
(썸네일 - 스프링 공식 문서)
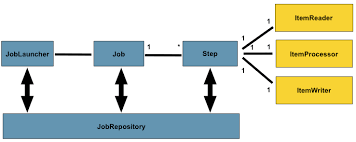
시작하기
로컬 환경에서 H2 디비 이용하기로 결정했다.
-
우선, Movie 프로젝트 자체가 벌크인서트 수행 속도를 측정하기 위해서 현재 시작마다 더미데이터를 인서트 하고 있다. (ddl-auto : create 설정해놓고)
-
더불어, 테스트를 위해서 @Scheduled 어노테이션을 활용해서 1분마다 어떤 아이디가 불렸는지를 확인해보려고 한다.
-
그럼, 시작해보자
부트시에 나오는, Hibernate의 ddl-auto 설정과 더불어 스타트 할 때 사용했던 설정들에 의한 쿼리.
@Component
@RequiredArgsConstructor
public class DummyDataLoader implements CommandLineRunner {
private final MovieRepository movieRepository;
private final JdbcBulkInsertRepository jdbcBulkInsertRepository;
@Override
@ExeTimer
public void run(String... args) throws Exception {
List<Movie> movies = movieRepository.findAll();
List<MovieImage> movieImages = new ArrayList<>();
for (Movie movie : movies) {
for (int i = 1; i <= 5; i++) {
MovieImage movieImage = MovieImage.builder()
.movie(movie)
.imageUrl("image_" + i + "_for_movie_" + movie.getId())
.build();
movieImages.add(movieImage);
}
}
jdbcBulkInsertRepository.bulkInsertMovieImage(movieImages);
List<MovieVideo> movieVideos = new ArrayList<>();
for (Movie movie : movies) {
for (int i = 1; i <= 3; i++) {
MovieVideo movieVideo = MovieVideo.builder()
.movie(movie)
.videoUrl("video_" + i + "_for_movie_" + movie.getId()).build();
movieVideos.add(movieVideo);
}
}
jdbcBulkInsertRepository.bulkInsertMovieVideo(movieVideos);
List<CastMember> castMembers = new ArrayList<>();
for (Movie movie : movies) {
for (int i = 1; i <= 3; i++) {
CastMember castMember = CastMember.builder()
.memberName("Cast Member " + i)
.movie(movie)
.build();
castMembers.add(castMember);
}
}
jdbcBulkInsertRepository.bulkInsertCastMember(castMembers);
}
@PostConstruct
public void afterRun(){
List<Movie> movies = IntStream.rangeClosed(1, 20)
.mapToObj(i -> Movie.builder()
.releaseDate((long) i)
.posterImageUrl("poster_" + i)
.movieName("Movie " + i)
.director("Director " + i)
.genre("Genre " + i)
.originalTitle("Original Title " + i)
.synopsis("Synopsis " + i)
.runningTime(120)
.build())
.collect(Collectors.toList());
jdbcBulkInsertRepository.bulkInsertMovies(movies);
}
}위 코드를 통해서 더미데이터들을 인서트 하고 있다
(자세한 내용은 "더미데이터 인서트 성능비교")
그러나 그 후, 다음과 같은 오류를 만나게 될 것이다.

아차! 내가 스키마 설정을 안했구나!!
어? 근데... 원래 H2 DB 로컬로 띄우면 스키마 설정 자동으로 해주는데!!??!?
그러나 ddl-auto : create 의 수행 과정 중 문제가 있을 수 있다고 한다 (Batch schema 설정에)
어 그러면...
spring.batch.jdbc.initialize-schema=alwaysapplication.properties에 위 코드를 추가하면 되겠다!!
또또 만나게 되는 에러! (위와 같은 이유로)
그렇다면, 그냥 직접 스키마를 넣어버리자. 근데 로컬인데?...
스키마를 찾아서, 해당 파일에 존재하는 스키마 생성부분 복사!
