결합(복합) 인덱스(Composite Index)
1. 인덱스?
특정 테이블의 특정 컬럼에서, 조건절에 의한 조회(where id=?와 같은)를 더 빠르게 만들어주는 녀석. 독자적인 공간을 차지하므로 모든 컬럼에 인덱스를 걸면 오히려 성능이 저하되며, 카디널리티가 높은(중복도가 낮은) 컬럼에 대해서 인덱스를 설정하면 조회 속도에서의 이점을 가진다.
인덱스가 적용이 안되는 경우 - 내용 출처 블로그
1. where 조건절의 컬럼에 추가적인 가공이 들어가는 경우
SELECT * FROM TABLE T WHERE T.AGE + 10 = 30 // 인덱스 X- 인덱스를 활용하지 않고 해당 계산을 모든 행에 대해 수행한 후 결과를 비교해야 한다.
2. where 조건절에 null 과 관련된 조건이 존재하는 경우
SELECT * FROM TABLE T WHERE T.AGE IS NULL
SELECT * FROM TABLE T WHERE T.AGE IS NOT NULL- null 값이 데이터의 일부가 아니기 때문에 인덱스를 구성하는 데 제한이 있기 때문.
3. where 조건절에 != 연산자를 사용하는 경우
SELECT * FROM TABLE T WHERE T.AGE != 30- 인덱스는 동등한 값을 찾는데 최적화되어 있으며, != 연산자는 불일치하는 값을 찾는 작업이므로
- 일반적으로 인덱스를 사용하지 않지만, 찾으려는 데이터의 비율이(테이블 전체에 비해) 낮으면 인덱스를 사용할 "수도" 있음
4. where 조건절에 LIKE 연산자를 사용하는 경우
SELECT * FROM TABLE T WHERE T.NAME LIKE '%abc' // 인덱스 X
SELECT * FROM TABLE T WHERE T.NAME LIKE 'abc%' // 인덱스 O- B+ 트리 인덱스는 데이터의 접두사를 이용해 데이터를 정렬하는데, 와일드카드가 앞에 오면 정렬된 순서를 활용하기 어려워지기 때문
5. IN 연산자로 걸러진 데이터/테이블 비율이 높은 경우
// 예를 들어, AGE 컬럼의 데이터가 1,2,3,4,5 라고 하자.
SELECT * FROM TABLE T WHERE T.AGE IN (1,2,3,4,5)- IN 연산자로 걸러진 데이터가 많으면서 데이터의 분포가 균일하지 않다면, 데이터베이스 시스템은 인덱스를 사용하기보다는 전체 테이블을 스캔한다.
6. 복합 인덱스에서 설정된 컬럼의 순서를 지키지 않은 경우
// 예를 들어, 복합 인덱스 순서가 name -> age 인경우
SELECT * FROM TABLE T WHERE T.AGE = 30 AND T.NAME = '춘식이' // idx X
SELECT * FROM TABLE T WHERE T.NAME = '춘식이' AND T.AGE = 30 // idx O2. B+ Tree?
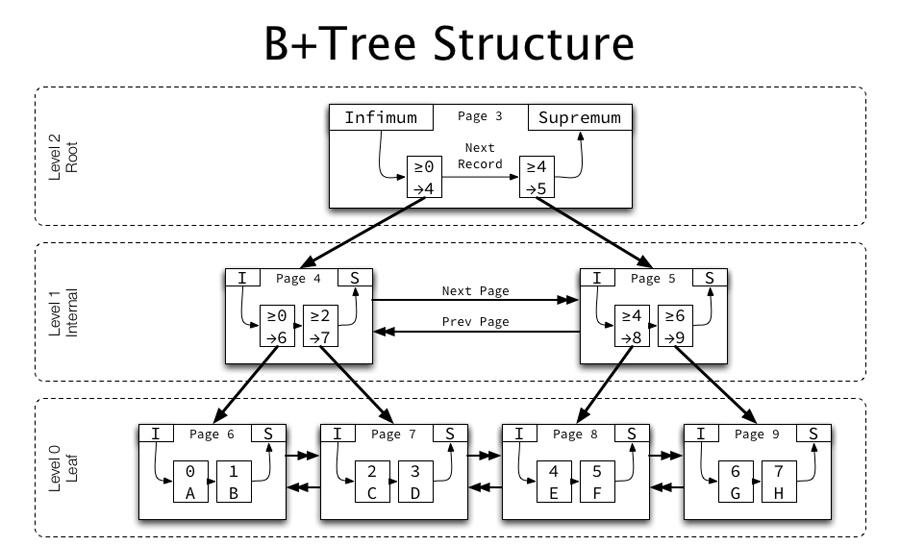
코딩애플의 인덱스 설명 및 B+Tree 소개 (링크)
-
위 그림과 설명에 나와 있는 대로, B+ Tree 는 논리적인 트리 구조를 사용하며
-
조건절에서는 더블 링크드 리스트
(값(==키)에 대한 링크드 리스트와, 그 값을 가지고 있는 페이지(==포인터)에 대한 링크드 리스트) -
리프 노드(맨 아래에 깔려있는 Level 0 Leaf) 에서는 싱글 링크드 리스트를 사용해서 값들을 선형으로 보관한다.
