🐶 Web crawling ?
- web crawling : 자동적으로 화면에 있는 data를 가져오는 것 (실시간 연동, 자동으로 업데이트 됨)
- web scrapping : 자동화 X / scrapping 하는 시점에서의 데이터만 갖고오기!
=> 두 가지 모두웹 사이트를 분석해 원하는 데이터를 추출하는 과정이다.
Tools
web crawling에 사용되는 tool은 두가지 이다.
- BeautifulSoup
- Selenium
BeautifulSoup
Selenium
동적인 입력이 필요할 때 (가상의 브라우저를 띄워 사람 대신 이것저것 클릭 or 검색 해준다.)
Selenium + BeautifulSoup flow
Selenium을 통해 동적인 입력이 들어간 뒤 모은 정보를BeautifulSoup에 전달BeautifulSoup에서는 전달받은 정보를 데이터에 저장
I. BeautifulSoup 예시
- 가상환경 : web-crawling (python=3.9)
- dir 위치 : MyProjects > c_pc
대상 웹페이지 = https://books.toscrape.com/
- 설치 pip :
pip install beautifulsoup4/
1️⃣ python 파일 생성
- requests 모듈 불러오기
- 대상 웹페이지로부터 html 코드 담아오기 (just text로 인식된다.)
- BeautifulSoup을 통해 css 코드 인식하게 하기 ('html로 파싱하기')
//pr1.py 생성
import requests
from bs4 import BeautifulSoup
response = requests.get("https://books.toscrape.com/")
bs = BeautifulSoup(response.text, 'html.parser')2️⃣ 개발자 도구를 통해 scrapping 하고자 하는 대상 선택
.png)
3️⃣ copy selector : 1개 요소
#default > div > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.image_container > a > img위 코드를 보면 내가 선택한 영역의 tag들을 가져왔다!!
+) 여기서 살펴보면
<img src="media/cache/2c/da/2cdad67c44b002e7ead0cc35693c0e8b.jpg" alt="A Light in the Attic" class="thumbnail">이 코드가 실제 해당 영역을 가리키는 코드이다.
img 태그에 src와 alt속성이 들어있다.
가져온 selector 값 출력해보기
위에 가져온 태그들 중, img 태그 안의 alt 속성에 대한 값을 출력시켜 보자!!
title_one = bs.selec_one("#default > div > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.image_container > a > img")
print(title_one['alt'])
-> A Light in the Attic4️⃣ copy selector : 동급의 selector 전부
코드를 살펴보면 같은 형식으로 표현되어 있는 책들의 경우 코드의 구성이 똑같다. (간혹 아닌것도 있으니 코드를 잘 구분할 줄 알아야 한다...)
각각의 책들은코드 구성이 같다가 li:nth-child에서 숫자에 변화가 있다. 따라서 이 부분을 공통적인 부분으로 잡아준다면 이러한 구성의 태그에 해당하는 모든 요소가 title에 담길 것이다.
.png)
위 화면에서 개발자 도구 화면을 보면 모두 li태그로 구분되고 있음을 알 수 있다!
title = bs.select("#default > div > div > div > div > section > div:nth-child(2) > ol > li > article > div.image_container > a > img")
for i in title:
print(i['alt'])여기서 값들은 list형태로 저장된다. 만약 print(i) 만을 한다면 <img alt="Set Me Free" class="thumbnail" src="media/cache/5b/88/5b88c52633f53cacf162c15f4f823153.jpg"/> 이련 형태로 출력된다. 내가 원하는 것은 그 속의 alt에 담긴 책의 제목이기 때문에 print(i['alt'])로 입력한다.
A Light in the Attic
Tipping the Velvet
Soumission
Sharp Objects
Sapiens: A Brief History of Humankind
The Requiem Red
The Dirty Little Secrets of Getting Your Dream Job
The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhull
The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics
The Black Maria
Starving Hearts (Triangular Trade Trilogy, #1)
Shakespeare's Sonnets
Set Me Free
Scott Pilgrim's Precious Little Life (Scott Pilgrim #1)
Rip it Up and Start Again
Our Band Could Be Your Life: Scenes from the American Indie Underground, 1981-1991
Olio
Mesaerion: The Best Science Fiction Stories 1800-1849
Libertarianism for Beginners
It's Only the Himalayas✴️ 하나의 selector 경로에서 두가지 속성 값 출력하기
css tag들을 보면 img 태그에 src alt 속성이 담겨 각각 이미지 주소와 이미지에 부합하는 책의 제목이 적혀있다. 이것을 이용해 하나의 경로로부터 두가지 속성을 각각 출력시켜 보자!