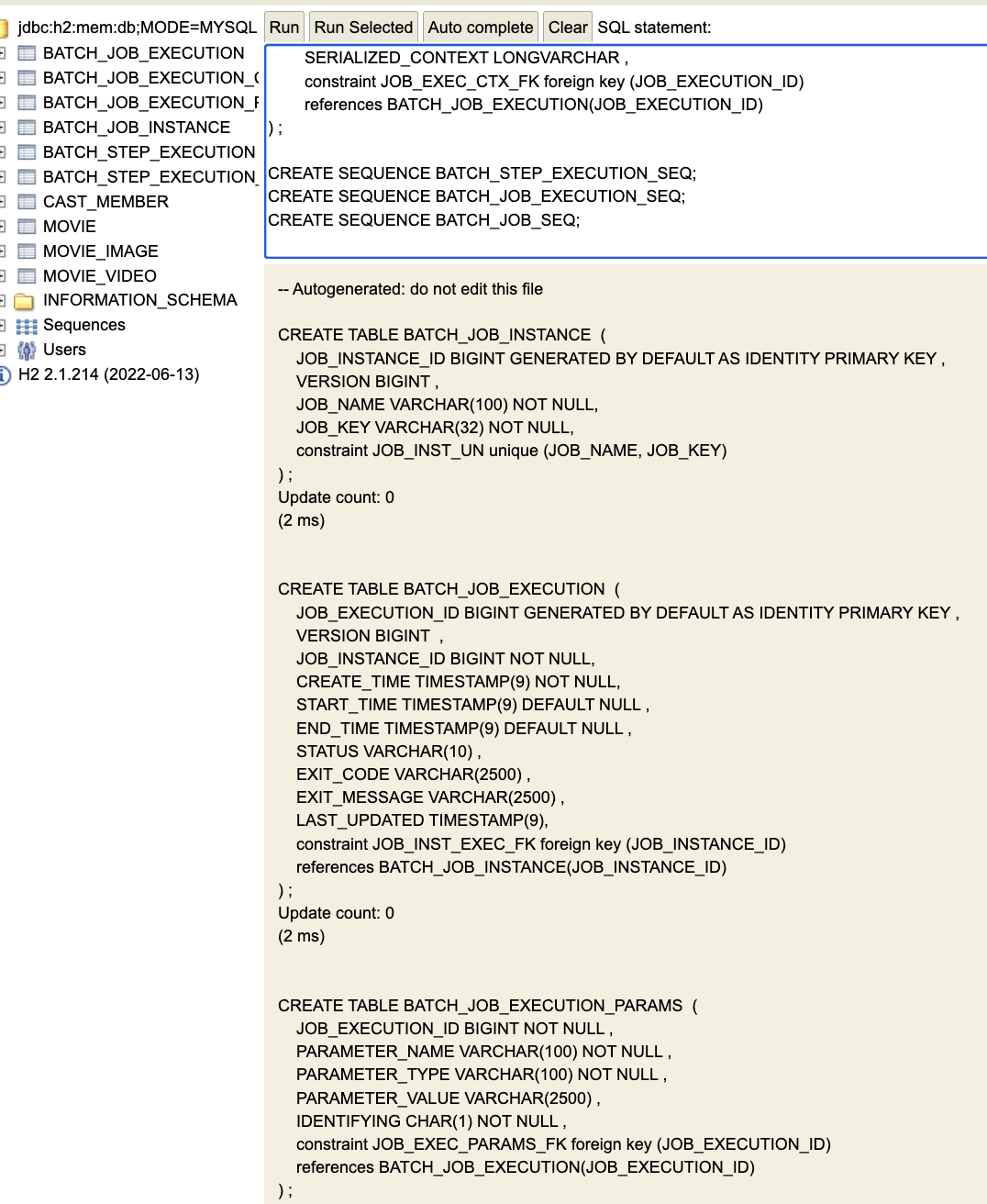
직접 넣어부러!

아아주 잘 실행되는 모습. 어? 근데 내가 전시간 코드에서, 분명 로깅이 되게 했었는데...
@Bean
public Tasklet testTasklet(){
return ((contribution, chunkContext) -> {
HashMap<String, Long> movieNameMap = new HashMap<>();
for (String s : AnnotationBasedAOP.map.keySet()) {
String movieName = movieRepository.findById(Long.parseLong(s)).orElseThrow().getMovieName();
movieNameMap.put(movieName, AnnotationBasedAOP.map.get(s));
// TODO: 2023/06/12 이곳에 movieNameMap을 파일/디비로 저장하는 로직이 필요하다.
// 현재는 로깅하도록 하자
log.info("영화 이름 :" + movieName + ", 호출 횟수 :" + AnnotationBasedAOP.map.get(s));
}
return RepeatStatus.FINISHED;
});
}AnnotationBasedAOP < 이라고 하는 클래스에 넣어줬던 static한 map이 현재 적용되지 않나보다!!! 왜냐면 AOP 사용해서 어노테이션 붙은 녀석에게만 적용되도록 했걸랑! 그럼 한번 적용시켜보자
1. AOP 이용해서 만든 어노테이션 살펴보기
@Target({ElementType.METHOD, ElementType.ANNOTATION_TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface CountExeByMovieId {
}
// 어노테이션 @CountExeByMovieId 를 선언해준 모습. 매서드에 걸 수 있고, 런타임에 작동한다
...
@Pointcut("@annotation(com.example.movie.common.aop.CountExeByMovieId)")
private void count(){};
@Before("count()")
public void countMovieIdCall(JoinPoint joinPoint){
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
String[] parameterNames = signature.getParameterNames();
// 무비아이디로 받고 있으므로, 패러미터는 하나이고 따라서 그냥 0번 인덱스 넣으면 될듯?
