chapter 01 : What is Reinforcement Learning?
기계학습의 기본적인 세 가지 요건 🤔
One of the three basic pillars of machine learning
- supervised learning ; x를 받았을 때 어떤 y를 내보내야 하는지 찾는 모델
- unsupervised learning ; 클러스터링 (라벨을 알려주지 않아도 알아서 찾는 모델)
- reinforcement learning ; 대표적인 예시가 게임 (어떤 화면이 등장했을 때 어떻게 움직여야 하는지 알려주기는 쉽지 않음)
이것에 관해 많은 흥미로운 연구들이 발전하고 있으나, 아직까지 상업적으로 대박나지는 않음. 이제 강화학습에 대해 살펴보자.
예시: 자율 헬리콥터(Autonomous Heolicopter) 
- 내장 컴퓨터, GPS, 가속도계, 자이로스코프, 그리고 자력 나침반이 장착
- 그래서 항상 정확하게 자신이 어디에 있는지 알고 있음
- 조이스틱으로 조종 가능
- Task
초당 열 번씩 헬리콥터의 위치, 방향, 속도 등이 제공
공중에서 헬리콥터를 균형있게 유지하기 위해 조종 스틱을 어떻게 움직여야 할지 결정
어떻게 automatically하게 프로그램을 작성할 것인지?
중요한 것은 주변 상황 정보가 모두 들어오고 있지만 너무 다양한 y가 존재하기 때문에 어떻게 움직여야 하는지 직접 알려주기는 어려움
- (A video of an autonomous helicopter)
강화학습 알고리즘 제어 아래 비행
강화 학습은 헬리콥터가 다양한 스턴트(예: 에어로바틱 기동)를 날 수 있도록 하는 데 사용
Reinforcement learning
- State s : 헬리콥터의 위치, 방향, 속도 등 agent가 마주친 상황을 말함 (The position, orientation, speed, and so on of the helicopter)
- Action a : 컨트롤 스틱을 어떻게 움직일지 등 해당 state에 맞춰서 어떤 행동을 할지 맞추는 것을 말함 (How to move the control sticks (i.e., how far to push the control sticks))
- Task : 상태 s에서 행동 a로 매핑하는 함수 𝜋(s) = a를 찾는 것으로 결국 강화학습은 PI를 찾는 것이 하이라이트임
- (Find a function 𝜋(s) = a that maps from the state s to an action a)
- f(x) = y 와 비슷한 꼴이다. 그렇지만 y가 너무 많다. 예를 들어 초창기 자율주행의 경우에는 supervised learning으로 이용자가 악셀을 밟았는지, 브레이크를 밟았는지를 알려줌
- Reward (or reward function) R(s) :
- 헬리콥터에게 잘하고 있을 때와 못하고 있을 때를 알려주기 : Tells the helicopter when it’s doing well and when it’s doing poorly
- 긍정적 보상: 헬리콥터가 잘 날아다님 (예: +1) : Positive reward: helicopter flying well (e.g., +1)
- 부정적 보상: 헬리콥터가 잘못된 비행을 하거나 날지 못함 (예: -1000) : Negative reward: helicopter flying poorly (e.g., -1000)
- state에 대해서 잘했는지 못했는지 알려줌 (state에 관한 함수)
- 구체적으로 reward를 알려주는 것이 아니라, 얼마나 잘했는지의 '정도'만 알려준다고 생각하자
Reward Function R(s)
강화학습의 중요한 입력 요소 (A key input to a reinforcement learning)
- 좋은 일을 할 때마다 "좋아"라고 말하기 (Whenever it does something good, you say “good”)
- 나쁜 일을 할 때마다 "나쁘다"라고 말하기 (– Whenever it does something bad, you say “bad”)
- 그러면 바람직한 일을 더 많이 하고 나쁜 일은 줄이도록 스스로 학습 (Then hopefully it learns by itself how to do more of the good things and fewer of the bad things)
- 이 reward 함수를 정의하는 것이 매우 중요하다.
강화학습 알고리즘의 역할 : 좋은 결과는 더 얻고, 나쁜 결과를 얻었을 경우 더 적게 얻도록 만드는 방식을 찾는 것임 (To figure out how to get more of the good outcomes and fewer of the
bad outcomes)
왜 강화학습이 매우 강력한가?
- You have to tell it what to do rather than how to do it
- 어떻게 하는지가 아니라 무엇을 해야 하는지를 알려줘야 함
- Specifying the reward function rather than the optimal action gives you a lot more flexibility in how you design the system
- 최적의 행동이 아니라 보상 함수를 명시하는 것은 시스템을 설계하는 데 훨씬 더 많은 유연성을 제공
supervised learning과 다른 점은 무엇인가요?