import requests
from bs4 import BeautifulSoup
a = "https://books.toscrape.com"
response = requests.get(a)
bs = BeautifulSoup(response.text, 'html.parser')
book_1 = bs.select_one("#default > div > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.image_container > a > img")
book_1_title = book_1['alt']
book_1_url = book_1['src']
print("book_1의 이미지 주소는 :", a+"/"+book_1_url)
print("book_1의 제목은 :", book_1_title)
일부러 이미지 주소 앞에 홈페이지 주소도 같이 출력되게 했다! 저 터미널상에서 command를 누르고 클릭하면 이미지 화면으로 이동한다 ^0^.png)
II. CSV 파일과 함께 돌리기
1️⃣ csv 관련 코드 세팅
bs 를 통해 얻어진 데이터를 csv 파일에 저장시킬 수 있다!! 먼저 설정해 줘야 할것이 있다.
import re
import csv
// csv 파일 열어두기
csv_name = "books.csv" //데이터들이 저장되면서 새로 생길 csv 파일의 이름
csv_open = open(csv_name, "w+", encoding = "utf-8")
csv_writer = csv.writer(csv_open)
csv_writer.writerow(('title','image_url'))
// bs 관련 코드 생략
// 각 타이틀 이름과 이미지 url을 모두 csv 파일에 저장
with open(csv_name, "w+", encoding = "utf-8") as file:
for i in range(len(titels)):
title = titles[i]['title']
img_url = a+'/'+image_urls['src']
writer = csv.writer(file)
writer.writerow([title, img_url])여기서 변수 title과 image_url은 아래에서 선언할 것이다. 미리 쓴 것 뿐!
2️⃣ beautifulsoup으로 데이터 모으고, csv에 저장시키기
import re
import csv
import requests
from bs4 import BeautifulSoup
csv_name = "books.csv"
csv_open = open(csv_name, "w+", encoding = "utf-8")
csv_writer = csv.writer(csv_open)
csv_writer.writerow(('title','image_url'))
a = "https://books.toscrape.com"
response = requests.get(a)
bs = BeautifulSoup(response.text, 'html.parser')
same = bs.select("#default > div > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.image_container > a > img")
with open(csv_name, "w+", encoding = "utf-8") as file:
for i in range(len(same)):
title = same[i]['title']
img_url = a+'/'+same[i]['src']
writer = csv.writer(file)
writer.writerow([title, img_url]) 제일 위에 import re가 뭔지 몰라서 지우고도 실행했는데 같은 결과(csv에 정보 저장)가 나왔다!! 없애도될꺼같은데....? 뭔지 알아보기!!!!
