
개요 - SQL 왜케 복잡하게 써?
SQL을 왜 배워야 하나? JPA로 다 되는거 아니야?
-> NO!
JPA로 해결할 수 있는 간단한 쿼리도 있지만, SQL을 사용해서 복잡한 쿼리를 한번에 수행하는 것이 DB에 주는 부담을 훨씬 줄여준다. 따라서 SQL을 사용해서 더욱 복잡한 CRUD를 수행한다면 서비스의 성능 향상에 큰 도움을 줄 수 있다.
Subquery 써보기
- checkins 테이블에서 course id, 유저의 체크인 수(중복없이) 뽑아본다.
select course_id, count(distinct(user_id)) as cnt_checkins from checkins
group by course_id- 결과

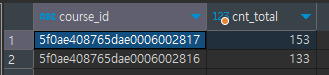
- course_id별 인원을 구해보기
select course_id, count(*) as cnt_total from orders
group by course_id- 결과
- 이 둘을 서브쿼리를 사용해서 합치기.
select a.course_id, b.cnt_checkins, a.cnt_total from
(
select course_id, count(*) as cnt_total from orders
group by course_id
) a
inner join (
select course_id, count(distinct(user_id)) as cnt_checkins from checkins
group by course_id
) b
on a.course_id = b.course_id- 결과

- id로 볼거야? title로 보자. 근데 title은 courses에 있는데...그리고 비율도 한번 보자!
select c.title,
a.cnt_checkins,
b.cnt_total,
(a.cnt_checkins/b.cnt_total) as ratio
from
(
select course_id, count(distinct(user_id)) as cnt_checkins from checkins
group by course_id
) a
inner join
(
select course_id, count(*) as cnt_total from orders
group by course_id
) b on a.course_id = b.course_id
inner join courses c on a.course_id = c.course_id위와 같이 join하면 된다. left join / inner join 모두 가능하며, 둘 다 리즈너블 한듯(내가 left join해서...)
- 결과

근데 좀 더럽잖아. 좀 더 깔끔하게 보자.
- with절을 사용해서 좀 더 깔끔하게 만들 수 있다.
with table1 as (
select course_id, count(distinct(user_id)) as cnt_checkins from checkins
group by course_id
), table2 as (
select course_id, count(*) as cnt_total from orders
group by course_id
)
select c.title,
a.cnt_checkins,
b.cnt_total,
(a.cnt_checkins/b.cnt_total) as ratio
from table1 a inner join table2 b on a.course_id = b.course_id
inner join courses c on a.course_id = c.course_id위와 같은 형태이다. 테이블 1,2를 with절로 미리 사용할것이라고 선언하고 그 아래에 있는 select문에서 더 깔끔하게 만드는 방식.

당연히 결과는 같다.
유용한 SQL 분법들 알아보기
1. SUBSTRING_INDEX
SUBSTRING_INDEX 는 문자열을 쪼개주는 역할을 한다.
select user_id, email, SUBSTRING_INDEX(email, '@', -1) from users위와 같은 형태로 나타낸다.
substring_index(찾을 데이터가 있는 테이블, '식별할 특정 문자', 1부터 시작하는 순서(-1은 마지막 인덱스인 친구)) 와 같은 형태이다.
혹은 다음과 같은 사용도 가능하다.
select order_no, created_at, substring(created_at,1,10) as date from orders
- SUBSTRING(문자열, 출력을 하고싶은 첫 글자의 위치, 몇개의 글자를 출력하고 싶은지) 의 형태.
2. CASE
케이스는 다음과 같이 사용된다
case when 조건을 적용할 칼럼 + 조건식 then 새 칼럼에 추가할 값 혹은 메시지
when then ...
else ...
END as 'case로 감싼 칼럼명'
케이스 사용 예시는 다음과 같다.
WITH table1 as (
SELECT pu.point_user_id , pu.`point` ,
CASE
when pu.`point` > 10000 then '1만 이상'
when pu.`point` > 5000 then '5천 이상'
else '5천 미만'
END as lv
from point_users pu)
select lv, count(*) from table1
group by lv- 결과
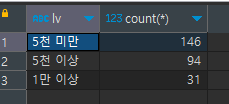
다음과 같이 보여진다.
출처
출처 : 스파르타 코딩 클럽 - 엑셀보다 쉬운 SQL 강의
