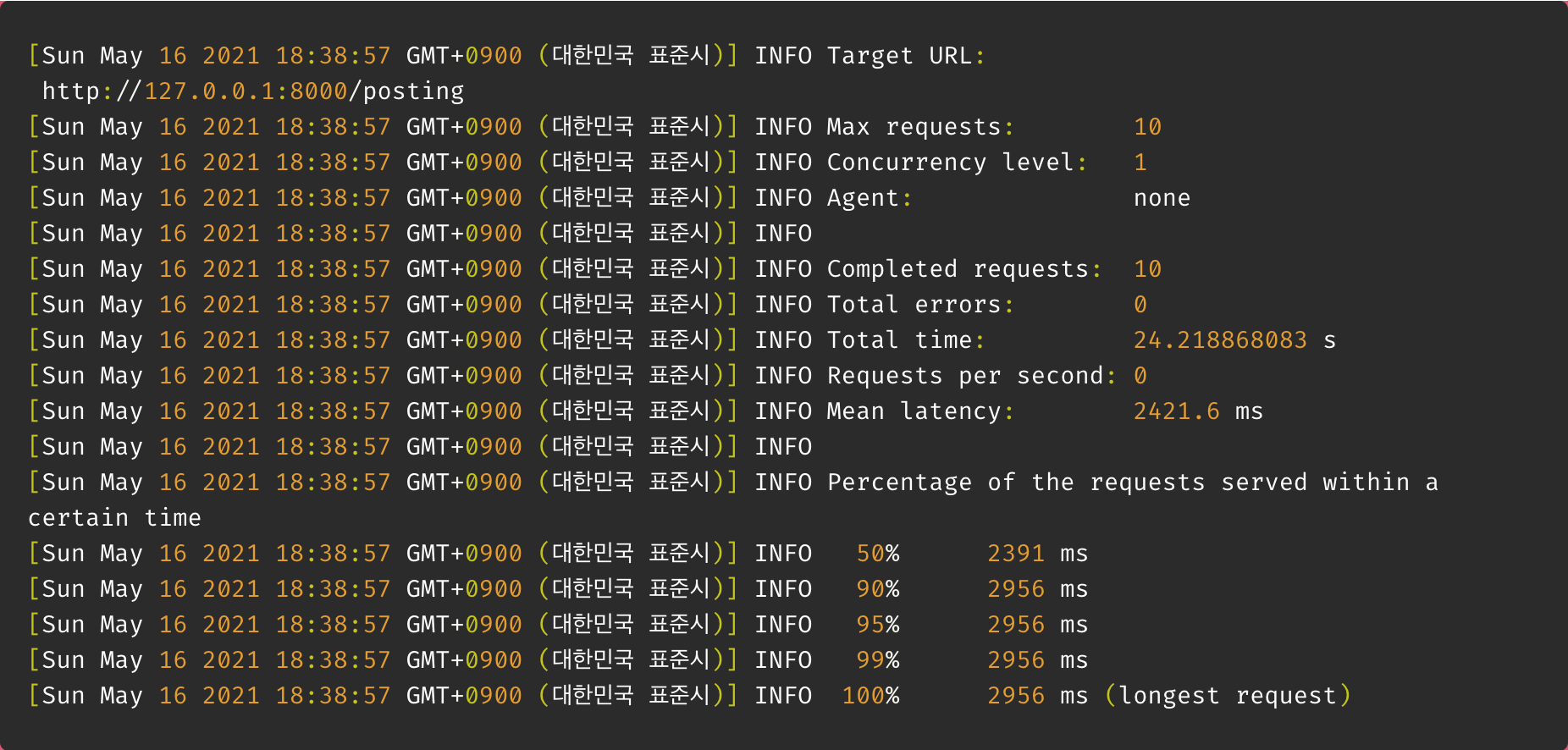
결과 : 24초
10명의 유저 말고 100명의 유저일때를 가정해 테스트해 보았다.
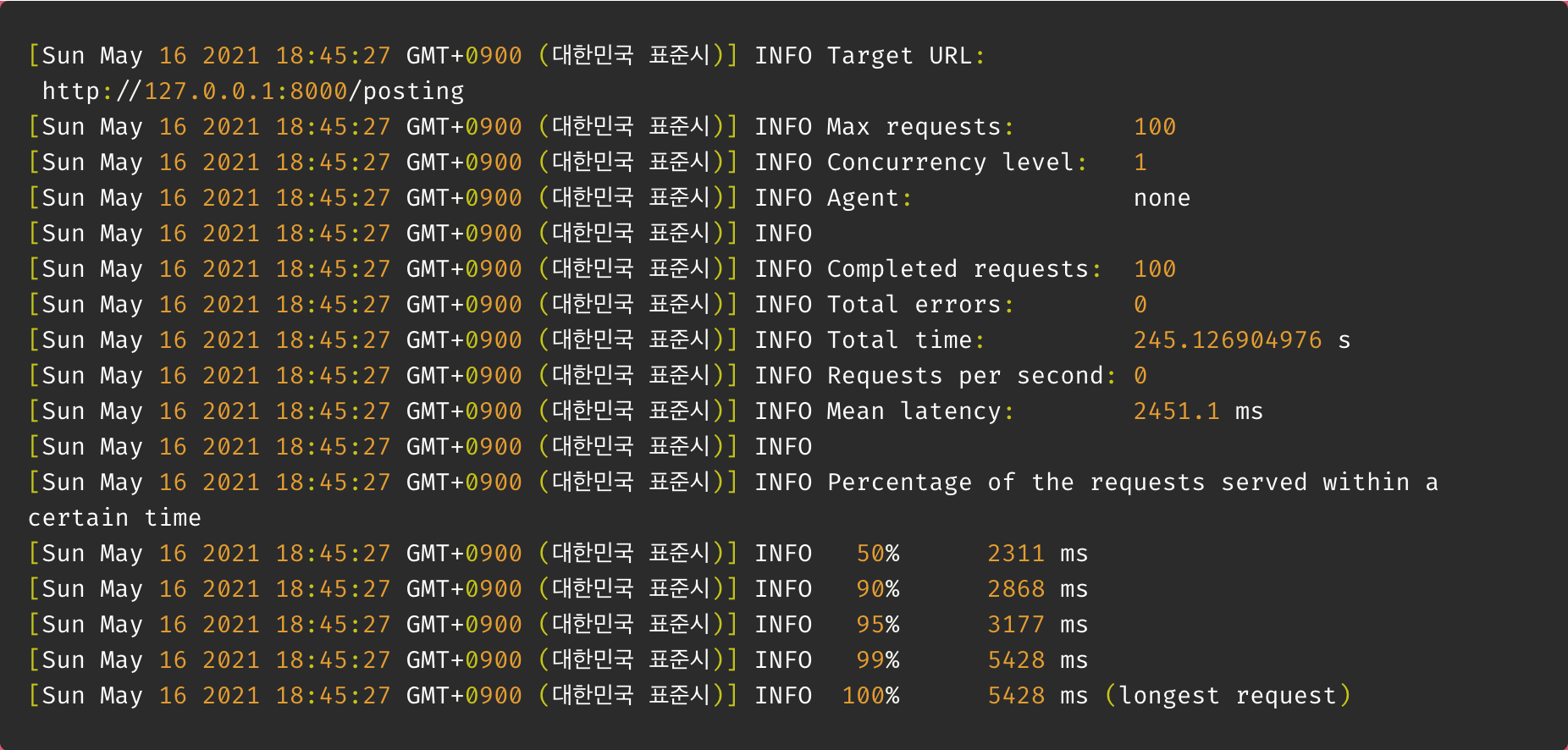
결과 : 245초
2) 멀티 쓰레드 환경
gunicorn 을 사용해 멀티쓰레드 환경일때도 확인해 보았다.
