intro
FSDP는 Fully Sharded Data Parellel의 약자로 DDP의 사촌(?)이다. DDP의 사촌이라한 까닭은 DDP처럼 모델을 관리하는 프로세스 그룹이 스폰되고 통신을 통해 순전파, 역전파, 옵티마이징에서의 parameter와 grad를 동기화하기 때문이다. 그렇다면, DDP 와의 가장 큰 차이점은 무엇이 있을까, 가장 큰 차이점은 두 가지가 있다.
- 각 프로세스(각 GPU를 관리하는)가 모델의 복사본이 아닌 모델의 조각을 갖는다.
- all_reduce를 사용하는 대신 all_reduce를 all_gather과 reduce_scatter로 분할하여 통신의 부담을 줄인다는 점이다.
이제 FSDP의 과정을 살펴보면서 자세히 알아보자.
FSDP
FSDP는 이름에서 알 수 있듯이 DDP와 마찬가지로 Data Parellel의 한 종류이다. 개요에서 설명했듯이 모델의 파라미터, 옵티마이저의 파라미터, 기울기 모두를 각 rank 프로세스에 샤딩한다. 이 방법은 DDP처럼 GPU의 메모리를 많이 사용하지 않기 때문에, 커다란 모델을 사용가능하도록 만들어주고 모델에 들어가는 데이터의 배치 사이즈 역시 키울 수 있다.
대신 메모리가 줄어든 만큼 통신을 자주한다. 다만 이런 통신의 과부하는 내부적인 최적화 방법론을 사용하여 최대한 줄이도록 되어있습니다.
Work Flow
이제는 모델의 생성, 모델의 분할 샤딩 전략, 순전파, 역전파 등을 살펴 보겠습니다.
모델 파티셔닝
- 기존의 Tensor Parellism이나 모델 파티셔닝은 모델의 파라미터를 분할하여, 저장하여 여러 대의 GPU로 모델을 학습 시키는 것이 가능했습니다만, 이 때 gpu끼리 연산의 순서가 정해져 있어야 했고, 여러대의 GPU에서 병렬적으로 동시에 학습하는 것이 불가능 했습니다. 즉 아래의 그림 처럼 모델이 분할 되어 있다고 할 때,
GPU 1 : 연산 → GPU 2 : 연산 → GPU 3 : 연산 → GPU 4: 연산과 같이 이루어져야 했습니다.

- 학습 시에는 조금 비효율적일 수 있지만 모델 파티셔닝의 기법은 인퍼런스 시에는 충분히 효율적으로 사용될 수 있습니다.
모델 샤딩
- FSDP의 핵심 아이디어인 샤딩은 파티셔닝에서 조금 더 나아간 아이디어 입니다. 파티셔닝처럼 각 GPU에서 모델의 파라미터를 분할하여 가지고 있게 됩니다. 하지만, 순차적으로 학습할 때 텐서가 이동하는 대신 각 gpu를 분할받은 프로세스에서 통신을 통해 자신에게 없는 샤드를 불러와 해당 부분의 연산을 진행하는 것이라고 볼 수 있습니다. 즉 한 번의 연산에 하나의 샤드만이 사용되는 방식입니다.
- 즉 일종의 다이나밍 프로그래밍의 인메모리 연산과 비슷하게 연산하고자하는 부분만 메모리에 올린 뒤 결과를 다시 분할하는 것이라고 생각하면 될 것입니다.
- 모델의 파라미터를 샤딩하고 각 랭크는 자신의 조각만을 가지게 된다. 실제로는 Rank 0인 프로세스가 각 프로세스를 스폰한 후에 모델의 조각들을 분배할 것 입니다.
모델 초기화
모델을 로컬에서 한 번에 올리 때와는 달리 모델 인스턴스를 생성한 후에 분할하는 것은 소스코드의 수정을 피할 수 없었습니다. 논문에서는 이를 해결하기 위해서는 두 가지 문제를 해결해야 한다고 합니다.
- 텐서가 특정 장치에 할당되기 전까지는 초기화를 미루는 기능이 필요합니다.
- GPU에 모델을 전부 로드할 수 없을 때에도 사용자가 지정한 대로 정확한 모델 초기화를 보장해야 합니다.
1번의 문제를 해결하기 위해서 FSDP deferred initialization (지연된 초기화)를 도입했습니다. 이는 가상의 디바이스(fake device)에 텐서를 적재하고 안의 생성 로직을 실행하고 기록합니다. 텐서가 가상의 디바이스에서 실제 디바이스(GPU)로 옮겨 갈 때, 기록된 생성 로직이 다시 재생됩니다.