-
즉, 리프 노드에는 실제적 데이터가 존재 하고, 그 외 나머지 노드들에서는 리프 노드에 있는 실제 값을 찾아 갈 수 있게 해주는 논리적 데이터 가 존재한다.
-
인덱스는 일반적으로 B+ Tree 구조를 사용해서 데이터를 탐색한다
3. Composite Index?
여러 개의 컬럼을 순서대로 인덱스화 시켜서, 단일 컬럼으로써는 카디널리티가 높지 않던 컬럼들이 결합하여 인덱스로써 활용 될 수 있다.
즉,
단일 컬럼 에서의 인덱스는 카디널리티가 충분히 높아야 사용이 "가능"하고,
결합 인덱스의 장점은 카디널리티가 높지 않은 컬럼들을 묶어서 카디널리티가 높은 것처럼 활용하여, 인덱싱 가능하다는 것이다.
그리고
결합 인덱스에서는 인덱스의 각 컬럼이 정렬되어 있으며, 이 정렬된 순서대로 데이터를 검색한다.
결합 인덱스의 생성
SQL
CREATE INDEX idx ON table_name (column_A, column_B);SpringBoot
@Entity
@Table(name = "table_name")
@Indexes({
@Index(name = "idx_compound", columnList = "column_A, column_B")
})
public class Entity {
// ...
}결합 인덱스 생성 시 주의사항
출처 : 개발자를 위한 인덱스 생성과 SQL 작성 노하우(이병국), 참고 블로그
1. 공통적으로 사용하는 필수 조건절 컬럼을 우선한다.
선행 컬럼은, 조건절로 쓰일 컬럼을 우선한다.
2. '=' 조건의 컬럼을 다른 연산자 컬럼보다 우선한다.
결합 인덱스의 컬럼 순서가
1 -> 2 -> 3 -> 4 -> 5 라면
WHERE 컬럼1 = ?
AND 컬럼2 = ?
AND 컬럼3 BETWEEN ? AND ? -- 결합인덱스에서 '='이 아닌 연산자를 사용하는 첫 번째
AND 컬럼4 = ?
AND 컬럼5 = ?-
위와 같은 쿼리를 예로 들면
-
컬럼 1, 2, BETWEEN 연산자가 등장하는 컬럼까지는 인덱스가 활용되지만
결합 인덱스에서는 인덱스의 각 컬럼이 정렬되어 있으며, 정렬된 순서대로 데이터를 검색하므로
- BETWEEN 연산자 이후의 컬럼(연산)은 이미 BETWEEN 연산에 의해 검색 범위가 좁혀진 결과 집합을 대상으로 추가적인 필터링을 하는 역할만을 수행 (정렬된 구조를 활용하여 검색 범위를 좁히는 것이 아닌, 이미 좁힌 결과에 대한 추가적인 필터링을 수행)
따라서,
결합 인덱스의 컬럼 순서를
1 -> 2 -> 4 -> 5 -> 3 으로 재정의 하는 것이 더 유리할 것.
3. 카디널리티 높은 컬럼 우선
- 그렇게까지 우선되는 사항은 아니다.

글 재미있게 봤습니다.