3️⃣ csv 파일 확인
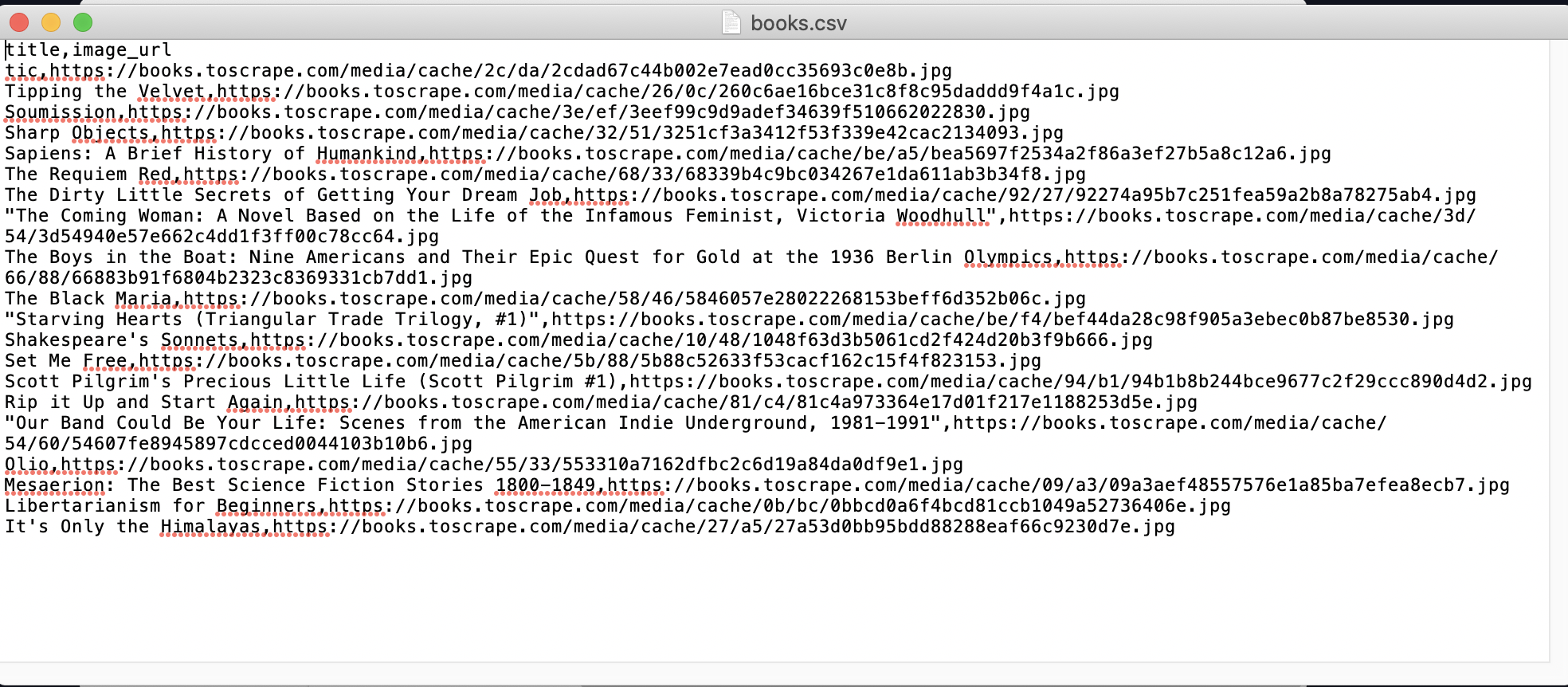 근데 왜 첫번째 책 제목이 잘려서 입력되는지 모르겠다... 왜....?
근데 왜 첫번째 책 제목이 잘려서 입력되는지 모르겠다... 왜....?
csv ?
comma-separated values : 몇 가지 필드를 쉼표(,)로 구분한 텍스트 데이터 및 텍스트 파일
II. Selenium 예시
selenium을 사용하기 위해선 다음의 모듈을 설치해야 한다.
- pip install slenium
- pip install webdriver-manager
1️⃣ selenium 관련 코드 세팅
import csv
import time //selenium에 직접적인 것은 아님!
from bs4 import BeautifulSoup
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
csv_filename = "pr2.csv"
csv_open = open(csv_filename, "w+", encoding='utf-8')
csv_writer = csv.writer(csv_open)
//selenium을 통해 각 카테고리를 클릭할 수 있으므로 이 또한 정보이다. 카테고리도 함께 저장하기 위해 코드를 추가한다.
csv_sriter.sriterow(('category', 'title', 'image_url'))
driver = webdriver.Chrome(ChromeDriverManager().install())
a = "https://books.toscrape.com/"
driver.get(a)
full_html = driver.page_source
soup = BeautifulSoup(full_html, 'html.parser')
time.slepp(3) // selenium으로 새롭게 로딩되는 페이지 기다려 주는 시간
categories = soup.select('#default > div > div > div > aside > div.side_categories > ul > li > ul > li > a')
for i in range(1, len(categories)+1):
element = driver.find_element_by_css_selector(f'#default > div > div > div > aside > div.side_categories > ul > li > ul > li:nth-child({i}) > a')
category_name = element.text
time.sleep(2)
element.click() //selenium이 클릭!
full_html = driver.page_source
soup = BeautifulSoup(full_html, 'html.parser')
same = driver.find_elements_by_css_selector("#default > div > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.image_container > a > img")
//각 타이틀 이름, 이미지 url 프린트 하기
for i, title in enumerate(same):
print('title: ', title['alt'])
print('original src: ', title['src'])
print('image_url: ', title['src'].split('/')[4:])
url = a + '/'+'/'.join(title['src'].split('/')[4:])
if i == 0:
csv_writer.writerrow((category_name,title['alt'], url))
else:
csv_writer.writerow(('',title['alt'], url))