Electra는 전기를 이용한 알고리즘 학습을 위한 모델 중 하나로, GPT (Generative Pre-trained Transformer)와 같은 대형 언어 모델의 일종. Electra는 Google이 2020년에 발표한 모델로, 기존의 언어 모델과는 약간 다른 접근 방식을 채택.
[1] Language 모델의 역사
- N-gram 모델 (1950년대):
-
초기 언어 모델로, 문장의 단어를 나열한 순서를 기반으로 다음 단어를 예측하는 통계적인 방법을 사용.
-
주어진 문맥에서 고정된 개수의 연속된 단어를 고려하는데, 이를 N-gram이라고 함. 예를 들어, bigram은 두 단어의 연속이며 trigram은 세 단어의 연속임. 예를 들어서 문장 An adorable little boy is spreading smiles이 있을 때, 각 n에 대해서 n-gram을 전부 구해보면 다음과 같음.
unigrams : an, adorable, little, boy, is, spreading, smiles
bigrams : an adorable, adorable little, little boy, boy is, is spreading, spreading smiles
trigrams : an adorable little, adorable little boy, little boy is, boy is spreading, is spreading smiles
4-grams : an adorable little boy, adorable little boy is, little boy is spreading, boy is spreading smiles -
🤔 n-gram을 통한 언어 모델에서는 다음에 나올 단어의 예측은 오직 n-1개의 단어에만 의존
예: An adorable little boy is spreading ___
bigrams 예측 : is spreading 만 가지고 예측 👉 갖고 있는 100개의 corpus에서 is spreading 다음에 joy가 온 경우가 10번, smile이 온 경우가 20번이라면 joy의 확률은 10%, smile의 확률은 20%임. 따라서 확률적으로 smile이 올 것이라 예측함 -
🤬 전체 문장을 판단하지 못하기 때문에 정확성이 떨어짐. n이 작으면 "is spreading"처럼 작은 문맥에서는 정확성이 높아지지만, 문장 전체의 의미를 이해하는 데 어려움이 있을 수 있음. 반대로 n이 크면 "an adorable little boy is spreading"처럼 큰 문맥에서는 전체적인 의미를 파악할 수 있지만, 해당 n-gram을 훈련 데이터에서 찾기 어렵고 모델의 크기가 커짐
def generate_ngrams(text, n):
words = text.split()
ngrams = [tuple(words[i:i+n]) for i in range(len(words)-n+1)]
return ngrams
# 예시
text_example = "An adorable little boy is spreading joy."
n_value = 2 # bigram 예시
result = generate_ngrams(text_example, n_value)
print(f"{n_value}-gram 결과: {result}")
# 결과
2-gram 결과: [('An', 'adorable'), ('adorable', 'little'), ('little', 'boy'), ('boy', 'is'), ('is', 'spreading'), ('spreading', 'joy.')]
- 통계적 언어 모델 (1980년대 - 1990년대):
-
고정된 확률을 할당하고, 각 단어를 모두 독립된 단어로 취급, 따로 훈련 필요없이 데이터셋이 주어지면 확률 확인
-
Markov 모델(시퀀스 데이터에서 현재 상태가 이전의 일정한 유한한 과거 상태에만 의존한다고 가정하는 확률 모델)과 같은 통계적 기법이 도입. 여전히 단어 간의 확률적 관계를 모델링하며, 훈련 데이터의 확률 분포를 기반으로 문장 생성이나 다음 단어 예측을 수행.
-
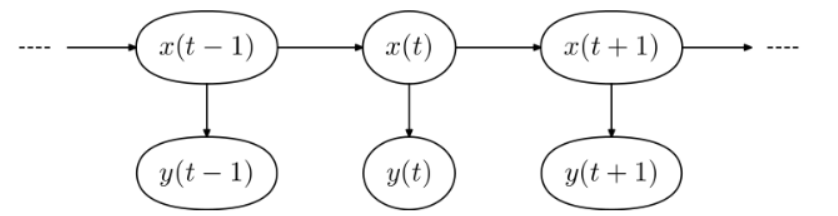
😎 Markov model의 핵심은 현재의 observation이 바로 이전의 state에 의해서만 결정된다는 것. 한 상태(state)의 확률은 단지 그 이전 상태에만 의존한다는 것이 마코프 체인의 핵심.
