Intro
지식 그래프의 구축은 보통 그래프 데이터베이스를 통해서 이루어진다. 그래프 데이터베이스는 데이터 베이스의 한 종류로 데이터를 그래프로 표현하는데 사용되는 데이터 베이스이다. Nosql의 한 종류로 SNS나 검색 서비스 그리고 그 외에 다양한 서비스에서 사용된다. 이때 주로 활용되는 대표적인 그래프 데이터베이스가 Neo4j이다. 그리고 Neo4j를 제어하는데 사용되는 언어가 Cyhper이다. Cypher는 현재 ISO에서 제정하려고 하는 GQL(Graph Query Language) 표준의 가장 핵심적인 기반으로 사용되고 있다.
Neo4j 설치
neo4j Desktop을 설치한 후에 실행하여 사용해볼 수 있다.
설치 링크를 통해 가이드를 따라서 설치하면 된다. 만약, Neo4j Desktop을 설치하긴 부담되고 Neo4j를 사용해보고 싶다면, Neo4j Sandbox를 통해 사용가능하다.
Cypher에 대하여
Cypher는 선언적이고 패턴매칭적인 특징을 지닌 쿼리 언어이다. 여기서 선언적이라는 말의 의미는 '무엇(what)'을 할지는 사용자가 정하지만 '어떻게(how)'는 시스템(여기서는 Neo4j)에게 맡겨두는 방식을 말한다. 패턴 매칭적이다라는 의미는 실제로 데이터가 연결되어 있는 패턴을 직접 기술한다는 의미이다. 즉, 노드 A와 노드 B가 연결되어 있다고 할때 (:A)-[:LINK]->(:B)와 같이 실제로 연결된 패턴을 직접 기술하는 형태로 쿼리 언어를 작성한다는 것을 의미한다.
Cypher의 기본적인 구조
( )괄호는 노드를 선언할 때 사용한다.:기호는 노드나 관계의 라벨을 의미한다. 예를 들어(:Person)은Person노드를 의미하는 것이다.-[: ]->의 대괄호와 화살표는 관계를 의미한다. 예를 들어-[:FRIEND]->는 '친구'라는 라벨을 가진 관계를 의미하는 것이다.{ }중괄호는 속성을 의미한다. 예를 들어,(:Person {name:'Carl'})은 'Carl'이라는 이름을 가진 '사람' 노드를 의미한다.
Cypher, 자주 쓰이는 쿼리 예시
MATCH (n) DELETE n - 모든 노드 삭제 , 관계 역시 절단된 상태로 남기지 않고 중단함
MATCH ()-[r:LIVES_IN]->() DELETE r - 모든 노드 사이의 LIVES_IN 관계 삭제
MATCH (n) DETACH DELETE n- 모든 노드와 노드에 부착된 모든 관계 삭제
Create문
Cypher의 구조는 '<Cypher 명령문> 그래프 패턴' 형태로 이루어진다. 아래는 Create를 통해 노드와 관계를 한번에 생성해내는 예시이다.
CREATE (:Person {name:'Rosa'})-[:LIVES_IN {since:2020}]->
(:Place {city:'Berlin', country:'DE'})
생성 명령문인 Create의 뒤에 넣고자 하는 데이터의 패턴 - (:Person {name:'Rosa'})-[:LIVES_IN {since:2020}]-> (:Place {city:'Berlin', country:'DE'}) - 이 뒤따르는 것을 확인할 수 있다.
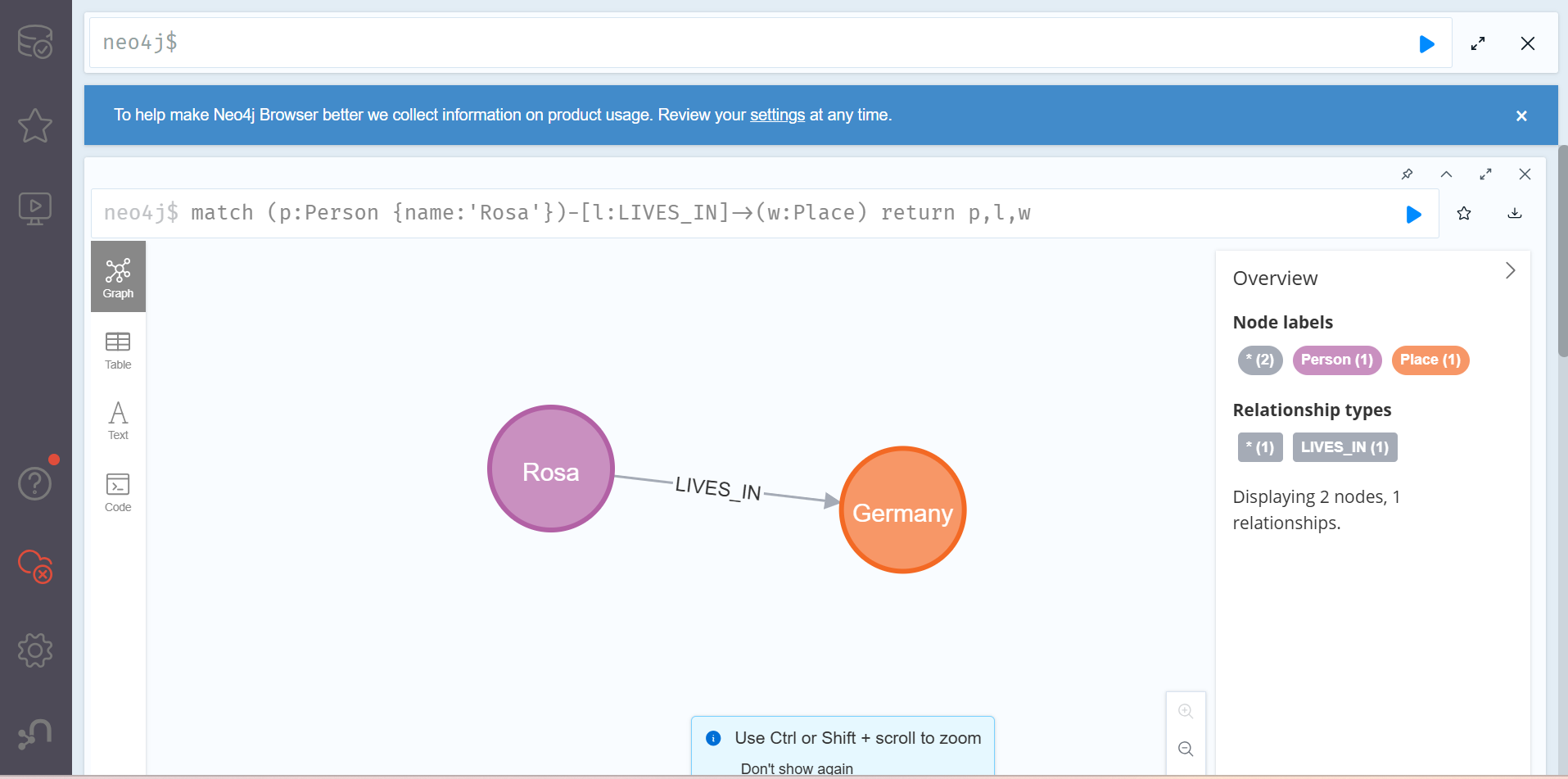
위는 match문을 통해 새로운 관계가 생긴 것을 위와 같이 확인할 수 있다.
중복없이 그래프를 생성하기
기본적으로 'Create' 문의 경우 항상 새로운 데이터를 생성한다. 만약 위의 Create문을 한번 더 실행할 경우 똑같은 노드와 관계가 생성되는 것을 확인할 수 있다.
