
Java Collections Framework를 알기 위해서는 자료구조가 무엇인지 어떠한 종류가 있는지 간단하게라도 알고 가면 좋을 듯 해 짧게 적어보았다.
자료구조란
프로그램에서 사용하기 위한 자료를 기억장치의 공간 내에 저장하는 방법과 저장된 그룹 내에 존재하는 자료 간의 관계, 처리 방법 등을 연구 분석한 것.
풀어서 얘기하자면 컴퓨터가 데이터를 효율적으로 관리해야 하고 관리 방법이 있을테니 데이터의 특성과 사용하는 목적에 맞게 효율적으로 다룰 수 있도록 구조화 한 것이라고 볼 수 있다.
자료구조의 분류
대표적인 자료구조의 분류는 선형 자료구조(Linear Data Structure)과 비선형 자료구조(Non-linear Data Structure)가 존재한다.
선형 자료구조(Linear Data Structure)
선형 자료구조는 우리가 물건을 사기 위해 일렬로 줄을 선 것 처럼 데이터 뒤에 데이터가 따라오는 일렬롱 연결된 구조를 가지고 있다.
선형 구조의 대표적인 예는 List, Stack, Queue, Deque 등이 있다.
비선형 자료구조(Non-Linear Data Structure)
비선형 자료구조는 선형 자료구조와 다르게 일렬로 연결된 구조가 아닌, 각 요소가 여러 개의 요소와 연결된 구조를 가지고 있다.
이 때문에 1:N 또는 N:N의 관계를 가지게 된다.
비선형 구조의 대표적인 예는 Graph, Tree가 있다.
Java Collections Framework란
Java는 개발 언어의 한 종류이니 Collections Framework가 무엇인지 의미를 풀어본다면
Collections는 무언가를 한 곳에 모아놓은 것을 뜻하고, Framework의 frame은 "틀"이란 뜻이다. work은 "일하다"라는 뜻으로 이것을 합쳐보면 "틀을 가지고 일하다"가 된다. 즉 프레임워크는 일정한 틀과 뼈대를 가지고 일하다라는 뜻으로 제공받은 일정한 요소와 틀, 규약을 가지고 무언가를 만드는 일이다.
개발에서 데이터를 다루는 직업인만큼 한 곳에 모아놓을 것 또한 데이터 이므로 위의 단어들을 합쳐 말한다면 Java Collectinos Framework란, Java에서 사용되는 데이터들이 모여 쉽게 가공 할 수 있도록 지원하는 규약, 기본 구조 라는 의미이다.
Java Collections framework의 구조는 아래와 같다
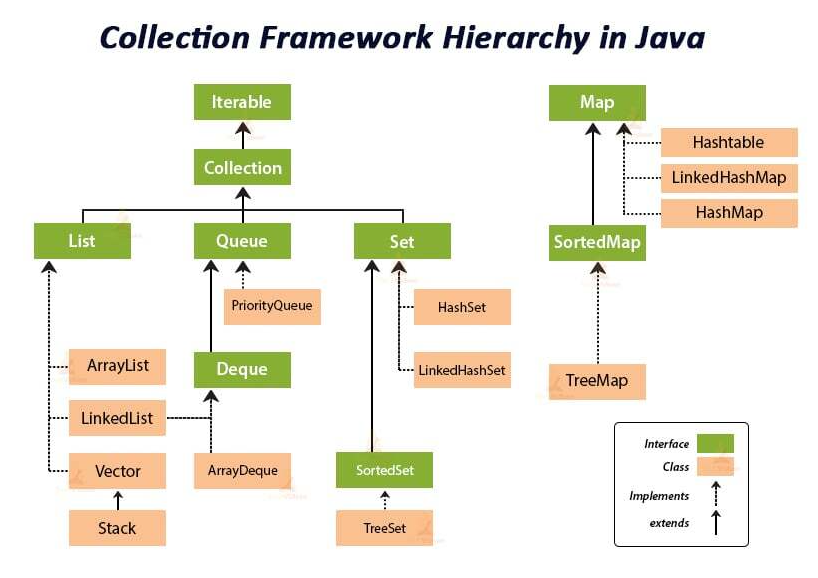
점선은 구현(Implements)을 나타냈고 실선은 확장(extends)를 의미한다.
이미지에 있는 모든 자료구조에 대해 조사하고 공유하고 싶지만 지금은 가장 기본적인 내용에 대해서 다뤄보고자 한다.
List
List Interface는 대표적인 선형 자료구조이고, 우리가 배열에서 int[] array = new int[100];와같이 선언한 경우 우리는 100개의 공간까지 사용가능 하고 더 이상 사용을 할 수 없다. 하지만 List Interface에서는 배열의 기능을 포함해 가변적인 크기를 갖고 있는 것이 특징이다.
List Interface를 구현한 클래스는 ArrayList, LinkedList, Vector 등이 있다.
