intro
분산학습의 본격적인 학습 전에 간단하게 알아두면 좋을 내용들입니다.
Sharding Primitives
분산 프레임 워크의 토대가 되는 것들에 대한 내용입니다.
- DTensor : 공유/분산 되는 텐서 데이터타입닙니다.
- Device Mesh : Accelerator device communicator를 가속기 장치의 통신기를 다차원 배열로 추상화하여 다차원 병렬처리에서 통신에 사용되는
ProcessGroup의 인스턴스를 관리합니다.
어떤 경우에 어떤 병렬처리 방법론을 선택해야 하는가?
-
DDP를 사용할 때
모델의 크기가 하나의 GPU에 들어갈 수 있고 여러 개의 지피유에 병렬학습을 시키고자 할 때,
-
FSDP를 사용할 때
모델이 하나의 GPU에 들어갈 수 없을 때
-
Tensor Parrellel / Pipeline Parallel 을 사용할 때
FSDP를 사용할 때 scaling 한계에 다다를 때
DDP란?
- DistributedDataParellel의 약자
- 옛날에는 Data Parellel이란 기법도 있었는데, 현재는 약간 레거시화 되어있는 것 같음.
학습 과정 요약
여러 개의 GPU에 프로세스가 스폰되고 하나의 모델이 각 프로세스에 복사되어 들어가게 됨.
- 각 프로세스에 배당되는 데이터는
DistributedSampler라는 모듈을 통해 각 데이터의 배치가 겹치지 않게 샘플링 되어 각 프로세스에 있는 모델로 할 당 됨. - 이 때 accumulation과정에서 서로 다른 파라미터 값이 생기게 되면서 하나의 모델이 ’분산 학습’을 진행한 상황이 아니라 여러 개의 서로 다른 모델이 생기게 된 것이 됨.
- 해당 상황을 타파하고자 모든 기울기들을 합산할 수 있는 Ring_AllReduce라는 기법이 사용됨.
- 동기화 과정에 모든 기울기가 계산 되는 걸 기다리는 대신 모델이 연결된 가상의 Ring을 따라서 역전파 과정 중에 상호작용을 통해 각 모델의 복사본이 같은 기울기를 겪게 된다.
분산 학습 시의 통신 패턴
- DDP를 논할 때 통신과정이 포함되어 있음을 항상 염두에 두어야 한다. 싱글 노드의 각 여러 대의 GPU를 통해 학습을 하는 경우와 , multinode의 GPU를 활용해 학습을 하는 경우 모두, data와 파라미터 모두 통신과정을 거쳐 공유된다.
- 분산학습 시에는 각 GPU를 담당하는 프로세스들이 스폰되고 해당 프로세스를 묶는 프로세스 그룹이 생성됨. 해당 프로세스 그룹끼리 서로 통신하고 데이터를 주고 받기 때문에, 프로세스 그룹을 초기화하여 그룹을 생성해주어야 한다.
Point to Point to Communication
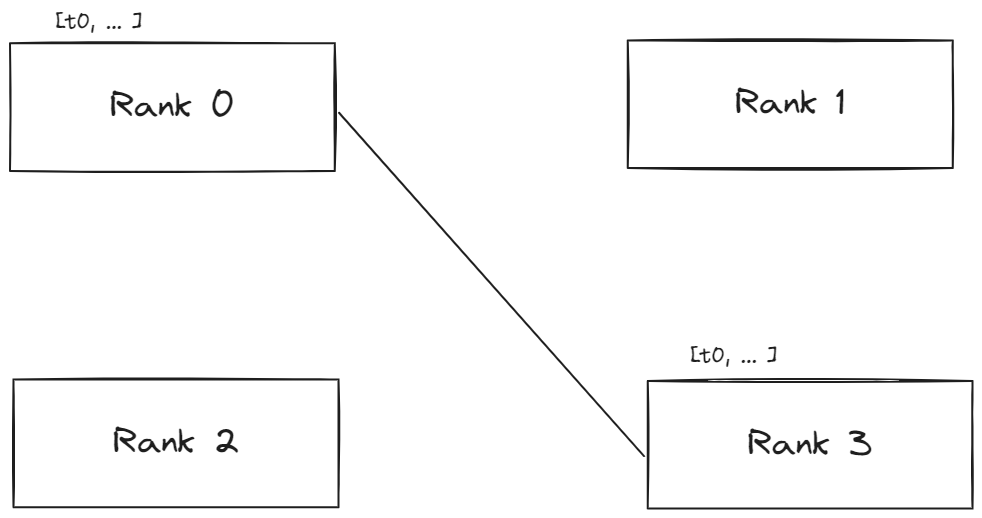
하나의 프로세스와 다른 하나의 프로세스가 직접 통신하는 경우이다. 좀 더 세밀하게 프로세스들을 제어해야 하는 상황에서 사용하기 좋은 방안이다.
메소드로는 send recv isend irecv 등이 있다.
send recv 는 동기 처리 방식에 가깝다. 두 개의 프로세스의 통신이 종료될 때까지 block로 인해 대기하게 된다.
isend irecv 는 반면에 비동기 처리 방식에 가깝다. 두 개의 프로세스가 통신할 동안 다른 스크립트들이 실행된다. 다만 사용시에 주의 사항이 있다. 프로세스끼리 소통하는 정확한 타이밍을 모르기 때문에, wait 이 호출되기 전에 전송될 텐서를 수정하거나, 전송받을 텐서에 접근하려고 하면 안 된다.
isend:wait이전에 텐서를 수정하려고 하면 안 된다.irecv:wait이전에 텐서를 읽으려고 하면 안 된다.
wait 은 통신이 이루어졌음을 보장하기 때문에 , wait 이후에는 상관없다.
Collective Communication
- point to point 통신 방식과는 다르게 프로레스 그룹 내의 모든 프로세스들이 통신 패턴에 맞추어 통신할 수 있게 함.
- 모든 프로세스가 있는 그룹인
world에 collective 패턴이 동작함.