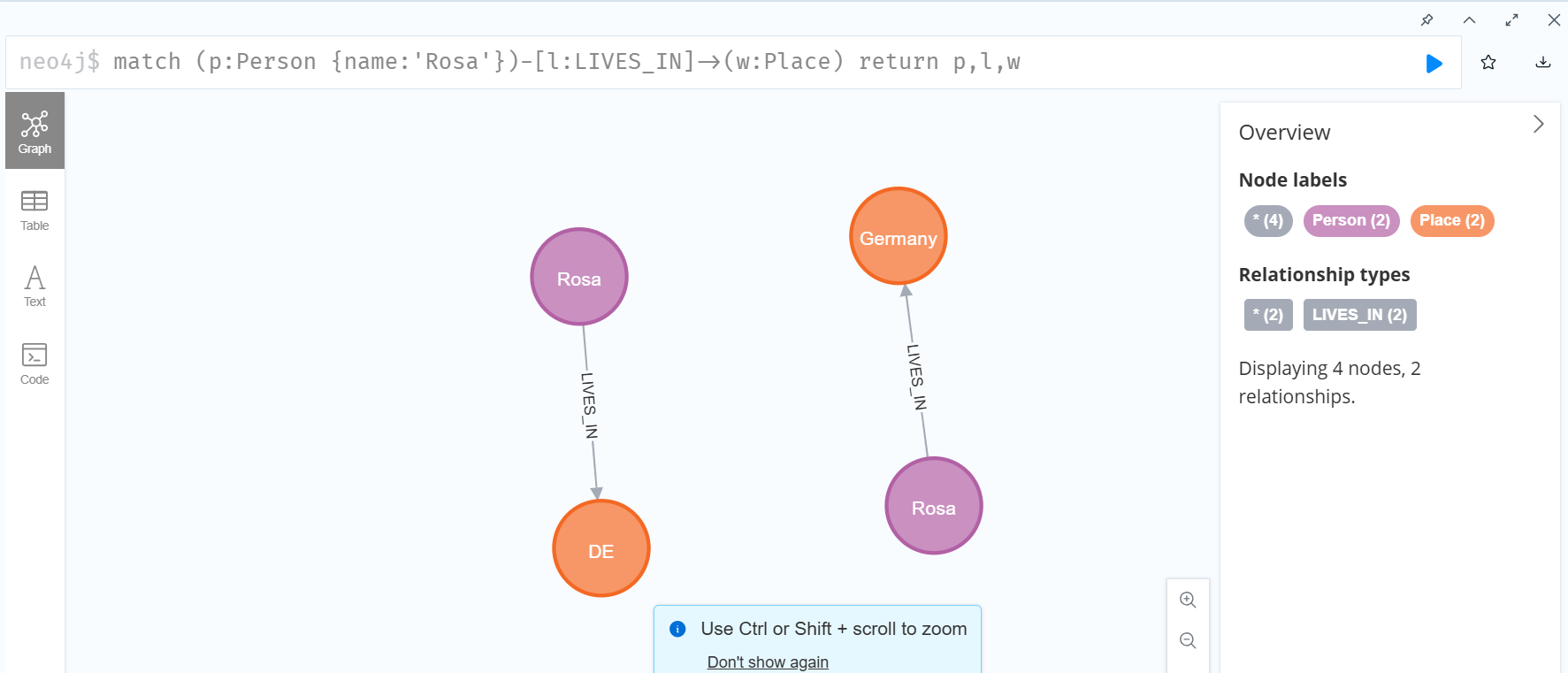
즉, Create문을 쓰게 되면 우리는 데이터의 unique함을 보장하며 데이터를 생성하는 것이 불가능하다는 것을 알 수 있다. 이를 피하기 위해 Merge 문을 써야 한다. Merge문은 merge 뒤의 데이터 패턴 '전체'가 존재하지 않는 경우에만 새롭게 데이터를 생성한다.
일단 위의 데이터를 MATCH (n) DETACH DELTE n을 통해 지워버리도록 하자.
자 이번에는 Merge 문을 통해 생성을 해보자.
MERGE (:Person {name:'Karl', age:64})-[:LIVES_IN {since:1980}]→(:Place {city:'London', country:'UK'})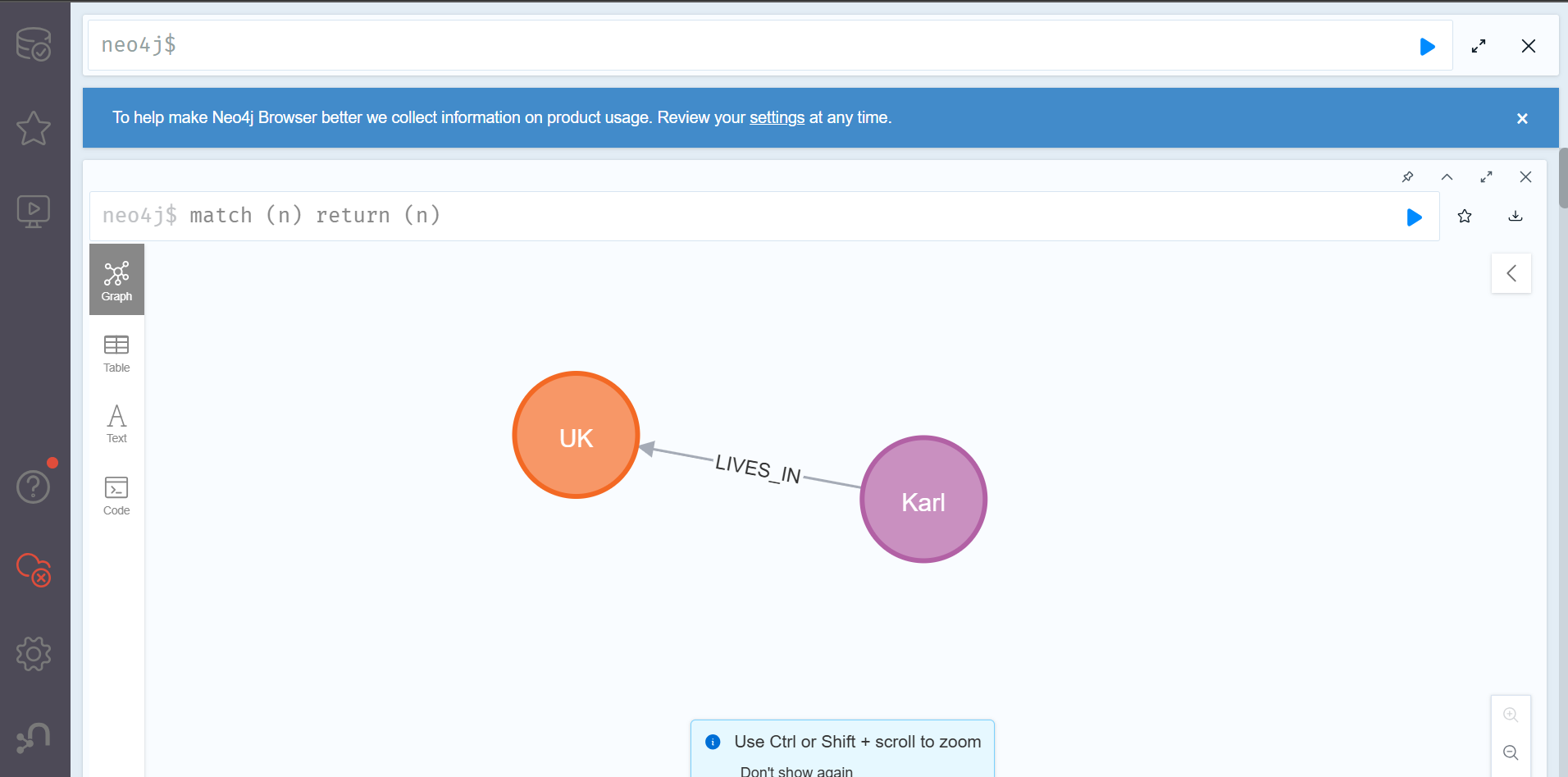
위와 같이 'person'노드와 'place'노드의 관계가 노드와 함께 잘 생성되었음을 알 수 있다.
자 이번에는 아래의 쿼리를 실행시켜, 새로운 노드와 관계를 만들어보자
MERGE (:Person {name:'Fred'})-[:LIVES_IN]→(:Place
{city:'London', country:'UK'}), 여기서 새로운 사람노드가 LIVES_IN 관계를 통해 기존에 존재하는 london 노드와 연결되리라는 것을 기대할 것이다. 하지만 쿼리를 실행시키면 다음과 같은 결과를 얻게 될 것이다.