2번의 경우가 만족되기 위해서는, 이상적으로 정확하게 할당 받은 샤드만을 디바이스에서 생성해야 합니다. 하지만 , 모델의 특정 파라미터 구간이 init() 함수 내부에서 다른 인자나, 다른 레이어에 의존적으로 설계된 경우 이를 반영하여 분할하는 것은 매우 까다로운 일입니다.
즉 할당받지 않은 샤드에 모델의 초기화에 관련된 정보가 있는 경우를 말합니다. 이를 해결하기 위해서, FSDP에서는 하나의 순전파/역전파에서 샤드를 다루는 것처럼, 한 번에 하나씩 지연된 초기화를 도입하여 생성하는 방식으로 해결합니다.
순전파와 역전파의 간단한 예시

순전파
- all_gather 연산을 진행하여 각 rank에 흩어져 있는 샤딩 된 파라미터를 모은다.
- 순전파 연산을 순차적으로 진행한다.
- 이미 순전파 연산이 진행된 파라미터를 다음 파라미터로 교체한다.
역전파
- 순전파와 똑같이 각 rank에 흩어져있는 샤딩 된 파라미터를 모은다.
- 역전파 연산을 순전파의 반대 순서로 진행한다.
- 각 gpu에서 행해진 연산 과정의 grad를 동기화 하기 위해 accumulation과 그 결과를 배분하여 통신하는 reduce-scatter 통신패턴을 사용한다.
- 방금 전에 수집한 파라미터를 교체한다.
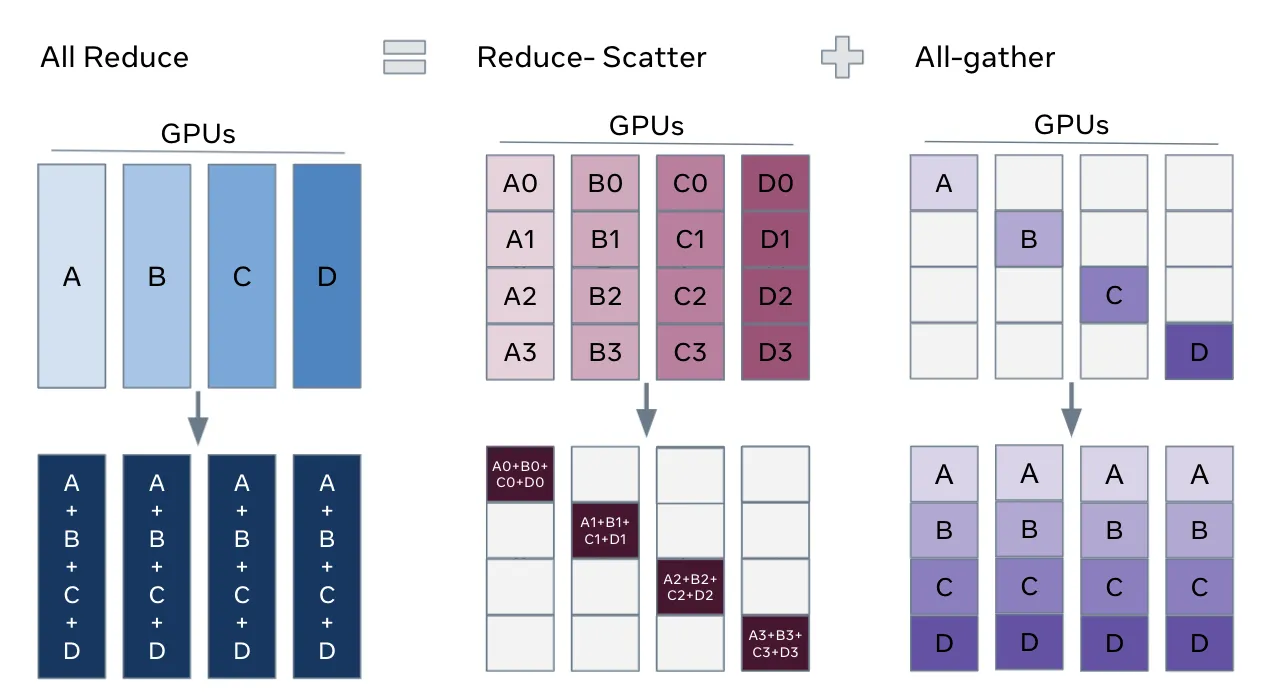
All Reduce to (Reduce-Scatter, All-gather)
FSDP의 샤딩과정을 보는 방법은 all_reduce 연산을 Reduce-Scatter 와 All-gather 분해한 후 재배치하는 과정으로 이해하는 것 입니다. All_Reduce 연산은 아래와 같이 분할한다. 즉, 궁극적으로 각 GPU에 배분된 파라미터를 결국 하나의 계산된 결과값으로 모든 gpu에서 공유하고 갖고 있는 것을 말합니다.