String movieId = parameterNames[0];
map.put(movieId, map.getOrDefault(movieId, 0L) + 1);
// 콜 될때마다 해시맵에다가 호출 횟수를 관리하는거지
}- 위는 어노테이션의 설정이고,
- 아래는 실제 AOP Configuration class 에서 포인트컷과 수행 동작을 설정 해 준 모습이다.
따라서, 내가 원하는 컨트롤러 매서드에 그냥 어노테이션 찍어주면 된다!
@GetMapping("/api/v1/movies/{movieId}")
@CountExeByMovieId // 특정 movieId를 통해 get하므로, 여기다 찍어주자
public ResponseEntity<MovieResponseDto> getMovieById(@PathVariable Long movieId){
return ResponseEntity.ok(movieService.getMovieById(movieId));
}위와 같이 실행 후, 살펴보자
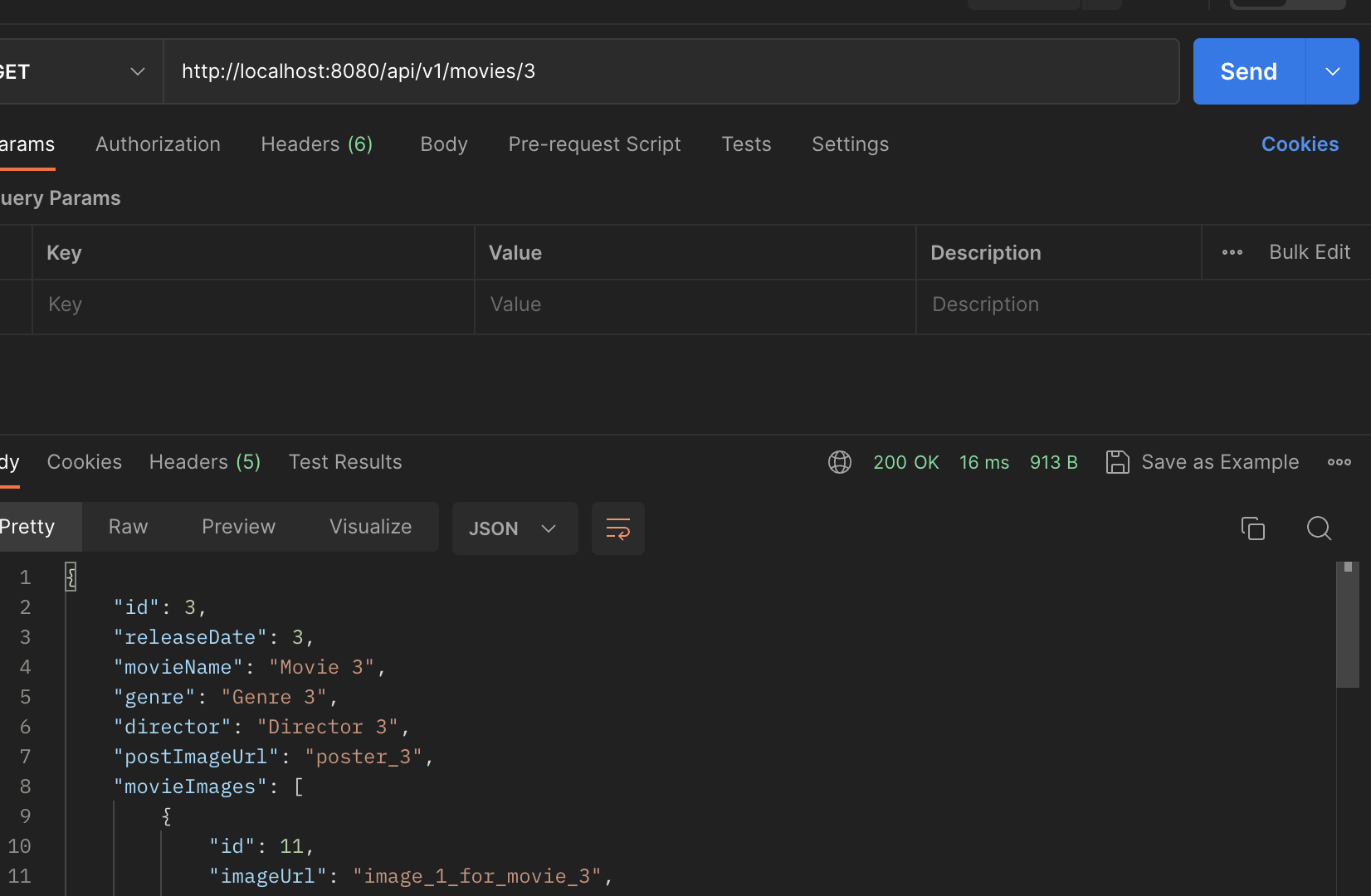
위처럼 포스트맨을 사용해서, 해당하는 API 3번 movieId로 요청을 보내봤다.