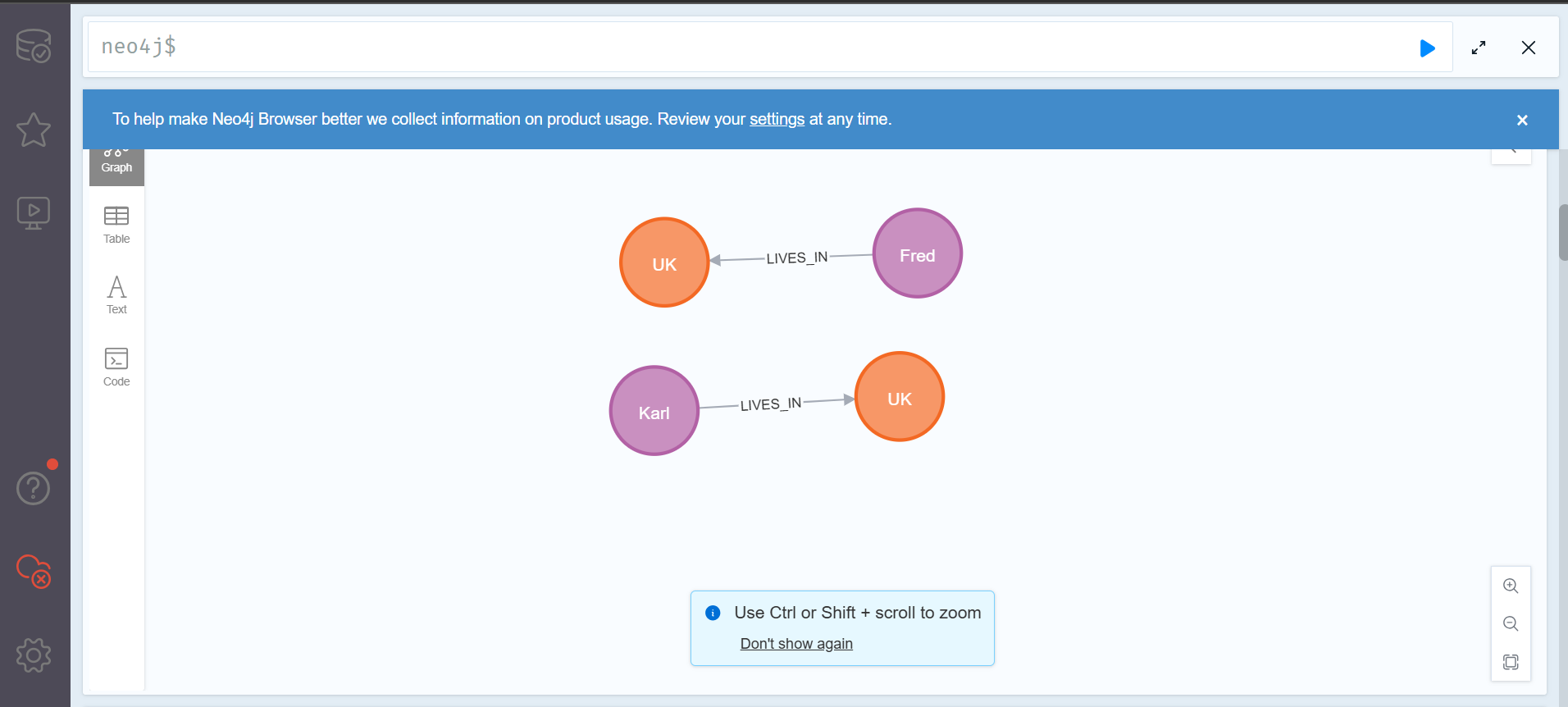
이는 Merge문이 match문과 create문의 조합이기 때문에 match되는 패턴이 없다면 create를 하게 된다. 하지만 create의 동작은 기존의 같은 노드나 관계가 있는지 없는지 신경 쓰지 않고 새로운 노드를 만들 뿐이다. 따라서 이를 해결하기 위해서는 다른 방법이 필요하다.
- match & merge
match & merge는 연결하고자 하는 노드를 match를 통해 찾은 후에 해당 노드에 새로운 연결을 생성하는 방법이다.
match (place:Place {country:'UK'})
merge (p:Person {name:'Fred'})-[:LIVES_IN]->(place) 위의 쿼리를 통해 우리는 우리가 원하던 결과를 얻어낼 수 있다.
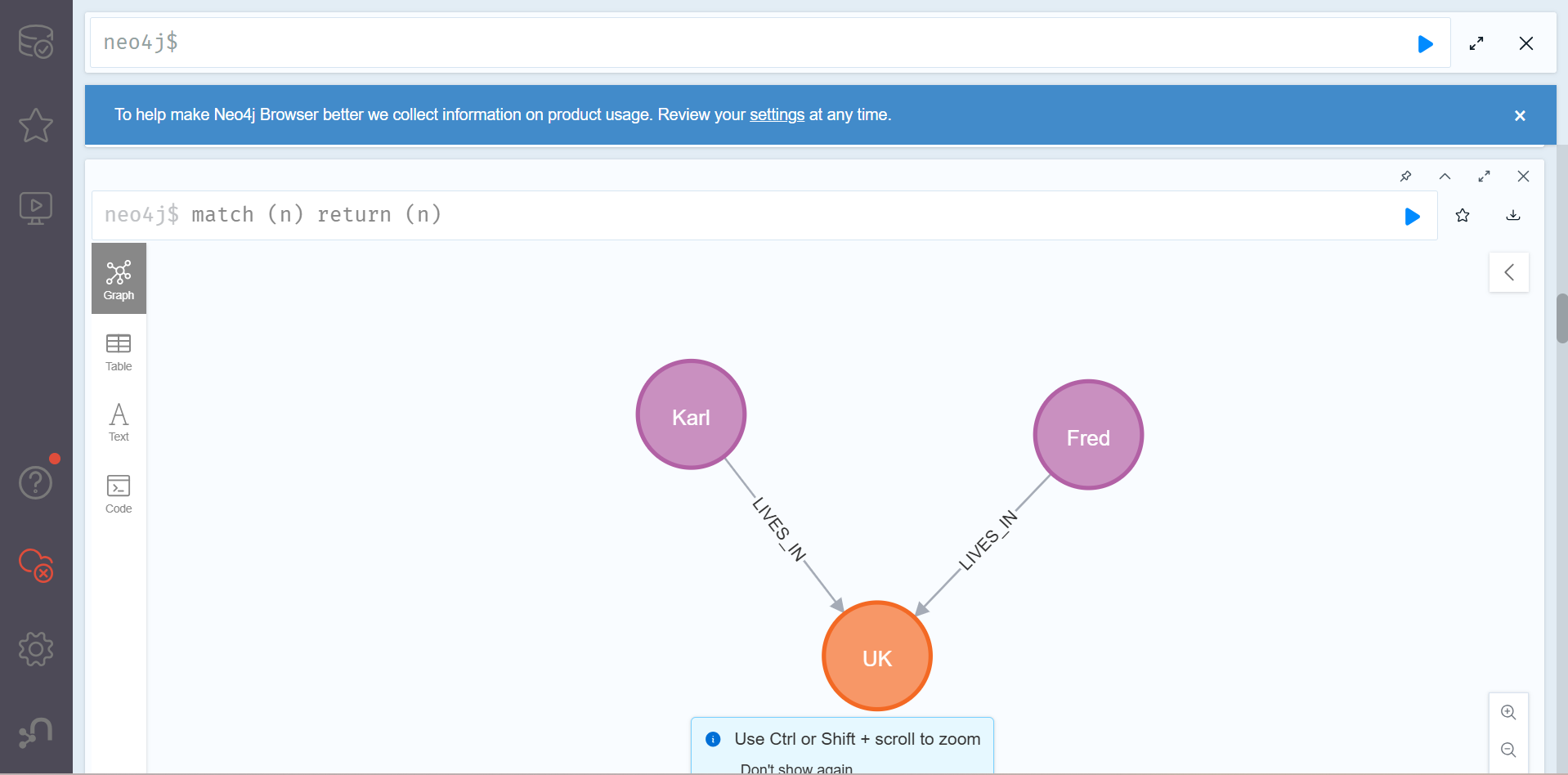
하지만, 이 방법은 매번 로직에서 '정확하게' 사람이 해당 노드의 중복을 검사하고 찾아야 하는 번거로움이 있고 이러한 번거로움은 결국 중복된 노드를 만들 가능성을 높이게 된다.
- Unique 제약 조건
놀랍게도(?) Neo4j 역시 Unique 제약 조건을 만들 수 있다. 물론 제약 조건을 추가한 후에 match & merge를 통해서 생성을 해줘야 하는 건 똑같지만, 사람이 매번 명확하게 중복을 검사하고 node를 찾아서 생성해야하는 번거로움보단 훨씬 수고가 줄게 되고, 시스템 자체에서 중복을 막기 때문에 안전하다.
