빅쿼리 테이블의 클러스터링에 관한 내용을 정리했습니다.
이슈
기존의 모든 테이블들은 날짜를 기준으로 파티셔닝 되있었지만 새로 만들 테이블은 파티셔닝을 적용하기가 어려운 상황이 생겼습니다. 회원 정보 테이블에서 '등급이 GOLD 인 유저를 추출' 이라고 하면 정수 범위나 시간 단위로 파티셔닝을 적용하기가 어렵습니다. 그렇다고 전체 테이블을 스캔하면 어마어마한 비용이 발생할테니 일단 String 값을 숫자로 변환해 파티셔닝을 적용해보았습니다.
private int getPartitioningIndex(String str) {
long count = 0;
for (int i = 0; i < str.length(); i++) {
long ch = str.charAt(i);
count += (ch*ch*ch);
}
return (int) (count%10000);
}
// 자바 코드로 문자열을 정수값으로 변환SELECT * FROM `DataSet.table` where grade = 'GOLD' and partitionIndex = 6860
// where 조건에 partitionIndex 추가
테이블에 partitionIndex 컬럼을 추가했고 조회시 where 조건에 포함했습니다. 1G가 넘는 조회 비용이 110MB로 줄었으니 분명 비용 절감에 도움이 됬습니다. 하지만 코드로 partitionIndex를 매번 구해야 하는 번거로움이 생겼기에 다른 방안을 찾아보았습니다.
맞춤형 파티셔닝
찾아보니 빅쿼리는 이미 String Field로 파티셔닝하는 방법을 제공하고 있었습니다. 링크 를 보시면 자세한 과정이 나와있는데 String 값을 INTEGER 로 변환해주는 기능을 제외하면 제가 시도한 방법과 동일했습니다.
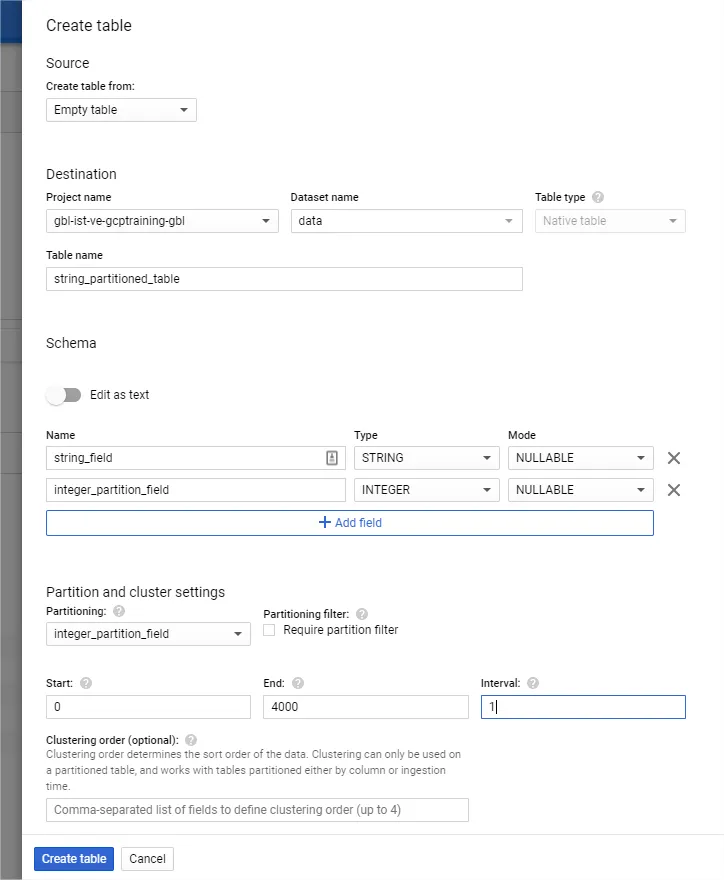
SELECT *
FROM `data.string_partitioned_table`
WHERE 정수_파티션_필드 = ABS(MOD(FARM_FINGERPRINT("string_example"),4000) + 1)BigQuery에는 많은 기능이 내장되어 있으며 그 중 하나가 Farm-Fingerprint 해시 기능입니다. 이 함수는 입력을 INT64 값으로 변환합니다. 위 방법으로 동일한 파티션 값 처리를 사용하여 올바른 파티션에 따라 데이터를 검색합니다.