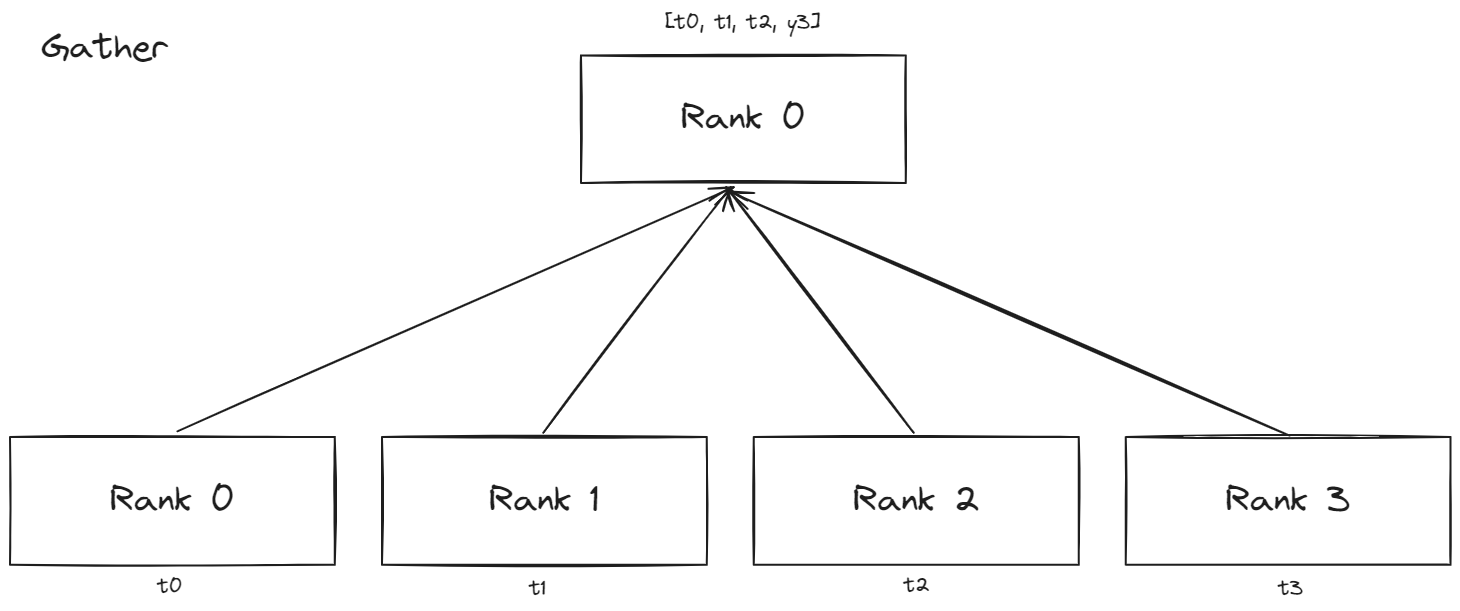
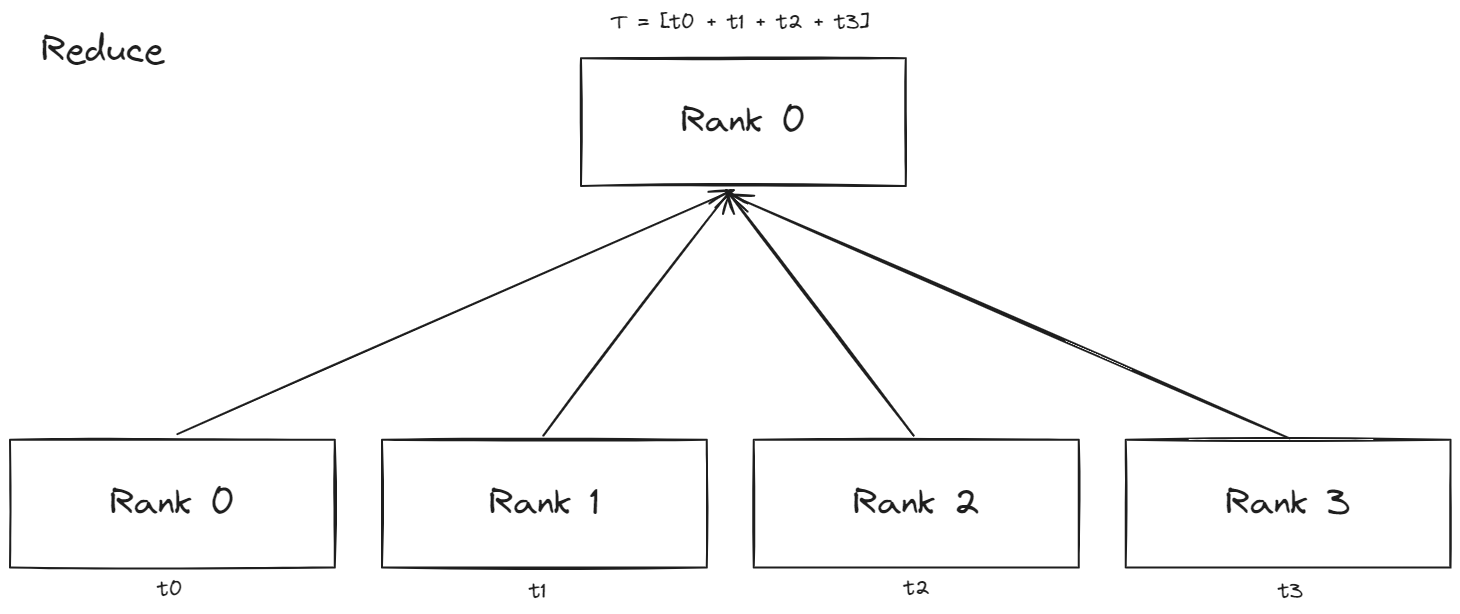
Collective Patterns
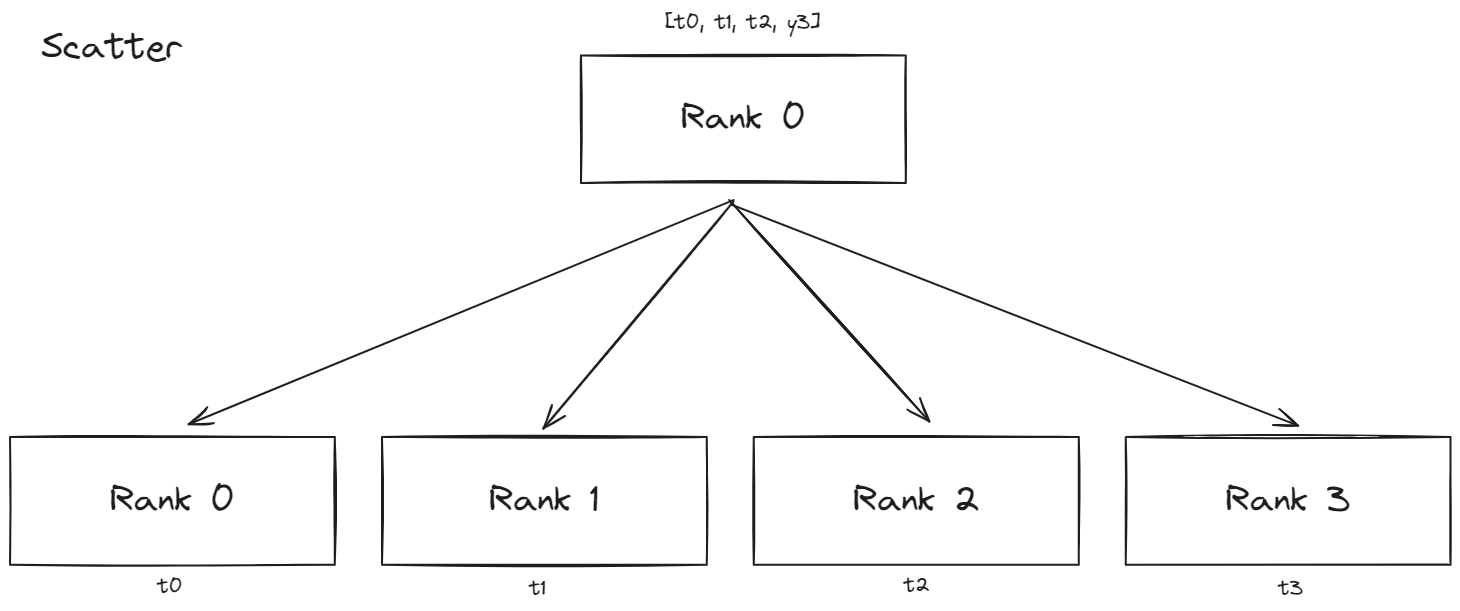
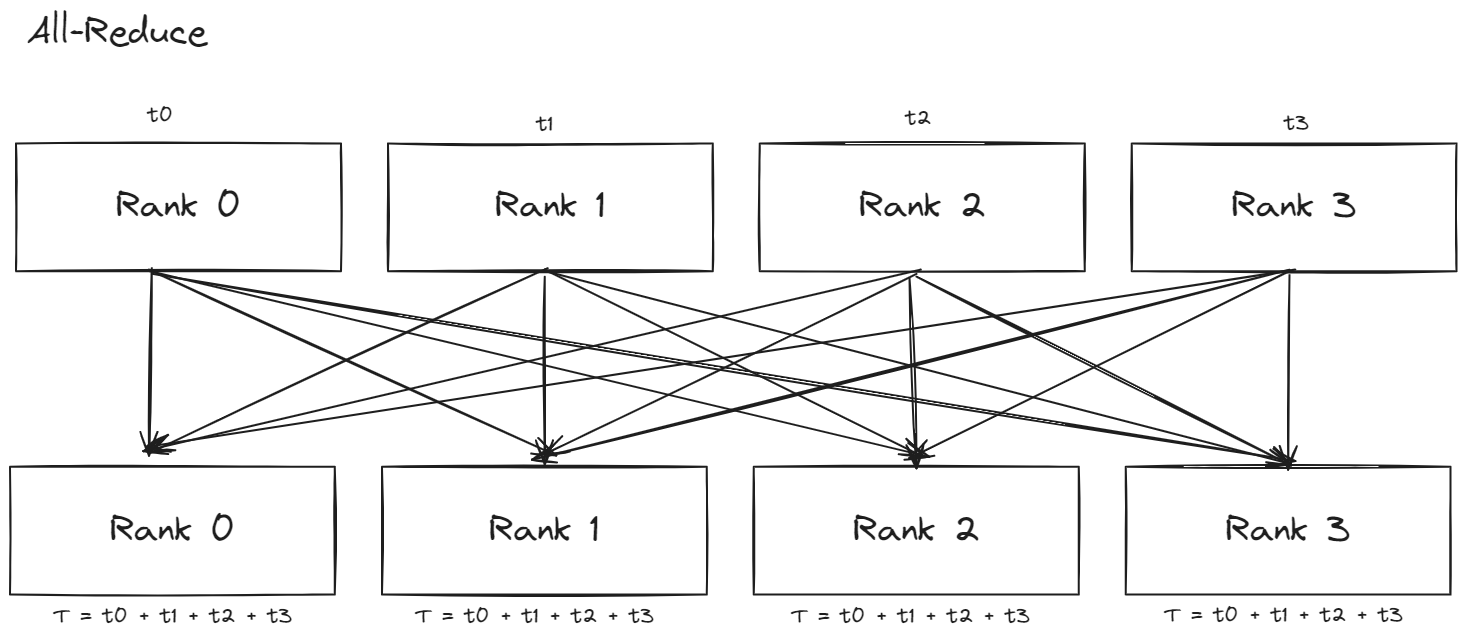
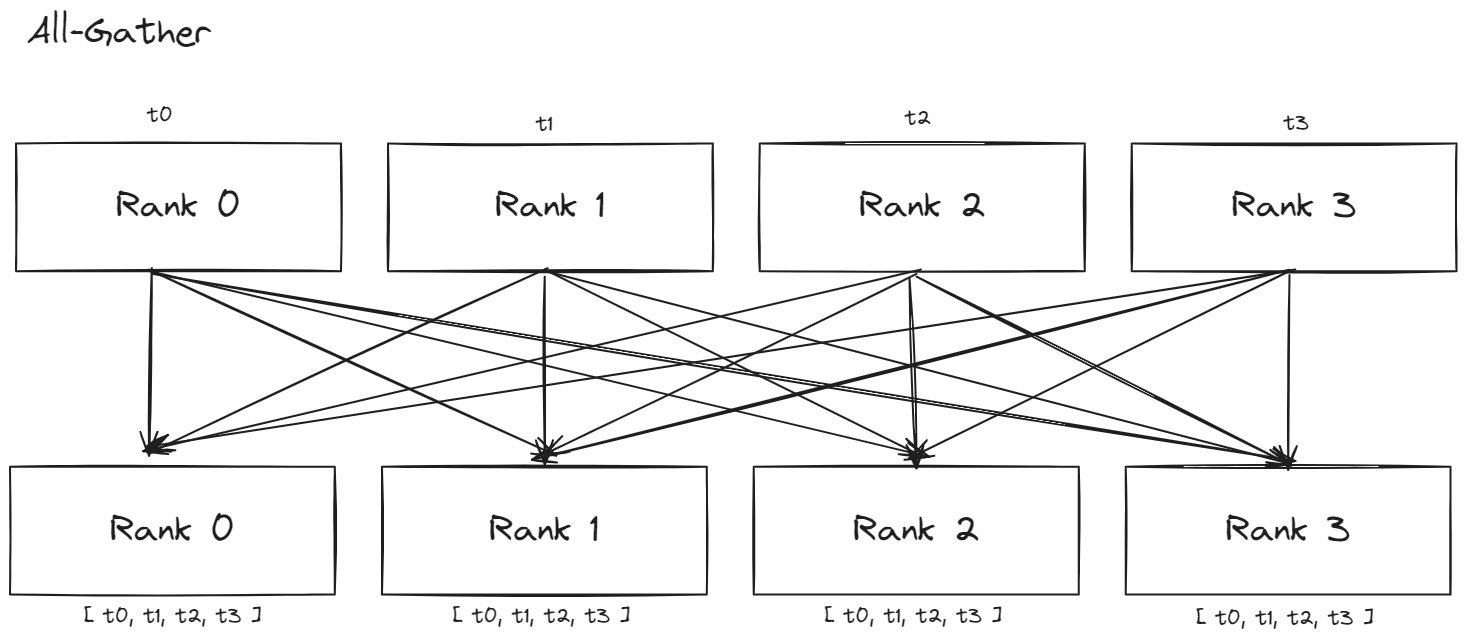
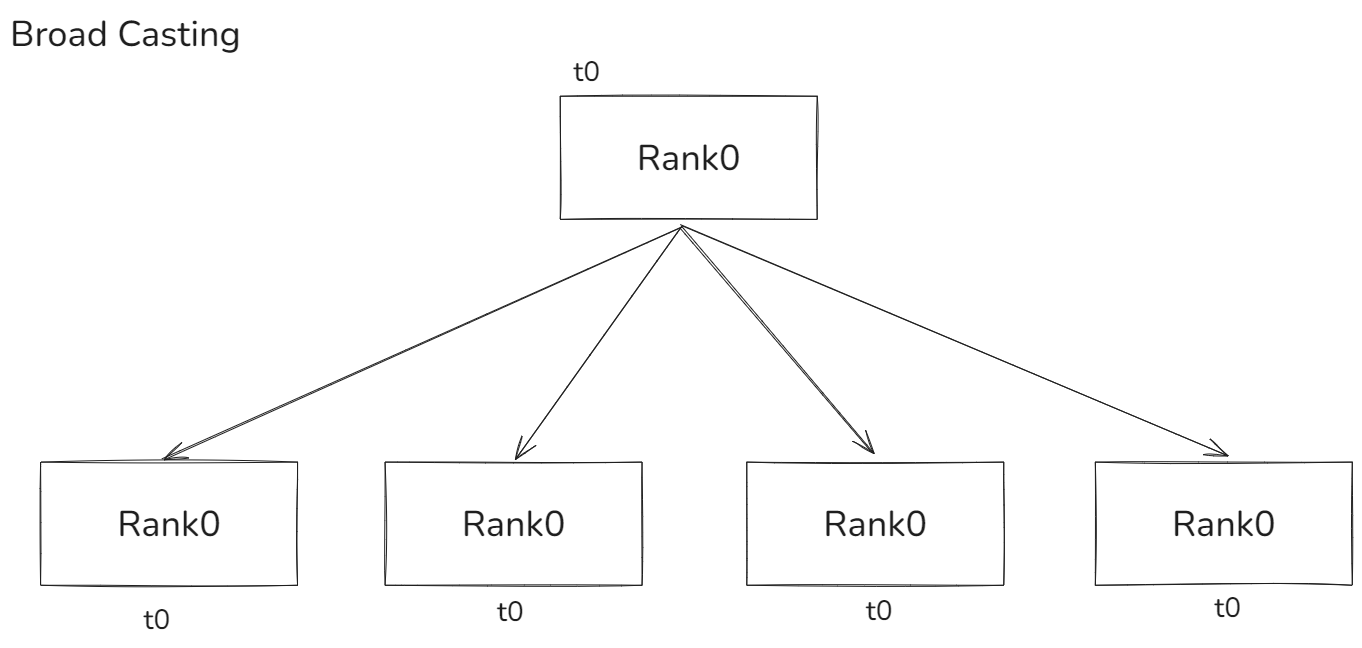
- Scatter : 해당 패턴은 각 텐서를 분할 후에 각 프로세스에 하나씩 할당하는 패턴이다.
- Gather : 각 프로세스에 있는 텐서를 하나의 프로세스에 모으는 패턴이다.
- Reduce : 각 프로세스에 있는 텐서를 연산을 거친 후에 하나의 프로세스에 모으는 패턴이다.
- BroadCast : 네트워크의 BroadCast와 똑같은 과정이다. 각 프로세스에 똑같은 텐서를 전파하는 것이다.
- All-Reduce : reduce동작이 모든 프로세스에서 이루어지는 것이다.
- All-Gather : gather 동작이 모든 프로세스에서 이루어지는 것이다.