```cypher
CREATE CONSTRAINT no_duplicate_cities FOR (p:Place) REQUIRE (p.country, p.city) is Node key
```위는 country, city의 속성을 합쳐서 합성키를 만들어서 새로운 'place'의 노드 생성시 같은 속성을 가진 노드의생성을 제한하는 것이다. 다만, 위와 같은 합성키의 생성은 neo4j Enterprise Edition에서만 가능한 방법이다. 따라서, 이럴 때는 두개의 문자열을 합성해서 하나의 unique key로 만들어서 사용하는 법을 사용하면 위와 같은 효과를 누릴 수 있다.
먼저 기존의 노드들의 city와 country 속성을 찾은 후에 결합하여 하나의 속성으로 만들자. 당연히 그래프 데이터베이스 역시 데이터베이스의 일종이므로 이미 생성된 데이터에 접근하여 데이터를 수정하거나 추가하는 것이 가능하다. 아래는 where문과 set을 통해 찾고자 하는 데이터의 집합을 정의하고 추가적인 key속성을 만들어주는 예시이다.
match (n)
wher n.city is not Null and n.country is not null
set n.key = n.city + '|' + n.country 이후에 해당 Place 노드에 해당 속성을 유니크로 만들어 주자.
FOR (n:Place) REQUIRE n.key IS UNIQUE 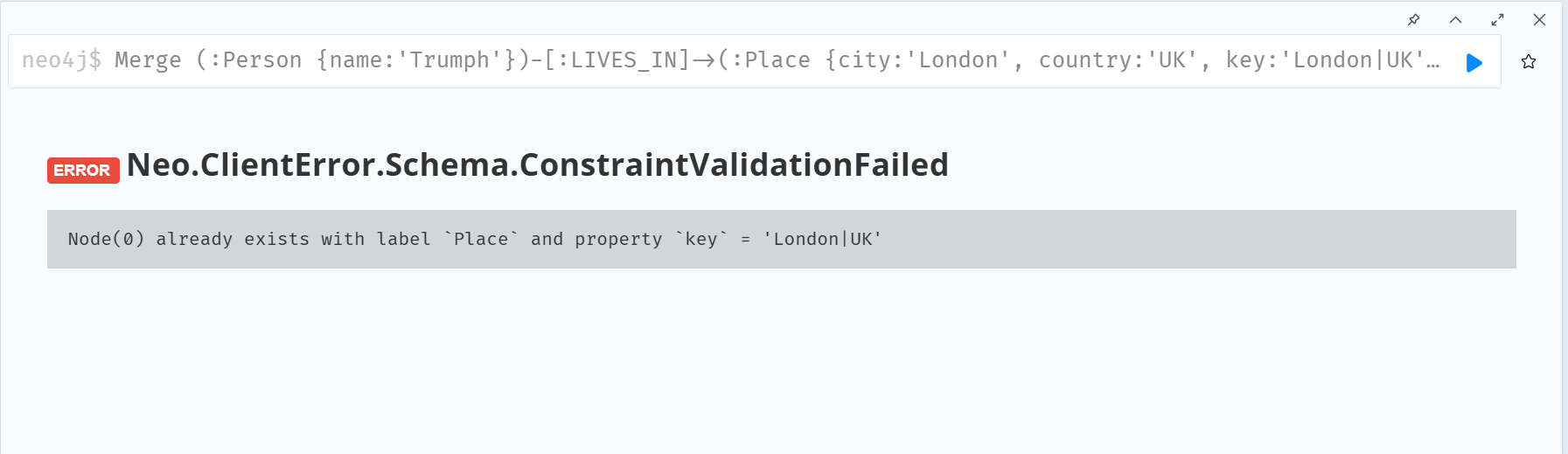
다시 UK 노드를 MERGE를 시켰을 때, duplicate 에러가 나는 것을 확인할 수 있다.
자 이렇게 키를 만든 이후에 중복된 데이터 없이 삽입하는 법을 알아보자.
1. London을 나타내는 장소 노드를 Merge(match or create)
2. 새로운 사람 노드를 Merge(match or create)
3. 사람 노드와 장소 노드를 연결하는 관계 생성
칼을 지워버리고 다시 한 번 만들어보자.
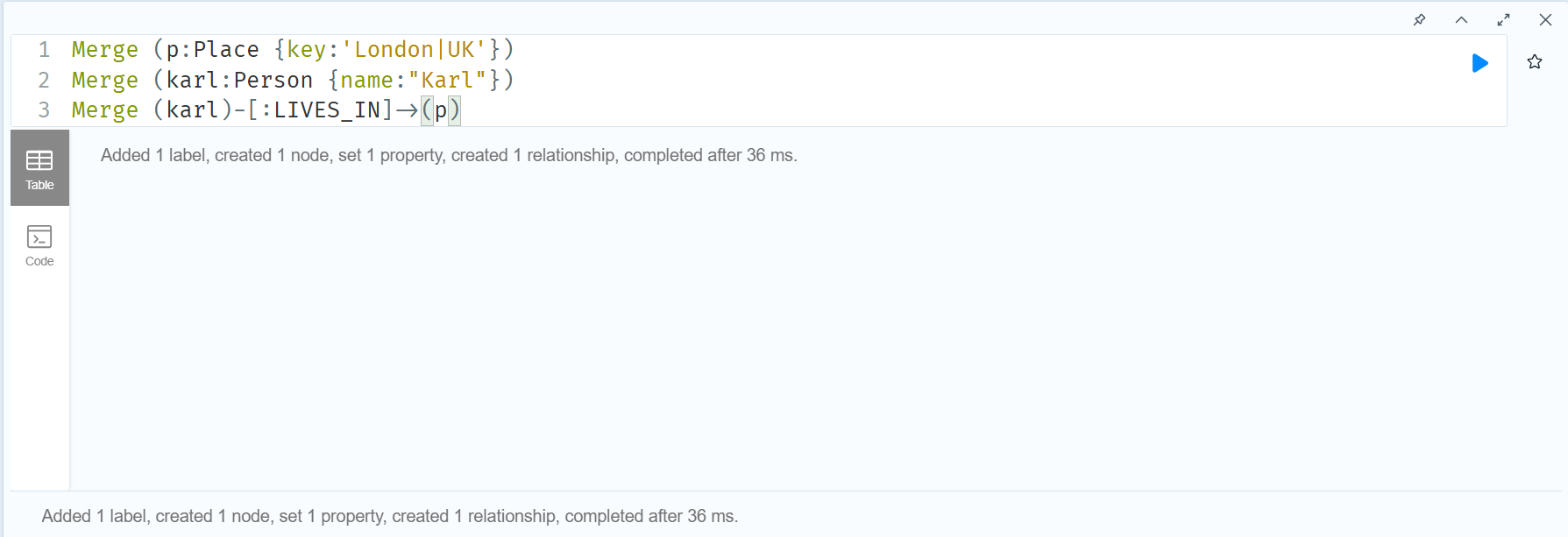
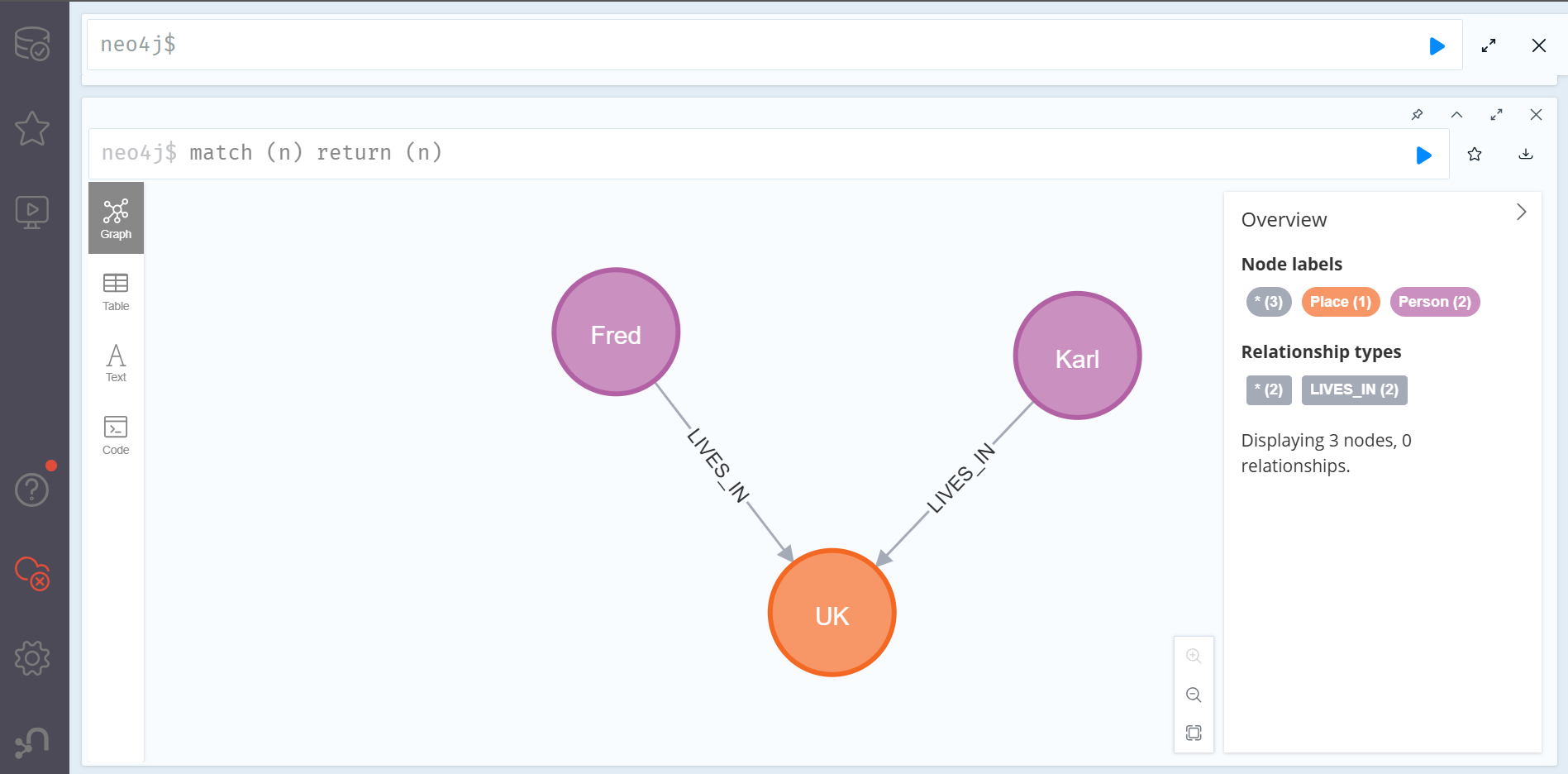
우리가 원하는 대로 잘 생성된 것을 확인할 수 있다. 다만 이런 방편은 아무래도 composite key보다 불편하기 때문에, 이러한 방편 대신 실제로 Enterprise 에디션을 쓰지않고 unique한 노드를 생성하고 싶다면, 생성할 떄 unique키를 발급하여 쓰는 방식을 고려하는 편이 좋을 것 같다.
