새 고객을 유치하는데 드는 비용은 기존 고객을 유지하는 것보다 5배에서 25배까지 이른다고 합니다. 신규 고객 유치는 어려운 과정이기에 많은 시간과 자원을 필요로 합니다. 그렇기에 신규 고객을 유치하는 것 만큼 기존 고객을 유지하는 것 또한 중요합니다. 어렵게 도입한 고객들이 쉽게 이탈할수록 더 큰 유치 비용으로 돌아오게 되기 때문입니다. 그렇다고 재계약률을 높이기 위해 모든 고객사에게 혜택을 제공하는 것은 오히려 수익의 감소로 이어집니다. 이탈할 가능성이 높은 고객을 분류해 적절한 마케팅(할인 제공 등) 전략을 수행해야 하고 그 첫 단계로 BigQuery ML 을 이용한고객 이탈 예측을 시도해 보았습니다.
BigQuery ML 이란

- BigQuery의 standard SQL 쿼리로 머신 러닝 모델을 생성하고 실행할 수 있습니다.
- 데이터웨어 하우스(BigQuery)에서 모델링이 진행되기 때문에 속도가 빠릅니다.
- BigQuery와 통합되어 있어 데이터 추출, 전처리, 모델 학습, 평가 등 모든 단계를 단일 환경에서 처리할 수 있습니다. 개발 생산성을 향상에 도움이 됩니다.
여러 장점이 있지만 그 중에서도 가장 눈길을 끌었던 점이 SQL만으로 빠르게 ML 모델을 구축할 수 있다는 것입니다. 위 이미지를 보면 단 2번의 명령어 만으로 모델을 생성하고 예측합니다. 별도의 프로그래밍 언어를 배울 필요 없기에 BQ ML을 선택 했습니다.
지원 모델
- Linear regression : numerical value를 예측할 때 사용. 어머니와 아버지의 키를 기준으로 성인의 키 예측
- Logistic regression : 이메일 스팸 필터처럼 2개의 클래스를 분류할 때 사용.
- K-means clustering
- XG boost
- DNN
- Custom TensorFlow model importing
비용
저장 비용, 쿼리 비용 등 BigQuery의 가격 정책을 그대로 따릅니다.
Problem Solving
- 고객사의 데이터를 수집
- 수집된 데이터를 활용하여 이탈 여부를 예측하는 머신러닝 모델을 학습
- 이후 계약이 만료되는 고객사가 있을 경우
- 사전에 학습시켜둔 모델을 활용하여 고객사의 이탈 여부를 예측
- 이탈 가능성이 높은 고객사에게 프로모션을 주는 등 이탈을 방어
가설 설정 및 검증
가설 설정
먼저 ‘재계약 고객사와 이탈 고객사의 서비스 이용 패턴 혹은 성과에 차이가 있을 것이다' 라고 가설을 세웠습니다. 재계약 고객사는 주기적으로 서비스를 이용하거나 자주 문의하는 경향이 있을 수 있습니다. 이탈 고객사는 이러한 패턴이 적을 수 있습니다. 재계약 혹은 해지 시점으로부터 3달 동안의 데이터를 수집했습니다.
| Feature | 설명 | |
|---|---|---|
| 1 | label | 라벨. 재계약이면 1 해지면 0 |
| 2 | login | 로그인 |
| 3 | loginTime | 로그인 시간 |
| 4 | orderAmt | 전환 금액 |
총 20여개의 Feature를 가지고 진행했지만 자세한 목록은 생략하겠습니다.
모델 생성
CREATE OR REPLACE MODEL `dataSet.logistic_model`
OPTIONS(model_type = 'logistic_reg', input_label_cols=['label'], enable_global_explain=TRUE) AS
SELECT *
FROM `dataSet.stat`CREATE MODEL 절을 사용하여 logistic_model이라는 모델을 만들고 학습시킵니다.
OPTIONS(model_type='logistic_reg') 절은 로지스틱 회귀 모델을 만든다는 것을 나타냅니다. input_label_cols 옵션은 SELECT 문에서 라벨로 사용할 열을 지정합니다. ENABLE_GLOBAL_EXPLAIN=TRUE 옵션을 사용하면 모델의 중요한 특성이 무엇인지 확인가능합니다. 로지스틱 회귀 모델은 입력 데이터를 두 클래스로 분할하려 시도한 후 데이터가 클래스 중 하나일 확률을 제공합니다. 일반적으로 감지하려는 항목은 1로 표시되고 나머지는 0으로 표시됩니다. 여기서 로지스틱 회귀 모델 출력이 0.9면 재계약 확률이 90%입니다.
평가
SELECT *
FROM ML.EVALUATE(MODEL `dataSet.logistic_model`,
(
SELECT *
FROM `dataSet.stat`
)
)로지스틱 회귀를 수행했으므로 결과에 다음 열이 포함됩니다.
- precision : 분류 모델의 측정항목입니다. 정밀도는 포지티브 클래스 예측 시 모델의 정확한 빈도를 식별합니다.
- recall : 가능한 모든 포지티브 라벨 중에서 모델이 올바르게 식별한 라벨 수라는 질문에 답하는 분류 모델의 측정항목입니다.