어!!?? 근데 NumberFormatExeption이 발생한다!!
디버그로 혼내주자.
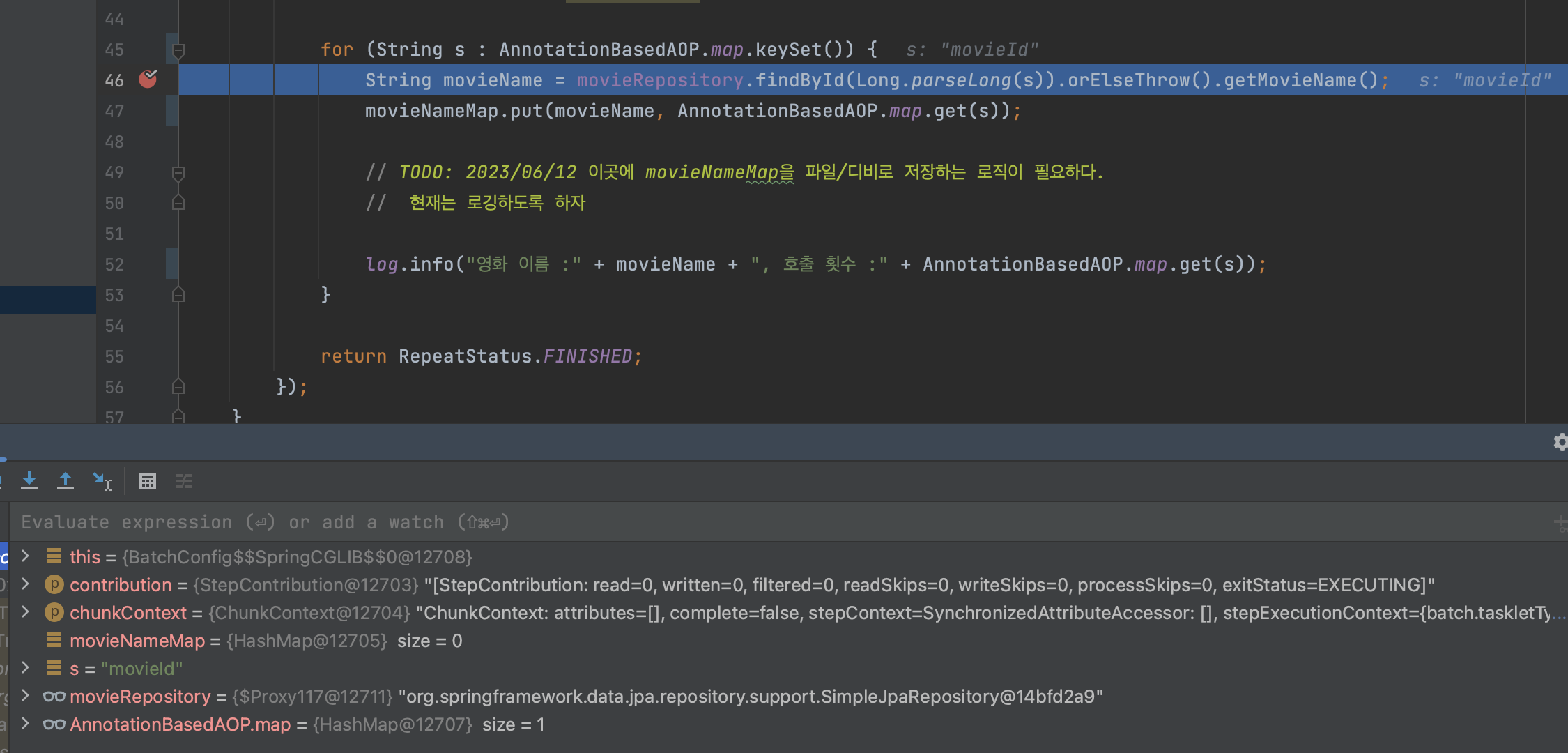
어제의 나(멍청함)는 무슨 짓을 저질렀던 것일까? keySet에 movieId가 들어오고 있다...
- 패러미터의 "값"이 아니라
- 패러미터의 "이름" 이 들어오고 있다!!!