loadtest -n 10 http://0.0.0.0:8000/posting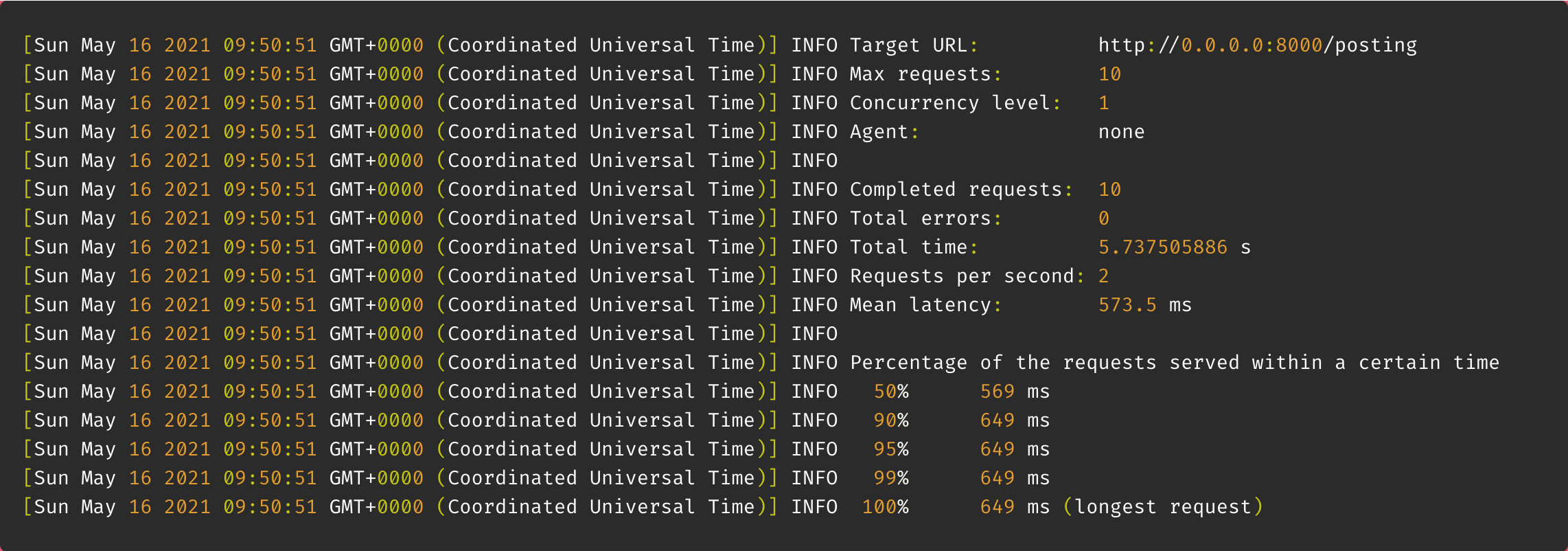
결과 : 5초
100명일때도 확인해 보았다.
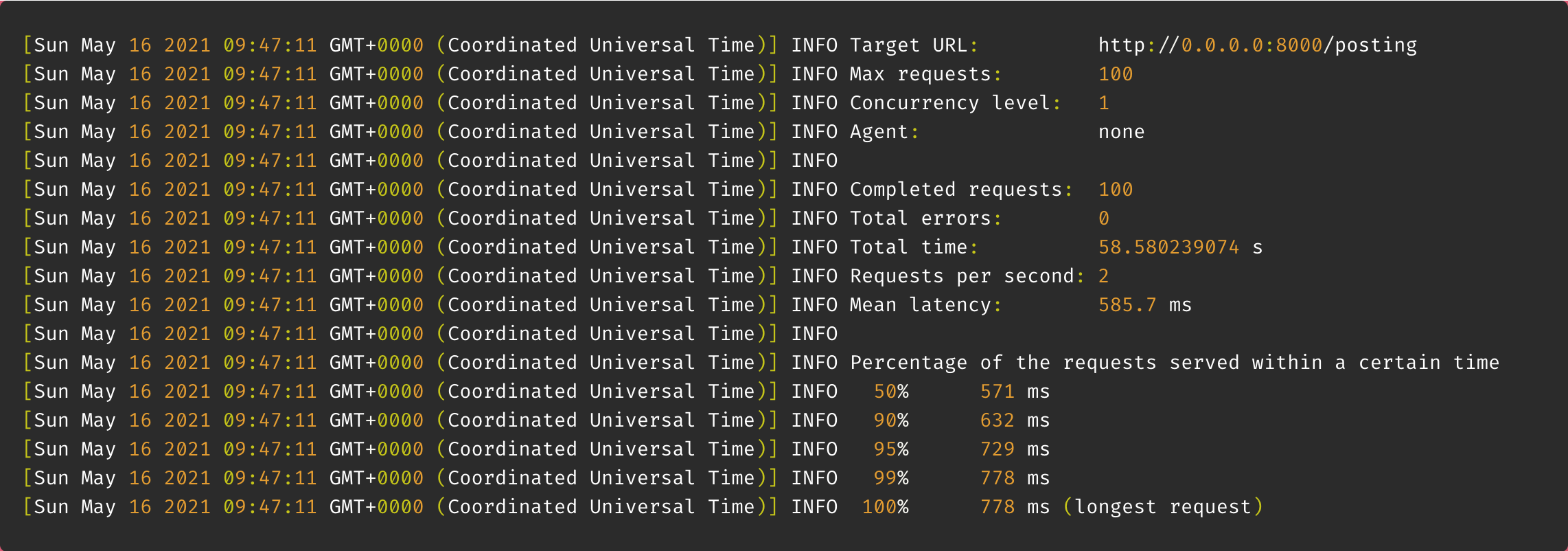
결과 : 58초
약 5배의 속도차이를 보였다.
2. locust
다음은 locust를 통해 확인해 보았다.
당시 코드를 보면 다음과 같다.

이왕 성능체크하는거 prefetch_related와 select_related를 사용하기 전과도 비교해 보도록 하자. 그래서 코드를 다음과 같이 수정하였다.

1) file 작성
부하성능을 알아보기 위해 선택한 것은 locust를 사용하는 방법이다.
이는 python에서 제공하는 모듈로 간단히 pip install locust를 통해 설치할 수 있다.
이후 locust를 실행시킬 명령어들이 작성된 파일을 작성한다.
기본적인 틀은 공식문서를 참고했다.
# locust_test.py
from locust import User, task, between
class PostingReadTest(User):
wait_time = between(1, 2.5)
@task
def my_task(self):
self.client.get("/posting")locust attribute
wait_time
wait_time 이라는 메소드는 증가되는 user들 간의 딜레이 타임을 의미한다.즉, 새로운 요청이 어느 시간 간격으로 들어오는지를 나타낸다. 이 메소드는 3가지의 built in 속성이 있다.
- constant : 고정된 시간
- between : min과 max를 지정해 그 시간 사이의 랜덤한 시간
- constant_pacing : 최소 지정된 시간에 한번씩은 실행되도록 지정한 시간
이중에서 내가 사용한 것은 between이다. (실제로 user는 규칙적인 시간 텀을 두고 들어오지 않으니)
@task
@task는 task를 지정하는 가장 쉬운 방법인 task decorator를 의미한다.
이를 사용하면 선택적으로 로직의 구현 비중을 조절할 수 있다. (=weight를 지정할 수 있다.)
예를 들어 다음과 같은 코드가 있다고 가정하자.