Graph Local Query
그래프의 특정한 노드를 찾거나, 특정 패턴을 붙이거나 연결을 해제하는 등의 query를 가리켜 graph local query라고 한다. 즉, 그래프의 서브 그래프를 찾아서 어떠한 패턴을 생성하거나 해제하는 등의 역할을 하는 쿼리 패턴이라고 할 수 있다.
이 때, 주요한 로컬 쿼리는 다음과 같다.
로컬 쿼리의 주요 유형
- 이웃 노드 탐색: 특정 노드의 직접적인 연결 노드들 조회
- K-홉 쿼리: 특정 노드로부터 K 단계 이내의 노드들 탐색
- 서브그래프 추출: 특정 조건을 만족하는 노드와 엣지로 구성된 부분 그래프 추출
이웃노드 탐색
직접적으로 연결된 패턴이 있다면 해당 노드를 직접 cypher 패턴을 통해 조회할 수 있다. 하지만 우리가 특정 노드에 직접적으로 바인딩 된 관계를 모를 땐 어떻게 해야할까? match (n) return (n) 과 마찬가지로 우리는 연결에 [r]을 넣어 해당 노드에 연결된 모든 연결을 탐색할 수 있다.
양방향 노드 탐색
MATCH (n:Person {name:'Fred'})-[r]-(connectedNodes)
RETURN r, connectedNodes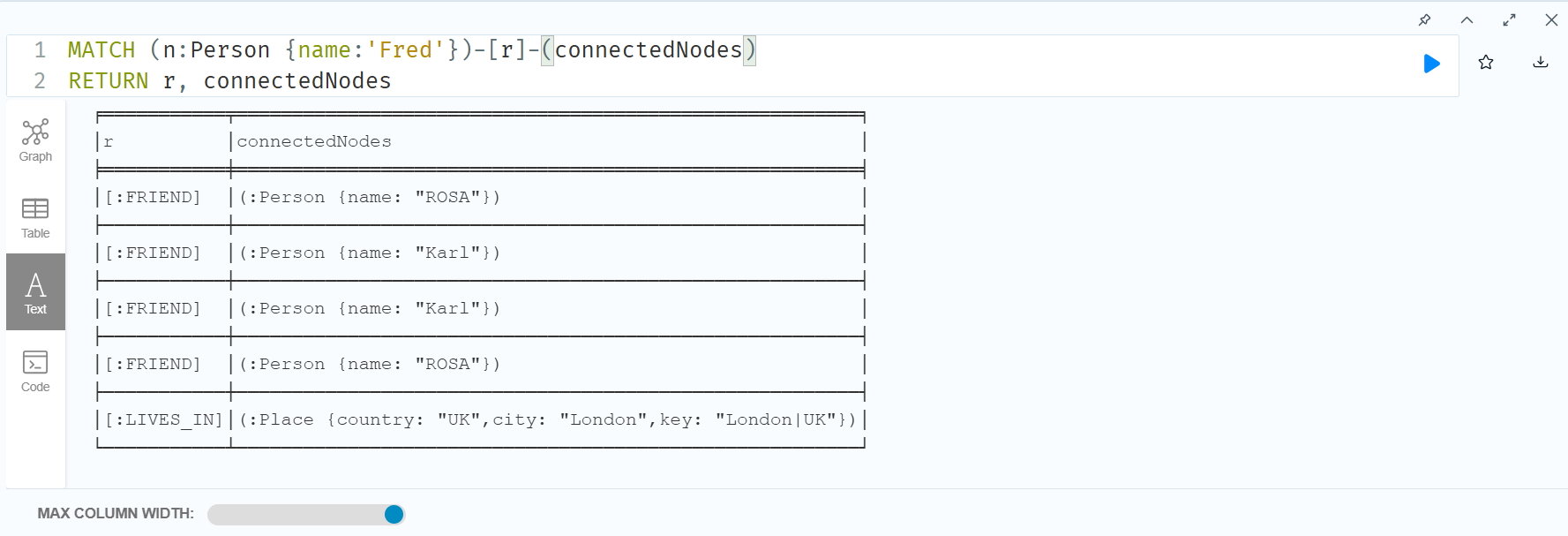
Fred 노드에 들어가고 나가는 모든 연결과 노드를 조회한 결과이다.