- 자율 헬리콥터 비행에는 좋은 방법이 아님
- 만약 상태 𝐱의 다양한 관측치를 얻고 전문 조종사가 최선의 행동 𝐲를 알려준다면 지도 학습을 사용해 모델을 훈련시켜 직접적으로 𝐲 = 𝑓(𝐱)를 배울 수는 있음
- 하지만 헬리콥터가 공중을 움직일 때 y(정확히 옳은 행동)은 매우 모호함
- (𝐱, 𝐲)의 완벽한 집합을 얻는 것이 실제로 매우 어려움
- 그래서 헬리콥터와 같은 로봇을 제어하는 많은 작업에서는 지도 학습 접근법이 잘 작동하지 않ㅇㅁ
Example of Learning to Walk
https://www.youtube.com/watch?v=gn4nRCC9TwQ

- 프로그램에게 어떻게 걷을지를 아무도 가르쳐주지 않음
- 로봇(인형?)은 목표에 대한 진전을 도와주는 보상만 받고, 자동으로 학습함
적용; Applications
요즘에는 강화 학습이 다양한 분야에 성공적으로 적용돼요.
1. 로봇 제어 : 헬리콥터, 로봇 등
2. 공장 최적화 : 공장 내 물건들을 재배치해 처리량과 효율성을 극대화 (이럴 때는 효율성이 떨어진다 알려줄 수 있음)
3. 금융 (주식) 거래 : 최상의 가격을 얻기 위해 시간별 거래 순서를 결정
4. 게임 플레이 (비디오 게임 포함) : 체커, 체스, 카드 게임 등 많은 비디오 게임에서 사용
- 대전 게임의 경우 강화학습이 잘 작동함
- 사람의 수준에 따라서 게임의 수준이 달라지게 할 수 있음
- Deep Q learning! 벽돌깨기 게임
중간 요약; Summary
-
핵심 아이디어
모든 입력 𝐱에 대해 정확한 올바른 행동 𝐲를 알려주지 않아도 됨
대신, 잘하고 있는지 아닌지를 알려주는 보상 함수를 명시
좋은 행동을 선택하는 방법은 알고리즘의 역할
You don’t need to tell the algorithm what is the right action 𝐲 for every single input x
Instead, all you have to do is to specify a reward function that tells it when it’s doing well and when it’s doing poorly
And it’s the job of the algorithm to automatically figure out how to choose good actions -
Let’s now formularize the reinforcement learning problem (Also start to develop algorithms for automatically picking good actions)
chapter 02 : Mars Rover Example
간단한 예제를 활용하여 강화 학습을 개발
Let’s develop reinforcement learning using a simplified example
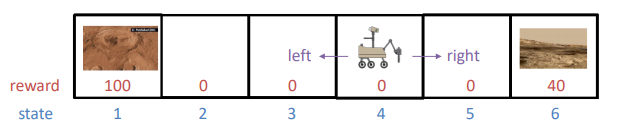
State
• The position of the Mars rover (1, 2, 3, 4, 5, 6)
Rewards
• At state 1 → 100 (a very interesting surface to sample) 매우 잘함!
• At state 2, 3, 4, 5 → 0 (not as much interesting surface) 별로 영양가 없음. 잘한 것도, 못한 것도 아님
• At state 6 → 40 (a pretty interesting surface to sample) 나쁘지는 않음
- reward는 stae에 대해 매겨지는 것임 (너가 이 state에 진입했으면 이만큼 줄게!)
Actions
• On each step, the rover can either go to the left or it can go to the right
- 모든 possible한 action에 대해 정의해야 함 (이 예제에서는 왼쪽, 오른쪽만 움직일 수 있음)
Examples of rewards
– Assume that when the rover gets either state 1 or 6, the day ends
– state: 4 → 3 → 2 → 1 ➔ reward: 0, 0, 0, 100
– state: 4 → 5 → 6 ➔ reward: 0, 0, 40
– state: 4 → 5 → 4 → 3 → 2 → 1 ➔ reward: 0, 0, 0, 0, 0, 100
✓ Not such a great way because it is wasting a bit of time
✓ 다양한 움직임이 있을 수 있고, 그 움직임에 따라 reward가 달라짐 (단, 여기에서는 단순 reward를 산술 합으로 하지않음 (이 예제에서 4번 움직이는 것과 6개 움직이는 것은 reward의 합은 100이지만, 빨리 도착할 수록 reward를 높이고 느리게 도착할 수록 reward를 낮춤)
✓ terminal state가 있을 수 있음 (종료를 나타내는 경우)
- 예를 들어서 게임에서 미션을 전부 달성하고 게임을 깼을 때
- 이 예제에서는 양쪽 끝에 도착하면 자동으로 종료되게 함.