# locusttest.py
from locust import User, task, between
class MyUser(User):
wait_time = between(5, 15)
@task(3)
def task1(self):
pass
@task(6)
def task2(self):
pass이런식으로 작성된 locust 코드가 있다면 @task로 묶인 함수에 대해서 task1이 3번 호출될동안 task2는 6번 호출되도록 한다.
class : User
class에 사용된 parameter로 User라는 것이 사용되었다. 이는 locust의 클래스인데 이로 인해 내가 작성한 class는 User 클래스를 상속받게 된다. Locust는 테스트되는 동안 각 user에 대해 User class의 instance 하나를 생성한다.
class : HttpUser
HttpUser class는 User class보다 더 흔하게 사용된다. User와 달리 HttpUser에는 client 속성이 추가되어 있는데 이를 통해서 HTTP request로 테스트가 가능하다.
여기서 client는 HttpSession의 instance이다.또한 HttpSession은 requests.Session의 하위 클래스이다. 추가적인 공부가 필요한 부분
client속성은 모든 HTTP methods를 포함한다! GET / POST / PUT 등... 즉, 위에서 말했던 것 처럼 method에 맞는 HTTP request 테스트가 가능하다.
🔥 Error 발생
위에서 작성한 코드대로 locust를 실행했더니 다음과 같은 에러가 발생했다.
AttributeError: 'NoneType' object has no attribute 'get'위 코드에서 get이 사용된 부분은 client이다. 즉, client에 아무것도 담기지 않은것 같다.
때문에 기존에 User class를 상속받도록 작성한 것 대신 위에서 작성한 것 처럼 client 속성을 갖고 있는 HttpUser 클래스를 상속받게 하였다.