Reduction에 사용되는 연산 같은 경우 torch.distributed 에 정의된 4개의 연산이 존재한다.
- torch.distributed.ReduceOp.SUM
- torch.distributed.ReduceOp.PRODUCT
- torch.distributed.ReduceOp.MIN
- torch.distributed.ReduceOp.MAX
torch.distributed 에 정의된 메소드들은 아래와 같다.
dist.broadcast(tensor, src, group)dist.reduce(tensor, dst, op, group)dist.all_reduce(tensor, op, group)dist.gather(tensor, gather_list, dst, group)dist.scatter(tensor, scatter_list, src, group)dist.all_gather(tensor_list, tensor, group)dist.barrier(group)- 그룹 안의 모든 프로세스들이 이 함수에 진입하기 전까지 block하는 역할을 수행한다.
Communication Backends
각 gpu 프로세스들이 통신하기 위한 backend들에 대한 것입니다. 각 backend들은 사용례에 따라 장점과 단점이 있습니다.
- GLOO
- 장점
- 개발 플랫폼으로 사용하기 편리
- torch binary에 컴파일되어 편입되어 있기 때문에 추가적인 설치는 불필요함.
- 단점
- 다만, NCCL 보다 cuda tensor 에 최적화 되어있지 않음.
- 장점
- MPI (Messgae Pass Interface)
- 장점
- 고성능 연산에 표준화 된 툴이다.
- point to point, collectives 모두 지원.
- 특정 사용 목적에 맞추어 최적화된 특정 버전의 MPI가 존재한다.
- 커다란 클러스터에서 사용하게 될 때 가용성이 매우 높고 최적화가 잘 되어 있다.
- cuda 와 gpu에 바로 데이터를 쓰는 기술 등을 지원
- 단점
- torch binary에 컴파일 되어 있지 않기 때문에 별도의 설치 후 컴파일 하여 사용해야 한다.
- 장점
- NCCL
- 장점
- CUDA 텐서에 대한 GPU의 collective 연산을 지원한다.
- 만약 모든 연산이 CUDA 텐서에 관한 연산일 경우 매우 높은 성능을 자랑한다.
- torch에 편입되어 있다.