ArrayList
Java를 공부하면서 가장 많이 사용한 List Interface는 ArrayList가 아닐까 싶다.
ArrayList의 특징은 다음과 같다.
- Object[]배열을 사용하면서 내부 구현을 통해 동적으로 관리한다.
- 최상위 타입인 Object타입으로 배열을 생성해 사용하기때문에 요소 접근이 원활하다.
- 단방향 구조로 인덱스만 안다면 빠르게 원하는 데이터를 얻을 수 있다.
- 삽입 또는 삭제가 일어나는 경우 데이터들을 뒤로 밀거나 앞으로 당겨야 하므로 이때에는 처리 속도가 느리다는 단점이 있다.
LinkedList
LinkedList는 노드와 포인터를 이용해 만들어진 리스트이며, 장점으로는 메모리에 따로 저장되어도 각 노드의 이전 노드 와 다음 노드를 안다면 순회를 통해 찾을 수 있다는 것과 삽입/삭제 시에 포인터를 끊고 새로운 노드에 연결만 하면 되므로 효율이 좋다. 단점으로는 중간의 포인터가 끊어진다면 이전 노드 또는 다음 노드를 알 수 없다는 점이 있다.
연결 리스트(Linked List)와 이중 연결 리스트(Double Linked List)로 나뉘어진다.
연결 리스트(Linked List)는 노드에 값과 다음 포인터를 담고, 특정 원소를 조회하는 경우 첫 노드부터 순회해야하기 때문에 ArrayList에 비해 느리다. 하지만 위에서 언급했듯이, 삽입 또는 삭제에 있어서는 ArrayList보다 좋은 효율을 가지고 있다.
이중 연결 리스트(Double Linked List)는 연결 리스트의 단점을 보완한 리스트이며, 연결 리스트는 다음 노드밖에 가지고 있지 않아 이전 노드를 조회할 수 없지만, 이중 연결 리스트는 노드 내에 값과 이전 포인터, 다음 포인터를 저장하고 있어 이전 노드를 조회할 수 있다.
또한 중간에 위치한 데이터를 조회할 때 이전/다음 포인터를 가지고 있기에 조회하려는 데이터가 리스트의 끝위치에 가깝다면 끝위치에서 이전 포인터를 이용해 순회하여 찾을 수 있어서 연결 리스트에 비해 비교적 처리 속도가 빠르다고 할 수 있다.
Stack
Stack은 데이터를 쌓아 올려 차례대로 수행하게 지원한다. 가장 큰 특징으로는 LIFO(Last in First out)이라고 후입선출 이라는 것인데, 가끔가다 이러한 게임광고를 본 적 있을것이다.

이 게임은 맨위에서부터 모래를 꺼내 각 병에 같은 색의 모래끼리 담기게 만들면 되는데 Stack도 똑같다. 마지막에 담긴 데이터(Last in)가 가장 처음 나가게 된다(First out).
Queue
Queue는 선형 자료구조로 Stack과 반대로 FIFO(First in First out) 선입선출의 특성을 지니고 있다. 현실 세계에서 우리가 맛집에 손님이 많아 웨이팅을 한다고 생각해보자.
이때 자연스럽게 기다리는 모든 손님들이 한줄로 서서 기다리고 있을 것이고, 자리가 생길때마다 가장 앞에서부터 한 팀씩 차례대로 들어간다. 또한 새로운 사람들이 온다면 줄의 끝에 서게 되는데,
Queue또한 가장 먼저 들어간 데이터가 가장 먼저 나오게되는 구조이다.
Set
Set의 가장 큰 특징은 데이터를 중복해서 저장할 수 없고 순서를 보장하지 않는다 라는 점이다.
데이터 중복이 안된다는건 이해되나 순서를 보장하지 않는다라는 것은 무슨 뜻인지 이해하기 어려울테니 풀어보자면 List의 경우 1, 2, 3 의 순서로 추가 한다면 출력 또한 1, 2, 3이 된다.
하지만 Set의경우 똑같이 1, 2, 3 의 순서대로 추가를 했어도 출력이 2, 3, 1이 된다던지 1, 3, 2가 될 수 도 있다. 무조건 1, 2, 3 의 순서대로 출력이 된다는 보장을 할 수 없다는 뜻이다.
Set의 구현 클래스에는 HashSet, TreeSet, LinkedHashSet이 존재한다.
기본적인 구조는 동일하니 특성만 간단하게 설명을 하자면
HashSet의 경우, Set의 대표적인 클래스이며, 데이터를 중복 저장 하지 않고, 순서를 보장하지 않는다.
TreeSet은, HashSet의 특성과 동일하지만 이진 탐색 트리(Binary Search Tree)구조로 이루어져 있다. 따라서 데이터의 추가와 삭제는 HashSet보다 느리지만 검색과 정렬에 있어서는 우위에 있다.
LinkedHashSet은 중복을 허용하지 않지만 순서를 보장한다.