# locusttest.py
from locust import HttpUser, task, between
class MyUser(HttpUser):
wait_time = between(5, 15)
@task(3)
def task1(self):
pass
@task(6)
def task2(self):
pass2) 실행
첫 시도는 단순히 locustfile이 작성된 위치에서 (참고로 해당 파일도 프로젝트의 root directory에 작성하였다.) 실행하였다.
locust -f locust_test.py결과는 모두 fail이 떴다. 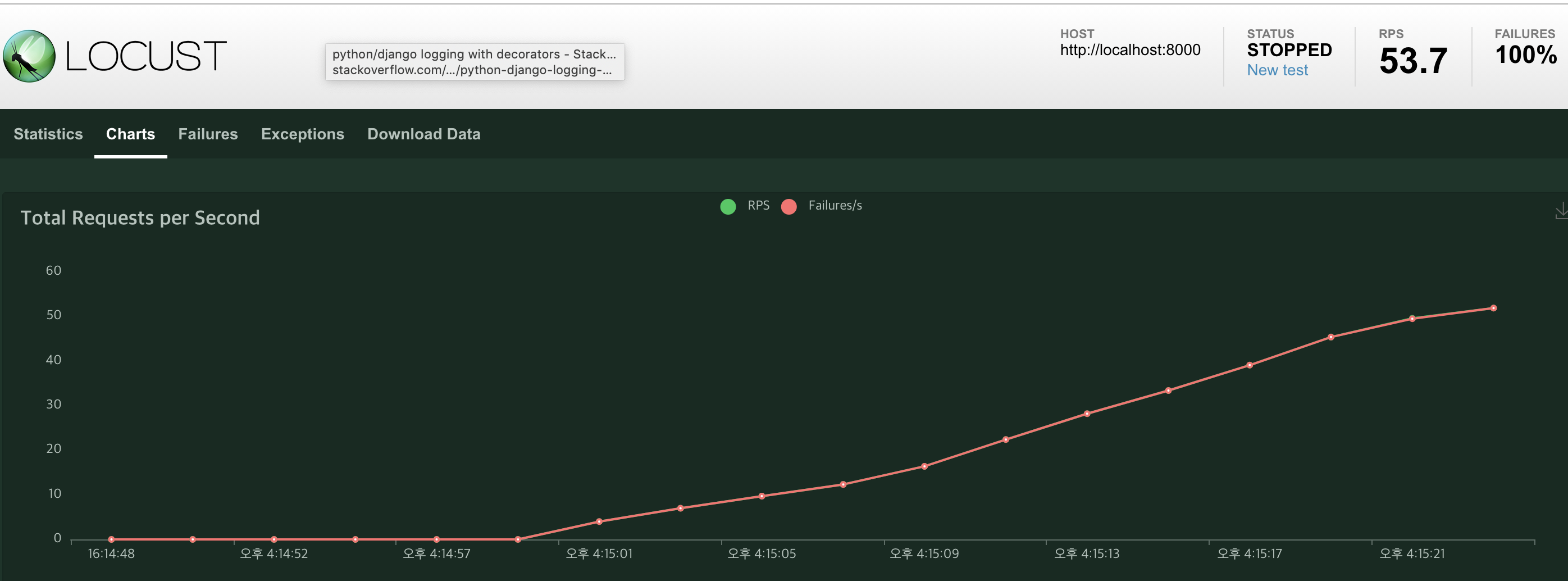
Failures 항목을 보니 어떤 유형의 에러인지 확인 할 수 있었다.

ConnectionError라고 떴다. 생각해보니 가동중인 server가 없는데 어떤 경로로 test를 할수 있을지 의문이 들었고, 테스트 하고자 하는 프로젝트의 서버를 가동하였다. runserver
이후 다시 test 하였다.
python manage.py runserver
locust -f locust_test.py#1 .all()
테스트 환경은 다음과 같다.
- 총 user : 100명
- 초당 증가하는 user : 5명
- host : http://localhost:8000
locust test 차트양상은 다음과 같다.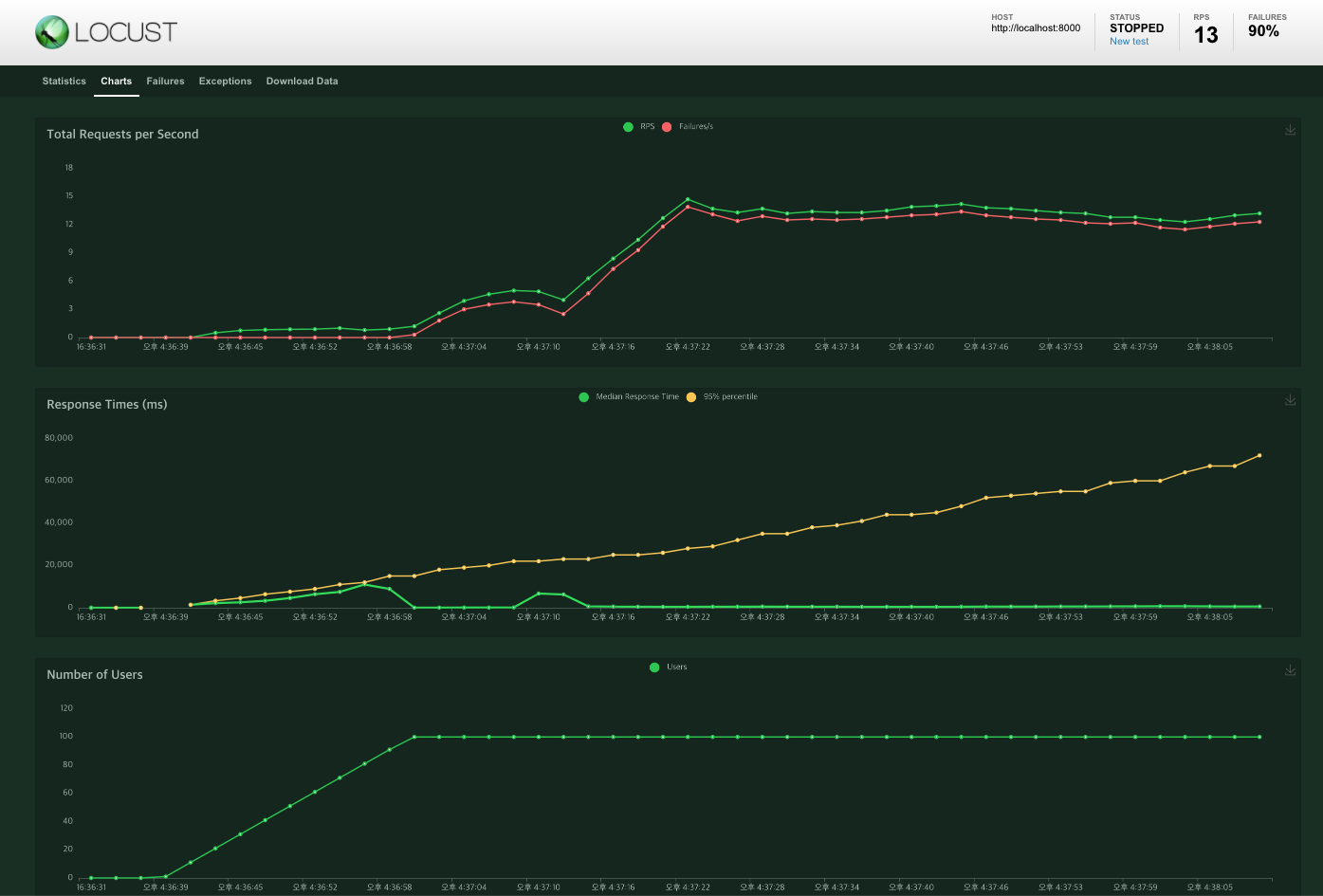
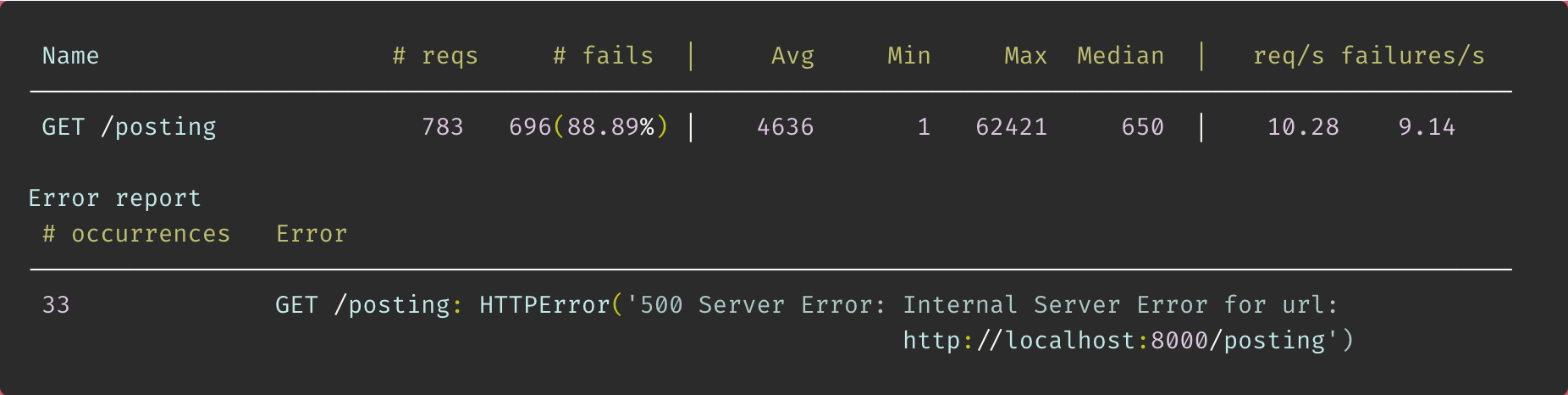
test통계와 error상황은 다음과 같다.
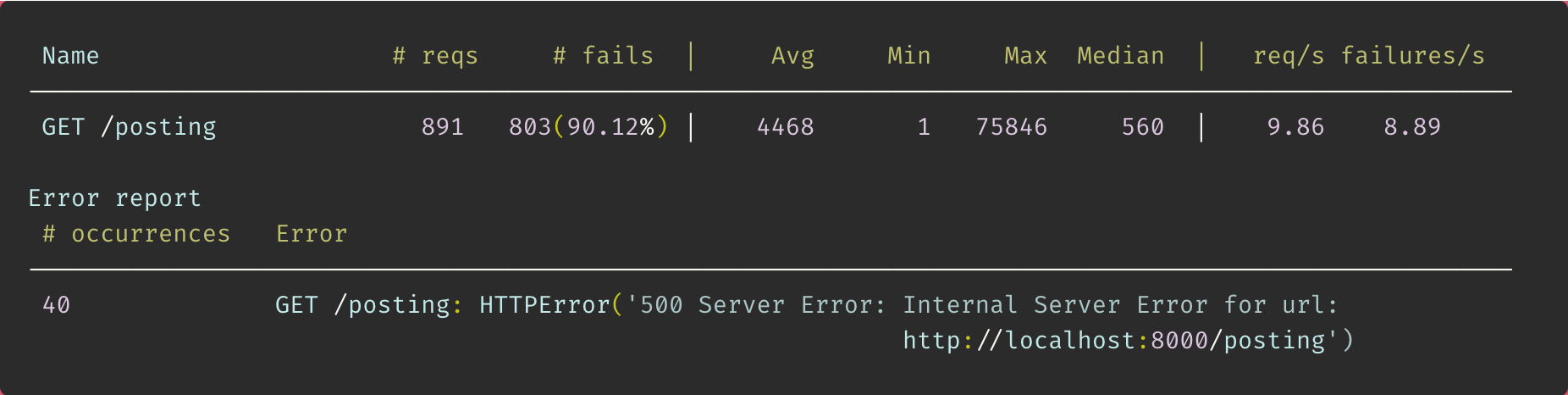
100명의 user가 호출하는 상황에서 통신 실패율이 약 90%... 엉망진창
통신 속도는 평균 4468ms를 기록하였다. 내 로직이 부하를 견디지 못한걸로 보여진다.
#2 ~~_related.all()
프로젝트 당시 DB 성능 개선을 위해 작성했던 대로 다시 test를 진행해 보았다. 당시에 초점을 둔 곳은 DB자체를 호출하는 횟수를 줄이기 위함이었다.