- 장점
Initialization Methods
위의 한 번 작성하였다시피, 분산학습이 가능하기 위해서는 각 GPU를 담당하는 프로세스들을 그루핑하는 방식을 초기화해야 한다. 이 때, 각각 클러스터에 맞는 적절한 방식을 선택하여 사용하면 된다.
- 환경변수
- 각 머신에 아래의 4개의 환경변수들을 지정함으로써 모든 머신에서 master에 접근 가능하다.
MASTER_PORT: 비어있는 포트고 마스터가 점유할 포트이다. 해당 프로세스의 rank는 0번으로 지정된다.MASTER_ADDR: 마스터의 IP 주소WORLD_SIZE: 사용할 프로세스의 개수RANK: 각 프로세스의 랭크. 이 정보를 통해 각 프로세스가 마스터인지 아닌지 판별 가능
- Shared File System
- Shared File System의 경우 모든 프로세스가 해당 파일 시스템에 접근할 수 있어야 한다.
- 각각의 프로세스가 파일을 읽고 쓰고 다른 스로세스가 모든 동작을 끝낼 때가지 대기하는 locking이 필수적이다. 이는 Race Condition 상황을 피하기 위해서 필수적이다.
- TCP
- TCP 통신을 통해서도 초기화가 가능하다. host 주소와 port만을 제공하면 된다.
Appendix(?)
Internal Design
내부의 디자인은 각 모듈의 상속과 구성 관계를 설명해주고 있다. 작동 방식을 설명한 내용이다.
prerequists
DDP는 GPU마다 하나 씩 프로세스가 점유하고 각 프로세스가 통신하여 정보를 교환한다고 하였다. 이 떄 해당 프로세스의 그룹을 만들어주는 프로세스 그룹의 인스턴스를 우선적으로 생성해야 한다.
Construction
- 생성자가 로커 모듈을 참조 후 모든 프로세스에 state_dict에 대한 브로드캐스팅을 진행. 각 프로세스는 모두 같은 초기값을 지니게 된다. 즉, Rank 0에서부터 Rank i 번까지 같은 상태를 지니게 된다.
- 각 프로세스는 로컬 ‘Reducer’를 생성한다. Reducer는 기울기의 동기화를 담당하는 역할을 하게 된다. 이때, 통신의 효율성을 위해 파라미터를 버켓에 담게 되고 한 번에 하나 씩 reducing 작업을 진행하게 된다.
- 모델의 파라미터는 버켓에 들어가게 될 때 거꾸로 정렬되어 들어가게 된다. 이유는 역전파 시에 연산을 진행할 때 그 순서로 이루어지기 때문이다.
- ‘Reducer’는 생성 작업 시에, 버켓팅만 하는 것이 아니라 각 파라미터에 hook을 걸어준다. ‘hook’이란 엮여있는 파라미터가 준비가 되었고 역전파가 시작했을 때 촉발되는 예정된 동작을 의미한다 .
ForwardPass
find_unused_parameters: True일 경우, 모델의 서브그래프에서 backward로 진행한다 그리고 모델의 아웃풋 결과에서부터 역전파 시에 사용되는 모든 파라미터를 검사하면서, 사용되지 않은 파라미터들을 역전파 시에 ‘reduction’ 작업에 사용될 수 있도록 ‘준비 됨’ 마킹 처리를 한다.- ‘Reducer’는 버켓에 있는 파라미터가 준비가 되지 않을 경우 대기하지만, 여전히 reducing 작업은 진행할 것이다. 이 작업은 DDP가 해당 버킷을 건너 뛰도록 만들진 않지만, 역전파 시에 비어있는 기울기를 무한정 대기하는 것은 막아줄 것이다.
- 해당 작업은 연산의 부하가 심하므로, 필요할 때만 설정해야 한다.
BackwardPass
- backward 함수는 loss_tensor 가 호출될 때 바로 자동으로 호출된다.
- DDP는 생성 시에 등록된 hook을 사용하여 기울기들끼리 동기화 할 수 있도록 한다.
- gradient가 준비되면 그에 해당하는 DDP hook이 작동한다. 그 이후에 reduction 작업이 준비가 되었다고 마킹한다.
- 하나의 버켓에 있는 gradient가 준비되면 각 프로세스에 있는 ‘Reducer’가 비동기적인 allreduce작업을 실행한다. 이 작업은 모든 gradient를 평균내는 작업이다.
- 위의 reduction작업이 종료되게 되면, ‘param.grad’ 의 값에는 같은 값이 각각 쓰여지게 된다. 따라서, 역전파가 종료된 이후의 시점에서는 같은 위치의 파라미터의 gradient는 모두 같아지게 된다.
Optimizer Step
- 옵티마이저의 관점에선 로컬 모델을 옵티마이징하는 것과 같다.
- 이 과정에서 동기화를 하는 것은 추가적인 작업이 불필요한데 이는 각 프로세스의 파라미터의 초기값이 같고 모든 gradient들이 동일하기 때문이다.
Ring_Allreduce
각기 흩어져 있는 프로세스의 데이터를 한군데로 합치는 과정의 연산은 분산 학습에서 필수적인 과정이다. 위의 이러한 collectives 연산 과정에서 allreduce가 사용되곤 했지만, 필수적으로 all-reduce과정의 연산은 master 프로세스의 과도한 부담을 안겨 주므로 이를 보완하고자 ring-allreduce가 제안되었다.
Allreduce
여러 개의 배열들에 reduction 연산을 수행한 후 하나의 배열로 만들어 그 결과를 모든 프로세스에 전달한다. 이 때 가장 간단한 연산 방식을 떠올려보자면, 하나의 프로세스를 마스터로 만든 후 모든 프로세스에서 데이터를 수집하고 해당 연산을 수행한 후 데이터를 다시 모든 프로세스로 분배하는 방안이 있을 것이다.