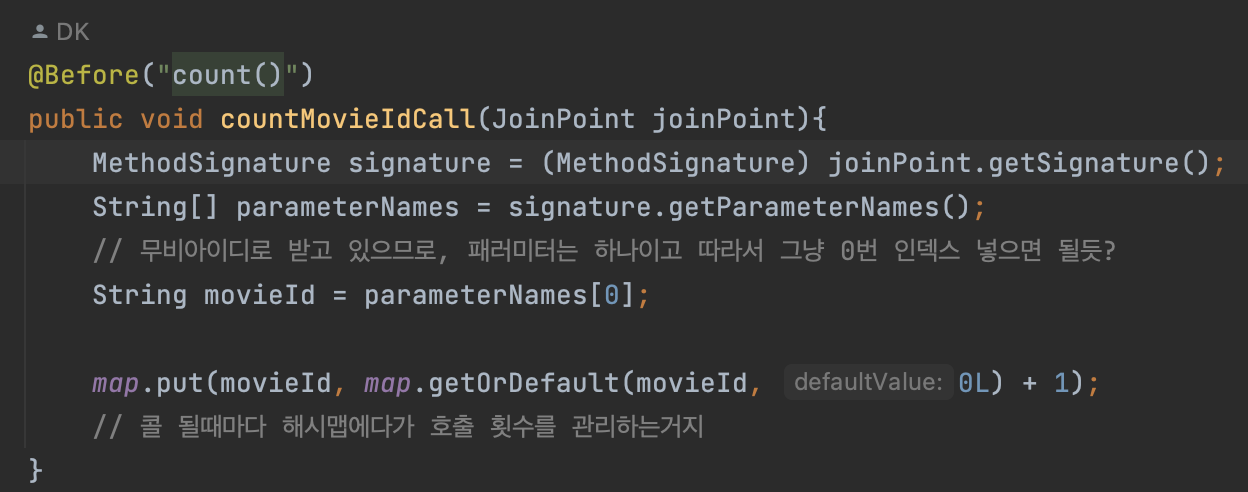
범인은 바로 너!!! 패러미터의 이름을 가쟈ㅕ오고 있구나! 고럼 오째야할고?
아래와 같이 바꾸면 된다!
@Slf4j
@Aspect
@Component
public class AnnotationBasedAOP {
public static HashMap<Long, Long> map = new HashMap<>();
// 이제 이녀석은 String 타입이 아니라 Long 타입으로 관리되어도 됨!
...
@Pointcut("@annotation(com.example.movie.common.aop.CountExeByMovieId)")
private void count(){};
@Before("count()")
public void countMovieIdCall(JoinPoint joinPoint){
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Object[] arguments = joinPoint.getArgs();
Long movieId = (Long) arguments[0];
map.put(movieId, map.getOrDefault(movieId, 0L) + 1);
// 콜 될때마다 해시맵에다가 호출 횟수를 관리하는거지
}
}그럼 이제 잘 바꿔줬으니. 잘 되는지 볼까? 3번 아이디로 4번만 호출해보자

오!! 매우 잘된다!
그러면, 초기화도잘 되는 지 보자. 다시 4번 아이디 몇번 호출해보자구

3번아이디가 초기화되고 (STEP2에 의해), 4번 아이디가 정상적으로 호출을 집계했다.
그럼 3,4,5 각각 3번씩 불러볼까?
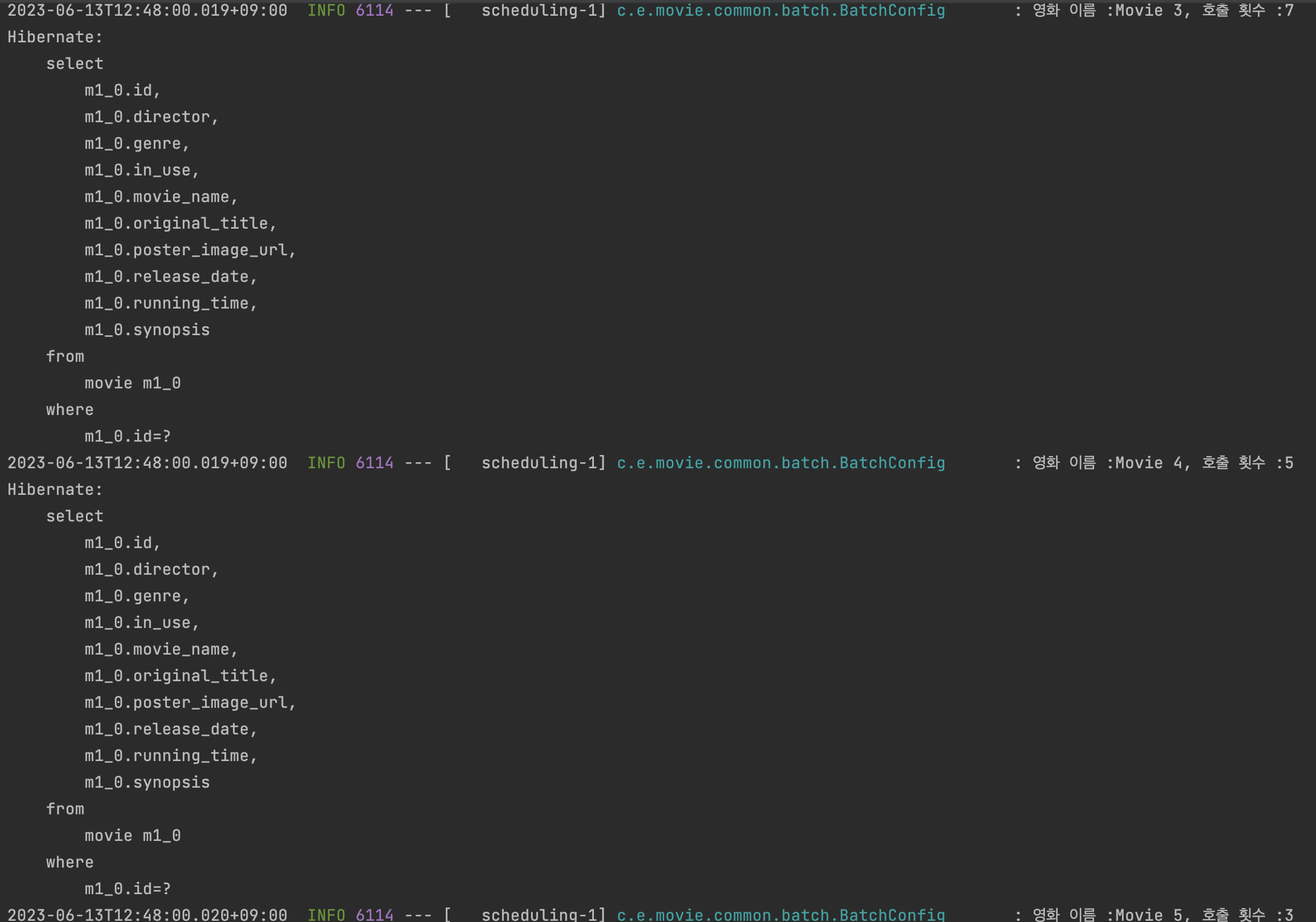
매우 잘 나오긴 하지만, 이렇게 쿼리가 많이 발생하는 것을 바라진 않았다! 그럼 최적화해보자.
2. 최적화 (쿼리)
먼저, 원래 존재했던 로직을 보자
@Bean
public Tasklet testTasklet(){
return ((contribution, chunkContext) -> {
// HashMap<String, Long> movieNameMap = new HashMap<>();
for (Long s : AnnotationBasedAOP.map.keySet()) {