-
🪄 마르코프 성질(Markov property) : 과거와 현재 상태가 주어졌을 때의 미래 상태의 조건부 확률 분포가 과거 상태와는 독립적으로 현재 상태에 의해서만 결정
-
마르코프 모델의 두 가지 요소:
-
전이 확률 (Transition Probability):
- 역할: 전이 확률은 현재 상태에서 다음 상태로 전이할 확률을.
- 표기: 보통 (P(X_{t+1} | X_t))로 표기되며, (X_t)는 현재 시간 스텝의 상태를 나타냄. 이는 마르코프 체인에서 상태 간의 전이를 확률적으로 모델링하는 데 사용.
- 예시: "현재 날씨가 맑다면 다음 날씨가 비가 올 확률"과 같이 이전 상태에서 다음 상태로의 이동.
-
출력 확률 (Output Probability 또는 Emission Probability):
- 역할: 출력 확률은 각 상태에서 특정 출력이 관측될 확률.
- 표기: 일반적으로 (P(O_t | X_t))로 표기되며, (O_t)는 현재 상태에서 관찰된 출력을 나타냄.
- 예시: "현재 상태가 어린이가 말하는 상태이면 '바나나'를 말할 확률"과 같이 상태에서 특정 출력이 관측될 확률.
- 날씨 모델 예시:
-
상태 (States): 맑음 (Sunny), 흐림 (Cloudy), 비 (Rainy) 세 가지 날씨 상태를 가정.
-
전이 확률 (Transition Probabilities): 현재 날씨 상태에서 다음 날씨 상태로의 전이
- 각 날씨 상태 간의 전이 확률을 정의합니다.
- P(Sunny→Cloudy)=0.3
- P(Sunny→Rainy)=0.2
- P(Cloudy→Sunny)=0.4
- P(Cloudy→Rainy)=0.3
- P(Rainy→Sunny)=0.1
- P(Rainy→Cloudy)=0.2
-
출력 확률 (Output Probabilities):
- 각 날씨 상태에서 특정 관찰 (출력)이 나타날 확률을 정의.
- P(’Sunglasses’∣Sunny)=0.8
- P(’Jacket’∣Sunny)=0.2
- P(’Jacket’∣Cloudy)=0.7
- P(’Umbrella’∣Rainy)=0.9
이러한 확률은 각 날씨 상태에서 특정 관찰이 나타날 확률을 나타냄. 예를 들어, 맑은 날씨에서 '선글라스'를 발견할 확률은 0.8.
- 확률 계산: 만약 현재 날씨가 맑다면, 다음 날씨가 흐리고, 그 후에 '우산'을 발견할 확률 : P(Sunny→Cloudy→’Umbrella’)=P(Sunny→Cloudy)×P(’Umbrella’∣Cloudy) = 0.3 × 0.3 = 0.09 =0.3×0.3=0.09
import random
def build_markov_model(text, order=1): # # order를 지정하지 않은 경우, 기본값 1
words = text.split() # 문자열을 특정 구분자를 기준으로 나누어 리스트로 반환
model = {}
# 주어진 텍스트로부터 마르코프 모델 생성
for i in range(len(words) - order):
state = tuple(words[i:i + order]) # 현재 상태를 정의 (튜플로 변환하여 사용)
next_word = words[i + order] # 다음 단어를 가져옴
if state not in model: # model은 마르코프 모델을 나타내는 딕셔너리
model[state] = []
model[state].append(next_word)
return model
def generate_text(model, length=10, start=None):
if start is None:
start = random.choice(list(model.keys())) # 시작 상태를 무작위로 선택
current_state = start
generated_text = list(start) #새로운 단어가 추가될 때마다 편리하게 처리하기 위해 list 사용
# 주어진 길이 만큼의 새로운 문장 생성
for _ in range(length - len(start)): # _은 반복 변수이지만 특별히 사용되지 않는 변수를 나타냄
next_word = random.choice(model.get(current_state, [""])) # 다음 단어를 무작위로 선택
generated_text.append(next_word)
current_state = tuple(generated_text[-order:]) # 현재 상태 업데이트
return ' '.join(generated_text) # ' '은 각 단어 사이에 삽입될 문자열
# 예시 텍스트
example_text = "The quick brown fox jumps over the lazy dog."
