
- 본 시리즈에서는 How to GraphQL의 Tutorial 문서들을 차례대로 번역합니다.
- 이 글은 GraphQL Fundamentals - GraphQL is the better REST을 번역한 글입니다.
- 오역 또는 의역이 있을 수 있습니다. 양해 부탁드리며, 수정이 필요한 부분은 댓글로 요청해주세요.
GraphQL은 더 좋아진 REST
지난 수십 년간, REST는 웹 API를 설계하는 표준으로 거듭났습니다. 물론, 표준이라고 하기에는 애매한 부분이 조금 있지만 말이죠. REST는 무상태 서버, 자원에 대한 구조화된 접근과 같은 훌륭한 발상을 제공합니다. 하지만 REST API는 오늘날 클라이언트의 급변하는 요구 사항들을 만족시키기에는 유연성이 부족합니다.
GraphQL은 이러한 유연성과 효율성을 향상시키고자 하는 요구에 부합하고자 개발되었습니다! GraphQL을 사용하면 개발자들이 REST API와 상호작용할 때 경험했던 단점과 비효율을 해결할 수 있습니다.
API로부터 데이터를 불러오는 상황을 가지고 REST와 GraphQL의 주요 차이점을 설명해보도록 할게요. 다음과 같은 상황을 가정해보겠습니다. 블로그 어플리케이션에서는 특정 사용자가 작성한 게시글의 제목들을 표시해야 합니다. 또한 동일한 화면 상에 해당 사용자를 가장 최근에 팔로잉한 사용자 3명의 이름을 표시해야 합니다. REST와 GraphQL은 이 상황을 각각 어떻게 다루게 될까요?
왜 개발자들이 GraphQL에 열광하는지 이 글에서 더 자세히 확인할 수 있습니다.