나가는 방향 노드 탐색
MATCH (n:Person {name:'Fred'})-[r]->(connectedNodes)
RETURN r, connectedNodes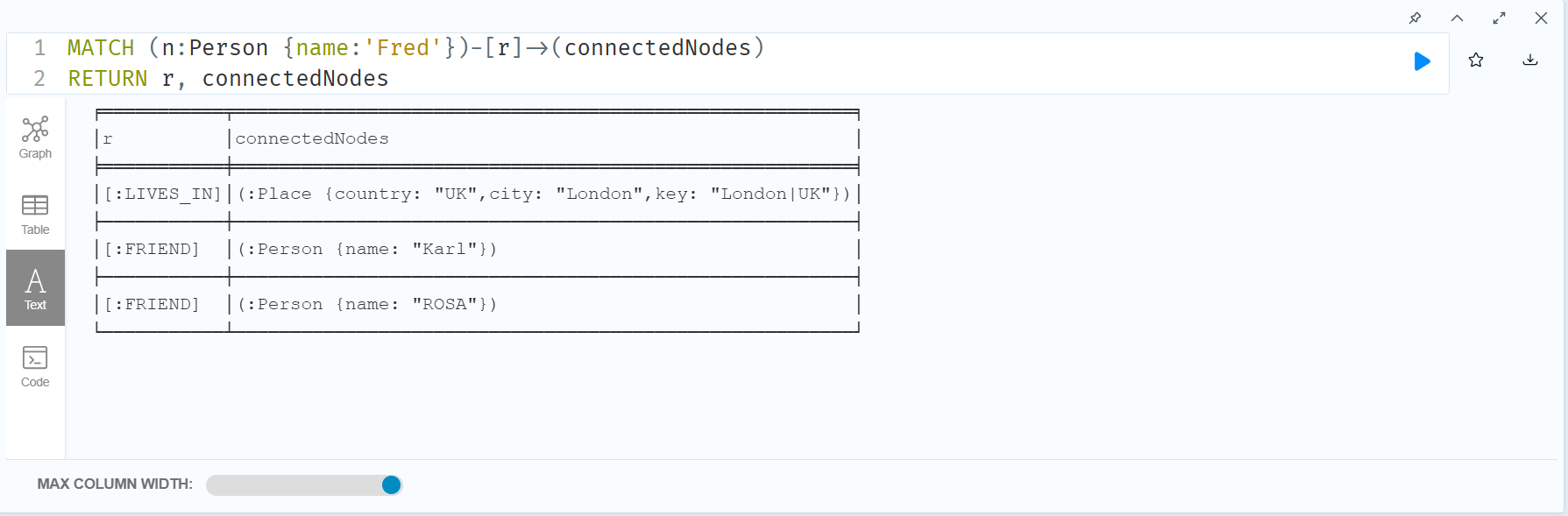
들어오는 방향 노드 탐색
MATCH (n:Person {name:'Fred'})<-[r]-(connectedNodes)
RETURN r, connectedNodes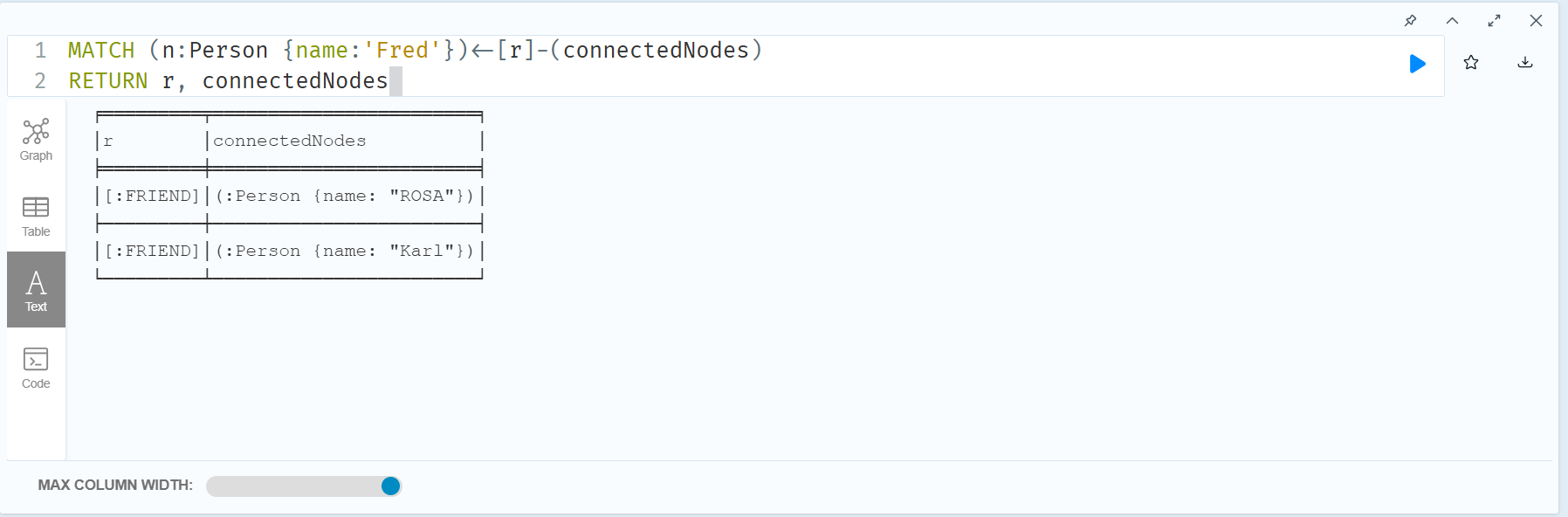
k-홉 쿼리 탐색
예를 들어 친구의 친구를 찾고 싶다고 하자 이는 몇 단계를 거쳐가야하는 그래프인가? 이는 2단계를 거쳐가야하는 그래프로 볼 수 있고, 이는 다음과 같은 쿼리로 작성될 수 있다.
MATCH (:Person {name:'Rosa'})-[:FRIEND*2..2]->(fof:Person)
RETURN (fof)*2..2는 2 to 2를 의미하고 여기에서는 명시적으로 2단계만을 탐색하라는 의미를 지니고 있다. 이는 다음의 쿼리 패턴과 같다. (:Person)-[FRIEND]->(:Person)-[FRIEND]->(:Person) 만약 친구 혹은 친구의 친구를 탐색하고자 한다면 1..2로 나타낼 수 있다.
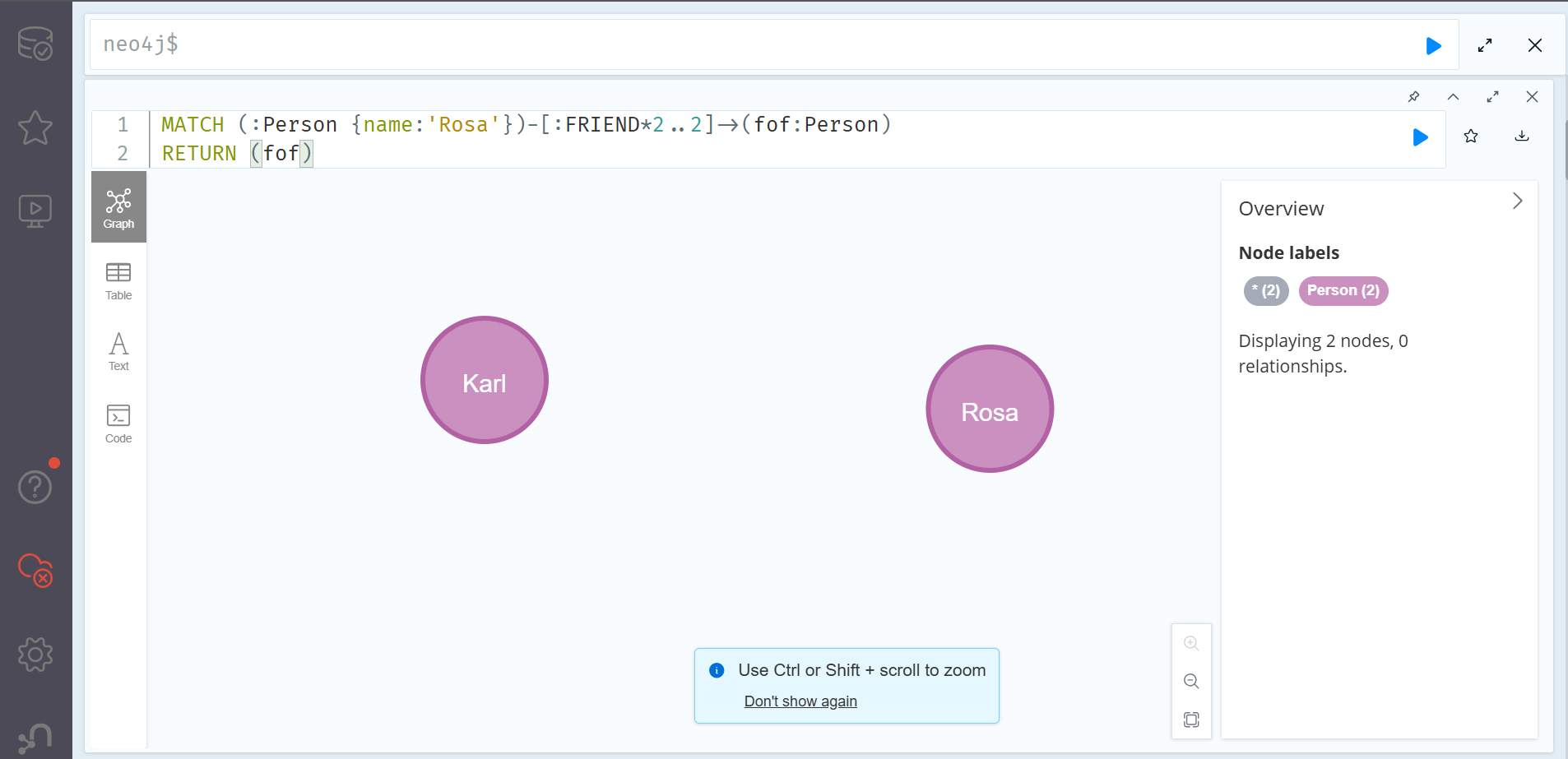
Rosa와 친구인 Fred 역시 Rosa와 친구관계로 이어져 있으므로, Rosa 역시 반환되는 것을 알 수 있다. 이 때 간단하게 where문을 추가한다면 Rosa가 반환되는 것을 방지할 수 있다
MATCH (rosa:Person {name:'Rosa'})-[:FRIEND*2..2]->(fof:Person)
Where fof <> rosa