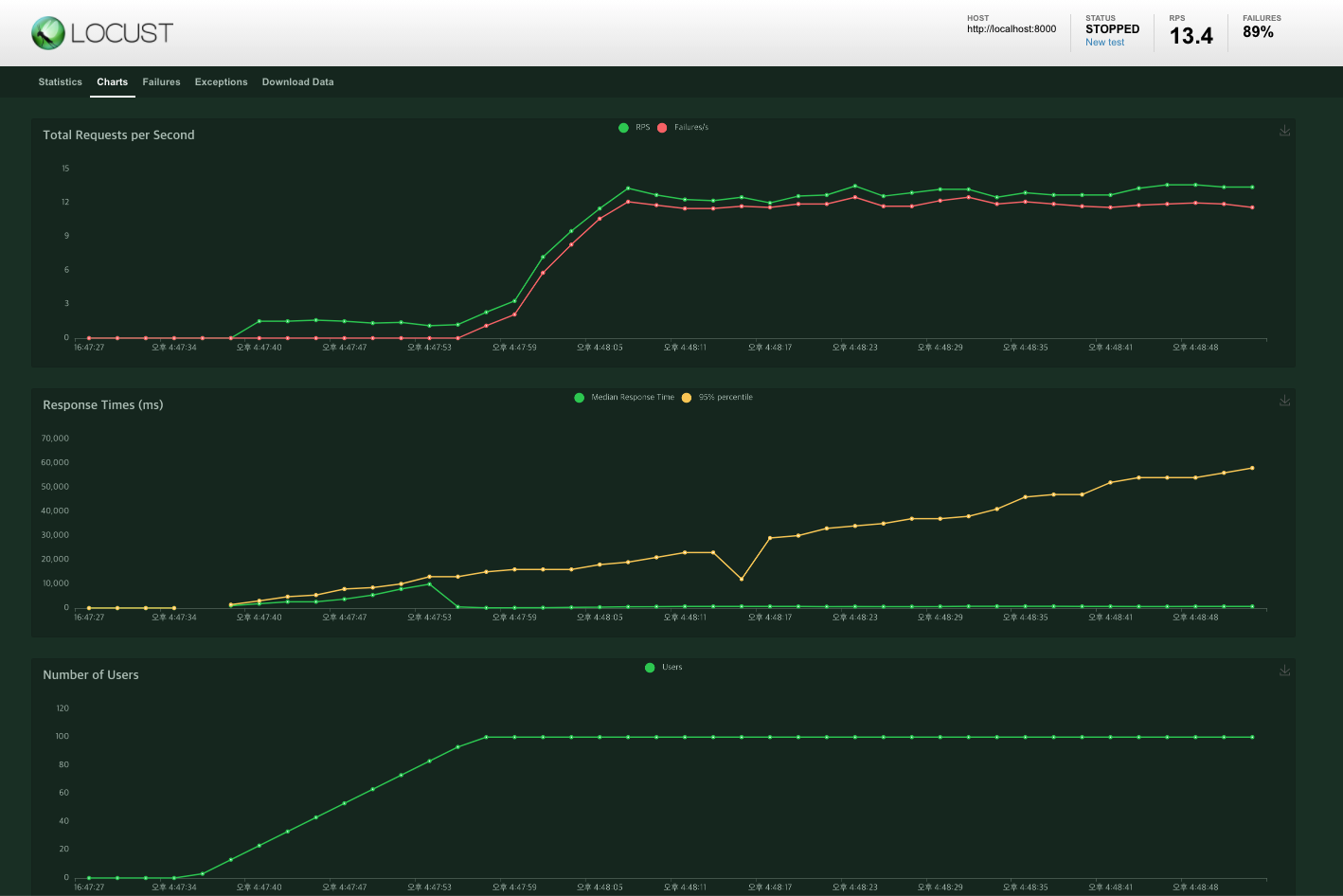
아니 대체..;;
test결과통계와 error는 다음과 같다.
#3 멀티스레드 환경에서 실행해보기 (gunicorn)
너무나도 높은 실패율로 인해 redis를 적용하기 전 좀더 개선할 수 있는 방법을 생각하다가.
python runserver로 할 시 단일 스레드 환경에서 실행하므로, gunicorn을 사용해 개발환경에 적합한 멀티스레드 환경에서 실행한다. 라는 말이 생각나 이 환경에서 다시 test해보았다.
그러기 위해선 먼저 해당 프로젝트를 gunicorn 환경에 맞게 setting 해주어야 한다.
case1 : user 100명
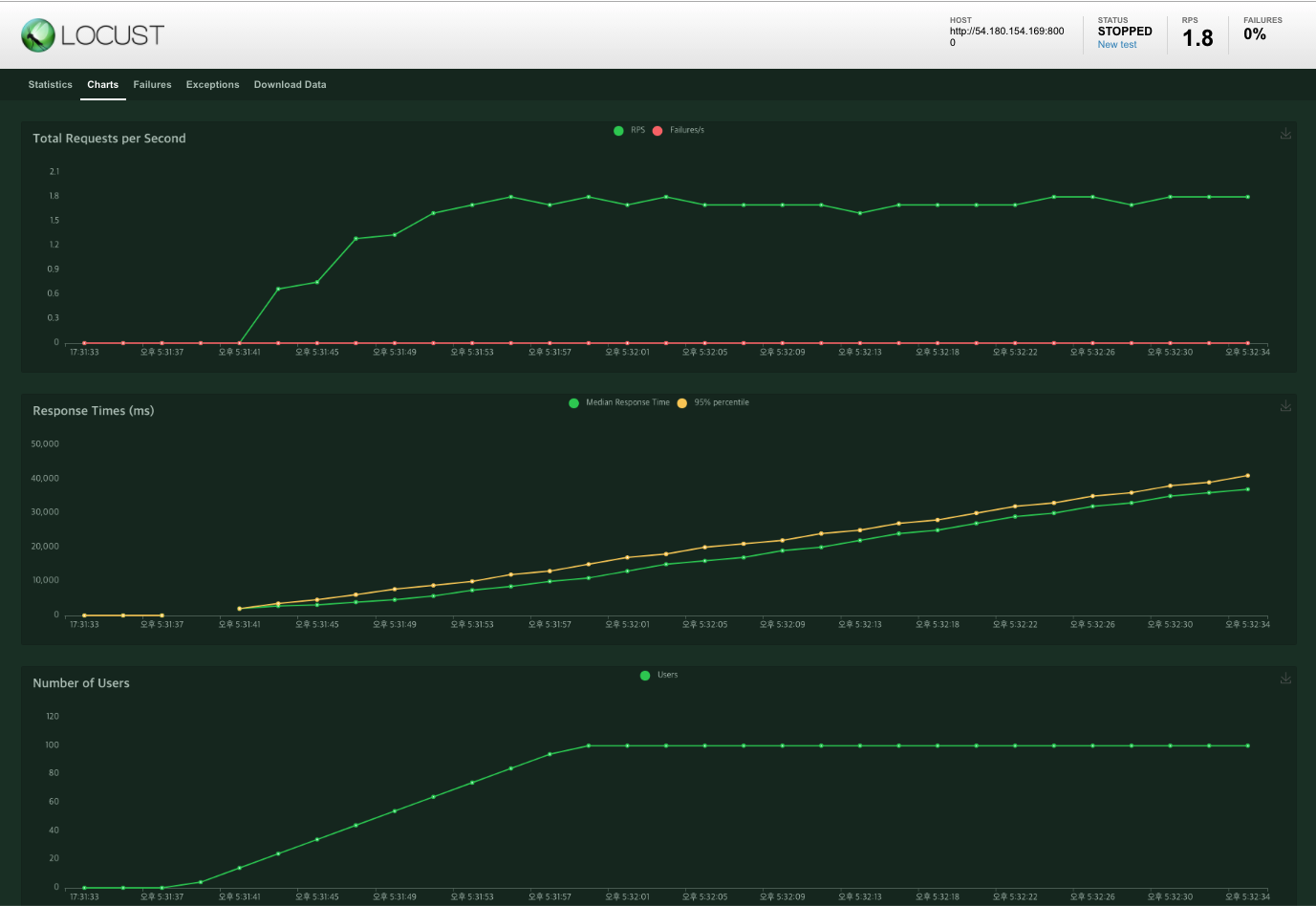

🥰 깔끔!
case2 : user 100000명
중간에 fail이 심하게 뜨고, 노트북 발열이 너무 심해서 중단! 대략 user 4000명까지 fail 없이 호출되는 것 처럼 보인다. 이후 redis를 사용해 user가 5000명인 상황에서 비교해 보도록 하자!