REST와 GraphQL의 데이터 불러오기
REST API를 사용하면 여러 개의 엔드포인트로부터 데이터를 모으는 것이 일반적입니다. 위의 예시에서는 우선 해당 사용자의 데이터를 /users/<id> 엔드포인트를 통하여 불러올 수 있습니다. 다음으로, 해당 사용자의 모든 게시글을 불러오는 데에 /users/<id>/posts 엔드포인트를 사용할 수 있습니다. 그렇다면 세번째 엔드포인트로는 /users/<id>/followers를 사용하여 해당 사용자의 팔로워 명단을 불러올 수 있습니다.
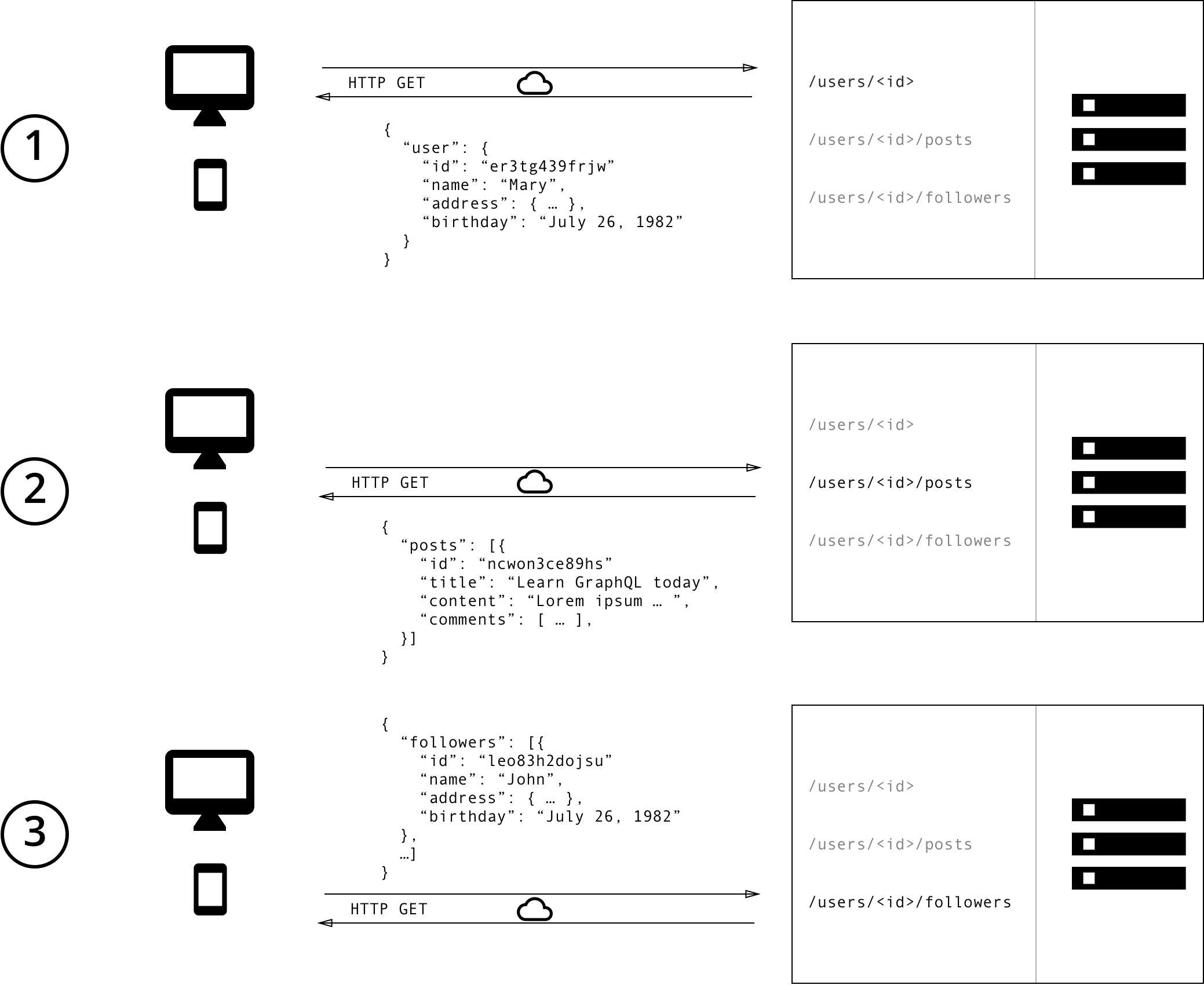 [REST를 사용하면 데이터를 불러오기 위하여 각각의 엔드포인트들에 3번의 요청을 보내야 합니다. 게다가 필요없는 정보까지 가져오게 됨으로써 데이터를 과하게 불러오게(Overfetch) 됩니다.]
[REST를 사용하면 데이터를 불러오기 위하여 각각의 엔드포인트들에 3번의 요청을 보내야 합니다. 게다가 필요없는 정보까지 가져오게 됨으로써 데이터를 과하게 불러오게(Overfetch) 됩니다.]
반대로 GraphQL에서는, 구체적인 데이터 요구 사항을 포함한 딱 하나의 쿼리를 GraphQL 서버에 보내게 됩니다. 그러면 서버는 요구 사항에 일치하는 JSON 객체를 반환해줍니다.
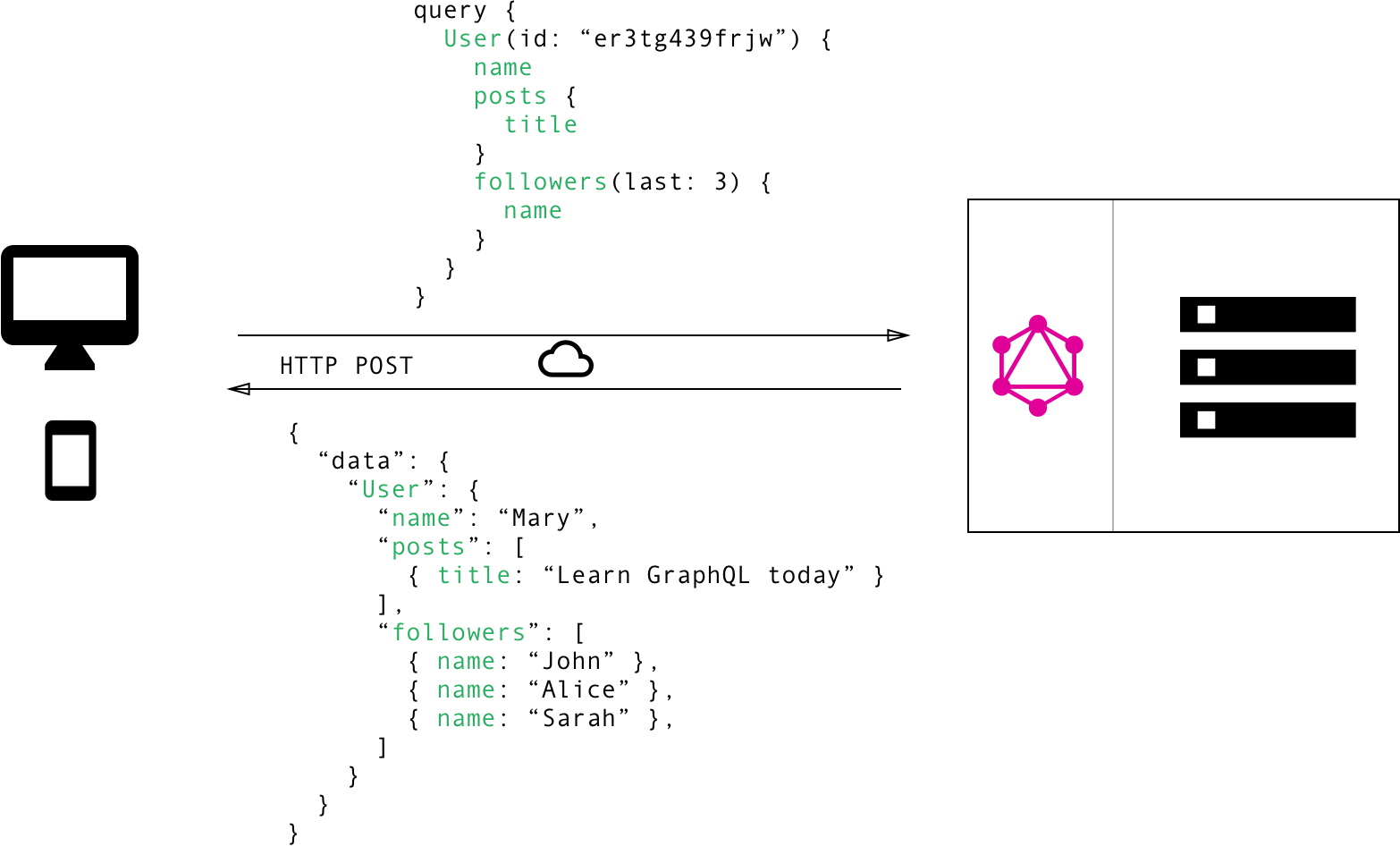 [GraphQL을 사용하면 클라이언트에게 필요한 데이터를 쿼리에 정확히 특정해줄 수 있습니다. 서버로부터 반환된 데이터의 구조가 쿼리에 정의된 중첩 구조를 정확히 따르고 있다는 점에 유의하세요.]