RETURN (fof)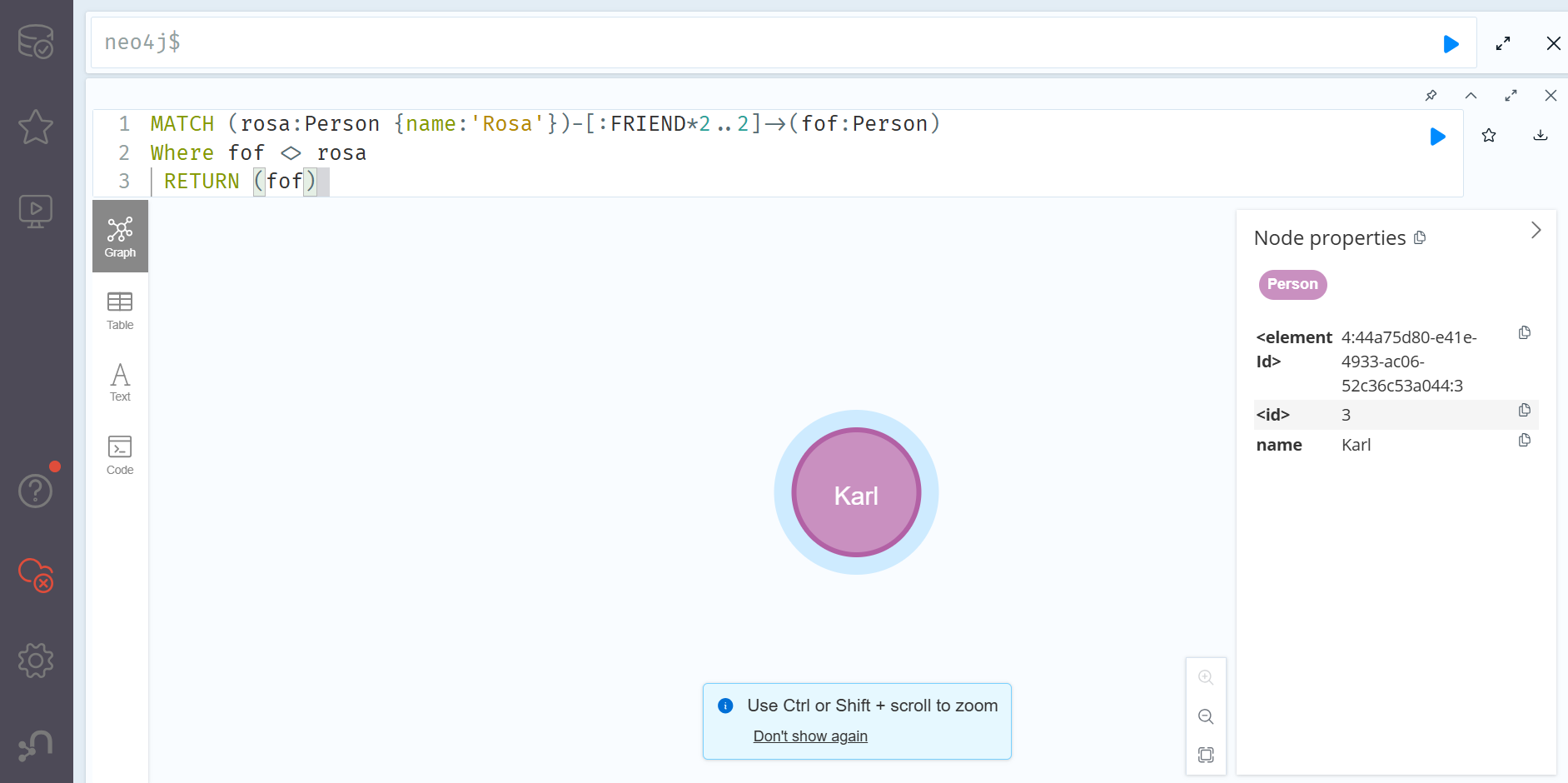
Subgraph
Subgraph는 전체 그래프의 일부분을 가지는 그래프로서, 특정한 패턴에 따라 분할되어 있는 그래프를 말한다. 하지만 일반적인 쿼리와의 차이점은 단순한 값의 나열이 아닌 구조적인 연결성을 가지고 있고, RDB의 View와 같이 활용된다는 점이다.
예를 들어 아래의 쿼리는 노드의 정보만을 반환하게 된다.
MATCH (p:Person)-[:LIVES_IN]->(:Place {city:'Berlin', country:'DE'})
RETURN (p)하지만, 서브 그래프는 특정 패턴을 지니고 있는 전체 그래프의 부분집합을 반환하여 구조적인 특징과 맥락을 이해할 수 있게한다.
MATCH subgraph = (p:Person)-[:LIVES_IN]->(:Place {city:'Berlin', country:'DE'})
RETURN subgraphGraph Global Query
로컬 쿼리와는 다르게 전체 그래프를 대상으로 패턴이나 데이터를 뽑아야 하는 경우가 있다. 예를 들자면 aggregation 작업이 필요한 쿼리의 경우가 그렇다. 예를 들어, 사람이 가장 많이 사는 도시가 어디야라고 한다면 우리는 각 도시와 사람 노드의 [:LIVES_IN]관계를 집계해야할 것이다.
MATCH (place:Place)<-[l:LIVES_IN]-(:Person)
RETURN place, count(l) AS rels ORDER BY rels DESC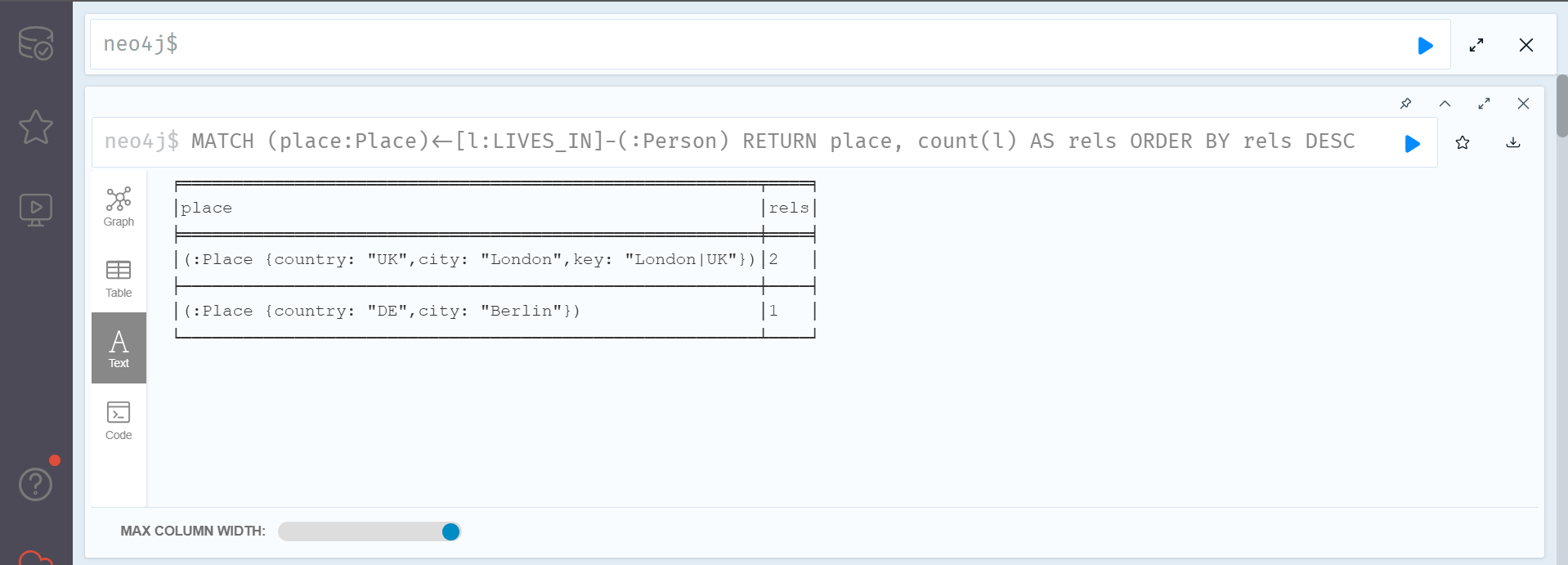
위와 같은 aggregation 작업 외에도 다음과 같은 목적의 쿼리들 역시 global query의 대사이 될 수 있다.