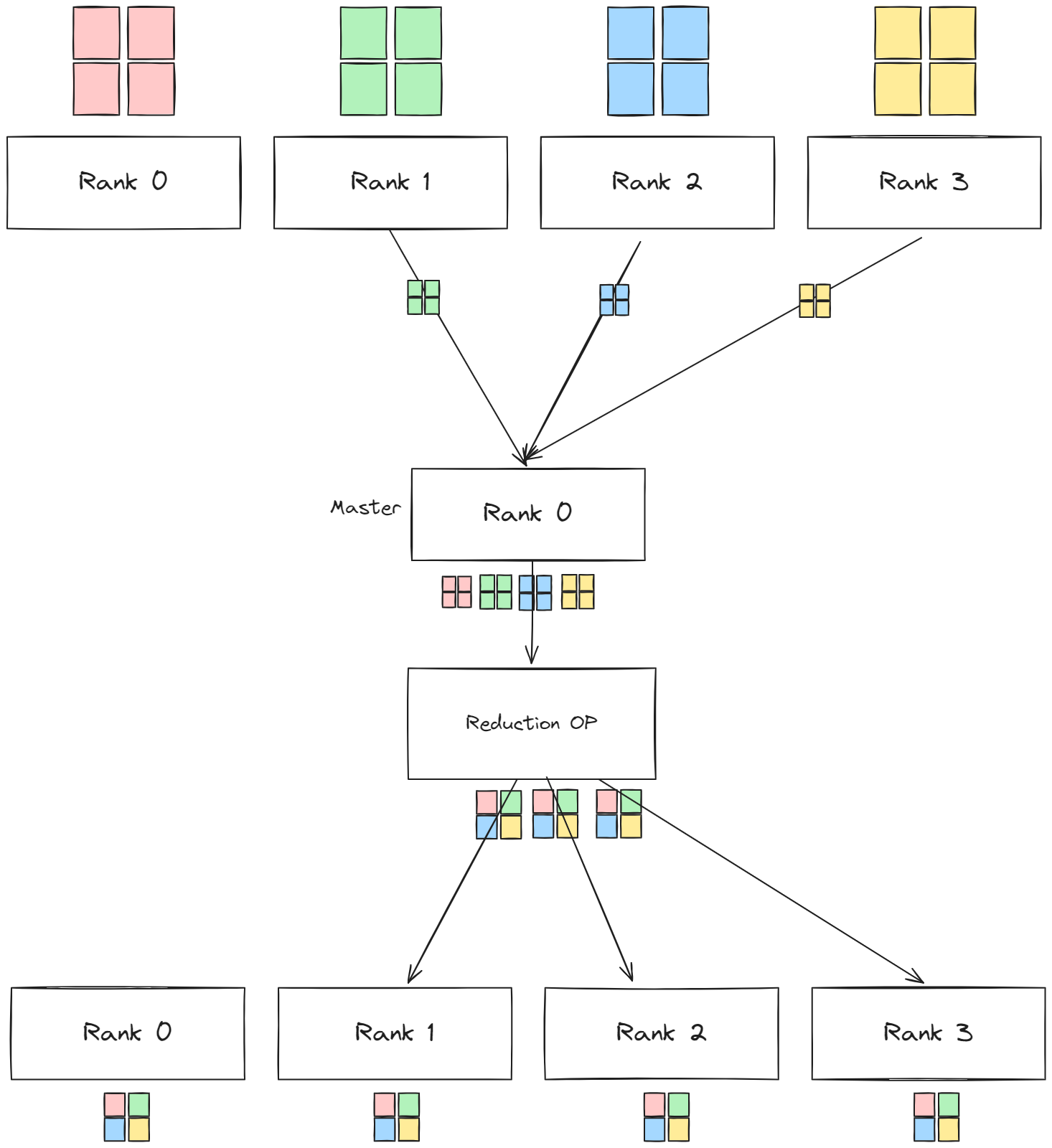
이 경우에는 필수적으로 모든 연산을 master가 담당하므로 master의 연산에 병목현상이 생길 수 밖에 없고 프로세스의 수가 늘어난만큼 master의 연산의 부담도 증가할 것이다.
Ring-Allreduce
ring-allreduce는 allreduce의 이러한 단점을 보완하고자 만들어진 패턴이며, 동시에 모든 프로세스가 reduction 연산에 참여하기 때문에, 연산의 병목현상을 대체할 수 있다. 핵심적인 동작 방식은 다음과 같다.
P를 각 프로세스의 개수라고 할때 rank p는 (0≤ p ≤ P -1 )이다.
- 각 프로세스에 있는 배열을 P만큼의 청크로 나눔