# 2차 마르코프 모델 생성
markov_model = build_markov_model(example_text, order=2)
# 새로운 문장 생성
generated_sentence = generate_text(markov_model, length=10)
print(generated_sentence)
- 신경망 기반 언어 모델 (2000년대 초반):
- 통계적 모델의 한계를 극복하기 위해 신경망을 사용한 언어 모델이 등장. 특히, 피드포워드 신경망과 리커런트 신경망(RNN)이 사용.
- 단어를 분산표현으로 전환–고차원벡터 : 임베딩 단어끼리 얼마나유사한지 판단할 수 있게 섬세하게 표현했다. RNN과 같은 모델
- 입력층(Input Layer): 네트워크에 데이터를 입력
은닉층(Hidden Layer): 입력층과 출력층 사이에 있는 중간 층으로, 입력 데이터의 비선형 특징을 학습
출력층(Output Layer): 네트워크의 최종 출력을 생성
가중치(Weights)와 편향(Bias): 연결 강도와 각 노드에 추가되는 편향
활성화 함수(Activation Function): 노드의 입력을 출력으로 변환하는 비선형 함수
# 신경망 모델
import torch.nn as nn
class FeedforwardNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(FeedforwardNN, self).__init__()
self.layer1 = nn.Linear(input_size, hidden_size)
self.layer2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = self.layer1(x)
x = torch.relu(x)
x = self.layer2(x)
return x- 순환 신경망 (RNN) 기반 언어 모델 (2010년대 초반):
- RNN은 단어의 시퀀스를 처리하는 데 효과적이라 판단되어 언어 모델링에서 많이 사용.
그러나 RNN은 긴 시퀀스에 대한 처리에 어려움이 있어, 장기 의존성(Long-Term Dependencies) 문제가 발생. - Long-term defendency : (장기 의존성 문제) 은닉층의 과거 정보가 마지막까지 전달되지 못하는 현상으로 time step이 길어질 수록 앞의 정보가 뒤로 충분히 전달되지 못하는 현상
- 예시 : 나는 여름 밤을 제일 좋아해. 다들 의아해할 지도 모르지만 상대적으로 선선한 공기와 예쁜 야경들을 보고 있으면 괜히 기분이 좋아지거든 그래서 나는 ____ 이 좋아. 👉 이런 경우 RNN이 충분한 기억력을 가지고 있지 않으면 밑줄에 해당하는 단어를 유추하기 쉽지 않음.
- 이런 현상은 RNN에서 자주 발생하는데, 그 이유는 활성화 함수 때문임.
🤬 Vanishing Gradient Problem(기울기 소실 문제): 긴 시퀀스에서 역전파(backpropagation)를 통해 기울기가 전파될 때, 기울기가 지수적으로 감소하여 초기 입력에 대한 영향이 거의 없음 : sigmoid 함수 중 대표적인 로지스틱 함수를 미분한 함수의 그래프의 기울기는 최대가 0.25이고 최소가 0에 수렴함. 따라서 역전파에서 입력층에 가까운 앞쪽의 layer로 갈수록 sigmoid 함수의 미분을 연쇄적으로 곱하는데 기울기가 1보다 작으므로 곱할수록 값은 점점 작아짐. layer가 아주 많으면 입력층에 가까운 앞쪽의 layer로 갈수록 기울기의 값은 거의 0에 가깝게 작아져서 가중치의 변화가 거의 없게 되고 error값도 더 이상 줄어들지 않음.