클러스터링 적용

두 번째 방법은 클러스터링 입니다. 클러스터링된 테이블을 사용하면 쿼리 성능을 높이고 쿼리 비용을 줄일 수 있습니다. 테이블 생성시 해당 컬럼을 기준으로 클러스터링을 적용했고 파티셔닝과 거의 비슷한 결과가 나왔습니다. 따로 partitionIndex를 만들고 싶지 않았기에 클러스터링 하는 방향으로 진행했습니다.
주의할 점이 몇가지 있는데 비용측정기에서 쿼리에 의해 처리되는 바이트나 쿼리 비용을 정확히 예측하지 못할 수도 있다는 것입니다. 하지만 실행 시 총 바이트 수를 줄이려고 시도하기 때문에 실제 과금되는 데이터 처리량은 쿼리 후 결과를 보고 분석하는 것이 정확합니다.
SELECT * FROM `DataSet.table` where grade like 'GOLD%' // 클러스터링 적용
SELECT * FROM `DataSet.table` where grade like '%GOLD' // 클러스터링 미적용, FULL SCAN또한 파티셔닝을 적용할 컬럼이 어떤 식으로 검색될지 알아두셔야 합니다. 컬럼이 단어순으로 정렬되있기 때문에 like 검색시 클러스터링 적용이 안되서 Full Scan 하게 되는 경우도 있습니다.
SELECT * FROM `DataSet.table` where gender = 'MALE'
마지막으로 클러스터링 컬럼 순서는 가장 빈번하게 검색되는 컬럼 순서로 조합해야 합니다. grade, gender 순으로 클러스터링을 적용했기에 위 쿼리의 경우에도 gender 만을 검색하면 효율이 낮습니다.
클러스터링과 파티셔닝 조합

파티셔닝은 데이터를 분할해서 저장, 클러스터링은 분할된 영역안에서 정렬 이라고 생각하시면 됩니다. 위 이미지를 보면 이해가 쉽습니다.
- 위 사례에는 클러스터링과 파티셔닝을 둘 다 쓸 수 없었지만 테이블 클러스터링과 테이블 파티션 나누기를 결합하면 쿼리를 더 효율적으로 쿼리를 수행할 수 있습니다.
- 한 컬럼에 클러스터링과 파티셔닝을 둘 다 적용해도 한가지만 적용했을 때에 비해 성능 향상은 없었습니다.
코드
StandardTableDefinition definition = StandardTableDefinition.newBuilder()
.setSchema(Constants.SchemaConstants.USER_DATA)
.setTimePartitioning(TimePartitioning.newBuilder(TimePartitioning.Type.DAY)
.setField(Constants.FieldConstants.REG_DATETIME).setExpirationMs(7776000000L) // 90 days
.build())
.setClustering(Clustering.newBuilder()
.setFields(List.of(id, device, gender))
.build())
.build();
TableInfo updatedTableInfo = tableInfo.toBuilder()
.setDefinition(definition)
.build();
bigQuery.create(updatedTableInfo); 클러스터링 제한사항
- 클러스터링 열은 최대 4개만 지정할 수 있습니다.
- 클러스터링되지 않은 기존 테이블을 클러스터링할 경우 기존 데이터는 클러스터링되지 않습니다. 클러스터링된 열을 사용하는 새 데이터만 저장되며 자동 재클러스터링이 적용됩니다.
- 클러스터링의 이점을 얻으려면 쿼리 필터 순서가 클러스터링된 열 순서와 일치해야 하며 최소한 클러스터링된 첫 번째 열이 포함되어야 합니다.
- 클러스터링에 STRING 유형 열을 사용하는 경우 처음 1,024자만 사용하여 데이터를 클러스터링합니다.
후기
기존 테이블도 클러스터링을 적용했다면 비용절감 할 수 있었을텐데 아쉬움이 있습니다. 뒤늦게나마 알게됬으니 다행이긴 합니다.
참고
https://cloud.google.com/bigquery/docs/clustered-tables?hl=ko
https://burning-dba.tistory.com/147
https://hoffa.medium.com/bigquery-optimized-cluster-your-tables-65e2f684594b
https://medium.com/google-cloud/partition-on-any-field-with-bigquery-840f8aa1aaab