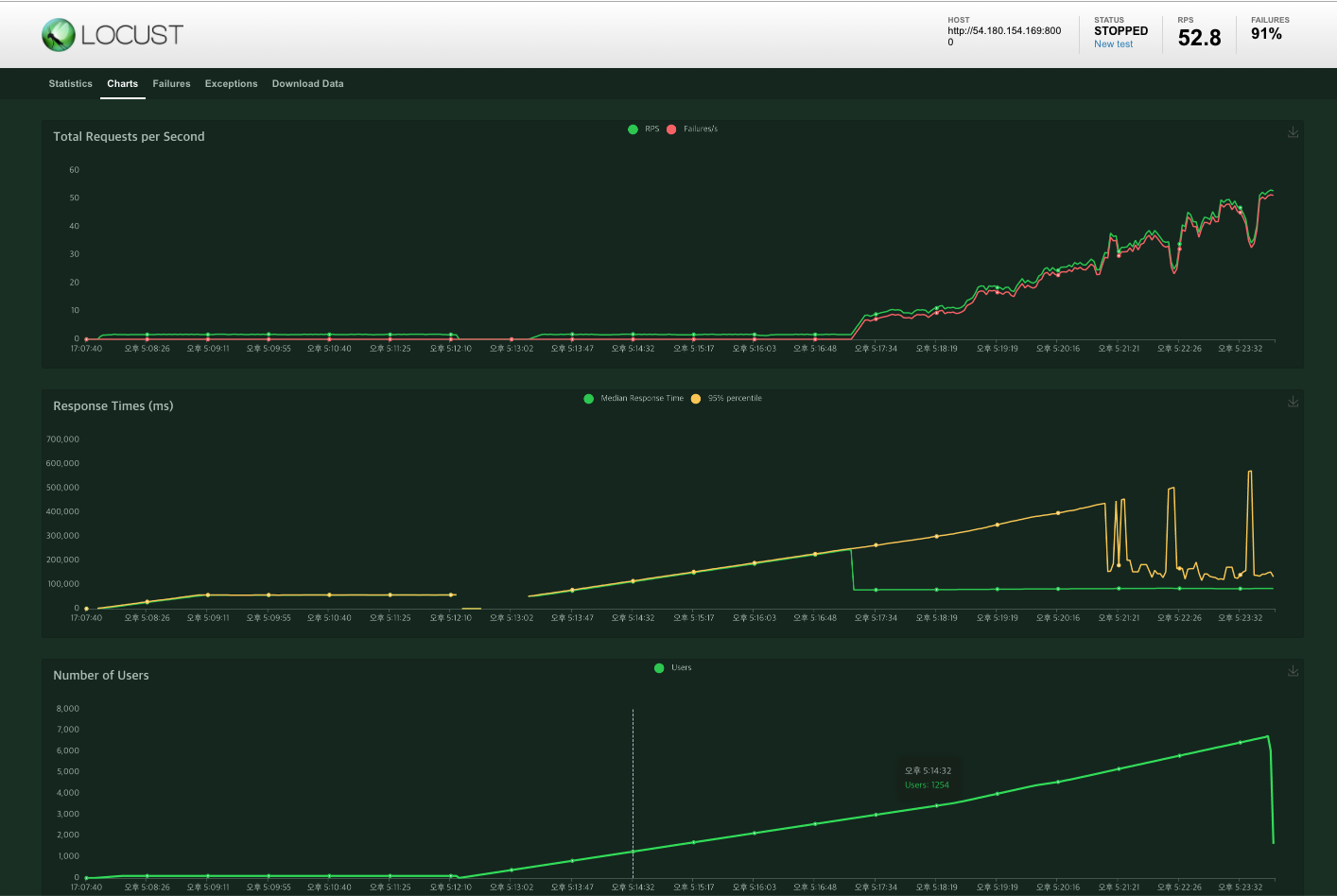


노트북 성능이라던가 여러가지 추가로 업그레이드가 필요한 부분인거 같다! 욕심이었나!
3) Error
EC2로 서버를 가동하고, DB는 내 로컬 DB로 사용하고자 했을때 다음과 같은 에러가 발생했다.
pymysql.err.OperationalError: (2003, "Can't connect to MySQL server on이말은 즉, 보안에 의해서 DB가 외부에서부터 접속이 안되기 때문이다. 따라서 VPC 보안그룹까지 모두 설정했던 RDS로 DB를 연결해 주어 테스트를 진행하였다.
4) 추가 사항
gunicorn을 사용해 locust test를 진행할때 환경은 다음과 같았다.
- EC2 로 runserver (gunicorn 사용 / Ubuntu 환경)
- 로컬환경 터미널에서 locust 실행
처음에는 locust 실행도 ubuntu 로 하려 했는데 ip주소를 제대로 변경하지 않아서인지 페이지에 접속이안되었다. 그래서 Ip 주소를 수정하려다가 혹시나 하여 로컬환경 터미널에서 locust를 실행했더니 그래도 잘 연결이 되더라!
이후 runserver 하는 프로젝트 위치와, locustfile의 위치가 달라도 제대로 실행이 될까? 하여 확인해 보았다.
예상 결과 :
어찌되었든runserver하는 프로젝트로 연결이 될 것이다.

결과 : 정답!
locustfile에 대한 것을 git으로 관리하지 않고자 할때 해당 file들만 따로 폴더에 관리하는 것도 방법일것 같다! (물론 gitignore에 올려도 되긴 하지만)
---------------------------
Redis
그렇다면 Redis는 무엇인가? 하면 다음과 같다.
- Remote dictionary server의 약자로 대용량 처리 관련 기술이다.
Redis에 대한 설명은 이곳에 정말정말 잘 나와있다.! 나도 여기서 참고했다.
https://goodgid.github.io/Redis/#redis%EB%9E%80
위의 글을 간단히 요약하자면
Redis는 NoSQL임과 동시에 In-memory솔루션으로 분리되는 Cache솔루션이며, Key-Value 방식의 구현이 가능해 빠른 속도의 데이터 처리가 가능하다. 또한 만료일을 지정하지 않은 이상 영구적인 데이터 보존이 가능하다. (디스크에 데이터를 저장하거나, 다른 서버에 복사본을 남길 수 있기 때문) 따라서 서버가 종료되고 다시 가동이 되어도 그대로 데이터를 유지할 수 있다.
MySQL과 비교하면 약 10배 빠른처리 속도를 자랑한다! 따라서 기존에 MySQL로 작성된 DB성능을 업그레이드하는데 Redis를 사용하는 것이다. (내 모든 프로젝트들은 모두 MySQL로 작성되었다.)
django에서 cache 세팅하기
내용은 RealPython 문서를 참고했다.
가상환경에서 pip install redis로 설치해준뒤 Django에서도 redis를 사용할 수 있도록 pip install django-redis도 설치해 준다.
그리고 나서 my_settings.py에 기존에 DB에 대한 정보만 있던것에 Cach에 대한 정보도 기입해준다.
#my_settings.py
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379/1",
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient"
}
}
}loadtest로 호출 속도 확인하기
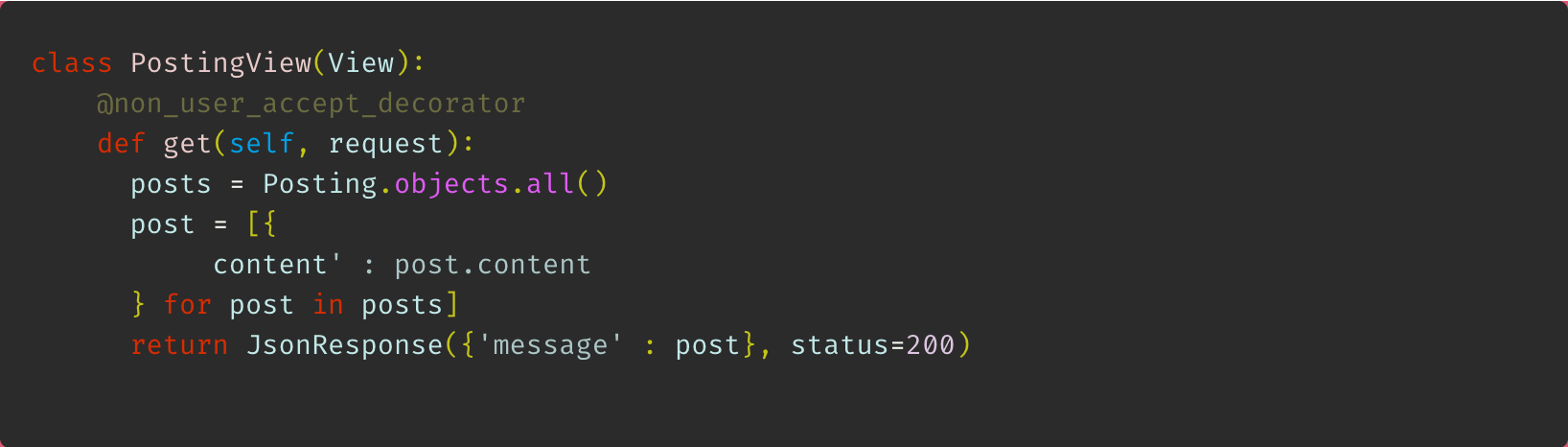
🔥 기존의 로직은 불러오는 데이터가 너무 많아 빠르게 테스트 결과를 확인하기에 적합하지 않다고 판단하여 로직을 간단하게 수정하였다.