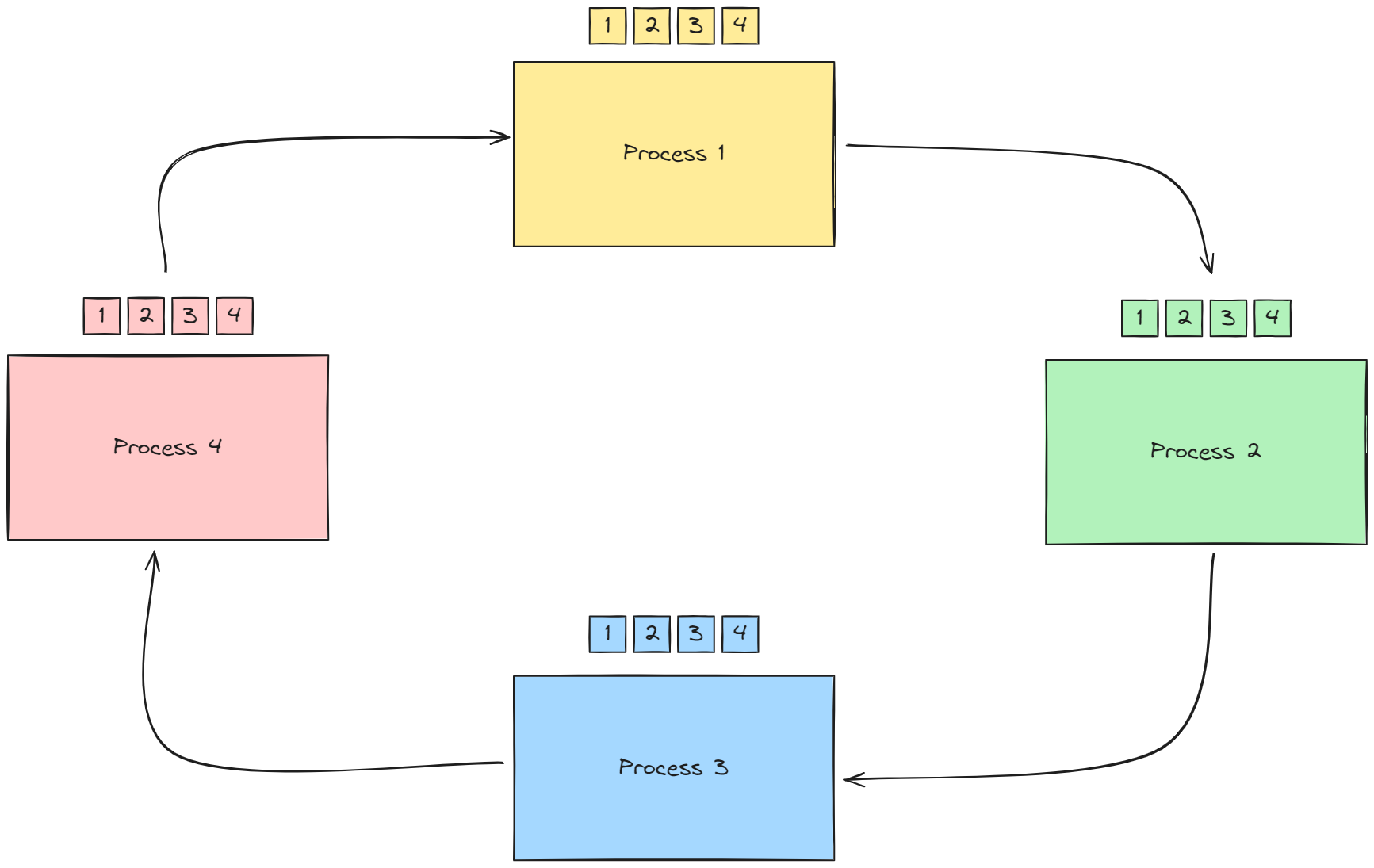
- 프로세스의 chunk[p]를 로 보냄. 이와 동시에 로부터 chunk[p-1]을 받음
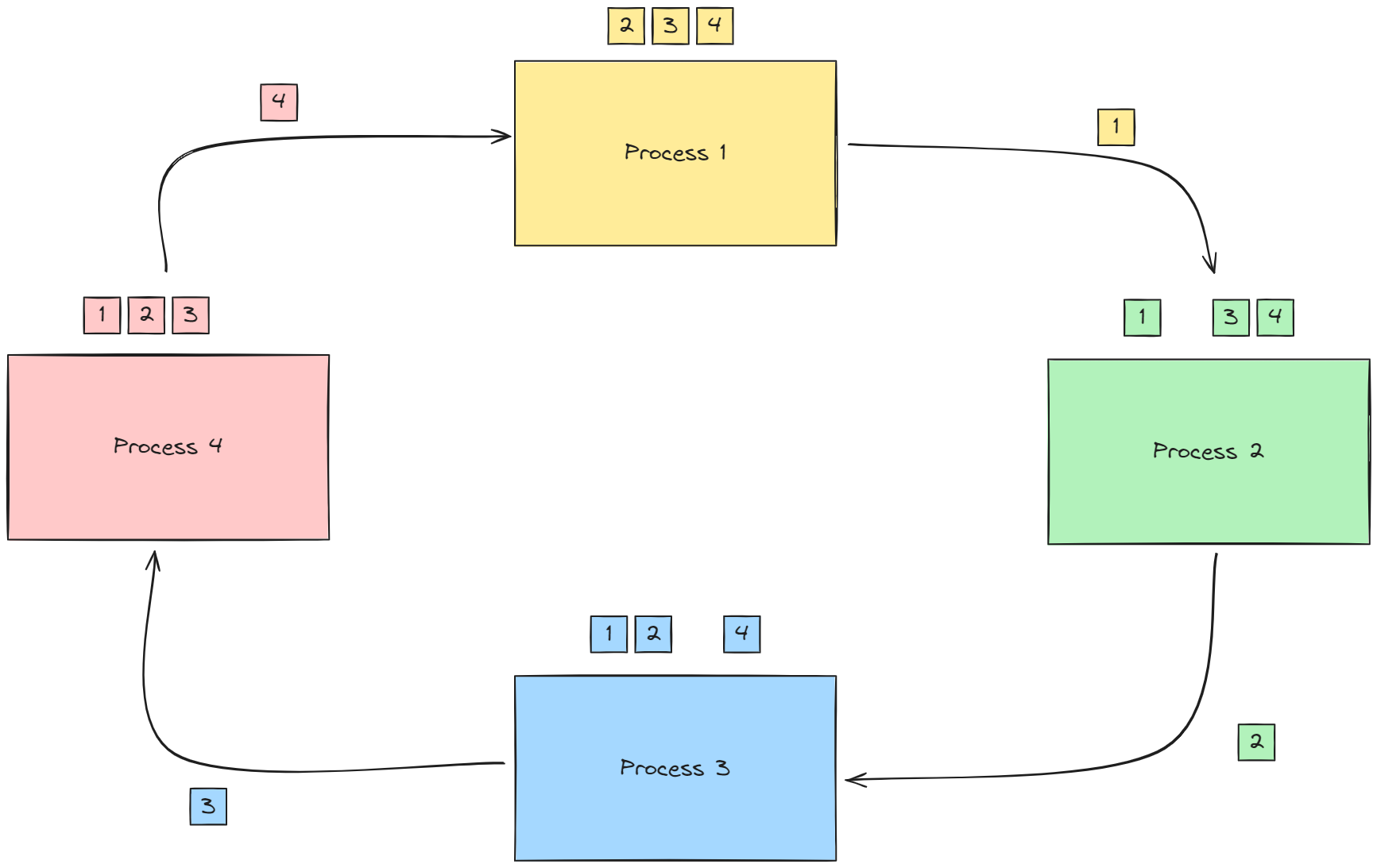
- 의 chunk[p-1] 과 의 chunk[p-1] 끼리 reduction 연산 수행, reduction 연산이 수행된 청크를 다시 로 보냄
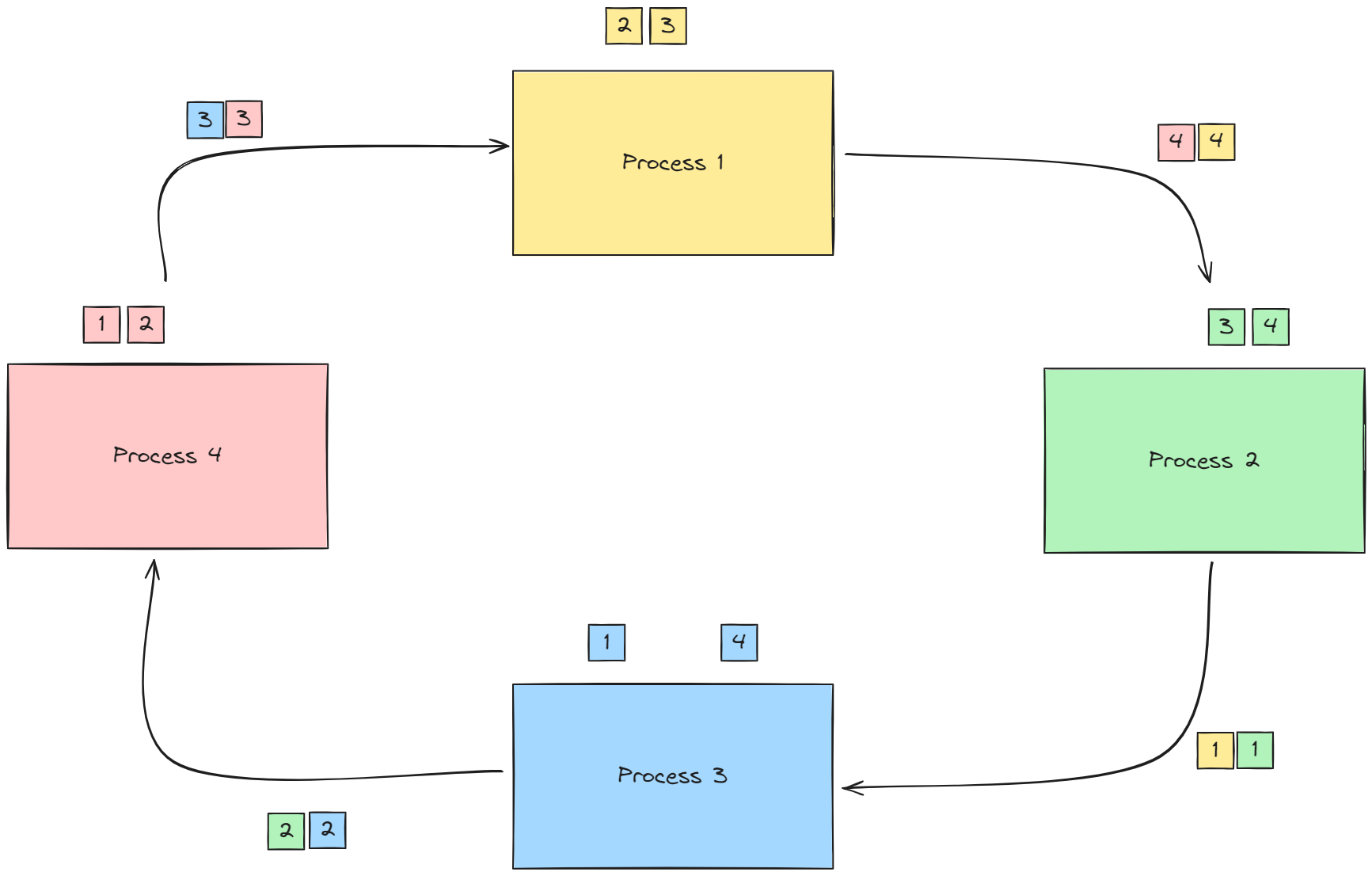
- (2,3,4)의 과정을 각 프로세스가 모든 프로세스의 청크를 소유할 때까지, p-1 번 반복
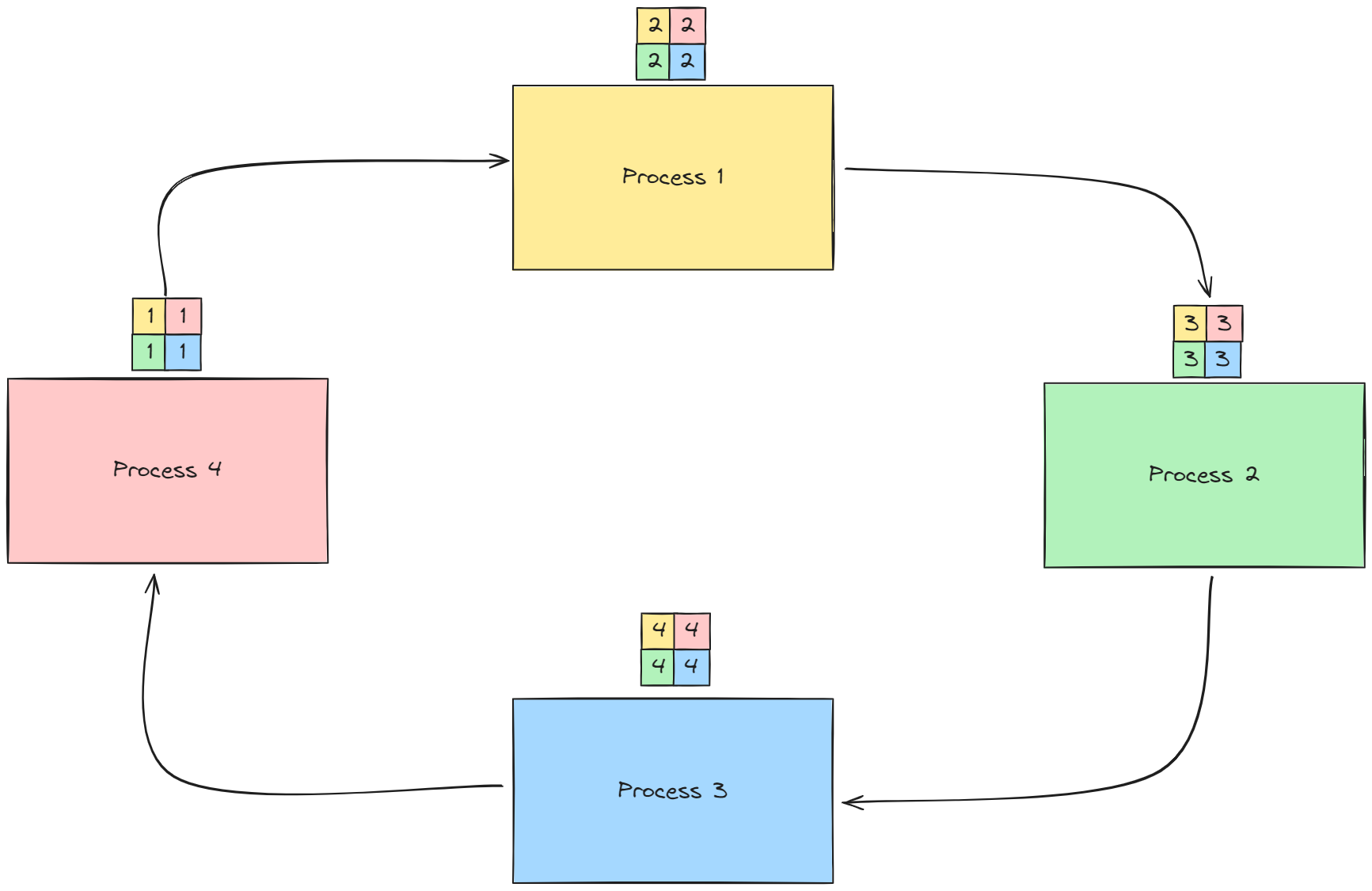
Reference
-
Writing Distributed Applications with PyTorch — PyTorch Tutorials 2.3.0+cu121 documentation
-
What is Distributed Data Parallel (DDP) — PyTorch Tutorials 2.3.0+cu121 documentation
-
PyTorch Distributed Overview — PyTorch Tutorials 2.3.0+cu121 documentation
-
Technologies behind Distributed Deep Learning: AllReduce - Preferred Networks Research & Development