[GraphQL을 사용하면 클라이언트에게 필요한 데이터를 쿼리에 정확히 특정해줄 수 있습니다. 서버로부터 반환된 데이터의 구조가 쿼리에 정의된 중첩 구조를 정확히 따르고 있다는 점에 유의하세요.]
데이터를 딱 필요한 만큼만 불러오세요
REST가 가지는 가장 흔한 문제 중 하나가 바로 데이터를 더 가져오거나(Overfetch), 덜 가져오는(Underfetch) 문제입니다. 이런 일이 발생하는 이유는 클라이언트가 데이터를 다운받는 유일한 방법이 바로 고정된 데이터 구조를 반환하는 엔드포인트에 요청하는 것이기 때문입니다. 클라이언트가 필요로 하는 데이터를 정확히 제공하도록 API를 설계하는 것은 아주 어렵습니다.
"엔드포인트가 아니라, 그래프 관점에서 사고하세요." GraphQL의 Co-Inventor, Lee Byron의 Lessons From 4 years of GraphQL
Overfetch: 데이터를 너무 많이 불러오기
Overfetch란 어플리케이션에서 실제로 필요한 것보다 더 많은 정보를 클라이언트가 다운받는 것을 말합니다. 예를 들어, 화면에 사용자 명단을 표시해야 하는데, 단지 각 사용자의 이름만 필요한 경우를 떠올려보세요. REST API를 사용한다면, 일반적인 경우 /users 엔드포인트에 요청을 보내고, 사용자 데이터로 구성된 JSON 배열을 반환받을 겁니다. 하지만 클라이언트에서는 각 사용자의 이름만 필요한 상황이므로, 이 응답 데이터에는 사용자의 주소, 생일 등과 같이 실제로는 필요없는 정보가 포함되어있을 수도 있습니다.