String movieName = movieRepository.findById(s).orElseThrow().getMovieName();
// movieNameMap.put(movieName, AnnotationBasedAOP.map.get(s));
// TODO: 2023/06/12 이곳에 movieNameMap을 파일/디비로 저장하는 로직이 필요하다.
// 현재는 로깅하도록 하자
log.info("영화 이름 :" + movieName + ", 호출 횟수 :" + AnnotationBasedAOP.map.get(s));
}
return RepeatStatus.FINISHED;
});
}- 위 for 반복문에서 "호출된 id" 마다 repository.findById 매서드를 호출하고 있다. 따라서 매번 쿼리가 발생한다
- 이렇게 하지 말고, 저 아이디를 싹 모아서 where id in ~ 쭉 나열해주고, 그 후에 그 아이디별로 싹 찾아와서 로깅해보자.
@Bean
public Tasklet testTasklet(){
return ((contribution, chunkContext) -> {
ArrayList<Long> ids = new ArrayList<>(AnnotationBasedAOP.map.keySet());
HashMap<String, Long> names = new HashMap<>();
List<Movie> movieList = movieRepository.findAllById(ids);
for (Movie movie : movieList) {
names.put(movie.getMovieName(), AnnotationBasedAOP.map.get(movie.getId()));
}
// TODO: 2023/06/12 이곳에 movieNameMap을 파일/디비로 저장하는 로직이 필요하다.
// 현재는 로깅하도록 하자
for (String s : names.keySet()) {
log.info("영화 이름 :" + s + ", 호출 횟수 :" + names.get(s));
}
return RepeatStatus.FINISHED;
});
}- 로직을 위와 같이 변경했다
- 젤 큰건 일단 "ids" 컬렉션을 이용해서 한 개의 쿼리로 여러 개의 엔티티를 한방에 가져왔다.