🤬Exploding Gradient Problem(기울기 폭주 문제): 반대로, 기울기가 지수적으로 증가하여 숫자가 커져 가중치가 매우 크게 업데이트되는 문제가 발생
import torch
import torch.nn as nn
# RNN 모델 정의
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleRNN, self).__init__() # 파이썬에서 사용되는 내장 함수로, 상위 클래스의 메서드를 호출하는데 사용
self.hidden_size = hidden_size
# 입력에서 은닉 상태로 가는 선형 변환
self.i2h = nn.Linear(input_size + hidden_size, hidden_size)
# 은닉 상태에서 출력으로 가는 선형 변환
self.i2o = nn.Linear(input_size + hidden_size, output_size)
# 활성화 함수 (여기서는 tanh를 사용)
self.tanh = nn.Tanh() # -1에서 1 사이의 값으로 압축하는 비선형 함수
def forward(self, input, hidden):
# 입력과 은닉 상태를 결합
combined = torch.cat((input, hidden), 1) #PyTorch에서 제공하는 텐서를 결합(concatenate)하는 함수
# 1: 차원을 나타내며, 여기서는 두 텐서를 가로로 결합하도록 지정함
# 입력과 은닉 상태를 고려한 새로운 은닉 상태 계산
hidden = self.i2h(combined)
hidden = self.tanh(hidden)
# 새로운 은닉 상태를 사용하여 출력 계산
output = self.i2o(combined)
return output, hidden
# 입력, 은닉 상태, 출력의 크기 정의
input_size = 3
hidden_size = 4
output_size = 2
# 모델 생성
rnn = SimpleRNN(input_size, hidden_size, output_size)
# 예제 입력과 초기 은닉 상태 생성
input_tensor = torch.tensor([1.0, 2.0, 3.0], dtype=torch.float32)
hidden_tensor = torch.zeros(hidden_size, dtype=torch.float32)
# 순방향 전파 수행
output_tensor, new_hidden_tensor = rnn(input_tensor, hidden_tensor)
# 결과 출력
print("Input:", input_tensor)
print("Output:", output_tensor)
print("New Hidden State:", new_hidden_tensor)
신경망 모델:
- 피드포워드(Feedforward) 구조: 입력이 출력 방향으로만 흐르는 구조. 즉, 입력층에서 출력층으로의 단방향 전파.
- 순서 정보 처리 불가능: 각 입력은 독립적으로 처리되며, 순서 정보가 고려 x. 예를 들어, 문장의 단어 순서를 고려하지 않고 개별 단어를 처리.
- 고정된 크기의 입력과 출력: 주어진 입력 크기와 출력 크기가 고정.
순환 신경망(RNN) 모델:
- 순환 구조: RNN은 이전 단계의 출력이 현재 단계의 입력으로 사용되는 순환 구조. 이로써 시퀀스 데이터의 처리가 가능.
- 순서 정보 고려: RNN은 시퀀스 데이터에서 각 단계의 입력에 대한 순서 정보를 고려. 예를 들어, 문장에서 단어의 순서를 인식하고 이전 단어의 정보를 활용.
- 가변적인 크기의 입력과 출력: 시퀀스 길이에 따라 가변적인 크기의 입력과 출력.
- LSTM (Long Short-Term Memory) 및 GRU (Gated Recurrent Unit) 등의 개선된 RNN (2010년대 중후반):
- LSTM과 GRU와 같은 구조가 소개되면서 RNN의 장기 의존성 문제가 해결. 이로써 긴 시퀀스에 대한 효과적인 모델링이 가능.
- Transformer 아키텍처와 대형 언어 모델 (2017년 이후):
- Transformer 아키텍처는 언어 모델의 패러다임을 바꿈. Self-attention 메커니즘을 이용하여 병렬 처리가 가능, BERT와 GPT와 같은 대형 언어 모델이 등장하면서 자연어 처리의 다양한 작업에서 높은 성능.
- GPT-3와 더 큰 모델 (2020년대 중반):
- GPT-3는 1750억 개의 파라미터를 가진 엄청난 규모의 언어 모델로, 다양한 자연어 처리 작업에서 놀라운 성과. 이로써 대형 모델의 활용이 중요한 연구 및 응용 분야로 자리매김.
- Electra는 GPT와 BERT와는 조금 다른 방식으로 학습되는 모델. Pre-training 단계에서 일부 단어를 마스킹하고, 이를 다른 단어로 대체하여 모델을 학습. 이후, 마스킹된 부분을 예측하는 데 중점을 둬 전체 문맥을 이해하도록 학습.
이 방식은 GPT와는 다르게 더 효율적인 학습을 제공하며, 문장의 일부를 숨기고 예측하도록 하여 미세한 문맥의 이해를 강조.
참고한 자료들