Underfetch와 n+1 문제
또다른 문제는 Underfetch와 n+1 문제입니다. Underfetch란 특정 엔드포인트가 필요한 정보를 충분히 제공하지 못하는 경우를 말합니다. 이 경우 클라이언트는 필요한 정보를 모두 확보하기 위하여 추가적인 요청을 보내야만 합니다. 그러면 리스트를 불러온 뒤, 리스트 내 각각의 요소들에 대하여 한번씩 더 추가적으로 요청을 보내야 하는 상황이 되버릴 수도 있습니다.
위에서 이야기한 동일한 어플리케이션에서, 사용자 한명당 가장 최근에 팔로우한 사용자 3명도 함께 표시해야 하는 상황을 예를 들어보겠습니다. API는 /users/<user-id>/followers 엔드포인트를 추가적으로 제공합니다. 필요한 정보를 모두 표시하려면 어플리케이션은 /user 엔드포인트에 요청을 보내고, 그 다음 각 사용자에 대하여 users/<user-id>/followers 엔드포인트에 요청을 보내야 합니다.
프론트엔드의 빠른 개발 순환(Iteration)
REST API의 흔한 패턴은 어플리케이션의 화면(View) 관점에서 엔드포인트를 구조화하는 것입니다. 클라이언트의 특정 화면에서 필요한 정보를 얻으려면 대응하는 엔드포인트에 접근하기만 하면 되므로 아주 편리합니다.
이 접근의 가장 큰 단점은 프론트엔드 개발이 빠르게 순환하기 어렵게 만든다는 것입니다. UI를 조금이라도 바꾸면, 필요한 데이터가 변할 수도 있기 때문입니다. 결과적으로, 필요한 데이터가 달라지면 백엔드는 이에 대응하여야 합니다. 이로 인하여 생산성이 떨어지고, 사용자 피드백을 제품에 통합하는 것이 느려집니다.
GraphQL을 사용하면 이러한 문제가 해결됩니다. GraphQL의 유연한 특성 덕분에 서버에서 추가로 작업하지 않더라도 클라이언트를 수정할 수 있습니다. 클라이언트가 데이터 요구 사항을 정확하게 특정할 수 있으므로, 프론트엔드의 디자인 또는 필요 데이터가 변하더라도 백엔드 엔지니어가 일하지 않아도 됩니다.
백엔드에 대한 통찰력있는 분석
GraphQL를 사용하면 백엔드에 요청된 데이터에 대하여 세밀하게 분석할 수 있습니다. 각 클라이언트는 관심있는 정보만을 정확히 특정하므로, 사용가능한 데이터들이 어디서 어떻게 사용되는지 심도있게 이해할 수 있습니다. 이를 통하여 특정 API를 업그레이드시키거나, 클라이언트들이 더 이상 사용하지 않는 필드를 Deprecate하는 식으로 활용할 수 있습니다.
GraphQL을 사용하면, 서버가 처리하는 요청들에 대하여 저수준의 성능 모니터링이 가능합니다. GraphQL은 resolver 함수라는 개념을 사용하여 클라이언트가 요청한 데이터를 수집합니다. resolver를 사용하여 성능을 측정하면 시스템의 병목에 대한 중요한 통찰을 얻을 수 있습니다.
Schema와 Type 시스템의 이점
GraphQL은 API의 기능을 정의할 때 강타입 체계를 사용합니다. API로 노출되는 모든 타입들은 GraphQL 스키마 정의 언어(Schema Definition Language; SDL)로 작성된 스키마에 정의됩니다. 이 스키마는 마치 클라이언트와 서버 간의 계약과 같이 작용하여, 클라이언트가 데이터에 접근하는 방법을 정의합니다.
스키마가 정의되면, 프론트엔드와 백엔드는 추가적인 의사소통을 하지 않고 각자의 업무에 전념할 수 있습니다. 이제는 양측 모두, 네트워크 상에서 전달된 확실한 데이터 구조(역자 주: 스키마)를 인지하는 상황이기 때문입니다.
프론트엔드는 필요한 데이터 구조를 모킹하는 것으로 간단하게 어플리케이션을 테스트할 수 있습니다. 서버가 준비되고나면, 실제 API를 사용하여 클라이언트 어플리케이션에 데이터를 제공하면 됩니다.
Quiz
GraphQL 스키마와 강타입 체계의 이점은?
- JavaScript의 타입 시스템과 잘 연동한다.
- 스키마가 정의되고나면, 프론트엔드와 백엔드는 각기 독립적으로 업무에 전념할 수 있다.
- n+1 요청 문제를 해결한다.
- 함정 문제: GraphQL에는 타입 체계가 없다.