수정한 로직은 다음과 같다.
db에 저장된 posting들 중 게시글의 'content'만 가져오도록 한다. 기억으론 한 40여개 정도의 데이터가 있던걸로 기억한다.
이 상태에서 Loadtest를 통해 100명의 user가 있다는 전제 하에 호출 속도를 확인해 보았다.
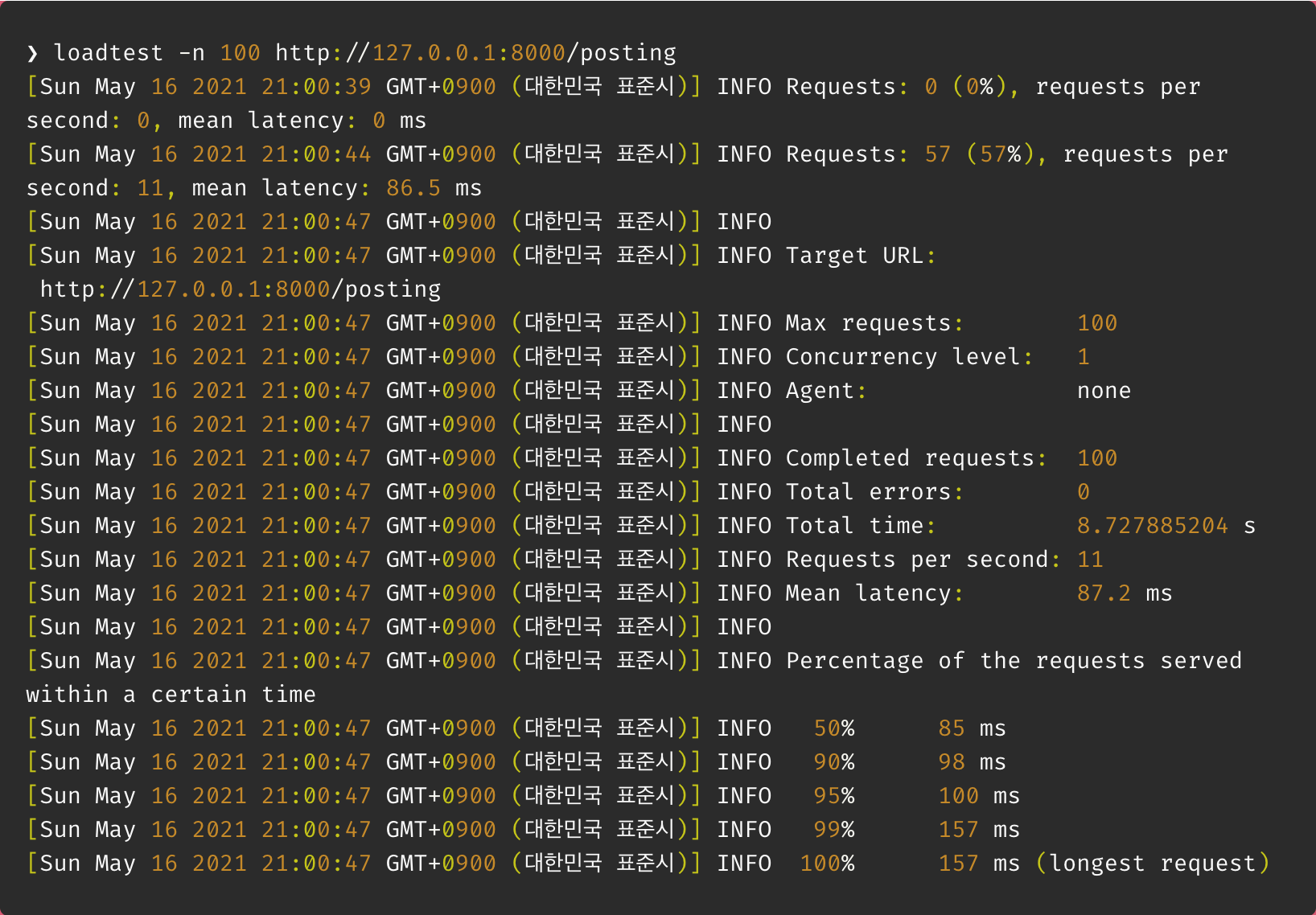
결과 : 약 8.7초
이후 cache를 적용해 수정한 뒤 loadtest로 호출 속도를 확인하였다. 이때 django에서 제공해주는 cache를 import 하면 된다.
똑같이 100명의 user가 있다는 조건에서 test해보았다.
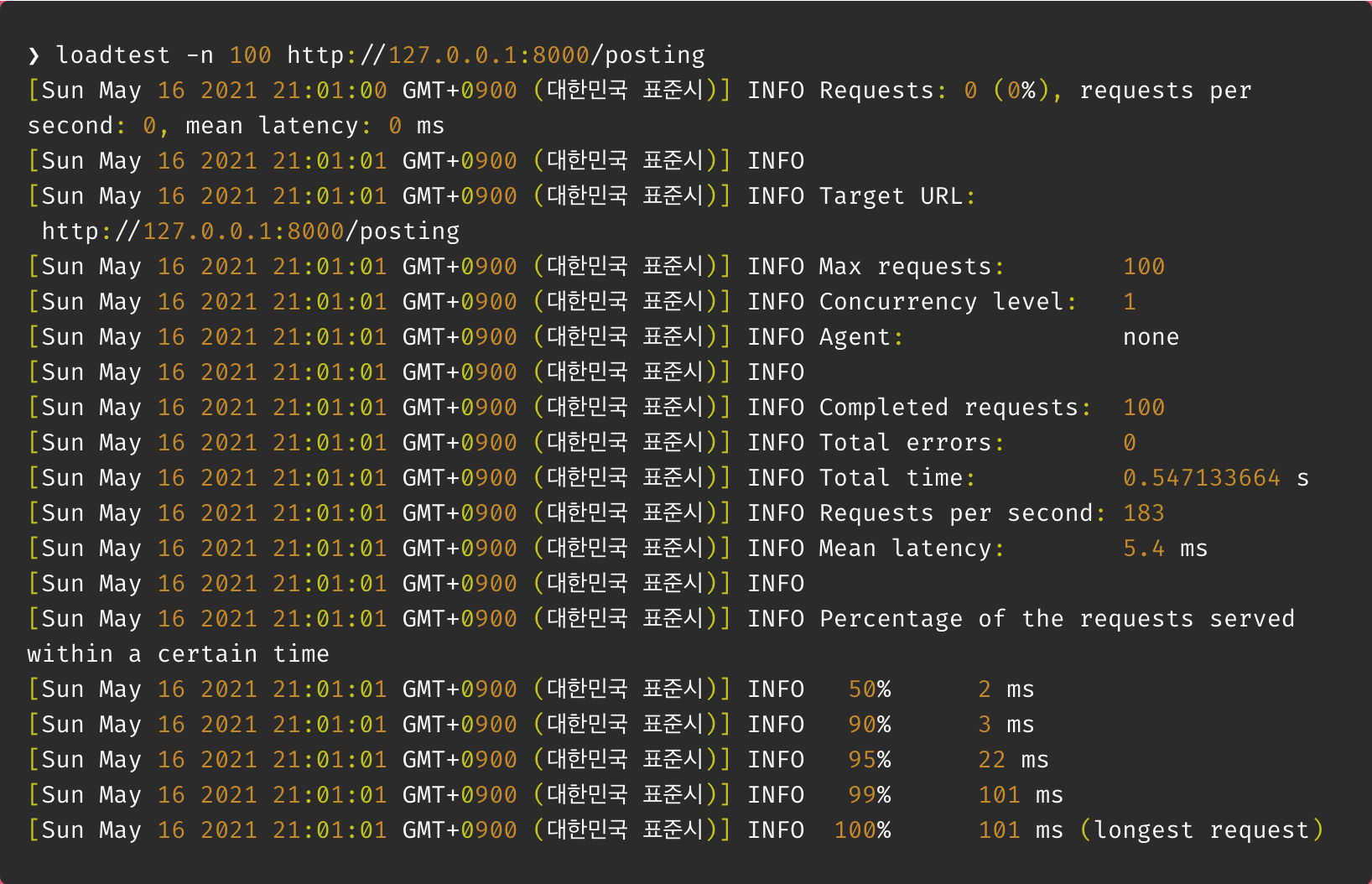
결과 : 약 0.5초
1) loadtest 결과
django-redis를 통해 caching을 적용한 결과 호출 속도가 10배 이상 빨라진걸 확인할 수 있었다.!