샤딩 전략
샤딩 전략은 샤딩을 어떤 방식으로 수행할 것인가를 결정하는 것입니다. 이는, 몇 개의 Rank를 사용할 것인가에 관련된 부분과 어떤 대상을 샤딩 대상으로 둘 것인가에 관한 내용으로 나뉠 수 있습니다.
FSDP 논문에서는 샤딩 전략과 관련하여, 샤딩할 때 사용될 Rank의 개수를 조절하는 요인인 샤딩 팩터 를 두고 이에 따라 결정 되는 방식을 의미합니다.
어떤 대상을 샤딩 대상으로 두느냐에 관한 내용은 torch.distributed의 프레임워크에서 지원하는 전략으로 학습할 때 대상이 되는 파라미터 (모델 파라미터, 옵티마이저의 파라미터, gradient 등)을 전부 샤딩할지 아니면, 옵티마이저와 gradient만 샤딩할지에 관한 내용입니다.
샤딩 팩터에 따른 샤딩 전략
샤딩 팩터 가 1일 때
- 샤딩 팩터가 1일 때는 모든 Rank에 모델의 복사본이 들어가게 됩니다. 즉 DDP와 똑같은 방식으로 이루어지게 됩니다.
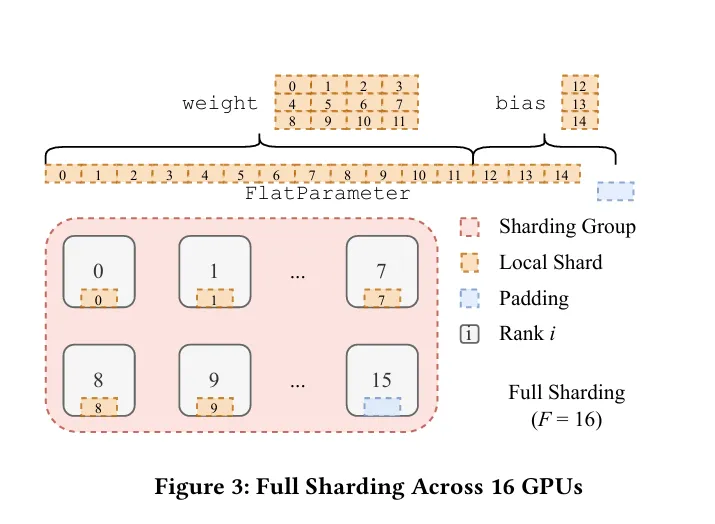
샤딩 팩터 일 때 (Full-Sharding)
- 샤딩 팩터가 W 즉, 전체 디바이스의 개수와 같을 때를 의미합니다.
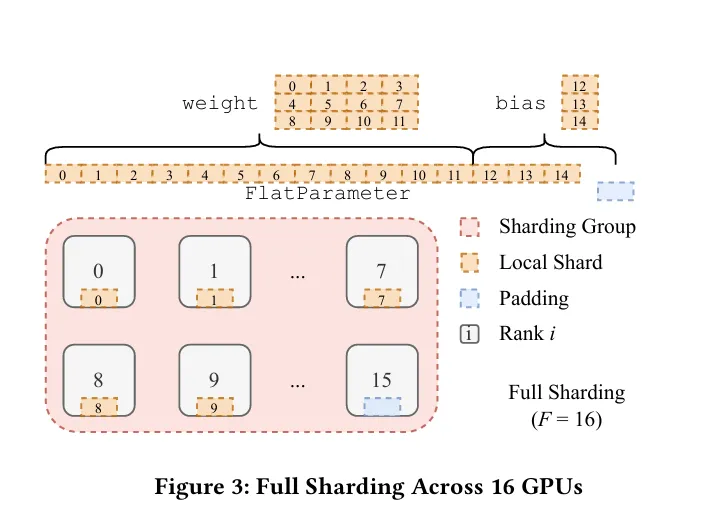
사용되는 메모리가 제일 적고 통신 부담은 제일 큰 방식의 샤딩입니다. 다시 인용한 위의 그림에서 볼 수 있다시피, input size가 모두 EVEN 합니다. 이 때 even한 사이즈를 맞추기 위해 패딩이 사용됩니다. EVEN한 사이즈는 CUDA의 NCCL 라이브러리에서 통신 시 가해지는 부담을 최소화하기 위함입니다. 더불어서, 이 때 최대한 GPU의 Vram 가용한 선 내에서 최대한 커다란 양의 배치 사이즈를 가져야 통신에 발생하는 부담을 줄일 수가 있습니다. 이유는 위와 마찬가지입니.