- 전역 최단 경로 찾기
- 그래프 전체의 특성 분석
- 글로벌 중심성 측정 (페이지랭크 등)
- 전체 그래프의 구조적 특성 분석
Cypher의 함수와 프로시져
Cypher의 Call 구문을 통해 이미 등록되어 있는 프로시져나 함수를 사용가능하다.
CALL <함수 이름>
APOC
APOC는 자주 사용되는 함수와 프로시져의 집합이다. 따라서, 혹시 사용하고자 하는 기능 APOC에 이미 있는지 확인하는 것이 새로운 함수를 작성하는 등의 불필요한 노력을 감소시킬 수 있다. APOC doc에서 APOC 목록들을 찾을 수 있다.
자주 쓰이는 함수 예시
-
db schema를 확인하는 함수
CALL db.schema.visualization -
시간/날짜를 변환하는 함수
RETURN apoc.date.convert(datetime().epochSeconds, "seconds", "days") as outputInDays;사용자 정의 함수는 JAVA로 작성하여 extension의 형태로 만들어 등록하여야한다
쿼리 검사 툴
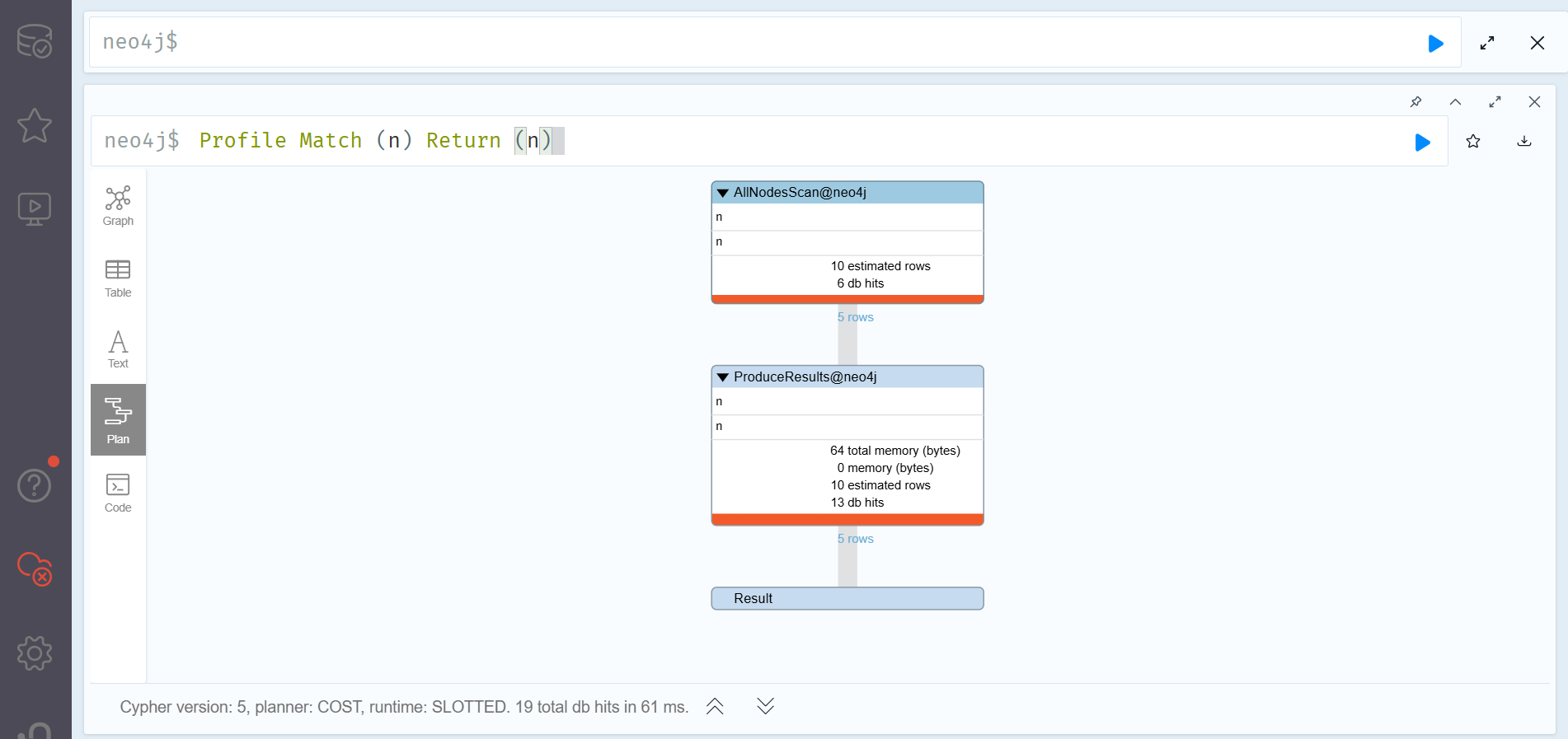
Explain과 PROFILE 의 두가지 툴이 있다.
EXPLAIN
- 쿼리가 어떻게 실행될지 특히 데이터의 양의 관점에서 시각화하여 보여주는 실행문이다.
EXPLAIN명령어는 실제로 큰 양의 쿼리를 실행시키기 이전에 사용하여 확인하는 편이 좋다.
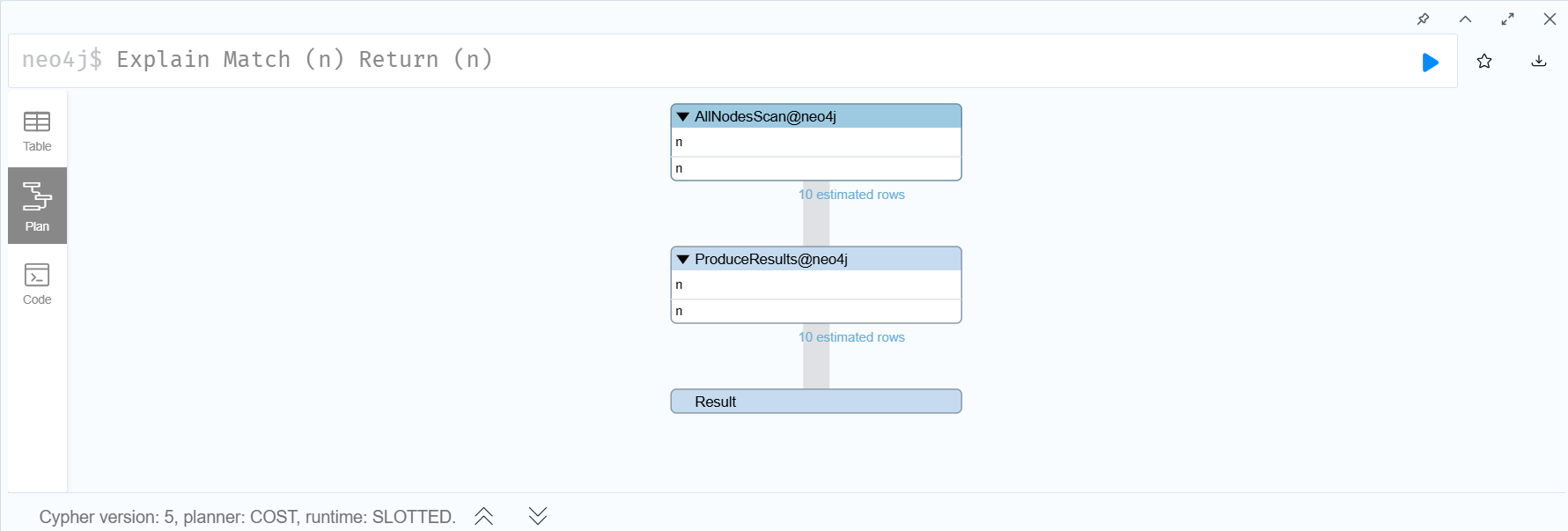
작은 글씨로 반환되는 row가 표시되어 있는 것을 확인할 수 있다.
PROFILE
PROFILE의 경우는 Explain보다 좀 더 상세한 내용을 알려준다. PROFILE 구문은 실제의 쿼리가 실제 지식 그래프 어떻게 동작하는지 등을 시각화하여 사용자가 좀 더 실제 쿼리 동작에 대한 자세한 피드백을 받을 수 있도록 한다.