- 가져온 엔티티의 값을 이용해서 "name" 과, "호출횟수" 를 로깅한 모습
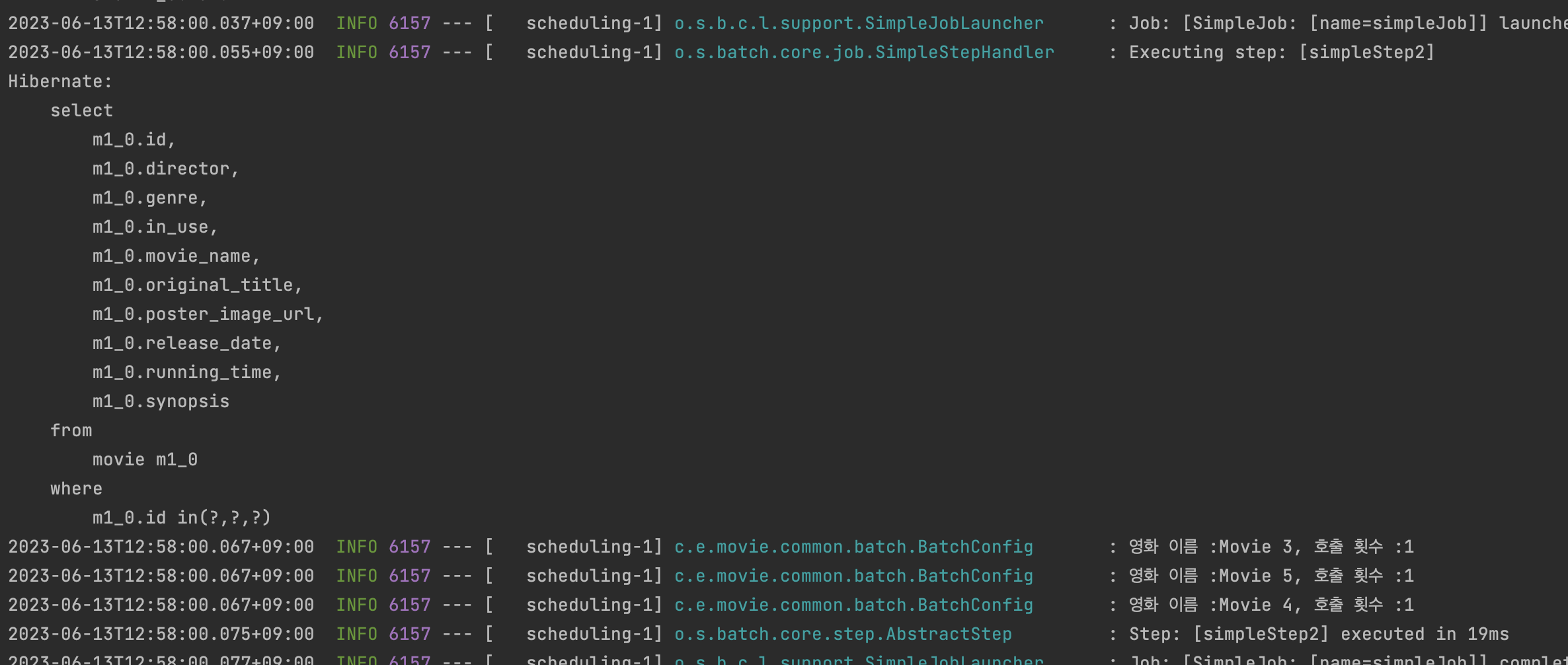
아주 잘된다!
스키마 살펴보기
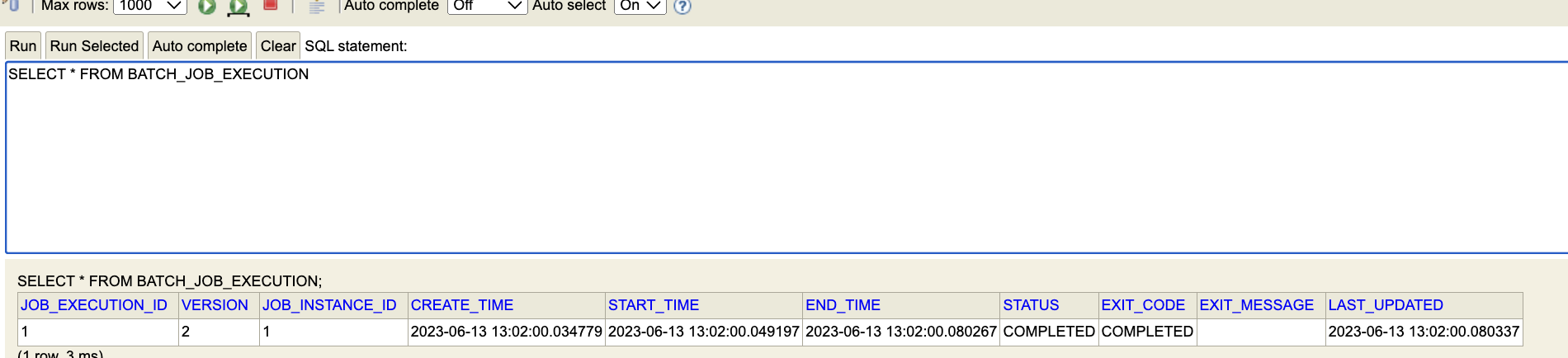
- JOB EXECUTION
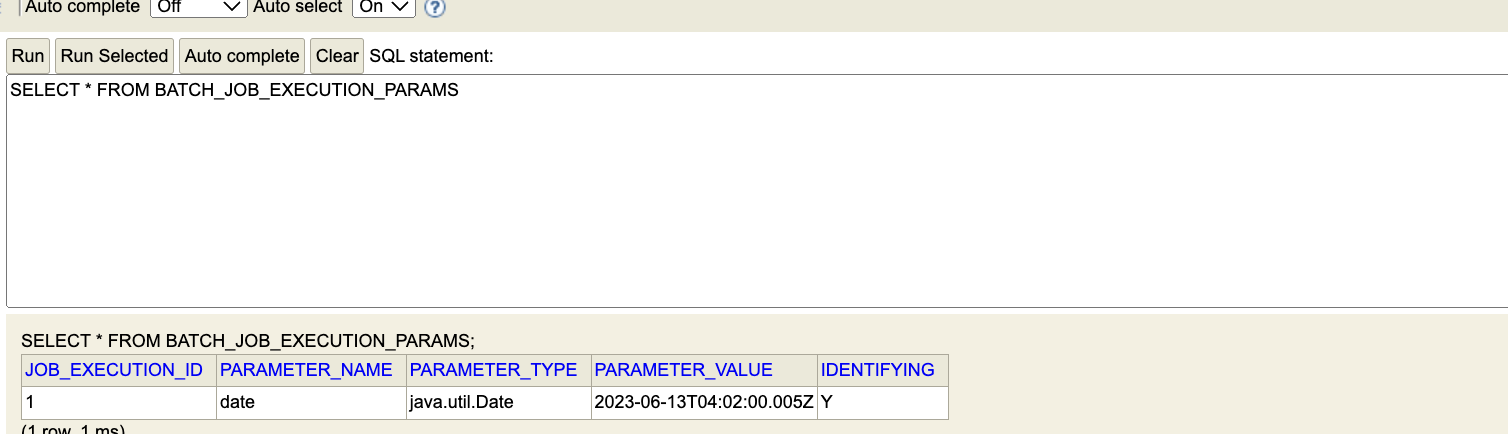
- JOB EXECUTION PARAMS
- BATCH STEP EXECUTION

결론
생각보다는 어렵지 않았다. 하지만, DB 스키마를 관리하고 조정하려면 엄청 까다롭게 관리해야 할 듯 하다. 실패 시 다시 시도하는 로직도 넣어보고 싶다.
수정
제일 중요한 JOB 부분 코드를 올리지 않은 듯 하여 올린다.(제일 궁금할?)
@Bean
public Job simpleJob1(JobRepository jobRepository, Step simpleStep1, Step simpleStep2) {
return new JobBuilder("simpleJob", jobRepository)
.start(simpleStep1)
.next(simpleStep2)
.build();
}위와 같이 simpleStep1 -> next(simpleStep2) 순서로 실행된다.
package com.example.movie.common.batch;
import com.example.movie.common.aop.AnnotationBasedAOP;
import com.example.movie.movie.entity.Movie;
import com.example.movie.movie.repository.MovieRepository;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.job.builder.JobBuilder;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.transaction.PlatformTransactionManager;
import java.lang.reflect.Array;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
@EnableScheduling
@Configuration
@Slf4j
@RequiredArgsConstructor
public class BatchConfig {
private final MovieRepository movieRepository;
@Bean
public Job simpleJob1(JobRepository jobRepository, Step simpleStep1, Step simpleStep2) {
return new JobBuilder("simpleJob", jobRepository)