FSDP에서 위와 같은 텐서의 분배를 가능하게 하도록 하기 위하여, FlatParameter 라는 객체를 만들어 사용합니다. 이는 nn.Parameter 클래스를 상속한 객체입니다. FlatParameter 는 1D 텐서로, 원래의 파라미터의 내용을 1차원으로 flatten하고 거기에 rank에 따라 나눠질 수 있게 패딩을 붙인 형태의 텐서입니다. FlatParameter는 원래 텐서의 shape에 대한 정보를 상속하여 가지고 있습니다. 이 때, 원래 텐서와, gradient 역시 가지고 있습니다.
샤딩 팩터가 일 때 (hybrid-sharding)
- 샤딩 팩터가 1보다는 크고 전체 W 사이즈보다는 작을 때를 의미합니다.
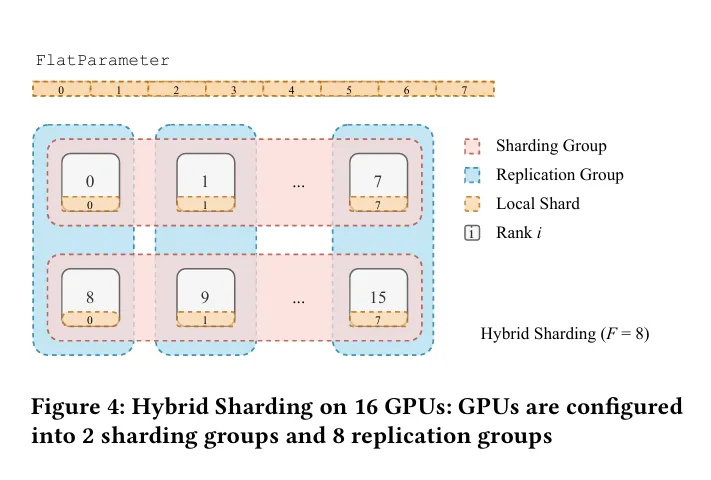
위의 예시 그림에서와 같이 하이브리드 샤딩은 샤딩과 복제를 사용합니다. 샤드는 샤드의 그룹을 라고 할 때, 의 크기로 분배됩니다. 위의 그림에서 local shard 내부의 노란색 아랫칸에 주어진 0…7까지의 번호가 샤드 그룹의 Rank입니다. 생성된 샤드 그룹 내부적으로 파라미터를 복제하여 생성된 복제 그룹이 생기게 됩니다. 복제 그룹에 생기게 되는 rank는 로컬 샤드의 중앙에 있는 번호입니다.
이 때 발생하는 gradient의 reduction 연산의 경우, 각 샤드 그룹 내부에 행해지는 reduce-scatter연산을 따라서 행해지는 all-reduce 연산과 같습니다.
하이브리드 샤딩은 가속화 된 데이터 센터의 지역성을 이점으로 취할 수 있고, 호스트 간의 통신 트래픽을 감소시킬 수 있는 이점이 있습니다.
샤딩 대상에 따른 샤딩 전략
이는 토치 프레임워크에서 지원하는 기능 혹은 전략이라 할 수 있습니다. 샤딩하고자 하는 범주를 설정할 수 있는 전략이라고 할 수 있습니다.
zero3sharding
학습할 때 대상이 되는 파라미터 (모델 파라미터, 옵티마이저의 파라미터, gradient 등)을 전부 샤딩하는 전략을 말합니다.
zero2sharding
옵티마이저와 gradient만 샤딩하는 전략을 말합니다.
아래와 같이 파라미터를 조절하여 실행할 수 있습니다.
torch.cuda.set_device(local_rank)
model = FSDP(model,
auto_wrap_policy=t5_auto_wrap_policy,
mixed_precision=bfSixteen,
device_id=torch.cuda.current_device(),
sharding_strategy=ShardingStrategy.SHARD_GRAD_OP # ZERO2)Autogrd
FSDP의 FlatParameter 는 torch의 autograde 엔진과 상호작용해야 합니다. 이 때 다음 두가지 문제를 해결해야 실현가능하다고 합니다.
- 정확한 기울기 전파
- 제 시간에 reduction 연산을 수행해야 함.
(1)번은 FlatParameter 가 원래의 파라미터를 소유함으로써 해결이 됩니다. 순전파가 실행되기 이전에 원래의 파라미터를 샤드 되지 않은 파라미터의 View로 쓰게하고 autograd 엔진이 샤드 되지 않은 파라미터의 기울기를 배정하고 offset에 맞게 원래 파라미터를 작성할 수 있습니다.
(2)번은 gradient에 hook을 등록합니다. (webhook이라고 할 때의 그 hook이 맞습니다.) 따라서, FlatParameter 가 계산이 완료됐을 때 동작합니다. 이 때의 경우는 역전파 이후의 로직이나 기울기 reduction의 과정을 포함합니다.
Fully Sharded Data Parallel: faster AI training with fewer GPUs
Getting Started with Fully Sharded Data Parallel(FSDP) — PyTorch Tutorials 2.4.0+cu124 documentation