2) locust 결과
locust를 이용해서도 결과를 확인해보고자 하였고 이때는 원래의 로직 그대 (두개의 외부 class를 각각 inner join과 outer join하는 값 있음)로 하려고 했다. 하지만 제대로 된 test인지도 파악이 안되는 상태에서 다음과 같은 에러가 자꾸 발생하면서 실패율이 90프로가 나왔다... cache를 사용해도ㅠㅠ
django.db.utils.OperationalError: (1040, 'Too many connections')이는 MySQL 자체에서 처리 가능한 connection의 수를 넘겼다는 말 이라던데 일단 그래서 User가 100명이 아닌 50명인 경우로두고 test 하였을땐 cache를 사용하지 않아도 모두 성공적인 호출을 불러왔고 rmp차이도 cache를 사용했을때와 사용하지 않았을때 변화가 없었다.
그래서 test용으로 작성한 간단한 로직으로 다시 test해 보았다.
100명일 경우 cache를 사용하지 않아도 fail이 뜨지 않았기에 user를 200명으로 가정하고 test를 진행하였다.
redis 사용 전
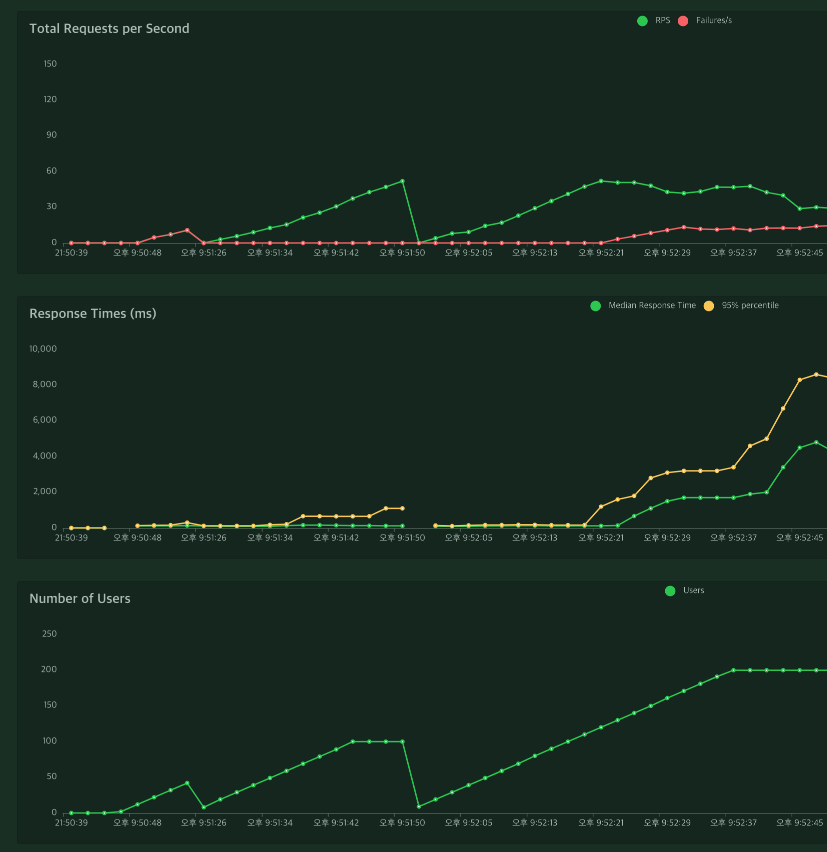

호출 속도 : 1693ms
redis 사용 후
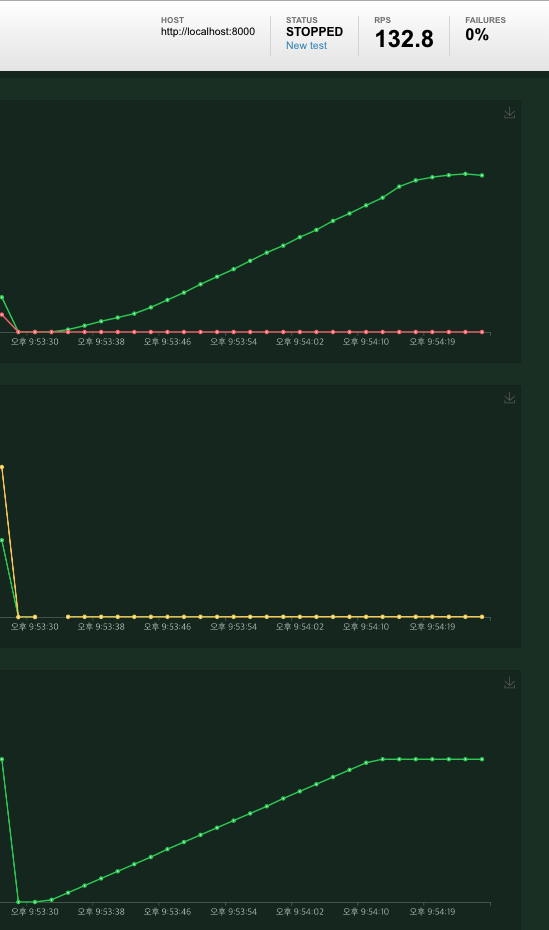

호출 속도 : 5ms
결과적으로 호출 실패도 없어졌고, 호출 속도도 향상했을음 확인할 수 있었다!!!
---------------------------
끝 🔥
django에서 redis를 사용하기 위해선 django의 cache를 꼭 import 해준다는 개념이 아직은 이해가 잘 안된다. 또한 cache로 메모리에 저장된 데이터를 확인하는 방법을 알고자 하였는데 redis-cli에 접속이 잘 안되서 확인하지 못했다! 데이터는 만료기한이 있거나 임의로 삭제해 주지 않는 한 계속 저장된다고 해서 cache.delete('posts') 로직이 실행되도록 해주었는데 제대로 삭제가 되었는지는 모르겠다.
좀더 공부해서 저장된 cache를 확인해 보도록 하자!
