개요
휘몰아쳤던 무수한 강의들과 알고리즘에 치여 한동안 블로그 작성을 못했는데, 그동안 배웠던 것 들 중에 새로 알게 된 것들이나 기억하고 싶은 것들을 올립니다.
1. 페치 조인
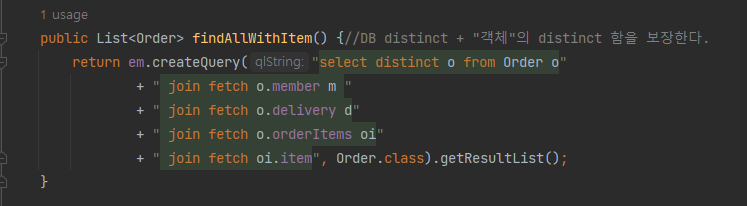
-
쿼리를 통해 사용되며 기본적으로 ~~~ToOne의 패치타입을 LAZY로 해놓는데, 이렇게 되면 엔티티를 불러 올 때 해당 엔티티에서 참조하는 다대일 관계의 객체의 값이 null이 됩니다.
-
패치 타입을 EAGER로 바꾸는 경우는 너무 비효율적입니다.
-
이 때 위와 같이 join fetch JPQL 쿼리를 이용해서 조인해주면 연관관계로 맵핑된 엔티티들의 정보까지 불러 올 수 있습니다.
-
더하여, OneToMany의 형태(혹은 ManyToMany) 로 연결되어있는 컬렉션 타입의 객체를 불러 올 때는 쿼리는 하나로 나가지만 결과값이 N번 출력됩니다(OneToMany로 연결되어있는 부모객체 N개만큼)
-
hibernate.default_batch_fetch_size 를 이용해서 배치 사이즈를 최적화 합니다.
단점으로는 페이징이 불가하며(N+1문제가 있으므로 정상작동X), 쿼리가 하나로 나가지만 양이 많습니다.
2. OneToMany를 사용한 두 번 이상의 연관관계
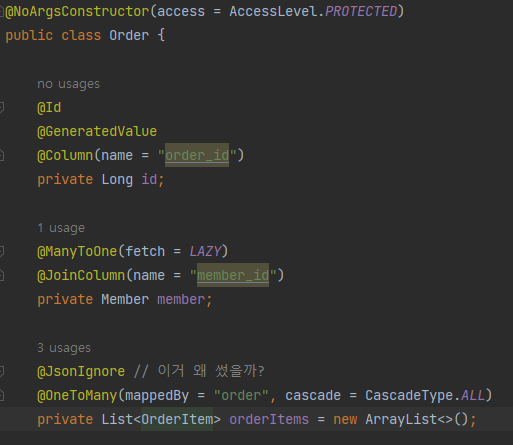
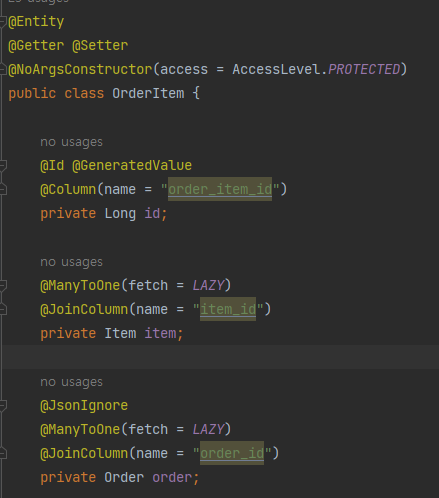
위와같이 Order, OrderItem, Item이 관계를 맺고 있습니다.
조회가 일어날때는 Order를 조회 했을 시 Item의 정보까지 필요하므로, 이에 대한 처리를 해줘야 합니다. 이는 아래와 같습니다.
public List<OrderQueryDto> findAllByDto_optimization() {
List<OrderQueryDto> orders = findOrders();
// orders 한번에 조회(쿼리발생)
List<Long> orderIds = toOrderIds(orders);
// in 절 사용하기 위해서 orders.stream.map 으로 order 각각의 id 뽑아서 List화
Map<Long, List<OrderItemQueryDto>> mappedOrderItems = findMappedOrderItem(orderIds);
// 성능 최적화 부분 OrderItemQueryDto 를 map으로 처리함. (for 문 해도 됨)
orders.forEach(o -> o.setOrderItems(mappedOrderItems.get(o.getOrderId())));
// orders 가 가지고 있는 OrderItemList 를 셋해주는 매서드.
return orders;
}
private Map<Long, List<OrderItemQueryDto>> findMappedOrderItem(List<Long> orderIds) {
List<OrderItemQueryDto> orderItems =
em.createQuery("select new jpabook.jpashop.repository.order.query.OrderItemQueryDto(oi.order.id, i.name, oi.orderPrice, oi.count)" +
"from OrderItem oi" + " join oi.item i" +
" where oi.order.id in :orderIds"
, OrderItemQueryDto.class)
.setParameter("orderIds", orderIds).getResultList();
return orderItems.stream().collect(Collectors.groupingBy(OrderItemQueryDto::getOrderId));
}위 주석에서 설명한 대로 두 번의 쿼리가 발생합니다.
여기서 중요한 것은, 첫 번째 조회 쿼리로 받아온 orders 의 아이디를 맵으로 받아오는 부분입니다.
이 값을 JPQL의 in 조건절로 사용 할 수 있습니다.
아이디가 아니어도 어떤 값이든 in 조건절로 사용하기 위해 가져올 수 있다는 아이디어가 중요합니다.