.start(simpleStep1)
.next(simpleStep2)
.build();
}
@Bean
public Step simpleStep1(JobRepository jobRepository, Tasklet testTasklet, PlatformTransactionManager platformTransactionManager){
return new StepBuilder("simpleStep1", jobRepository)
.tasklet(testTasklet, platformTransactionManager).build();
}
@Bean
public Tasklet testTasklet(){
return ((contribution, chunkContext) -> {
ArrayList<Long> ids = new ArrayList<>(AnnotationBasedAOP.map.keySet());
HashMap<String, Long> names = new HashMap<>();
List<Movie> movieList = movieRepository.findAllById(ids);
for (Movie movie : movieList) {
names.put(movie.getMovieName(), AnnotationBasedAOP.map.get(movie.getId()));
}
// TODO: 2023/06/12 이곳에 movieNameMap을 파일/디비로 저장하는 로직이 필요하다.
// 현재는 로깅하도록 하자
for (String s : names.keySet()) {
log.info("영화 이름 :" + s + ", 호출 횟수 :" + names.get(s));
}
// AnnotationBasedAOP.map.clear();
return RepeatStatus.FINISHED;
});
}
@Bean
public Step simpleStep2(JobRepository jobRepository, Tasklet testTasklet, PlatformTransactionManager platformTransactionManager){
return new StepBuilder("simpleStep2", jobRepository)
.tasklet(testTasklet2(), platformTransactionManager).build();
}
@Bean
public Tasklet testTasklet2(){
return ((contribution, chunkContext) -> {
AnnotationBasedAOP.map.clear();
// 클리어 해주기
return RepeatStatus.FINISHED;
});
}
}위와 같은 형태.