- accuracy : 정확도는 분류 모델이 바르게 되었다고 예측하는 비율입니다.
- f1_score : 모델의 정확도를 나타내는 척도입니다. f1 점수는 정밀도와 재현율의 조화 평균입니다. f1 점수의 최고 값은 1입니다. 최저 값은 0입니다.
- log_loss : 로지스틱 회귀에 사용되는 손실 함수입니다. 모델 예측과 올바른 라벨 간의 차이 정도를 나타내는 척도입니다.
테스트
SELECT *
FROM ML.PREDICT(MODEL `dataSet.logistic_model`,
(
SELECT *
FROM `dataSet.stat`
)
)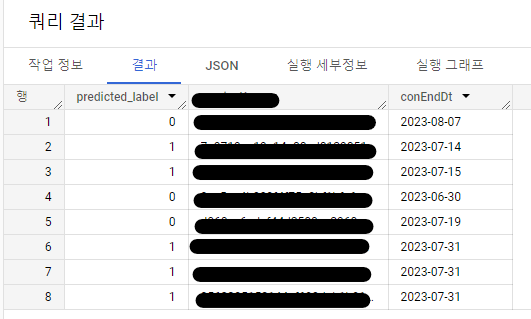
모델을 평가했으므로 다음 단계에서는 이 모델을 사용하여 결과를 예측합니다. 한 달 내에 계약 기간이 만료되는 고객사 만을 대상으로 예측했고 빠르게 결과가 나왔습니다. 결과를 예측하는 데 사용되는 쿼리는 위와 같습니다.
분석
다만 예측률에 문제가 있었는데 실제 서비스로 활용하기에는 무리인 수준 이었습니다. 예측이 빗나간 고객사들만 따로 분석해 보았습니다.
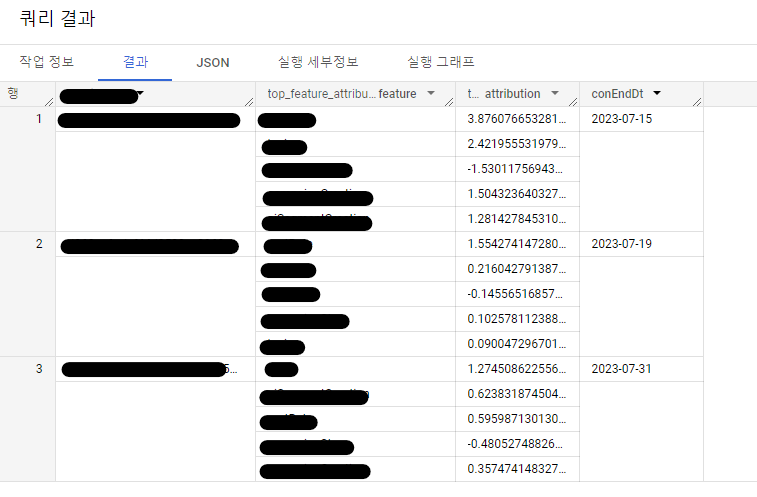
모델에서 이러한 예측 결과를 생성하는 이유를 알아보려면 ML.EXPLAIN_PREDICT 함수를 사용합니다. ML.EXPLAIN_PREDICT는 ML.PREDICT의 확장된 버전으로 예측 결과를 출력할 뿐만 아니라 예측 결과를 설명하는 추가 열을 출력합니다. 자세한 결과를 올릴 수는 없기에 짧게 요약하면 Feature 선정이 모델에 적합하지 않았다고 결론을 내렸습니다.!
SELECT
*
FROM
ML.GLOBAL_EXPLAIN(MODEL `dataSet.logistic_model`)
ML.GLOBAL_EXPLAIN 명령어로 모델 전체의 attribution을 알 수 있습니다.
결론
‘재계약 고객사와 이탈 고객사는 서비스 이용 패턴 혹은 성과에 차이가 있을 것이다' 라고 가설을 세우고 빅쿼리 ML을 사용하여 머신러닝 모델을 만들어 보았지만 예측력이 아직 높지 않은 상황입니다. 지속적으로 데이터를 수집, 탐색하고 모델을 업데이트해야 만족할 만한 수준에 도달할 듯 싶네요. 별개로 빅쿼리 ML에는 매우 만족했습니다. 구글에서 소개한대로 사용하기 쉬웠기에 ML을 잘 모르는 개발자가 사용하기에도 무리 없다고 봅니다.
참조
https://m.blog.naver.com/PostView.naver?blogId=davincilabs&logNo=222389635306&proxyReferer=
https://yozm.wishket.com/magazine/detail/1070/
https://dbr.donga.com/article/view/1303/article_no/5854/ac/magazine
https://cloud.google.com/bigquery/docs/logistic-regression-prediction?hl=ko
https://blog.elogia.net/bigquery-ml-machine-learning-desde-bigquery
https://groobee.atlassian.net/wiki/people/5fbe092e2730d80076a66261?ref=confluence&src=pageCard

글이 잘 정리되어 있네요. 감사합니다.